




如何在多模态信息检索和生成中,通过协作式多智能体系统来处理复杂的多模态查询。传统的单代理RAG系统在处理需要跨异构数据生态系统进行协调推理的复杂查询时存在根本性限制:处理多种查询类型、数据格式异质性和检索任务目标的多样性;在视觉内容和文本内容之间建立一致的跨模态关联;以及在不同模态之间进行有效的信息合成。
HM-RAG的核心目标是解决上述问题,通过分层多智能体协作与多模态知识合成,实现复杂查询的动态分解、跨模态检索与答案精炼。其设计灵感来源于:
-
多智能体系统:通过分工协作提升任务处理效率(如自动驾驶中的感知-决策-控制模块)。
-
知识图谱增强:结合图结构的关系推理与向量检索的细粒度匹配,弥补单一知识表示的不足。
-
动态实时性需求:引入网页检索代理,应对时效性敏感场景(如灾害事件中的实时社交媒体数据)。
研究方法
这篇论文提出了HM-RAG(Hierarchical Multi-Agent Multimodal Retrieval Augmented Generation),用于解决多模态信息检索和生成中的复杂查询问题。具体来说,
1 多模态知识预处理
1.1 多模态文本知识生成
传统的多模态知识提取方法依赖预定义类别,难以识别新的视觉概念。该框架借助BLIP - 2框架,将视觉信息转化为文本表示。这一过程分为三个协同阶段:先通过层次化视觉编码生成图像特征,再利用可学习查询进行跨模态交互,最后进行上下文感知的文本生成,并通过上下文细化机制优化生成结果。最终将生成的文本与原始文本语料库整合,形成多模态文本知识库。
1.2 多模态知识图谱构建
利用VLMs生成的细化视觉描述和LLM的结构推理能力构建多模态知识图谱(MMKGs)。通过LightRAG框架进行实体关系提取和双级推理增强,将知识形式化为三元组,同时嵌入视觉数据存储位置,实现跨模态接地,有效降低语言模型产生幻觉的概率。
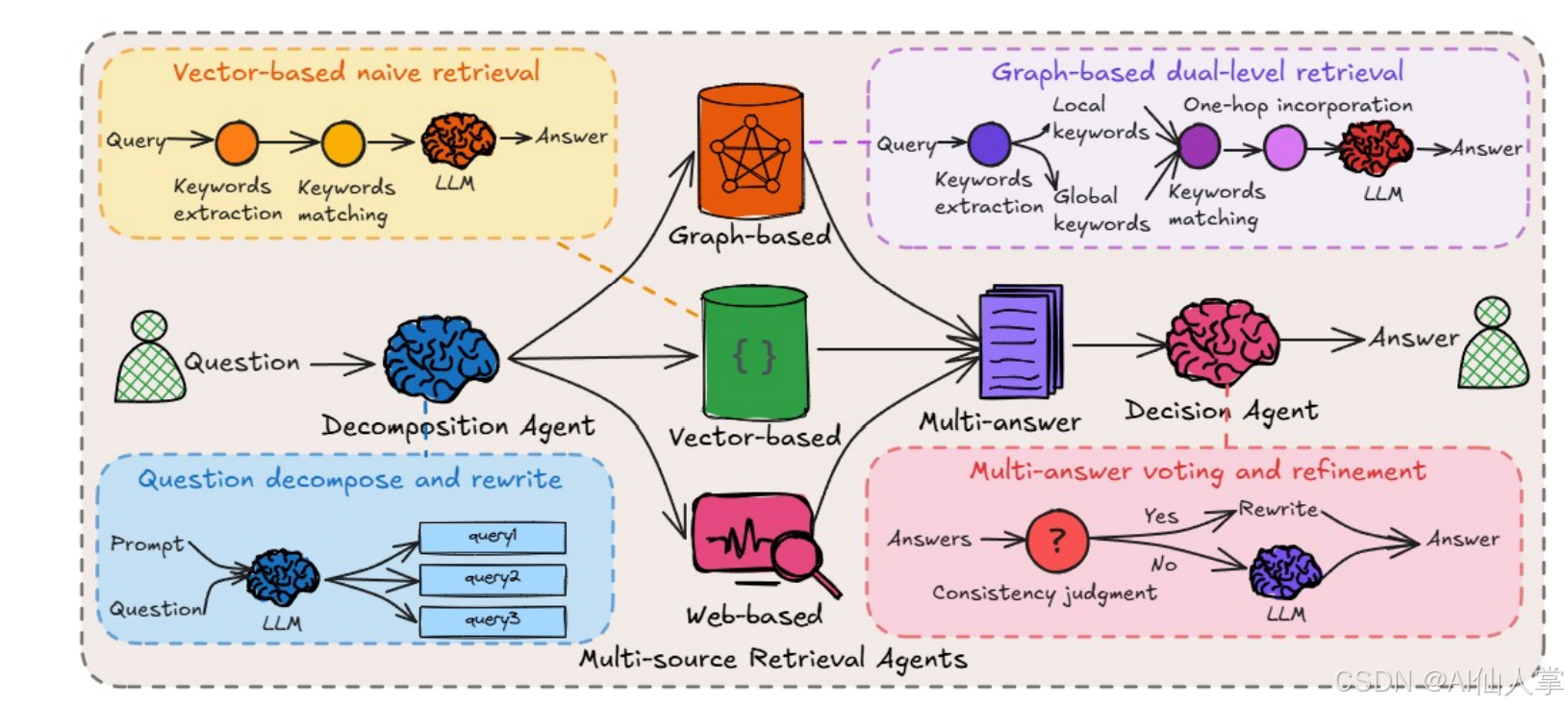
2 用于多意图查询的分解智能体
分解智能体是HM - RAG的关键组件,它能将复杂的多意图用户查询分解为多个可执行的子任务。通过任务特定的LLM提示策略,先判断查询是否包含多个意图,若是则将其分解为简单且逻辑相关的子问题,确保每个子问题能针对特定的数据模态或检索任务进行处理。
3 多源即插即用检索智能体
3.1 基于向量的检索智能体
基于向量的检索智能体用于细粒度信息检索。它通过计算查询与文档的语义相似度,从非结构化文本语料库中检索出最相关的文档,然后语言模型根据检索到的上下文生成答案。为保证答案的可靠性,采用确定性解码策略,降低幻觉风险。
3.2 基于图的检索智能体
基于图的检索智能体利用LightRAG的图遍历能力,在MMKGs上解决多跳语义查询。通过构建上下文感知子图,采用层次化搜索策略,结合图结构知识和向量表示,实现更高效、全面的信息检索,最后由轻量级LLM生成答案。
3.3 基于网络的检索智能体
基于网络的检索智能体利用Google Serper API获取实时信息,通过参数化API请求获取结构化结果。该组件通过实时事实验证、归因感知生成和自适应查询扩展等机制,提升生成文本的语义保真度和事实依据。
4 用于多答案精炼的决策智能体
4.1 一致性投票
决策智能体通过ROUGE - L和BLEU指标评估不同检索系统生成答案的语义一致性。若答案间相似度超过预定义阈值,使用轻量级LLM生成最终答案;若相似度低于阈值,则进入专家模型精炼阶段。
4.2 专家模型精炼
对于存在冲突的答案,利用LLMs、Multimodal LLMs(MLLMs)或Cot - based语言模型(Cot - LMs)整合多源证据,生成精炼的最终答案,确保答案既符合上下文逻辑又准确可靠。
实验设计
- 数据集:实验在两个多模态推理基准上进行,包括复杂的科学问答(ScienceQA)和危机事件分类(CrisisMMD)。
- ScienceQA:包含21,208个精心策划的例子,涵盖自然科学、社会科学和形式科学三个核心领域。
- CrisisMMD:包含约35,000条社交媒体帖子,包含视觉和文本内容,适用于零样本适应模型的评估。
- 实现细节:使用DeepSeek-R1-70B进行动态图构建,并通过Qwen2.5-7B的参数适应框架优化LightRAG的混合检索机制。决策精炼阶段使用GPT-4o处理ScienceQA数据集,使用GPT-4分析CrisisMMD数据集。所有多模态推理工作流在单个NVIDIA A800-80GB GPU上运行,支持图神经网络计算和检索增强生成任务的内存优化并行化。
结果与分析
-
ScienceQA上的结果:HM-RAG在ScienceQA数据集上取得了93.73%的平均准确率,超过了之前最好的零样本VLM方法LLaMA-SciTune和GPT-4o,分别提高了4.11%和2.82%。与基于向量、图和网页的基线方法相比,HM-RAG分别提高了12.95%、12.71%和12.13%的绝对准确率。
-
CrisisMMD上的结果:在CrisisMMD数据集上,HM-RAG的平均准确率为58.55%,比最强的基线GPT-4o提高了2.44%,比纯文本变体Qwen2.5-72B提高了3.44%。尽管仅使用了7B参数,但模型规模与性能提升呈非线性关系。
-
定性分析:通过案例研究展示了HM-RAG在处理复杂模式和做出准确选择方面的能力。当多个检索代理都产生错误结果时,决策代理的高层思考能够导出正确答案。
总体结论
这篇论文提出了HM-RAG,一种新颖的分层多代理多模态检索增强生成框架,旨在解决复杂多模态查询处理和知识合成中的挑战。通过在ScienceQA和CrisisMMD基准上的广泛实验,HM-RAG在多模态问答和分类的准确性方面达到了最先进的水平,显著优于所有类别的基线方法。HM-RAG通过有效地解决多模态推理和知识合成中的关键挑战,为各种应用领域的信息检索和生成系统提供了更健壮和适应性强的解决方案。
论文评价
优点与创新
- 分层多智能体架构:HM-RAG提出了一种新颖的分层多智能体框架,通过专门的智能体进行查询分解、多源检索和决策细化,实现了结构化、非结构化和图数据的动态知识合成。
- 模块化设计:该框架将查询处理模块化为专门的智能体组件,便于扩展和高效的多模态检索。
- 多源即插即用检索集成:通过标准化的接口动态组合异构多模态搜索策略,确保了跨不同搜索场景的领域无关适应性和互操作性。
- 专家引导的细化过程:采用专家模型引导的细化过程,通过最小限度的专家监督提高了响应质量,确保操作效率和上下文精度。
- 实验验证:在ScienceQA和CrisisMMD基准数据集上的广泛实验验证了HM-RAG的有效性,取得了最先进的性能。
不足与反思
- 多模态推理和知识合成的关键挑战:尽管HM-RAG在多模态推理和知识合成方面取得了显著进展,但仍需进一步研究和解决这些领域的关键挑战。
- 复杂查询处理的局限性:当前系统在处理需要同时处理向量、图和基于网络的数据库的复杂查询时仍存在局限性,未来需要进一步优化。
- 实时信息检索的效率:虽然Web检索代理在实时信息检索方面表现出色,但在处理大规模数据和高并发请求时仍需进一步提高效率。
关键问题及回答
问题1:HM-RAG框架中的分解代理是如何工作的?它如何处理复杂的多意图用户查询?
分解代理是HM-RAG框架中的一个关键组件,旨在将复杂的多意图用户查询分解为连贯且可执行的子任务。具体来说,分解代理通过以下步骤工作:
- 分解必要性判断:首先,分解代理使用一个二进制决策提示,指示大型语言模型(LLM)将输入问题分类为单意图或多意图。如果输出是多意图,查询将进入分解阶段;否则,直接返回原问题。
- 意图分解:接下来,LLM根据查询的意图将其分解为候选子问题。具体来说,LLM使用一个结构化提示:“根据其意图,将原始问题的推理步骤分解为2到3个简单且逻辑上相连的子问题,同时保留原始问题中的关键词。”
通过这种层次化解析机制,分解代理能够识别用户查询的底层结构并将其分解为原子单元,每个单元针对特定的数据模态或检索任务。这种方法显著提高了系统处理复杂查询的能力。
问题2:HM-RAG框架中的多源即插即用检索代理是如何实现异构多模态搜索策略的?
HM-RAG框架通过一个模块化的多代理检索框架实现异构多模态搜索策略。该框架包括三个专门的检索代理:向量检索代理、图检索代理和网页检索代理。每个代理都通过标准化接口进行连接,确保系统在不同数据源之间的灵活性和高效性。
- 向量检索代理:用于细粒度信息检索,通过计算查询的语义嵌入并使用余弦相似度度量文档与查询的相似性,检索最相关的文档片段。然后,语言模型在检索到的上下文中生成答案。
- 图检索代理:利用LightRAG的图遍历能力,解析多跳语义查询。通过动态检索实体和关系,构建上下文感知的子图,并使用双向知识增强框架进行跨模态推理。
- 网页检索代理:通过Google Search API获取实时信息,适用于需要最新数据的任务。API返回的结构化结果包括标题、摘要、URL和位置排名元数据。
这种模块化设计不仅增强了系统的灵活性,还确保了任务特定的优化目标,使得框架能够适应各种应用和数据模态。
问题3:HM-RAG框架中的决策代理是如何通过一致性投票和专家模型精炼来提高答案质量的?
决策代理是HM-RAG框架中的另一个关键组件,负责评估和精炼来自不同检索代理的答案。具体过程如下:
- 一致性投票:决策代理使用ROUGE-L和BLEU指标评估向量、图和网页检索系统生成的答案的语义一致性。首先,为每个答案生成摘要,然后计算摘要之间的相似度。如果答案相似度超过预定阈值,则使用轻量级语言模型进行最终答案的精炼;否则,进入下一步。
- 专家模型精炼:对于相似度低于阈值的答案,决策代理使用大型语言模型(LLM)、多模态LLM或基于Cot的语言模型进行综合。这些模型处理原始查询和检索到的证据,生成最终的精炼答案。
通过这种一致性投票和专家模型精炼的方法,决策代理能够显著提高答案的质量,确保生成的答案既具有上下文一致性,又具有事实准确性。



















 2067
2067

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











