







文章目录
hash,意思是混杂,拼凑,即把所有数据混杂凑在一起,在存储空间中,没有顺序。
散列技术:一种新的存储技术,也是一种查找方法
实在是牛逼 。敢想敢做还能做。
散列查找的原理和之前的查找全部不同。
存储位置是关键字的函数,给我一个关键字,我拿这个函数一算,就得到了其存储位置,于是可以立即查找到该关键字。根本不需要什么顺序查找,有序查找那种比较,一点比较都用不上,完全的纯粹地另辟蹊径。
而一旦避免了比较,查找效率就会蹭蹭蹭的提高,毕竟只是计算一下,相当于时间复杂度 O ( 1 ) O(1) O(1)?

几个概念
- 散列函数(哈希函数):存储位置和关键字之间的对应关系f
举个例子,下面例子的散列函数是:把学号存在学号的最后两位决定的存储单元内。


再比如,这个散列函数是:关键字是多少,就存在几号存储单元


- 散列表(哈希表):hash table, 利用散列技术存储数据的一段连续地址空间
散列表和线性表,树,图不同的是,它的数据元素之间并没有某种逻辑关系。所以散列是一种专门面向查找的数据结构,它不具备常规数据结构的能力,比如散列表不能对表中记录排序;不能得到最大值或最小值。
- 散列地址:关键字对应的记录的存储位置
散列技术的核心问题:精心设计或构造一个简单,均匀,存储利用率高的散列函数
什么是好的散列函数
- 不同关键字计算得到的地址一定不同
只是理想,现实中一定会有两个关键字计算出同样的地址,这就是冲突,是散列函数设计的重大问题
- 计算简单
起码计算上要快过之前那些使用比较的查找算法吧。。。不然就没有竞争优势了。毕竟查找操作本身是非常频繁的操作,所以散列函数的计算一定要快。
如果一个散列函数可以保证绝对没有冲突,但是要耗费很多很多时间在复杂的计算上,那也没有什么价值。
- 散列地址分布均匀
让地址均匀分布在存储空间中,以保证空间的有效利用,还能减少处理冲突的时间。
尽量避免会造成数据查找错误的冲突collision(不能完全避免)

设计的再好的散列函数也不可能完全避免冲突。下面介绍了五六种散列函数,没有谁敢说自己绝对不会引起冲突。
再说了,我们也不需要完全没有冲突,因为有了冲突,我们想办法解决就行,并不会造成啥不好的后果。
常用的几种散列函数构造方法
散列函数的好坏直接影响了冲突出现的频繁程度。但是,不同散列函数对同一组关键字,出现冲突的可能性是一样的。所以分析散列表的查找性能时,并不把散列函数考虑在内。
下面的这些散列函数的关键字都是数字,但如果关键字是字符串,不管哪国语言,都可以通过某种方式(常用各种字符编码)转换为数字,就可以用下面这些散列函数了。
直接定址法: f ( k e y ) = a ∗ k e y + b f(key)=a*key+b f(key)=a∗key+b
比如刚才的第二个例子,
f
(
k
e
y
)
=
k
e
y
f(key)=key
f(key)=key,相当于a=1,b=0
再比如

f
(
k
e
y
)
=
k
e
y
f(key)=key
f(key)=key,相当于a=1,b=0
下图红框的2000改为20

f
(
k
e
y
)
=
k
e
y
−
1980
f(key)=key-1980
f(key)=key−1980,相当于a=1,b=-1980
优缺点和适用性
优点:简单,均匀,不会冲突
缺点:需要事先知道关键字的分布情况
适用于:查找表较小且连续的情况
所以,现实中,这种方法并不常用
数字分析法
这种方法比上面的直接定址法要稍微不那么naive一些了,也就稍微复杂一些。但是这种方法也是我们很容易就想到的,就是对数字本身进行各种变换,生活中给行李箱设置密码时我喜欢这么干,原来在这里被专门归类为一种方法,叫做数字分析法。
比如,要把所有学生的手机号存起来


同一学校的所有学生,前面7位数很可能多一样,我们大学时候是学校统一发的手机号卡,身边同学的前七位数就是一样的。而后四位,是用户号,只要前七位相同,后四位一定不同,所以我们可以直接把后四位作为散列地址,即抽取手机号的后四位来直接定址。
抽取,用关键字的一部分来计算散列存储位置的方法,在散列函数中经常使用。
但是林子大了,肯定有俩人后四位一样的情况(前七位不一样),所以就会引起冲突。
于是我们需要尽量避免冲突,可以使用的散列函数有:
- 将抽取的数字进行反转
1234变为4321
- 右环位移或者左环位移
右环位移即把四个数字看做一个环,向右移动一位。如1234变为2341
左环位移
- 数字叠加
比如四位数的前两位和后两位的叠加,1234,12+34=46,得到地址46
这三种方法只是举例子,我觉得真的很适合用来设置行李箱密码,哈哈,把生日数字经过左环位移得到的数字作为密码啥的
适用性:适用于关键字位数大,且其中若干位分布均匀
如果关键字位数大,且事先知道关键字的分布情况,且其中若干位分布均匀,就很适合这个方法。
平方取中法:适用于关键字位数不多,不知道其分布的情况
太神奇了吧
这和方法简直就是,,emmm,真的很随便的样子,但是却又能在实际中很好的工作,神奇,厉害。看来计算机科学领域,像深度学习一样,也很容易经验领先于理论。

折叠法:适用于关键字位数较多,不知道其分布的情况
天哪,好想知道这些方法计算出来的散列地址的冲突有多少。。真的感觉极其奇怪的一种操作,,就可以成为散列函数,怎么样保证大多数不同关键字得到的地址也不同的呢

除留余数法(最常用,取模)
正经的常用散列函数终于来了,前面几个,跟玩儿似的,没有用数学理论证明冲突数目。
但这个方法也超级简单,就是求个余数,说起来真是神奇,我们从小学加减乘除,用的更多的也是加减乘除,取余数一般很少用。但是计算机领域里,取余数这个操作,却总有一些厉害的用途。
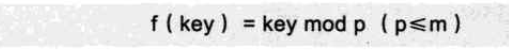
虽然公式中是对关键字key进行取模,但是其实也可以对关键字进行折叠或平方取中后再取模。
所以公式中的p,就是这个方法最大的关键。即对谁求余数。
比如下面,假涉取p为12,则关键字12对p取模,余数是0,所以存在位置0;关键字78对12取模得到6,所以存在位置6。

但是这种方法当然会有冲突,而且还不少,比如如果还有一个关键字30,它对12取模得到的余数也是6,而42对12取模得到的余数也是6,则给30和42也要分配位置6,这就冲突了。
更极端的,假设关键字全都是12的倍数,则大家对12取模得到的余数清一色都是0,如下图,你说气人不?

但是如果把p换成11,那么上面这些关键字存储时遇到的冲突就少很多了,只有12和144两个关键字冲突了。

所以,减少冲突的关键就是p的选择。
减少冲突的关键:p的选择

随机数法:适用于关键字长度不等的情况

呀呀呀,这个感觉很像给文件加密的哈希函数的感觉,当然啦二者不是一回事,区别还很大,但是很像。
怎么选散列函数,看什么因素
虽然介绍了一大堆散列函数,但是没有一种散列函数是走遍天下都不怕的,没有一招鲜吃遍天的散列函数,算法都是没有万能的,排序算法,查找算法也一样。我们要结合实际情况采用不同的散列函数,参考的因素有:

处理散列冲突的方法
再好的散列函数也不可能完全避免冲突。
下面这几种解决冲突的方法,都很好理解,很简单,只是说起来复杂而已,但思路都是很容易想到的,尤其是再散列函数法和链地址法。不过这些方法,出于不同的考虑角度,因此有不同的优缺点,使用时还是一样,需要结合实际情况。
开放定址法(常用):一冲突就去找下一个空地址

开放定址法的根本思想就是:这里冲突了,那我就找从这里出发,向前或者向后,或者随机,不管用什么手段,反正一定要找到一个空位置把自己存下来。
根据在散列表中找下一个空散列地址的方法,可以把开放定址法再细分为三种。
线性探测法:会产生堆积
即如果用散列函数计算得到的地址已经被使用了,则从这个地址开始,线性地往后依次查看每一个位置,直到找到一个空的地址,就存在这里。
用数学公式表达,则是

可以看到,需要用到一个数列
d
i
d_i
di, 它是位移量。
f ( k e y ) f(key) f(key)就是散列函数计算得到的散列地址,如果 f ( k e y ) f(key) f(key)已经被占用了,则对 f ( k e y ) f(key) f(key)加上 d 1 d_1 d1,代入上面的公式,求出新地址,如果新地址是空的,则存入,否则载代入 d 2 d_2 d2计算下一个地址。总之,从第一次计算的地址开始,单向地,向后一个个地找。这也是名字为啥叫线性探测的原因。
举个例子,便于理解

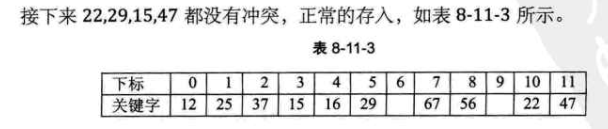

堆积:不是同义词的关键词们争夺一个地址,会引发更多冲突,造成查找和存入效率降低
同义词,文首说过的概念,即两个不同的关键字,经过一个散列函数,计算得到了一样的散列地址,于是发生地址冲突,这种现象叫做冲突,这俩关键字叫做同义词。
现在,线性探测法中出现了一种新现象,不是同义词的两个关键词也会争夺同一个地址了,这种现象被命名为堆积。
堆积不是什么好现象,它的出现,会引起更多冲突!所以存入和查找的效率都会降低。
二次探测法:线性探测的改进版,在散列表中双向寻找空地址
它由于双向搜索,所以产生的堆积更少,相同关键字和相同的散列函数,使用二次探测法处理冲突,比用线性探测法的查找性能好。
二次,不是“第二次”的意思,而是幂次为2,平方的意思。
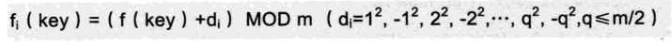

随机探测法:用伪随机函数计算位移量数列

只要随机种子一样,则多次调用随机函数,生成的数列都是一样的。所以只要种子一样,
d
i
d_i
di就一样,找到的散列地址也就一样,所以查找上不会有任何问题。
优缺点
- 优点:关键字不聚集
- 缺点:需要散列表够大
再散列函数法:事先准备多个散列函数
这方法是我们最容易想到的了,比开放定址法还容易想到。
冲突?换个散列函数继续搞啊!还冲突?再换!就不相信还找不到一个空地址了。
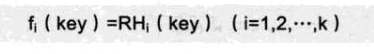
R
H
i
RH_i
RHi就是多个不同的散列函数。前面说的所有方法都可以算上,有一个算一个。
优缺点
- 优点
- 缺点:
- 还真有可能找不到一个空地址。。。用尽所有散列函数也找不到空地址,但散列表中确实又有空地址。。。
开放定址中的线性探测和二次探测是一定可以找到空地址的。
- 计算时间长
链地址法:冲突不换址,把所有关键字为同义词的记录存在一个单链表里
不产生任何堆积,所以查找性能比使用开放定址法处理冲突要好。
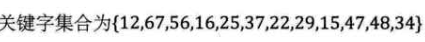
表长12,用除留余数法计算散列地址

优缺点
- 优点:绝对不可能找不到地址,这是绝对的保障。之前的开放定址和再散列函数,如果冲突就需要想办法换地址,虽然最终肯定是能找到空地址,毕竟表长一定大于等于待存元素数,但是查找新地址的时间耗费较多。
- 缺点:查找时需要遍历单链表,耗时一些;此外,可以看到散列表中有些位置是空着的,没被使用,所以空间利用率也相对差一点。
公共溢出区法:把所有冲突的关键字建立一个公共的溢出区来存放



散列表的适用性和优缺点
- 适用性
- 适用于查找性能要求高,记录之间的关系没有要求的数据
- 最适合查找和给定值相等的记录
- 不适合一个关键字对应多条记录的情况,因为散列函数是一对一的映射
比如关键字“男”,可以找到很多记录,散列表无能为力,他要求关键字必须和记录一一对应,一对一,毕竟是一对一的映射,不是一对多的映射。
必须用身份证号或者学号这种关键字去找。
- 不适合范围查找;不能对表中记录排序;不能得到最大值或最小值
- 优缺点
优点:查找效率非常非常高
缺点:
- 空间效率低,可能有很多空间都没用。所以散列函数的设计重点之一就是要提升空间利用率
- 记录之间没有任何关联
代码
散列表结构 HashTable
用一个动态数组实现哈希表,这样便于不断增加元素
动态数组可以用结构体实现,成员变量简单到只有俩,也许cpp的vector的底层实现就是结构体呢,只不过使用了模板
#define SUCCESS 1
#define UNSUCCESS 0
#define NULLKEY -32768
#define HASHSIZE 12 //散列表长度
typedef struct
{
int * elem;//数据元素的存储基址,动态分配
int count;//当前数据元素数目
}HashTable;
int m = 0;//散列表表长,全局变量
初始化散列表
Status InitHashTable(HashTable * H)
{
//给哈希表分配内存
m = HASHSIZE;
H->count = m;
H->elem = (int *)malloc(m * sizeof(int));//分配m个int位置,作为哈希表
//初始化哈希表的所有元素为NULLKEY,这样插入元素的时候就知道这个位置是不是为空地址了
int i;
for (i = 0; i < m; ++i)
H->elem[i] = NULLKEY;
return OK;
}
散列函数
用于插入元素时计算地址
这里用除留余数法
/*返回地址,并非真的内存地址,而是哈希表数组的下标,所以是int*/
/*但是&(H->elem[addr])是真实的内存地址,也是key在不冲突情况下会被存入的地址*/
int Hash(int key)
{
return key % m;
}
插入关键字操作(使用线性探测法解决冲突)
/*输入是关键字和待存入的哈希表*/
void InsertHash(HashTable * H, int key)
{
int addr = Hash(key);//求散列地址
while (H->elem[addr] != NULLKEY)//当前位置已经被占用,冲突
addr = (addr + 1) % m;//线性探测法
H->elem[addr] = key;//插入关键字
}
散列表的查找操作(和插入的代码相似,只是多了是否存在关键字的判断)
现在已经把元素都插入进去了,可以查找了
Status SearchHash(HashTable * H, int key, int * addr)
{
*addr = Hash(key);
while (H->elem[*addr] != key)//说明冲突了
{
*addr = (*addr + 1) % m;//用一样的方法(线性探测)找下一个地址,并逐一比较
//没找到,关键字不存在
if (H->elem[*addr] == NULLKEY || *addr == Hash(key))//*addr == Hash(key)表示循环回到原点
return UNSUCCESS;
}
return SUCCESS;
}
哈希表的查找性能
如果没有冲突,则散列查找的时间复杂度是 O ( 1 ) O(1) O(1)!
但这只是理想,现实中我们是无法完全避免冲突的
面对现实(有冲突),分析散列查找的平均查找长度的影响因素
- 不考虑散列函数对平均查找长度的影响

- 处理冲突的方法,有影响

- 散列表的装填因子

用空间换时间,还是更常用的操作。毕竟大多数情况下,时间资源比空间资源更重要。
这么一看的话,链地址法是最好的办法??虽然浪费了一点多余空间,但是装填因子小。















 1095
1095











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









