







Pix2pix:基于条件对抗网络图对图翻译
我现在正在研究GAN,GAN也正是我的兴趣方向之一。
本篇要讲的是pix2pix,讲道理,那个网页版我可以玩一年
(注:原代码是用torch写的,但是作者也在官网提供了tensorflow版和pytorch版。起码不用面对lua这个语言)
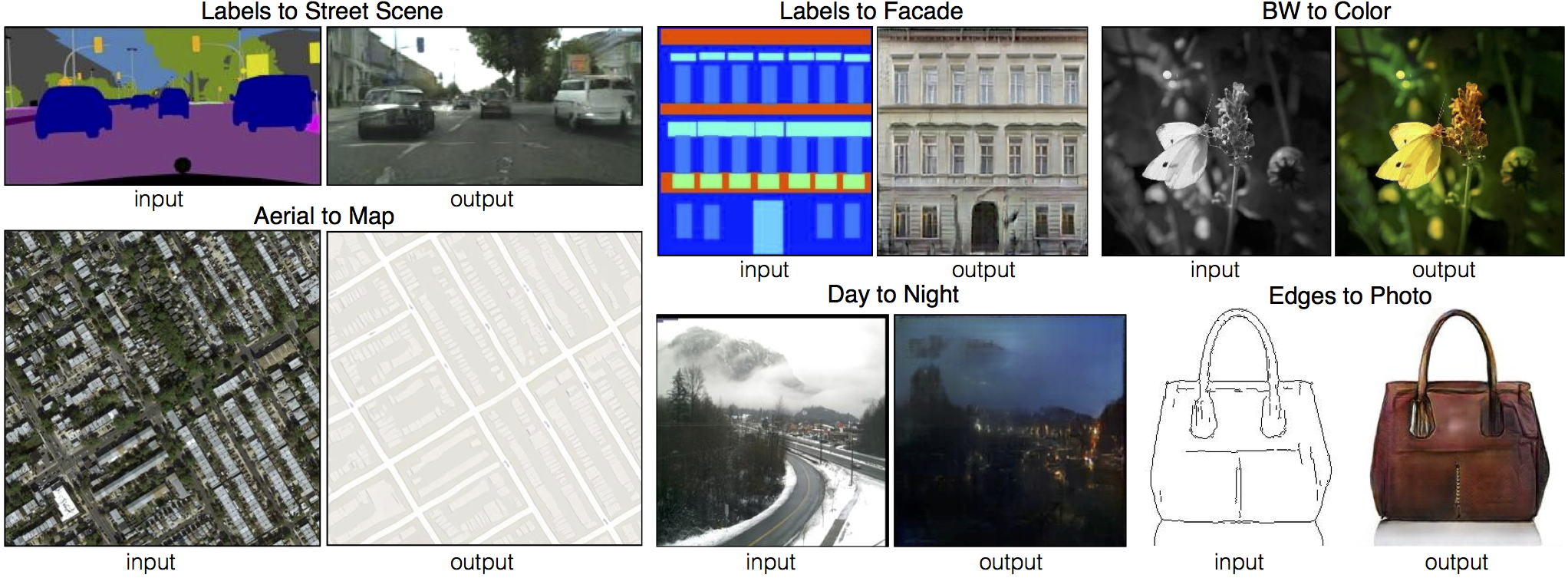
图像翻译
“翻译”常用于语言之间的翻译,就比如中文和英文的之间的翻译。但是图像翻译的意思是以不同形式在图与图之间转换。比如,一张场景可以转换为RGB全彩图,也可以转化成素描,也可以转化为灰度图。一张夜景图也可以转化为这个地方的日景图。
传统的来说,每一种转换,比如从灰度图到素描,或者从素描到灰度图,都是需要一种特定的算法。而Pix2pix的目标就是建立一个通用的架构去解决所有的这些问题。
自编码器与CNN,为了使loss function更小而不得不使生成出来的图片模糊。这些对loss function有益的行为最终导致的是生成很假的图片(讲个道理,模糊的原因与很多自编码器采取sigmoid有没有关系?笔者觉得使用leaky relu可能会减少模糊,但是笔者试过,效果不算好)GAN提供了一种生成精准图片的方法,原因是识别网络完全能判断出模糊的图像是假图。
这在里,作者使用了条件GAN(cGAN)去学习一个条件生成模型。
方法
损失函数
cGAN的损失可以表达为:
LcGAN(G,D)=Ex,y[logD(x,y)]+Ex,z[log(1−D(x,G(x,z)))]
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









