







 本文深入探讨了深度学习中各种优化器的工作原理及其优缺点,包括SGDwithMomentum、Adagrad、RMSProp、Adam等,同时介绍了学习率调整策略如CyclicalLR、One-cycleLR以及Warm-up的重要性。此外,还对比了SGDM与Adam的性能差异,并讨论了Nesterov accelerated gradient和Lookahead等高级优化策略。
本文深入探讨了深度学习中各种优化器的工作原理及其优缺点,包括SGDwithMomentum、Adagrad、RMSProp、Adam等,同时介绍了学习率调整策略如CyclicalLR、One-cycleLR以及Warm-up的重要性。此外,还对比了SGDM与Adam的性能差异,并讨论了Nesterov accelerated gradient和Lookahead等高级优化策略。
文章目录
配合参考链接的视频一起服用 效果更佳喔
1. SGD with Momentum 带动量的SGD
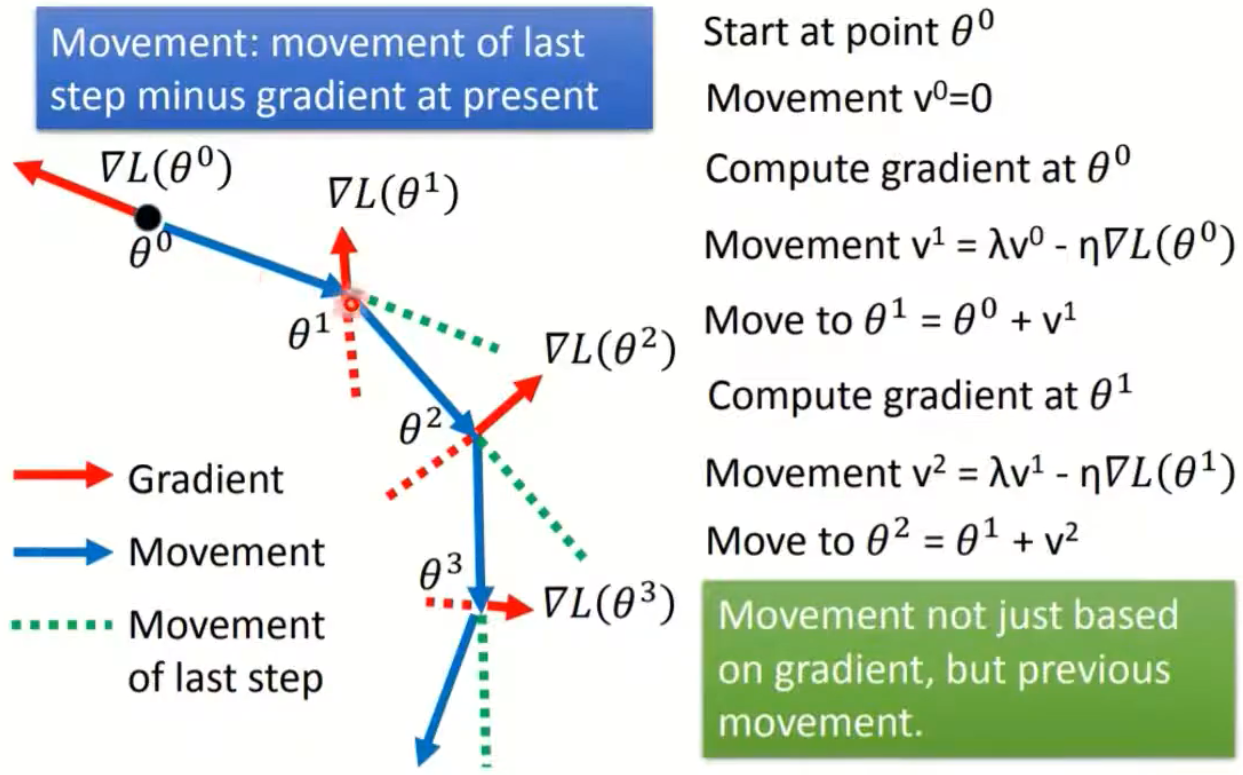
Momentum意思就是动量,有点类似于给梯度下降过程中加了一个惯性,在优化过程中不仅仅考虑了当前的梯度大小,也考虑到之前所有梯度累积对当前的影响。
加了动量之后有什么好处呢
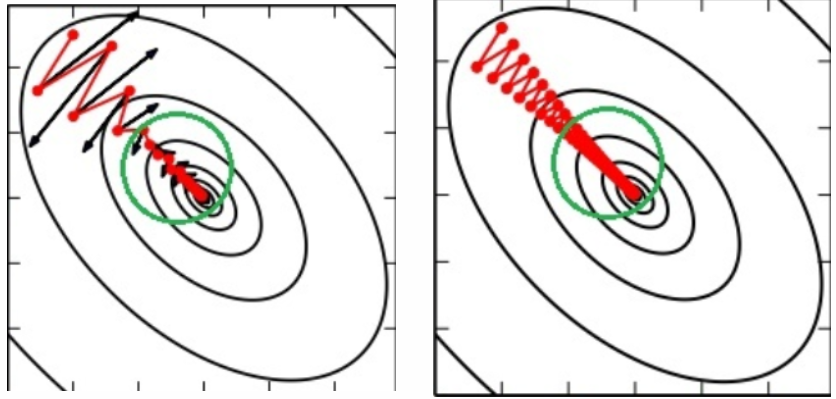
- 最大的用处应该是能在一定程度上避免局部最优解的陷阱,如下图所示,到达了局部最优点之后,虽然梯度为0,由于动量(惯性)的存在,会继续更新,更有可能逃离鞍点:
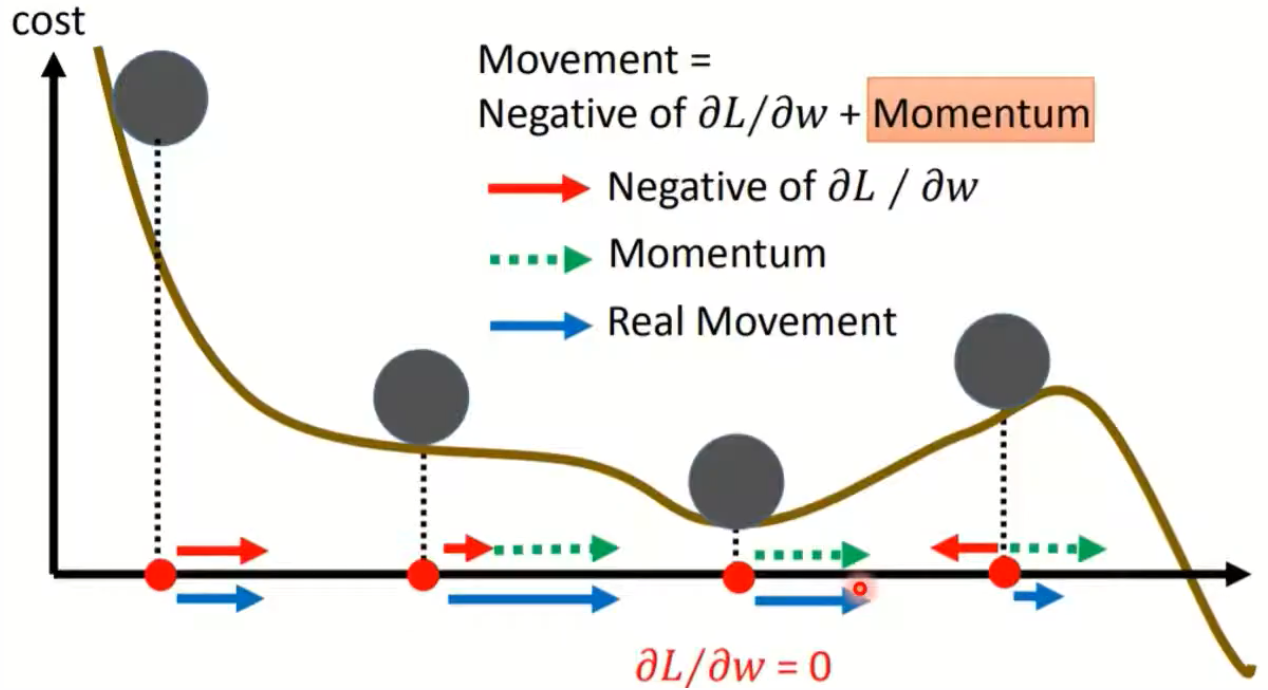
- 在梯度下降过程中能够减少震荡,可以把原始的SGD想成一个纸团,由于质量小在下降过程中受到干扰大,导致来回震荡,而SGDM使得其变为一个铁球,这样在gradient descent时会更加稳定。
2. 基于SGDM的提升
SGDM最大的缺点就是无法自适应地调整学习率,如果学习率设置地过小,那么收敛太慢,学习率过大,结果不好。所以学习率过大和过小所训练得到的结果都不会太好,所以出现了一系列动态调整学习率的方法。
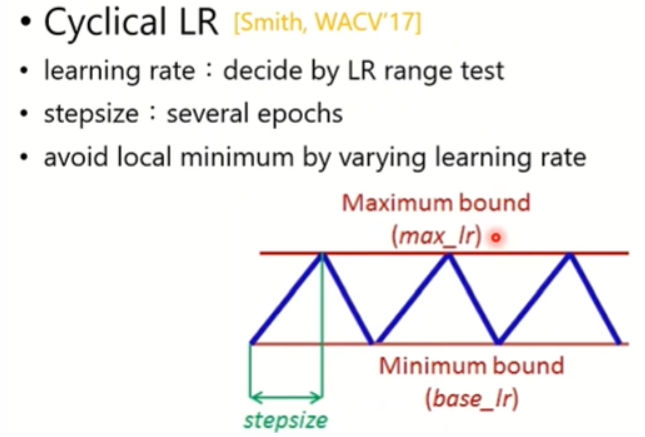
Cyclical LR
这是一个周期性调整学习率的方法,设置一个下界和上界,以及stepsize,让学习率周期性地进行调整。
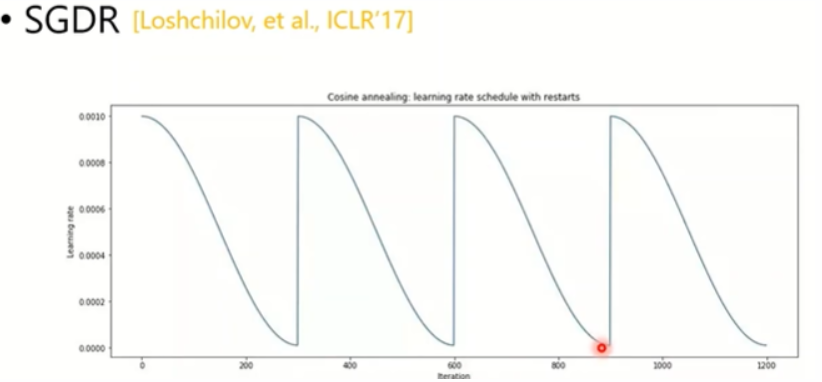
SGDR
类似于Cyclical LR的想法,只不过使用的周期函数不太一样。
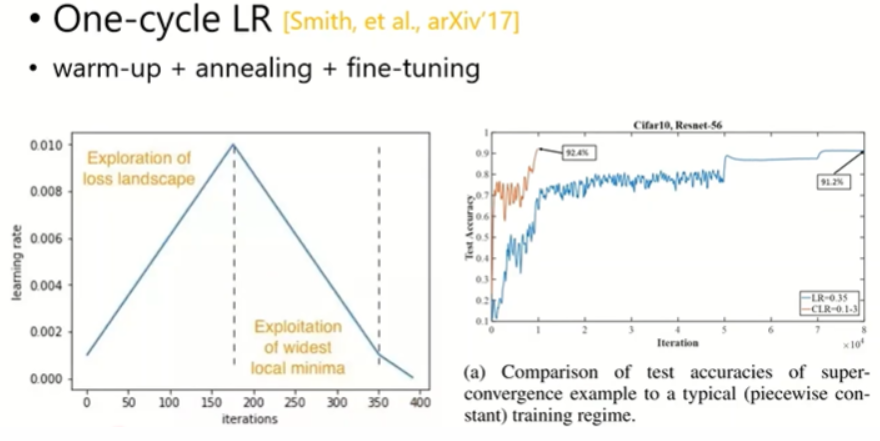
One-cycle LR
warm-up + annealing + fine-tuning
3. Adagrad 自适应学习率调整
我另一篇Blog有详细讲Adagrad的推导(对应博客),感觉李宏毅讲的和他助教讲的有点区别,这里简单提一下作用:
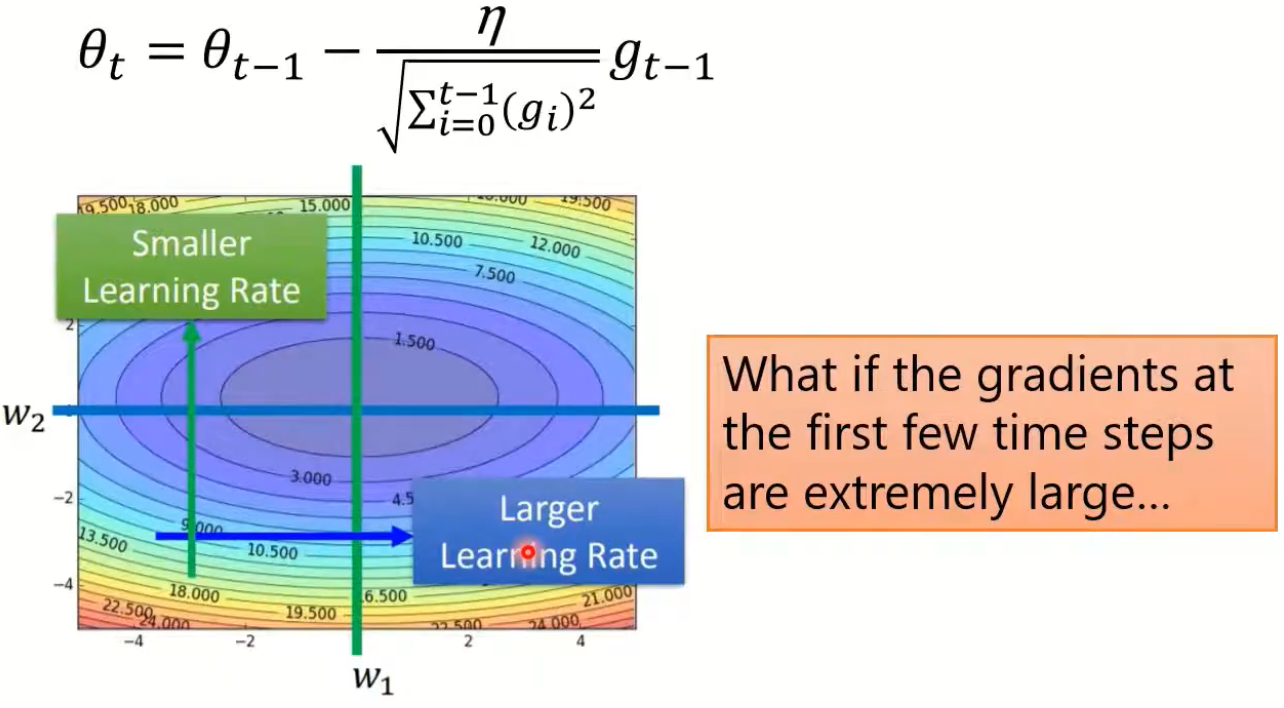
- 如果前几次梯度过大,那么Adagrad会进一步限制步长,避免学习率过大从而越过最优点;
- 如果前几次梯度过小,Adagrad会适当加大步长,加快收敛;(相比于SGD,Adagrad的学习率会设置地比较大)
- 针对不同的参数能够自适应地调整学习率大小
4. RMSProp 基于Adagrad的改进
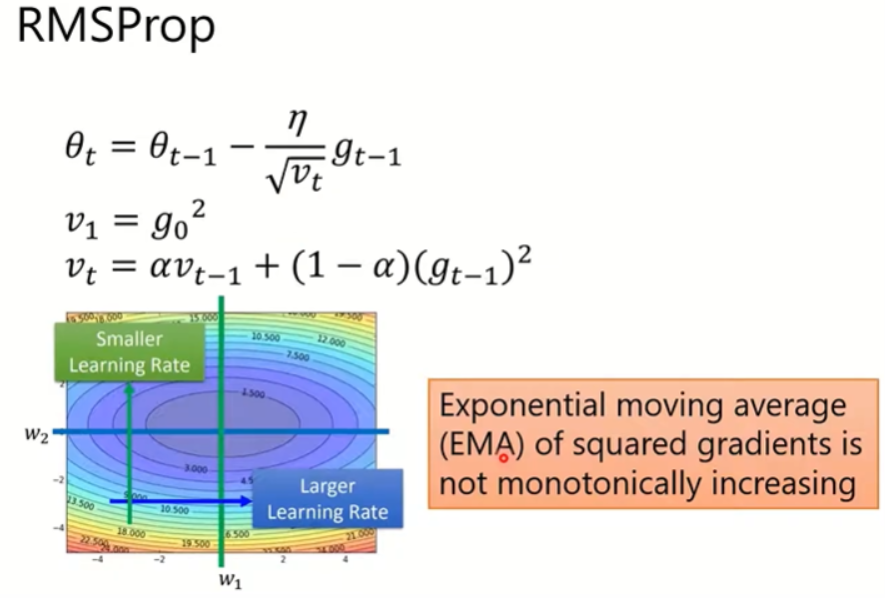
Adagrad会遇到一个瓶颈,如果前几次的梯度过大,那么后续的步长会很小,这样会使得收敛速度变得很慢。RMSProp就是来解决这个问题,它将Adagrad的分母部分进行了替换。Adagrad是简单地进行相加,而RMSProp使用了EMA(exponential moving average,指数加权平均/滑动加权平均),可以调整过去gradient的累计值对当前梯度下降的影响,这样可以避免分母部分一直无止境地增大。
5. Adam 自适应与动量的结合
RMSProp虽然对Adagrad做了改进,但是无法解决局部最优解的问题。既然SGDM可以解决局部最优的问题,而RMSProp能进行自适应调参,那把它们结合一下就是Adam (刚开始的iterations会进行纠偏 de-biasing):

SGDM 与 Adam 的比较
Adam: fast training, large generalization gap, unstable
SGDM: stable, little generalization gap, better convergence
Adam 存在的问题
由于Adam会考虑之前累积起来的梯度,那么就会出现一个问题,当前面一直是小的梯度,后面突然出现了大的梯度(突变的gradient往往很关键)。由于之前都是很小的梯度,即使来了一个很大的梯度,它的movement也会很小(相比于gradient的增幅)

AMSGrad 基于Adam的提升-1
为了消除Adam这些问题,有人提出了AMSGrad算法,每次在选择Vt时,会与之前更新过程中所出现过的最大V进行比较。(主要思想就是在梯度下降过程中,不要忘记之前所见过最大梯度值,这样会限制小gradient的Step,以免后面出现大的gradient,Step反而增幅不大)

但这样会出现和Adagrad一样的问题,就是如果前几个Step的Gradient过大,那么收敛会变得非常慢,甚至无法收敛。
AdaBound 基于Adam的提升-2
AMSGrad只能解决掉大learning rate的问题,AdaBound考虑的是解决小learning rate的问题。

AdaBound的学习率所设置的参数是经验性的、工程性的,不够优雅,并且学习率还不是自适应的。
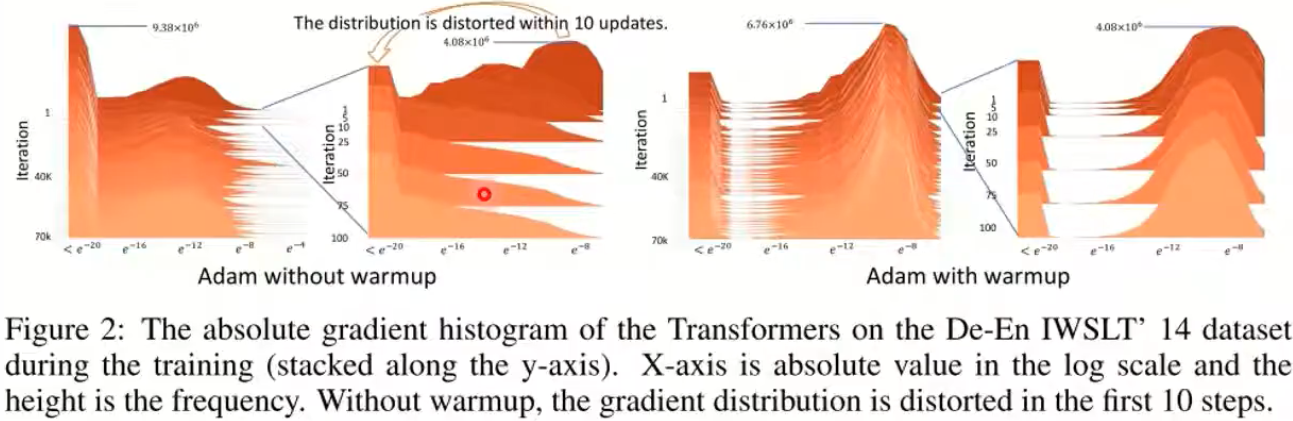
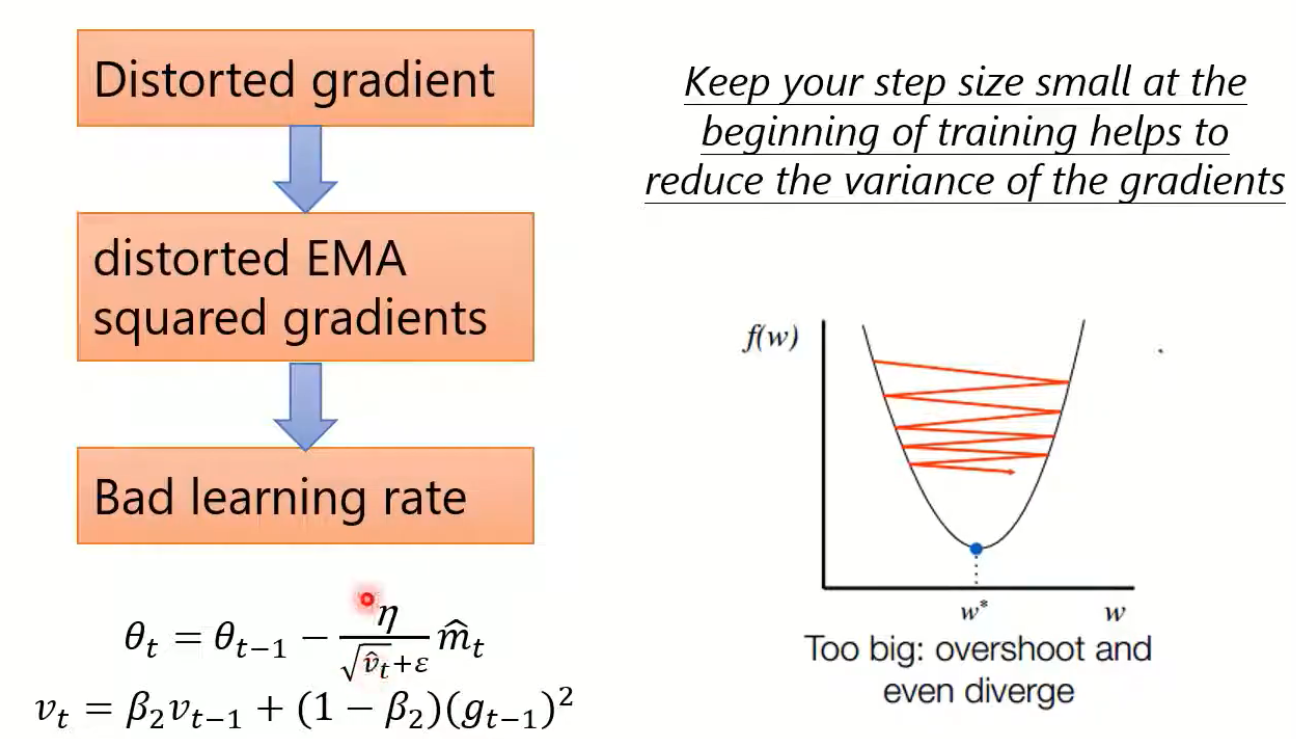
Adam需要Warm-up
Adam需要热启动(Warm-up),那为什么要需要Warm-up呢?如果没有warm-up,最开始的几个iteration中,初始化参数可能导致梯度分布十分不均匀,并且Adam分母部分的估计不准,导致gradient descent时的step可能一会儿大一会儿小。而增加了warm-up,由于learning rate增加,这种情况会得到改善。
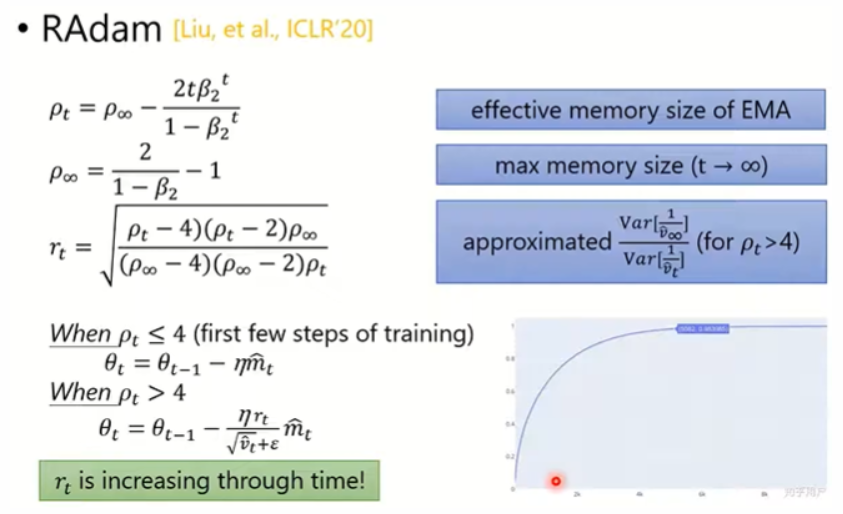
RAdam
既然刚开始的iteration的MEA估计不准确,那就先使用SGDM,随后使用RAdam(自己定义)。
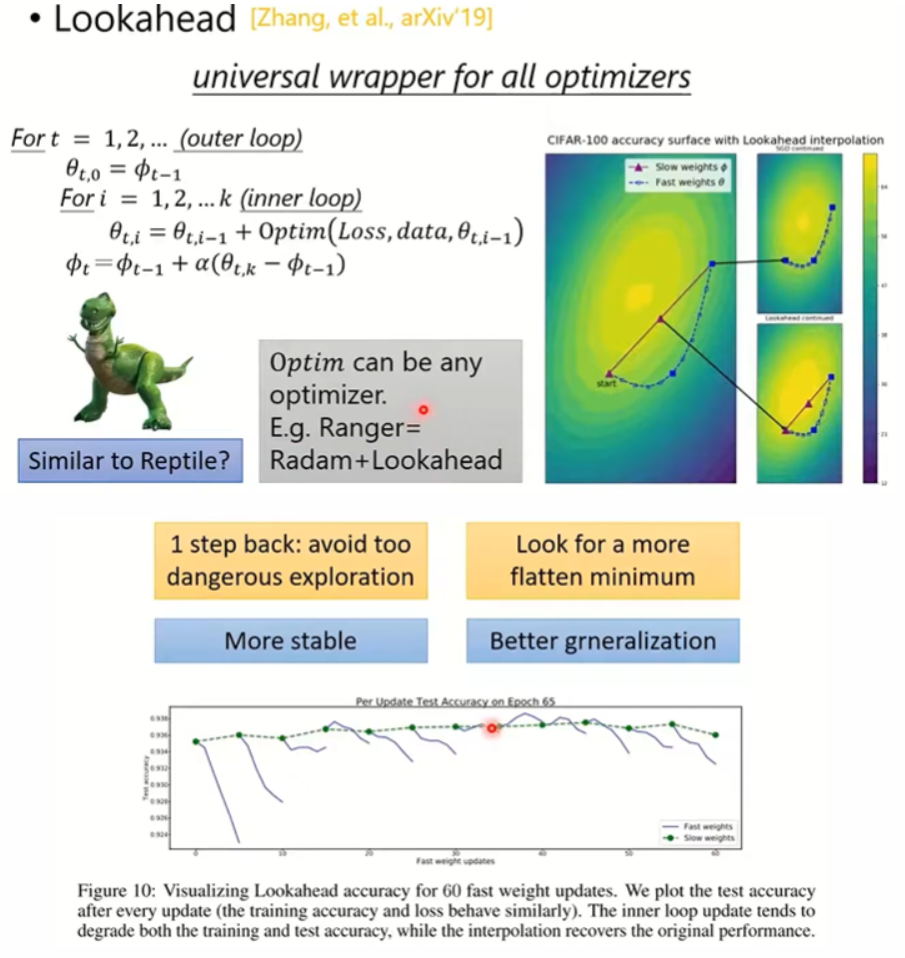
6. Lookahead 另一种角度的优化
Lookahead每训练K个iteration,进行一次计算,选中一个新的参数点Φ,能够带来更好的稳定性和泛化效果。
7. Nesterov accelerated gradient(NAG) 提前利用梯度
在当前的parameter设置下,能够超前地"预测"到下一段的step,其相对于Momentum的改进在于,以“向前看”看到的梯度而不是当前位置梯度去更新。经过变换之后的等效形式中,NAG算法相对于Momentum多了一个本次梯度相对上次梯度的变化量,这个变化量本质上是对目标函数二阶导的近似。由于利用了二阶导的信息,NAG算法才会比Momentum具有更快的收敛速度。

8. Nadam NAG结合Adam
将NAG的超前部署思想引入到Adam中:

9. 考虑L2 regurization与Weight decay
通常我们会加入下面的正则化来限制参数不要过大(使得函数崎岖容易出现过拟合),但加上这一项之后,我们在使用SGDM和Adam时,momentum和v需要考虑这一项吗?
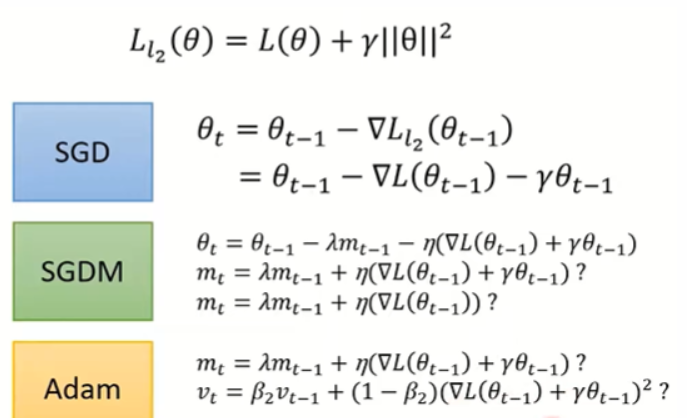
这个问题在17年得到了解决,这篇文章说明,在计算M和V时不需要考虑正则化项的影响效果会更好,最后在参数更新时减去weight decay项。(如果在M和V更新时考虑到正则项,称为L2 regurization,如果不考虑正则项,就称为weight decay)

10. 一些训练小技巧
- Shuffling:每个epoch数据的顺序需要变化
- Dropout:可以增加随机性
- Gradient noise:增加一些高斯项干扰
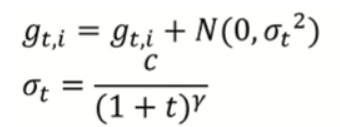
上面的方法都是增加model训练时的随机性,the more exploration, the better.
-
Warm-up
-
Curriculum learning:一开始使用easy data,然后使用difficult data,增加泛化能力
-
Fine-tuning:使用预训练模型
上面的方法就是对你的model多点耐心
-
Normalization
-
Regularization
参考
[1] 李宏毅《机器学习》
https://www.bilibili.com/video/BV1JE411g7XF?p=9

















 1582
1582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









