






📋📋📋本文目录如下:⛳️⛳️⛳️
目录

1 概述
电机控制几十年来一直是研究和工业领域的一个重要课题,并且已经发明了许多不同的策略,例如PI 控制器和模型预测控制 (MPC) [1]。后一种方法需要系统的精确模型。在此基础上,通过对下一个时间步长进行在线优化来计算下一个控制动作 [2]。在驱动系统中实施 MPC 算法时的典型挑战是由于实时优化要求和工厂模型偏差导致的计算负担,导致瞬态和稳态期间控制性能较差。此外,由于机器学习(ML),尤其是深度神经网络(DNN),近年来许多突破成为可能。一个例子是计算机视觉领域。将 RL 应用于电动机控制是一种新兴的方法 [11]。与 MPC 相比,RL 控制方法不需要在每个步骤中进行在线优化,这通常是计算成本高的。相反,RL-agent 在实际应用中实施之前,会尝试在离线训练阶段找到最佳控制策略 [2]。然而,许多现代 RL 算法是无模型的,不需要模型知识。因此,RL 控制方法不仅可以在模拟中进行训练,还可以在现场应用中进行训练,并针对所有物理和寄生效应以及非线性优化其控制。
本文结构如下: 对 RL 的简要介绍在第 2 节中给出。 而为控制目的建模电驱动器的技术在第 3节中讨论。然后是第4节是算例仿真。 第5节与 DDPG 和级联 PI 控制器的比较。最后是总结。
2 数学模型
通常,电动机可以用微分方程组(ODE 系统)表示,其中机械角速度和电流是电动机的状态。所有变量和电机常数都在表中进行了解释。机械角速度的微分方程为:
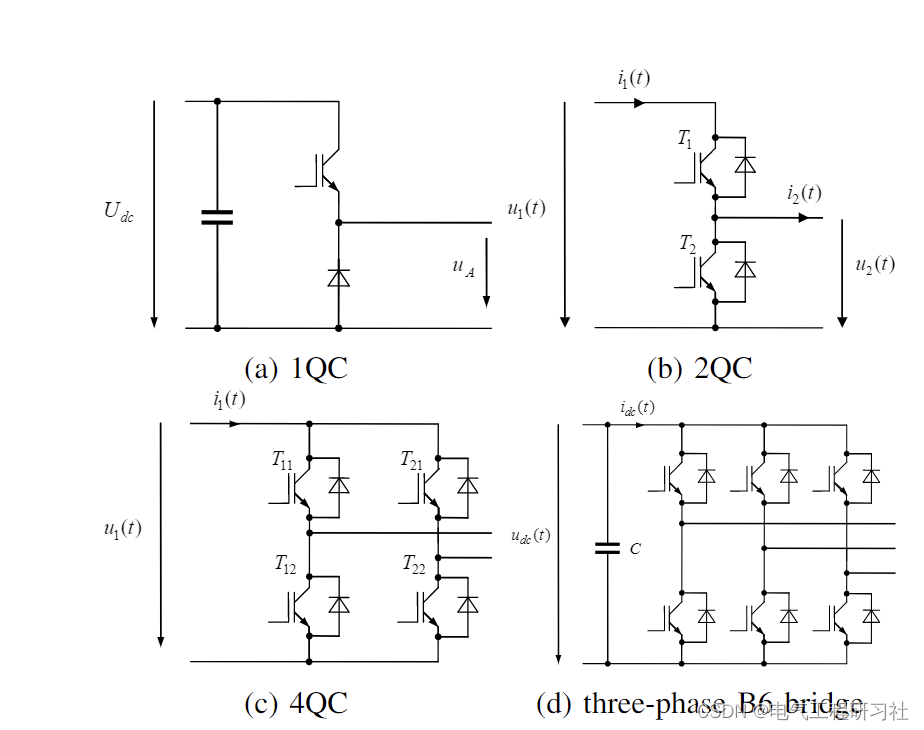
详细数学模型及解释见第4部分。
3 算例仿真及结果
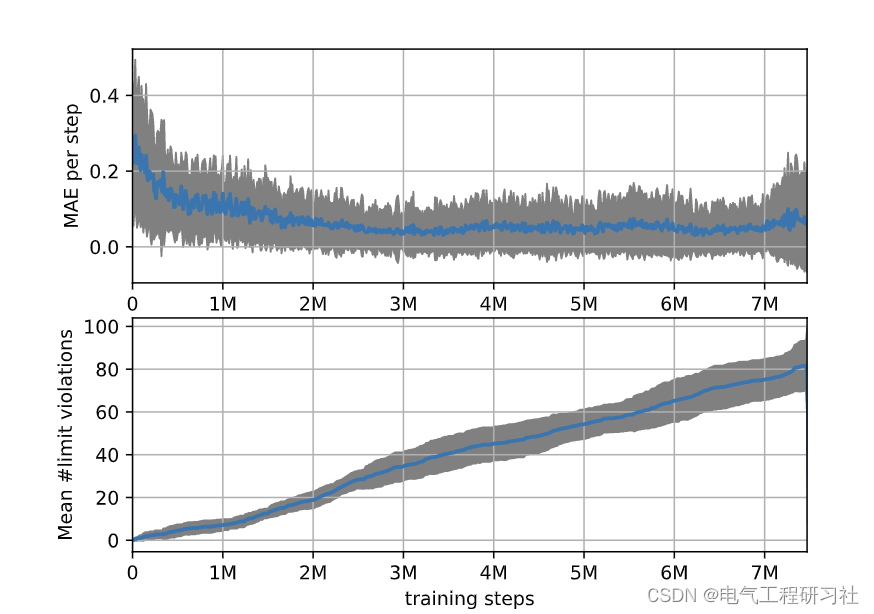
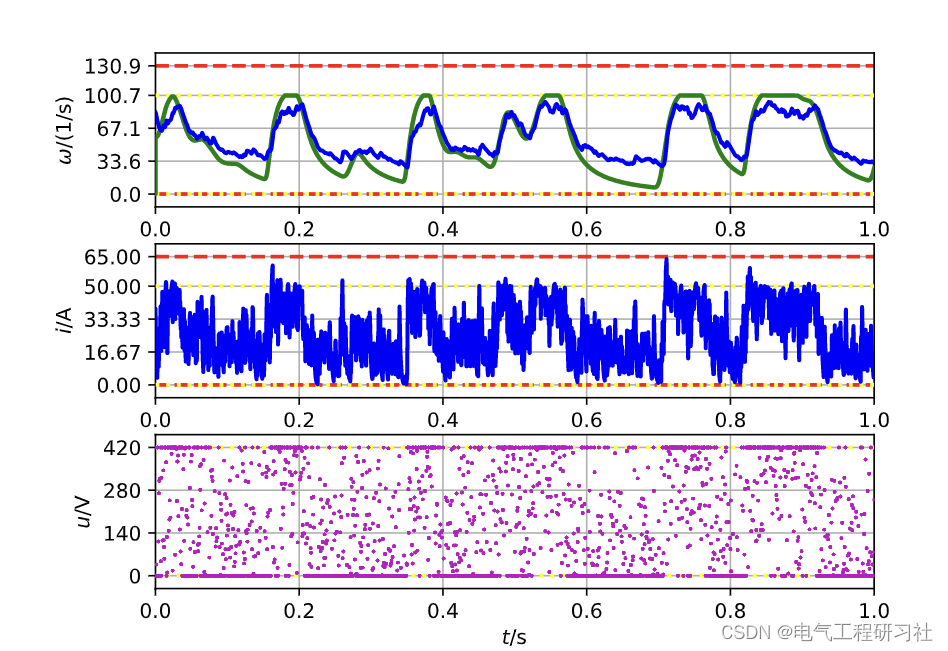
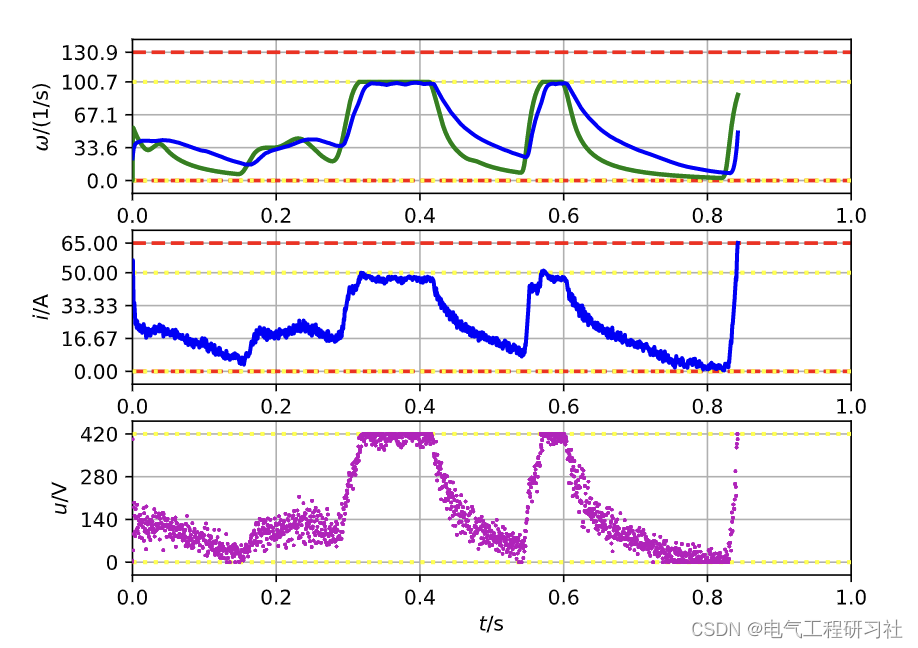
4 总结
本文是基于一种新颖强化学习 (RL) 的电机控制与电力驱动控制研究。
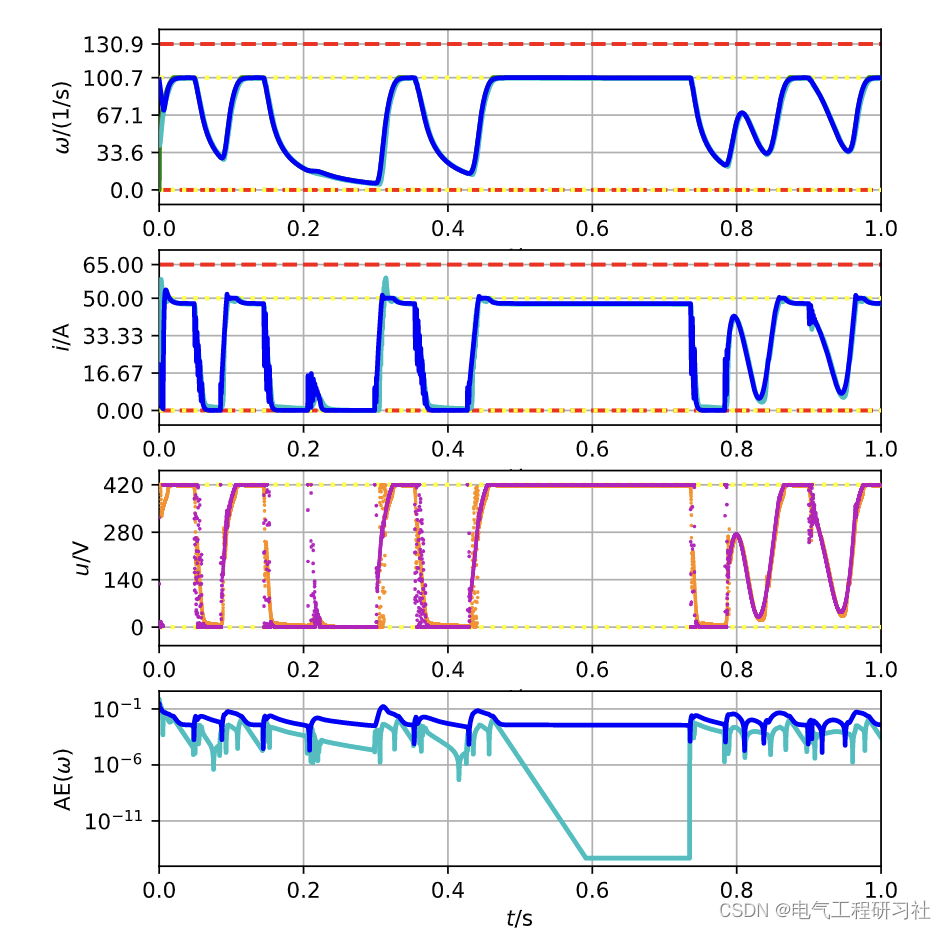
图 11 绘制了经过 7 500 000 个模拟步骤后学习代理的轨迹。角速度、输入电压和电流被突出显示,类似于工具箱中的仪表板。此外,还包括用于相同参考的级联 PI 控制器的轨迹。 DDPG-agent 的 MAE 为 0.0133,远小于之前的两个轨迹,PI-controller 的 MAE 更小,为 0.0024。在图 11 中显示的事件的角速度与其参考之间的绝对误差随时间的分散可以在底部图中看到。正如预期的那样,随着时间的推移,误差描述了由于系统的低通行为而与参考轨迹中的跳跃一致的突然跳跃。此外,从 0.4 s 到 0.8 s 之间的图中可以看出,DDPG 存在小的稳态误差。
5 参考文献
部分理论引用网络文献,若有侵权请联系博主删除。
[1]倪劲松. 基于无位置传感器的五相无刷直流电机控制系统研究[D].哈尔滨理工大学,2022.
[2]吕颖利,赵会娟.基于单片机的步进电机控制系统研究[J].南方农机,2022,53(08):132-134.
[3] A. Linder, R. Kanchan, P. Stolze, and R. Kennel, Model-Based Predictive
Control of Electric Drives, 1st ed. G ̈ottingen: Cuvillier Verlag, 2010.
[4] D. G ̈orges, “Relations between model predictive control and reinforce-
ment learning,” IFAC-PapersOnLine, vol. 50, no. 1, pp. 4920–4928,
2017

















 54
54











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











