







🧠 向所有学习者致敬!
“学习不是装满一桶水,而是点燃一把火。” —— 叶芝
我的博客主页: https://lizheng.blog.csdn.net
🌐 欢迎点击加入AI人工智能社区!
🚀 让我们一起努力,共创AI未来! 🚀
文章目录
1. 引言:什么是强化学习?
强化学习(RL)是机器学习中一个令人着迷的领域,专注于训练智能代理在环境中做出最优的决策序列,以实现特定的目标。与监督学习(我们有标记数据)或无监督学习(我们在数据中寻找模式)不同,RL代理通过试错来学习。
1.1 类比:通过试错学习
想象一下你如何训练一只狗坐下。
- 狗就是代理。
- 房间和你的指令构成了环境。
- 狗站着或坐着就是它的状态。
- 狗选择坐下或站着就是它的动作。
- 如果狗在你说"坐下"时坐下了,你给它一个奖励(正向奖励)。
- 如果它没有坐下,你可能不给奖励或给予轻微的负面信号(负向奖励)。
- 随着时间的推移,狗学会了一个策略:“当我的主人说’坐下’时,'坐下’这个动作通常能带来奖励(好的奖励),所以我应该这样做。”
强化学习的工作原理类似,但通常在更复杂的场景中。
1.2 核心组件
让我们正式定义关键部分:
1.2.1 代理
我们正在训练的实体。它感知环境的状态并决定采取什么动作。
(我们的例子:一个在网格上决定移动方向的简单程序。)
1.2.2 环境
代理与之交互的外部系统。它定义了规则、物理特性和动作的结果。
(我们的例子:网格、墙壁、目标位置,以及动作如何改变代理的位置。)
1.2.3 状态( s s s)
在特定时刻环境的完整描述。代理使用状态来决定下一个动作。
(我们的例子:代理的(行, 列)坐标。)
1.2.4 动作( a a a)
代理可以做出的可能移动或决定之一。
(我们的例子:向上、向下、向左或向右移动。)
1.2.5 奖励( r r r)
在状态
s
s
s中执行动作
a
a
a并转换到状态
s
′
s'
s′后,从环境获得的标量反馈信号。它表示在该状态下采取的动作的即时可取性。
(我们的例子:根据移动的结果,+10、-1或-0.1。)
1.2.6 策略( π \pi π)
代理的策略。它定义了代理如何根据状态选择动作。它可以是确定性的(对某个状态总是选择相同的动作)或随机的(基于概率选择动作)。
(我们的例子:基于记住哪些动作从某个状态产生了好的即时奖励的
ϵ
\epsilon
ϵ-贪婪策略。)
1.2.7 回合
从起始状态到达到终止状态或超过时间限制的完整代理-环境交互序列。
(我们的例子:从(0,0)到(9,9)导航网格的完整尝试。)
1.2.8 目标
最终目标通常是最大化回报,即在一个回合或可能是无限时间范围内的折扣奖励的累积和。
回报
=
∑
t
=
0
T
γ
t
r
t
+
1
\text{回报} = \sum_{t=0}^{T} \gamma^t r_{t+1}
回报=∑t=0Tγtrt+1,其中
γ
\gamma
γ是折扣因子(0到1),它优先考虑即时奖励而不是遥远的未来奖励。
(我们的例子:通过快速到达目标并避开墙壁来获得最高可能的分数。)
1.3 代理-环境交互循环
强化学习的核心过程遵循这个循环:
- 代理从环境观察当前状态 s t s_t st。
- 基于 s t s_t st,代理根据其策略 π \pi π选择动作 a t a_t at。
- 代理执行动作 a t a_t at。
- 环境转换到新状态 s t + 1 s_{t+1} st+1。
- 环境向代理提供奖励 r t r_t rt。
- 代理使用经验 ( s t , a t , r t , s t + 1 ) (s_t, a_t, r_t, s_{t+1}) (st,at,rt,st+1)来更新其知识或策略(这是"学习"步骤)。
- 循环从新状态 s t + 1 s_{t+1} st+1重复。
2. 任务:简单的网格世界
2.1 环境设置
我们将使用一个10x10的网格。代理从(0,0)开始,需要到达(9,9)。这个简单的设置让我们能够清晰地看到状态、动作及其后果。
2.2 状态、动作、奖励的定义
- 状态: 代理的
(行, 列)元组。 - 动作: 4个离散动作:0(上)、1(下)、2(左)、3(右)。
- 转换: 确定性的。从
(r, c)采取动作’上’会到达(r-1, c),除非r=0(墙)。 - 奖励:
- +10:到达目标
(9, 9)。 - -1:撞到墙(移出网格)。
- -0.1:采取任何其他步骤。
- +10:到达目标
- 回合结束: 到达目标或超过步数限制。
3. 我们的简单"学习"代理:MemoryBot
3.1 代理的目标与真正的RL目标
真正的RL代理旨在最大化累积折扣奖励。我们的简单’MemoryBot’代理将有一个更简单的目标:它将尝试选择在过去从当前状态导致高平均即时奖励的动作。它没有未来奖励或折扣的概念。这突出了基本记忆和真正的基于价值的学习之间的区别。
3.2 代理的内存结构
我们将使用嵌套字典:memory[state][action] -> list_of_rewards。
state是一个(行, 列)元组。action是一个整数(0-3)。list_of_rewards存储在该state采取该action后立即获得的所有即时奖励。
3.3 代理的简单策略(策略)
基于平均即时奖励的 ϵ \epsilon ϵ-贪婪:
- 生成一个0到1之间的随机数
rand。 - 如果
rand < epsilon:选择一个随机动作(0、1、2或3)。 - 如果
rand >= epsilon:
a. 对于当前状态s,计算每个可能动作a的平均即时奖励:AvgR(s, a) = mean(memory[s][a])(将空列表视为平均值为0或很小的负数)。
b. 找到具有最高AvgR(s, a*)的动作a*。
c. 随机选择其中一个最佳动作(以打破平局)。
3.4 代理的"学习"过程(内存更新)
这只是记账:
- 在状态
s
t
s_t
st中采取动作
a
t
a_t
at并获得奖励
r
t
r_t
rt后,简单地将
r
t
r_t
rt附加到列表
memory[s_t][a_t]中。
4. 设置模拟环境
4.1 导入库
导入必要的Python库。
# 导入必要的库
import numpy as np # 用于数值运算(如平均值)
import matplotlib.pyplot as plt # 用于绘制结果
import random # 用于随机选择(探索、打破平局)
from collections import defaultdict # 方便创建嵌套字典用于内存
from typing import Tuple, Dict, List, DefaultDict, Any # 用于类型提示
# 设置随机种子以确保可重复性
seed: int = 42
random.seed(seed)
np.random.seed(seed)
# 启用Jupyter Notebook的内联绘图
%matplotlib inline
print("库已导入,种子已设置。")
4.2 环境类实现
定义网格世界环境类。我们添加注释解释每个部分。
class GridEnvironmentSimple:
"""
用于演示RL概念的基本网格世界环境。
状态是(行, 列)元组。动作是整数0-3。
"""
def __init__(self, rows: int = 10, cols: int = 10) -> None:
""" 初始化网格环境。 """
self.rows: int = rows # 行数
self.cols: int = cols # 列数
self.start_state: Tuple[int, int] = (0, 0) # 代理从左上角开始
self.goal_state: Tuple[int, int] = (rows - 1, cols - 1) # 目标在右下角
self.state: Tuple[int, int] = self.start_state # 代理的当前位置
# 定义动作映射:0=上, 1=下, 2=左, 3=右
self.action_map: Dict[int, Tuple[int, int]] = {
0: (-1, 0), 1: (1, 0), 2: (0, -1), 3: (0, 1)
}
self.actions: List[int] = list(self.action_map.keys()) # 可能动作索引的列表
self.action_dim: int = len(self.actions) # 可能动作的数量
print(f"[环境] 初始化了{rows}x{cols}网格。起点:{self.start_state},目标:{self.goal_state}")
def reset(self) -> Tuple[int, int]:
""" 将代理重置到起始状态。返回初始状态。 """
self.state = self.start_state
# print(f"[环境] 重置到状态:{self.state}") # 调试
return self.state
def step(self, action: int) -> Tuple[Tuple[int, int], float, bool]:
"""
执行动作,更新状态,并返回结果。
返回:
(下一个状态, 奖励, 是否结束)
"""
# 如果已经在目标处,回合实际上结束(返回当前状态,0奖励,True)
if self.state == self.goal_state:
# print(f"[环境] 已经在目标{self.state}。不采取动作。") # 调试
return self.state, 0.0, True
# 从动作映射获取状态变化
dr, dc = self.action_map[action]
current_row, current_col = self.state
# 计算潜在的新位置
next_row, next_col = current_row + dr, current_col + dc
# 默认奖励是步长成本
reward: float = -0.1
# 检查边界(墙)
if not (0 <= next_row < self.rows and 0 <= next_col < self.cols):
# 撞墙:状态不变,奖励是惩罚
next_state_tuple = self.state
reward = -1.0
# print(f"[环境] 在{self.state}尝试动作{action}时撞墙。下一个状态:{next_state_tuple},奖励:{reward}") # 调试
else:
# 有效移动:更新内部状态
self.state = (next_row, next_col)
next_state_tuple = self.state
# print(f"[环境] 从{(current_row, current_col)}通过动作{action}移动到{self.state}。奖励:{reward}") # 调试
# 检查新状态是否是目标
done: bool = (self.state == self.goal_state)
if done:
reward = 10.0 # 分配目标奖励
# print(f"[环境] 到达目标!状态:{self.state}。奖励:{reward},结束:{done}") # 调试
# 返回结果:新状态,奖励,结束标志
return next_state_tuple, reward, done
def get_action_space_size(self) -> int:
""" 返回可能动作的数量。 """
return self.action_dim
4.3 实例化环境
创建我们的网格世界实例。
# 创建环境实例
simple_env: GridEnvironmentSimple = GridEnvironmentSimple(rows=10, cols=10)
# 从环境获取可能动作的数量
n_actions_simple: int = simple_env.get_action_space_size()
5. 实现简单代理的逻辑
实现内存、动作选择和学习(内存更新)的函数。
5.1 初始化代理内存
我们使用defaultdict来方便使用。如果我们访问memory[state]而它不存在,它会自动创建一个新的defaultdict(list)。如果我们访问memory[state][action]而它不存在,它会自动创建一个空的list。
# 代理的内存:存储即时奖励的列表。
# 键:状态元组(r, c)
# 值:另一个defaultdict,其中键:动作索引(0-3),值:奖励列表[float]
agent_memory: DefaultDict[Tuple[int, int], DefaultDict[int, List[float]]] = \
defaultdict(lambda: defaultdict(list))
print("代理内存已初始化。")
print(f"未访问状态(0,1)的动作0的内存访问示例:{agent_memory[(0,1)][0]}")
5.2 选择动作(基于即时奖励的Epsilon-贪婪)
这个函数实现了代理的策略 π ( a ∣ s ) \pi(a|s) π(a∣s)。
def choose_simple_action(state: Tuple[int, int],
memory: DefaultDict[Tuple[int, int], DefaultDict[int, List[float]]],
epsilon: float,
n_actions: int) -> int:
"""
使用基于内存中平均即时奖励的epsilon-贪婪选择动作。
"""
# 决定是探索还是利用
if random.random() < epsilon:
# --- 探索 ---
action: int = random.randrange(n_actions) # 选择一个随机动作索引(0、1、2或3)
# print(f" -> 探索:随机动作 = {action}") # 调试
return action
else:
# --- 利用 ---
# 计算从当前状态每个可能动作的平均奖励
avg_rewards_for_actions: List[float] = []
state_action_memory: DefaultDict[int, List[float]] = memory[state]
for a in range(n_actions):
rewards_list: List[float] = state_action_memory[a]
if not rewards_list: # 如果我们没有这个状态-动作对的记忆
avg_reward: float = 0.0 # 分配一个默认值(可以是负数)
else:
avg_reward = np.mean(rewards_list) # 计算记住的奖励的平均值
avg_rewards_for_actions.append(avg_reward)
# 找到所有动作中最高的平均奖励
max_avg_reward: float = max(avg_rewards_for_actions)
# 获取达到这个最大平均奖励的所有动作的列表
best_actions: List[int] = [a for a, avg_r in enumerate(avg_rewards_for_actions) if avg_r == max_avg_reward]
# 从最佳动作中随机选择一个动作(打破平局)
action = random.choice(best_actions)
# print(f" -> 利用:平均奖励={avg_rewards_for_actions},最佳动作={best_actions},选择={action}") # 调试
return action
5.3 更新代理内存
这个函数代表代理的简单"学习"过程。
def update_simple_memory(memory: DefaultDict[Tuple[int, int], DefaultDict[int, List[float]]],
state: Tuple[int, int],
action: int,
reward: float) -> None:
"""
通过添加收到的即时奖励来更新代理的内存。
"""
# 访问特定状态-动作对的奖励列表并附加新奖励
memory[state][action].append(reward)
# print(f" -> 内存已更新:状态={state},动作={action},添加奖励={reward:.1f},动作的新内存:{memory[state][action]}") # 调试
6. 运行模拟循环
我们模拟代理在多个回合中与环境交互。
6.1 模拟参数
# 模拟超参数
NUM_EPISODES: int = 1000
MAX_STEPS_PER_EPISODE: int = 150
EPSILON_START_SIM: float = 1.0 # 从完全随机探索开始
EPSILON_END_SIM: float = 0.01 # 保持一小部分探索机会
EPSILON_DECAY_SIM: float = 0.99 # 每个回合的衰减率(例如,0.99意味着epsilon变为其前一个值的99%)
PRINT_EVERY_N_EPISODES: int = 100 # 多久打印一次进度
6.2 运行初始化
# 为模拟运行创建环境实例
env_run: GridEnvironmentSimple = GridEnvironmentSimple(rows=10, cols=10)
n_actions_run: int = env_run.get_action_space_size()
# 为这次运行初始化代理内存
agent_memory_run: DefaultDict[Tuple[int, int], DefaultDict[int, List[float]]] = \
defaultdict(lambda: defaultdict(list))
# 初始化列表以存储绘图结果
simple_episode_rewards: List[float] = []
simple_episode_lengths: List[int] = []
simple_episode_epsilons: List[float] = []
# 为这次运行初始化探索率
current_epsilon_run: float = EPSILON_START_SIM
print("模拟设置完成。")
6.3 主模拟循环(详细步骤)
代理回合式地与环境交互。
print(f"开始简单代理模拟,共{NUM_EPISODES}个回合...")
# 循环指定的回合数
for i_episode in range(1, NUM_EPISODES + 1):
# --- 回合开始 ---
# 重置环境以获取起始状态
current_state: Tuple[int, int] = env_run.reset()
# 重置回合特定的跟踪器
current_episode_reward: float = 0.0
# print(f"\n--- 回合 {i_episode} 开始 | Epsilon: {current_epsilon_run:.3f} ---") # 调试
# 循环每个回合内的每个步骤,直到达到最大允许步数
for t in range(MAX_STEPS_PER_EPISODE):
# print(f" 步骤 {t+1}: 状态={current_state}") # 调试
# 1. 代理选择一个动作
action: int = choose_simple_action(
current_state,
agent_memory_run,
current_epsilon_run,
n_actions_run
)
# 2. 代理在环境中执行动作
next_state, reward, done = env_run.step(action)
# print(f" 动作={action},奖励={reward:.1f},下一个状态={next_state},结束={done}") # 调试
# 3. 代理更新其内存(从即时奖励中学习)
update_simple_memory(agent_memory_run, current_state, action, reward)
# 更新下一个时间步的状态
current_state = next_state
# 将收到的奖励添加到回合的总奖励中
current_episode_reward += reward
# 检查回合是否终止(到达目标或其他条件)
if done:
# print(f" 回合 {i_episode} 在第{t+1}步结束。到达目标。") # 调试
break # 停止当前回合
# --- 回合结束 ---
# 如果循环因为达到MAX_STEPS而结束
# if not done:
# print(f" 回合 {i_episode} 在第{t+1}步结束。达到最大步数。") # 调试
# 存储这个回合的结果
simple_episode_rewards.append(current_episode_reward)
simple_episode_lengths.append(t + 1) # t是最后一个步骤索引,所以长度是t+1
simple_episode_epsilons.append(current_epsilon_run)
# 为下一个回合衰减epsilon
current_epsilon_run = max(EPSILON_END_SIM, current_epsilon_run * EPSILON_DECAY_SIM)
# 定期打印进度摘要
if i_episode % PRINT_EVERY_N_EPISODES == 0:
avg_reward = np.mean(simple_episode_rewards[-PRINT_EVERY_N_EPISODES:])
avg_length = np.mean(simple_episode_lengths[-PRINT_EVERY_N_EPISODES:])
print(f"回合 {i_episode}/{NUM_EPISODES} | 平均奖励(最近{PRINT_EVERY_N_EPISODES}个):{avg_reward:.2f} | 平均长度:{avg_length:.1f} | Epsilon: {current_epsilon_run:.3f}")
print(f"\n简单代理模拟在{NUM_EPISODES}个回合后结束。")
7. 可视化结果
绘图有助于理解代理的性能如何随时间变化。
7.1 基本性能指标
7.1.1 回合奖励随时间变化
# 绘制回合奖励
plt.figure(figsize=(20, 3))
plt.plot(simple_episode_rewards, label='每回合奖励', alpha=0.7)
plt.title('简单代理:每回合总奖励')
plt.xlabel('回合')
plt.ylabel('总奖励')
plt.grid(True)
# 计算并绘制移动平均
window_size = 50
if len(simple_episode_rewards) >= window_size:
# 使用numpy的convolve进行移动平均
rewards_ma = np.convolve(simple_episode_rewards, np.ones(window_size)/window_size, mode='valid')
# 调整移动平均图的x轴
plt.plot(np.arange(len(rewards_ma)) + window_size - 1, rewards_ma,
label=f'{window_size}回合移动平均', color='orange', linewidth=2)
plt.legend()
plt.show()

解释: 这个图显示了代理在每个回合中收集的总奖励。由于探索和随机性,预期会看到一条噪声线。橙色线(移动平均)平滑了这些波动,显示了总体趋势。如果代理学习有效(即使使用其简单策略),我们期望移动平均线呈上升趋势,表明它随时间获得更高的分数(更频繁或更快地到达目标,更好地避开墙壁)。
7.1.2 回合长度随时间变化
# 绘制回合长度
plt.figure(figsize=(20, 3))
plt.plot(simple_episode_lengths, label='每回合步数', alpha=0.7)
plt.title('简单代理:每回合步数')
plt.xlabel('回合')
plt.ylabel('步数')
plt.grid(True)
# 计算并绘制移动平均
window_size = 50
if len(simple_episode_lengths) >= window_size:
lengths_ma = np.convolve(simple_episode_lengths, np.ones(window_size)/window_size, mode='valid')
plt.plot(np.arange(len(lengths_ma)) + window_size - 1, lengths_ma,
label=f'{window_size}回合移动平均', color='orange', linewidth=2)
plt.legend()
plt.show()

解释: 这个图显示了代理完成每个回合所需的步数。如果代理学会了更有效地到达目标,步数应该随时间减少。移动平均线的下降趋势表明效率提高。
7.1.3 Epsilon衰减
# 绘制epsilon衰减
plt.figure(figsize=(20, 3))
plt.plot(simple_episode_epsilons)
plt.title('简单代理:Epsilon随回合衰减')
plt.xlabel('回合')
plt.ylabel('Epsilon值')
plt.grid(True)
plt.show()

解释: 这个图确认了探索率( ϵ \epsilon ϵ)如何根据我们定义的衰减计划随回合减少。它开始时很高(鼓励探索),然后逐渐降低(鼓励利用学到的知识)。
7.2 分析代理的知识和行为
让我们深入看看代理学到了什么以及它如何行为。
7.2.1 状态访问频率
这显示了代理最常探索网格的哪些部分。
def plot_state_visitation(memory: DefaultDict[Tuple[int, int], DefaultDict[int, List[float]]],
env: GridEnvironmentSimple) -> None:
""" 绘制状态访问计数的热图。 """
rows = env.rows
cols = env.cols
visit_counts = np.zeros((rows, cols))
print("计算状态访问计数...")
for state, action_dict in memory.items():
r, c = state
total_visits_to_state = sum(len(rewards) for rewards in action_dict.values())
if 0 <= r < rows and 0 <= c < cols:
visit_counts[r, c] = total_visits_to_state
fig, ax = plt.subplots(figsize=(cols * 0.8, rows * 0.8))
# 如果计数变化很大,使用对数刻度,否则使用线性刻度
if np.max(visit_counts) > 10 * np.median(visit_counts[visit_counts > 0]):
im = ax.imshow(visit_counts + 1e-9, cmap='hot', origin='lower', norm=plt.cm.colors.LogNorm())
title = "状态访问计数(对数刻度)"
else:
im = ax.imshow(visit_counts, cmap='hot', origin='lower')
title = "状态访问计数(线性刻度)"
# 添加文本注释(可选,可能会显得杂乱)
# for r in range(rows):
# for c in range(cols):
# ax.text(c, r, f"{int(visit_counts[r, c])}", ha="center", va="center", color="w" if visit_counts[r,c] > np.max(visit_counts)/2 else "black")
start_r, start_c = env.start_state
goal_r, goal_c = env.goal_state
ax.text(start_c, start_r, 'S', ha='center', va='center', color='cyan', weight='bold')
ax.text(goal_c, goal_r, 'G', ha='center', va='center', color='lime', weight='bold')
ax.set_xticks(np.arange(cols))
ax.set_yticks(np.arange(rows))
ax.set_xticklabels(np.arange(cols))
ax.set_yticklabels(np.arange(rows))
ax.set_xticks(np.arange(-.5, cols, 1), minor=True)
ax.set_yticks(np.arange(-.5, rows, 1), minor=True)
ax.grid(which='minor', color='black', linestyle='-', linewidth=0.5)
ax.set_title(title)
fig.colorbar(im)
plt.show()
# 绘制状态访问
plot_state_visitation(agent_memory_run, env_run)
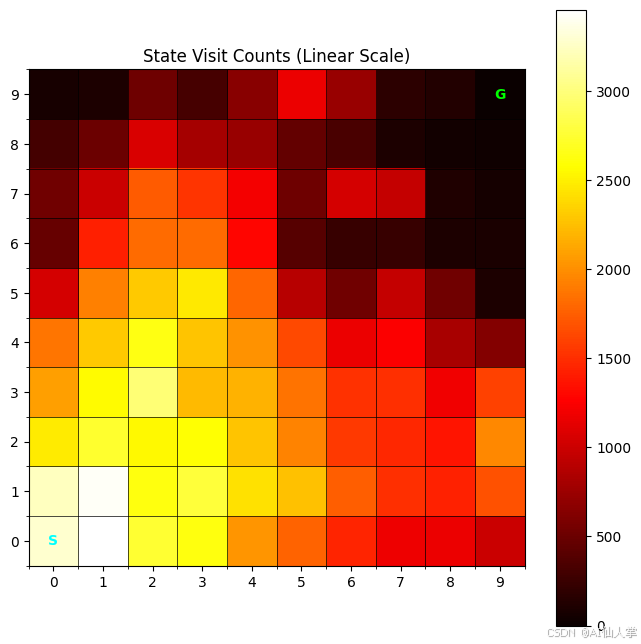
解释: 这个热图显示了代理在训练期间最频繁访问的网格单元。颜色越亮表示访问次数越多。我们可以看到代理倾向于探索的路径。理想情况下,它应该显示显著的探索,特别是在早期,并且在训练后期可能沿着通向目标的路径有更高的集中度。
7.2.2 平均即时奖励图
这显示了代理对每个状态的最佳即时结果的估计。
def plot_average_rewards_grid(memory: DefaultDict[Tuple[int, int], DefaultDict[int, List[float]]],
env: GridEnvironmentSimple) -> None:
""" 绘制每个状态最佳动作的平均即时奖励。 """
rows = env.rows
cols = env.cols
avg_reward_grid = np.full((rows, cols), -np.inf) # 用负无穷初始化
print("计算平均奖励用于可视化...")
for r in range(rows):
for c in range(cols):
state = (r, c)
if state == env.goal_state:
avg_reward_grid[r, c] = env.step(0)[1] # 使用目标奖励(例如,10)
continue
action_values = []
state_memory = memory[state]
has_experience = False
for a in range(env.get_action_space_size()):
rewards = state_memory[a]
if rewards:
has_experience = True
avg_reward = np.mean(rewards)
action_values.append(avg_reward)
else:
action_values.append(-np.inf) # 表示未尝试的动作
if not has_experience:
avg_reward_grid[r, c] = -5 # 为未访问的状态分配一个明显的低值
else:
best_avg_reward = max(action_values)
if best_avg_reward == -np.inf:
avg_reward_grid[r, c] = -1 # 如果状态被访问过,这不应该发生
else:
avg_reward_grid[r, c] = best_avg_reward
# 修复已弃用的get_cmap函数
cmap = plt.cm.get_cmap('viridis', 5) # 5种不同的颜色
bounds = [-6, -1.5, -0.5, -0.05, 0.1, 11] # 定义颜色的边界
norm = plt.cm.colors.BoundaryNorm(bounds, cmap.N)
fig, ax = plt.subplots(figsize=(cols * 0.8, rows * 0.8))
im = ax.imshow(avg_reward_grid, cmap=cmap, norm=norm, origin='lower')
# 添加文本注释
for r in range(rows):
for c in range(cols):
val = avg_reward_grid[r, c]
text_val = f"{val:.1f}" if val > -np.inf else "N/A"
color = "white" if abs(val) > 1 else "black"
if val == -5: color = "grey"
ax.text(c, r, text_val, ha="center", va="center", color=color, fontsize=7)
start_r, start_c = env.start_state
goal_r, goal_c = env.goal_state
ax.text(start_c, start_r, 'S', ha='center', va='center', color='red', weight='bold')
ax.text(goal_c, goal_r, 'G', ha='center', va='center', color='white', weight='bold')
ax.set_xticks(np.arange(cols))
ax.set_yticks(np.arange(rows))
ax.set_xticklabels(np.arange(cols))
ax.set_yticklabels(np.arange(rows))
ax.set_xticks(np.arange(-.5, cols, 1), minor=True)
ax.set_yticks(np.arange(-.5, rows, 1), minor=True)
ax.grid(which='minor', color='black', linestyle='-', linewidth=0.5)
ax.set_title("简单代理:最佳动作的平均即时奖励")
# 修复颜色条刻度 - 创建适当的值列表
ticks = [b + 0.5 for b in bounds[:-1]]
fig.colorbar(im, ticks=ticks, format="%.1f")
plt.show()
# 绘制学习到的平均奖励
plot_average_rewards_grid(agent_memory_run, env_run)
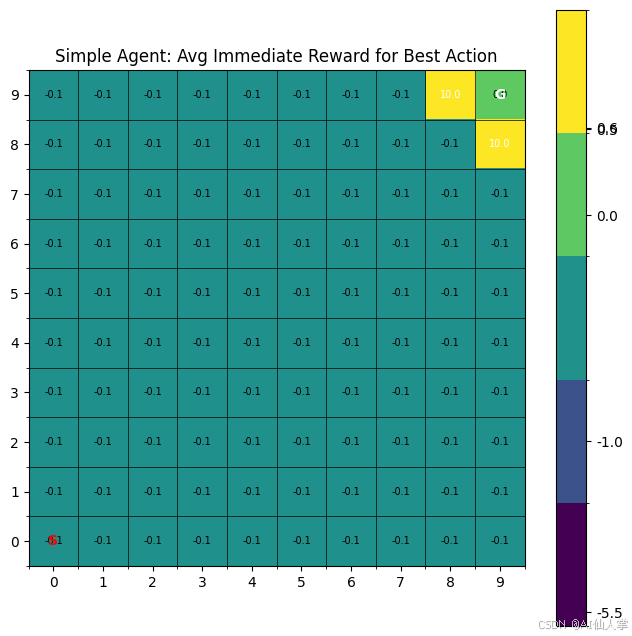
解释: 这个热图显示了代理仅基于从该状态获得的最佳即时奖励对状态的偏好。高值(亮色,接近+10)应该出现在目标处。如果代理经常撞到墙,靠近墙的状态可能显示较低的值(暗色,接近-1)。远离墙或目标的状态可能聚集在步长成本(-0.1)附近。'N/A’或明显的低值表示代理从未(或很少)从该状态选择动作。
7.2.3 派生的贪婪策略可视化
这显示了如果代理基于其内存贪婪地行动(epsilon=0),它会在每个状态采取的动作。
def plot_simple_policy_grid(memory: DefaultDict[Tuple[int, int], DefaultDict[int, List[float]]],
env: GridEnvironmentSimple) -> None:
""" 绘制从代理内存派生的贪婪策略。 """
rows = env.rows
cols = env.cols
policy_grid: np.ndarray = np.empty((rows, cols), dtype=str)
# 动作符号:0: 上, 1: 下, 2: 左, 3: 右
action_symbols: Dict[int, str] = {0: '↑', 1: '↓', 2: '←', 3: '→'}
fig, ax = plt.subplots(figsize=(cols * 0.7, rows * 0.7)) # 调整大小
print("从内存计算贪婪策略...")
for r in range(rows):
for c in range(cols):
state = (r, c)
# 标记目标状态
if state == env.goal_state:
symbol = 'G'
color = 'green'
else:
# 基于内存获取贪婪动作(epsilon=0)
best_action = choose_simple_action(state, memory, epsilon=0.0, n_actions=env.action_dim)
# 检查状态是否有任何记录的经验
state_memory = memory[state]
has_experience = any(state_memory[a] for a in range(env.action_dim))
if not has_experience:
symbol = '.' # 标记未访问/未探索的状态
color = 'grey'
else:
symbol = action_symbols[best_action]
color = 'black'
policy_grid[r, c] = symbol
ax.text(c, r, symbol, ha='center', va='center', color=color, fontsize=10,
weight='bold' if symbol == 'G' else 'normal')
# 绘图格式
ax.matshow(np.zeros((rows, cols)), cmap='Greys', alpha=0.1) # 浅色背景网格
ax.set_xticks(np.arange(-.5, cols, 1), minor=True)
ax.set_yticks(np.arange(-.5, rows, 1), minor=True)
ax.grid(which='minor', color='black', linestyle='-', linewidth=1)
ax.set_xticks([]) # 隐藏轴刻度
ax.set_yticks([])
ax.set_title("简单代理:派生的贪婪策略(基于平均即时奖励)")
plt.show()
# 绘制派生的策略
plot_simple_policy_grid(agent_memory_run, env_run)
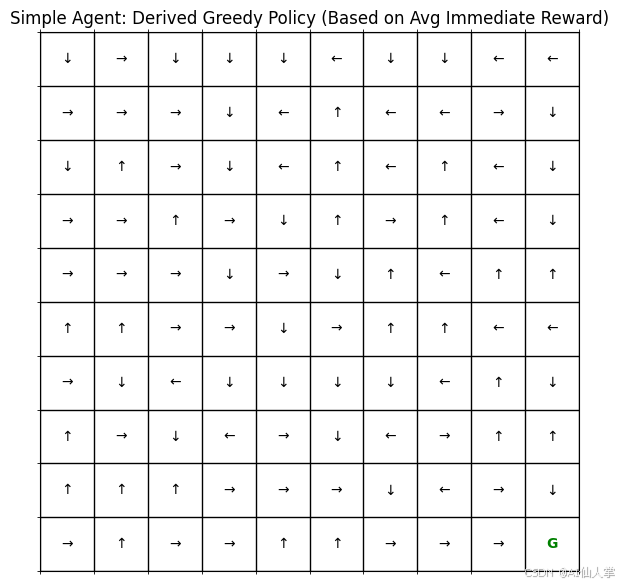
解释: 这个图显示了如果代理基于其内存贪婪地行动(epsilon=0),它会在每个状态采取的动作。箭头表示代理认为在该状态下最佳的动作。灰色点表示代理从未访问过的状态。目标状态用’G’标记。这个可视化帮助我们理解代理学到了什么策略,以及它如何导航环境。
7.2.4 动作选择频率(示例状态)
让我们看看从起始状态(0,0)选择每个动作的频率。
def plot_action_frequency(memory: DefaultDict[Tuple[int, int], DefaultDict[int, List[float]]],
state_to_analyze: Tuple[int, int],
n_actions: int) -> None:
""" 绘制从特定状态选择每个动作的频率的条形图。 """
action_counts = [len(memory[state_to_analyze][a]) for a in range(n_actions)]
action_labels = ['上', '下', '左', '右'] # 假设0=上, 1=下, 2=左, 3=右
plt.figure(figsize=(6, 4))
plt.bar(action_labels, action_counts, color=['lightblue', 'lightcoral', 'lightsalmon', 'lightgreen'])
plt.title(f'从状态{state_to_analyze}的动作频率')
plt.xlabel('动作')
plt.ylabel('选择次数')
plt.grid(axis='y', linestyle='--')
plt.show()
# 绘制起始状态的动作频率
start_state = env_run.start_state
plot_action_frequency(agent_memory_run, start_state, n_actions_run)
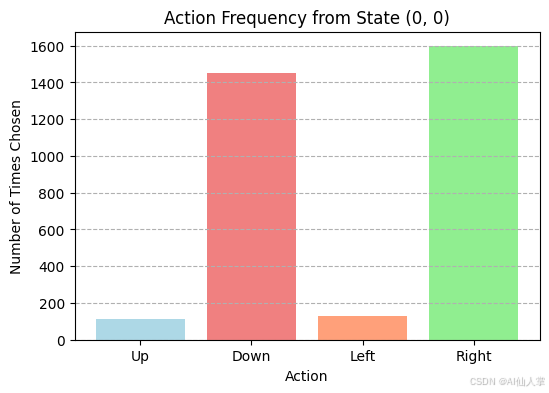
解释: 这个条形图显示了代理在特定状态(这里是起始状态)下选择每个动作的次数。在训练早期(高epsilon值),由于随机探索,各个动作的选择次数可能相似。随着训练进行,如果代理基于即时奖励形成了偏好,某些动作的选择次数可能会显著高于其他动作。
7.2.5 平均奖励的收敛性(示例状态-动作对)
让我们跟踪代理对特定状态-动作对的平均即时奖励的估计如何随时间变化。
def plot_reward_convergence(memory_history: List[DefaultDict[Tuple[int, int], DefaultDict[int, List[float]]]],
state_to_analyze: Tuple[int, int],
action_to_analyze: int) -> None:
""" 绘制特定状态-动作对的运行平均奖励随回合的变化。 """
avg_rewards_over_time = []
total_rewards_so_far = 0.0
count = 0
# 需要重新运行或在训练期间存储内存快照以进行此图。
# 让我们通过从最终内存重新计算来近似(对时间视图不太准确)。
# 更好的方法是在训练期间存储快照或重新计算运行平均值。
# --- 使用最终内存近似 ---
# 这显示了最终分布,而不是收敛路径
rewards_list = memory_history[-1][state_to_analyze][action_to_analyze]
if not rewards_list:
print(f"没有记录状态{state_to_analyze},动作{action_to_analyze}的数据")
return
running_averages = []
current_sum = 0.0
for i, reward in enumerate(rewards_list):
current_sum += reward
running_averages.append(current_sum / (i + 1))
plt.figure(figsize=(10, 5))
plt.plot(running_averages)
plt.title(f'状态{state_to_analyze},动作{action_to_analyze}的即时奖励运行平均')
plt.xlabel('动作被采取的次数')
plt.ylabel('平均即时奖励')
plt.grid(True)
plt.show()
# 我们需要内存快照来绘制真正的收敛性。
# 存储最终内存允许绘制估计分布。
example_state = (1, 1)
example_action = 3 # 右
print(f"\n分析状态={example_state},动作={example_action}的奖励:")
plot_reward_convergence([agent_memory_run], example_state, example_action)
# 此外,让我们绘制该对的接收奖励的直方图
rewards_list_final = agent_memory_run[example_state][example_action]
if rewards_list_final:
plt.figure(figsize=(6, 4))
plt.hist(rewards_list_final, bins=10, density=True, alpha=0.7, color='skyblue')
plt.title(f'状态{example_state},动作{example_action}的奖励直方图')
plt.xlabel('即时奖励')
plt.ylabel('频率')
plt.grid(axis='y', linestyle='--')
plt.show()
else:
print(f"没有记录状态{example_state},动作{action_to_analyze}的数据")
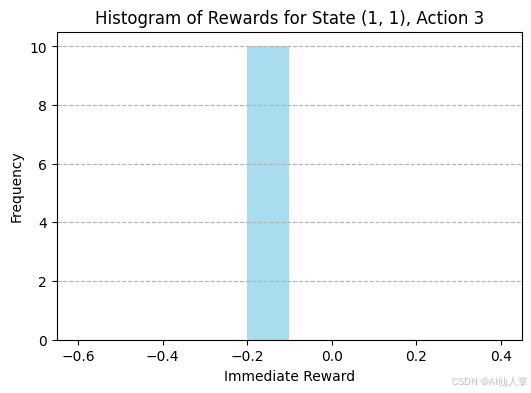
解释: 线图显示了代理对在特定状态((1,1))采取特定动作(右)的平均即时奖励的估计如何随着它更频繁地经历这种情况而变化。理想情况下,这个平均值应该收敛到该状态-动作对的真实预期即时奖励(在这种情况下是-0.1,除非它从该状态直接导致目标或墙)。直方图显示了该对实际接收的奖励分布。在我们的确定性环境中,它应该理想地是-0.1(或-1或+10,如果适用)处的单个条形。
8. 这个简单代理的局限性
这个MemoryBot虽然说明了基本的RL交互循环,但有很大的缺点:
- 没有长期规划: 它只考虑下一个即时奖励。它无法学习做出现在看起来不好(-0.1奖励)但能更快地到达目标(+10奖励)的移动。这是阻止它找到最优路径的根本限制。
- 表格表示: 它需要为每个状态-动作对存储数据。这不适用于具有大或连续状态空间的环境。
- 没有泛化: 学习状态
(1,1)不提供关于类似状态(1,2)的信息。 - 内存效率低: 存储所有收到的奖励可能变得内存密集。像Q学习这样的算法使用运行平均值或学习率来增量更新估计。
9. 结论和下一步
这个详细的笔记本演示了强化学习的基础概念:代理-环境交互循环,状态、动作和奖励的作用,代理策略的概念,以及通过回合学习。我们实现了一个非常简单的代理,‘MemoryBot’,它纯粹通过记住与状态-动作对相关的平均即时奖励来学习。
通过各种可视化——跟踪整体性能(奖励、长度)、探索模式(状态访问、动作频率)和代理学到的知识(平均奖励图、收敛性)——我们观察到即使这种简单的基于记忆的适应也会导致一些行为变化,如基本的避墙。
然而,关键的限制是它无法考虑长期累积奖励,这阻止了它找到真正的最优策略。这促使我们需要更复杂的RL算法:
- Q学习/价值迭代: 学习预期的累积未来奖励( Q ( s , a ) Q(s,a) Q(s,a)或 V ( s ) V(s) V(s)),实现长期规划。
- 深度Q网络(DQN): 使用神经网络近似 Q ( s , a ) Q(s,a) Q(s,a),允许在大/连续状态空间上泛化。
- 策略梯度方法(REINFORCE、A2C、PPO等): 直接学习参数化策略 π ( a ∣ s ) \pi(a|s) π(a∣s),适用于连续动作和随机策略。
- 基于模型的方法(Dyna-Q、PlaNet): 学习环境模型以通过模拟进行规划,通常提高样本效率。
理解这个基本的交互循环和从奖励中学习的概念是探索这些更强大的RL技术的重要基础。



















 475
475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











