







2018年发的老文章了,文章不错,所以决定再捞一下。文中有3段视频,如需观看请大家移步“基因Share”观看。
Pacbio测序原理及SMRT bell文库构建流程简述(二)
大家好,今天跟大家继续分享关于PacBio SMRT测序仪的相关知识,分享内容主要参考PB官方的《Template Preparation and Sequencing Guide》并以PPT格式展示。
在正式开始分享前,谈一谈关于目前主流基因测序技术的名称问题,很多人将测序技术分为或者叫做一代测序(Sanger测序)、二代测序、三代测序甚至是四代测序,个人认为这个叫法带有强烈的商业宣传动机,举例:因为所谓的一代到四代测序跟全球移动通讯技术(2G、3G、4G、5G)的概念是完全不同的,因为单从上网体验来看,下一代移动通讯技术从任何维度都比上一代要好得多即一代更比一代强,而几种测序技术在测序精确度、单位时间数据产量、平均序列读长、单位数据量成本等主要评价指标上却各有优劣,在不同的科研、临床应用场景中更是如此。
因此对于目前市面上的主流测序技术根据测序原理,分为“双脱氧末端终止法测序”“短读长大规模平行测序”“单分子实时荧光测序”更合适一些,不管是PacBio还是Nanopore都是单分子测序,在文库构建和光信号采集单元(Cluster、DNA Nanoball... ...)的生成的过程中没有PCR的过程,也正基于此,瀚海基因的CenoCare短读长基因测序仪才敢叫“第三代基因测序仪”。
接下来我们主要讨论的就是“单分子实时荧光测序”,而不再称之为“第三代测序”。


以基因组DNA为例(6~20k文库),从建库流程来看与“短序列大规模平行测序”相似,都是将基因组片段化,然后在片段化DNA的两端加上特定的接头序列,主要不同点在于最后bell文库需要与测序通用引物、具有链置换性的DNA聚合酶依次进行结合,形成待测模板、引物、聚合酶的复合物,然后loading到测序芯片上。
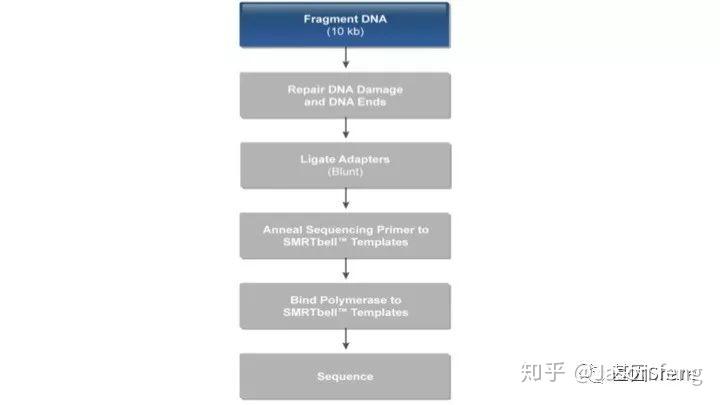
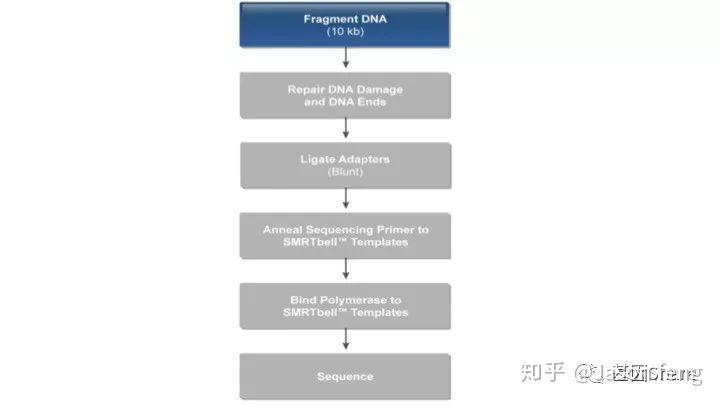
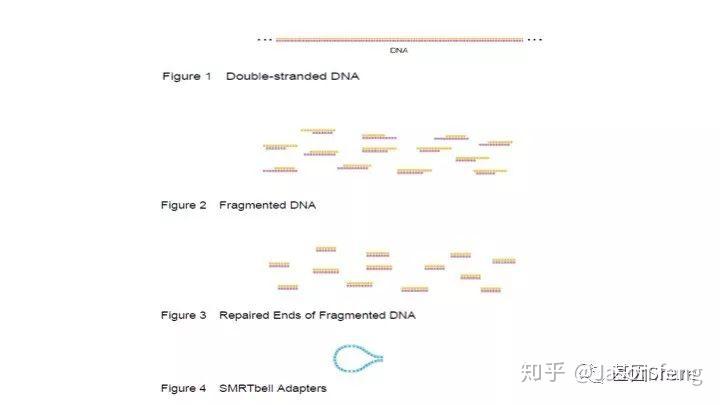
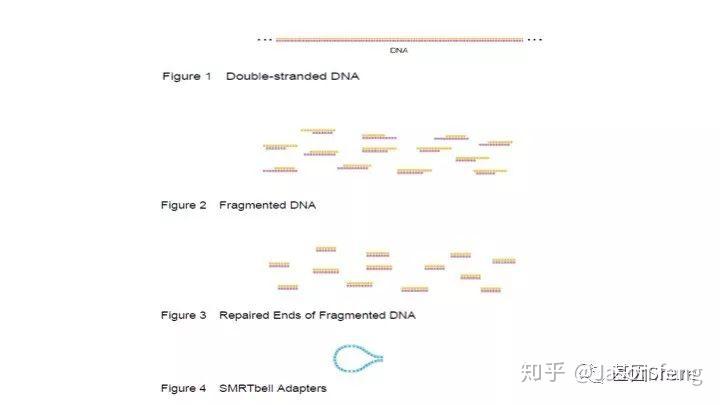
SMRTbell文库是单链发卡状的接头,文库两端连接的接头是相同的(Dual index时barcode序列除外)这得益于其滚环测序的原理而不需要像illumina或者MGI的adapter一样需要部分互补、部分游离的结构来实现PCR和双末端测序。
如下图,测序通用引物的5'具有PloyA尾巴,这与其后续利用MagBead方式Loading测序芯片有关,因此测序引物与接头部分互补。
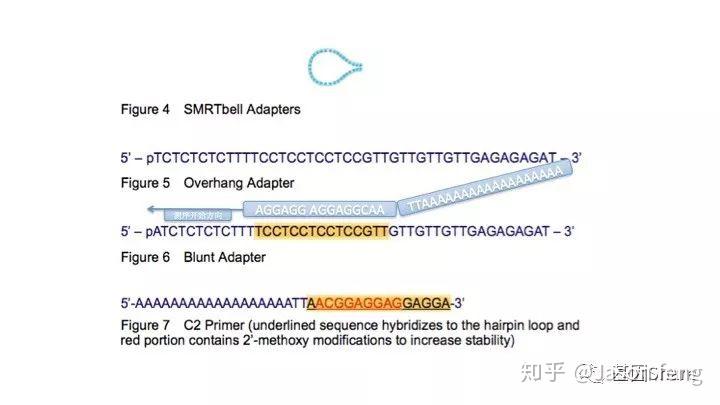
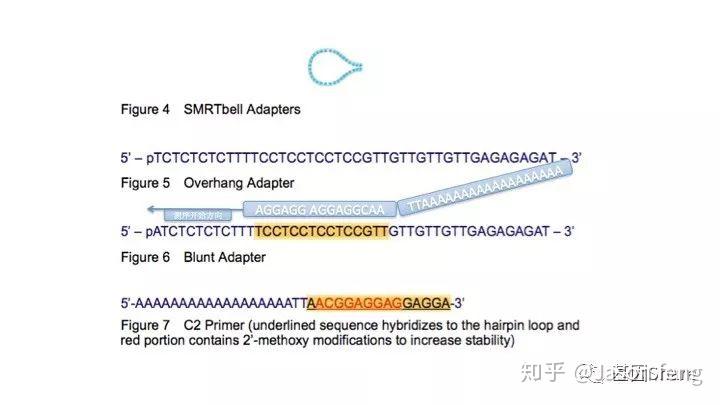
PB提供两种类型的接头序列,一种是我们熟知的A/T粘性末端接头,一种是平末端接头,当插入片段大于250bp时则使用平末端接头,反之使用A/T接头(当然这就意味着99%的情况下,使用平末端)


从下图中可以看出,PB建库、测序试剂包最独特的也就是DNA/Ploymerase Binding Kit了,它作为一个单独的包装出现,而“短序列大规模平行测序”技术中的DNA聚合酶是在测序试剂盒里的,每一个测序Cycle(每读取1个碱基)都需要从试剂槽中抽取酶并且在下一个Cycle进行前冲走。
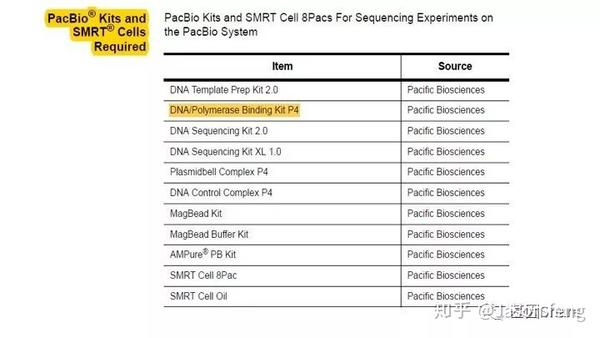
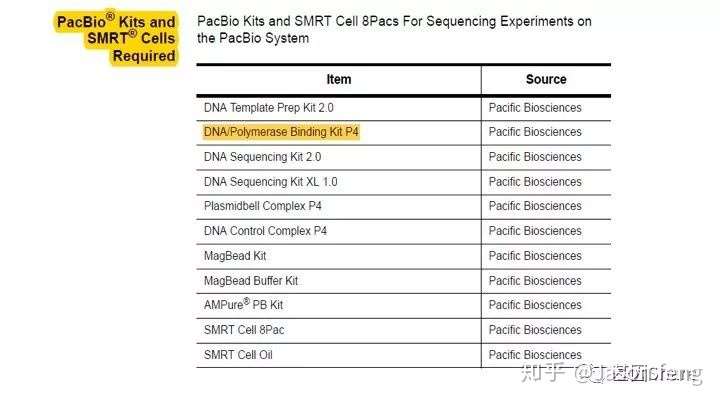
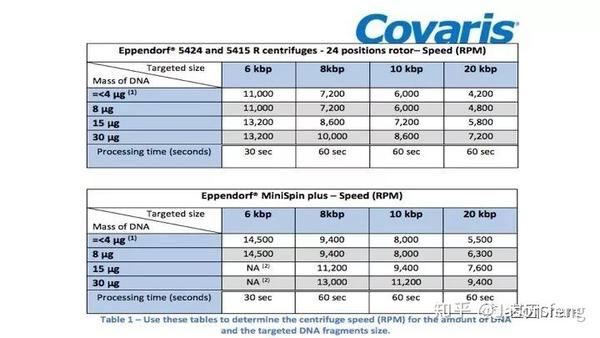
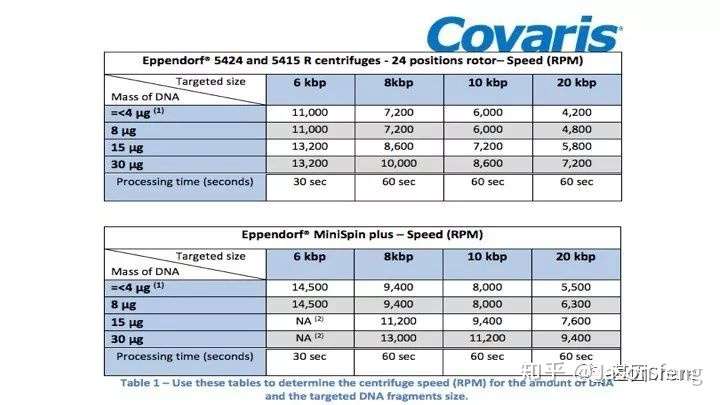
再来看一下需要的特殊实验仪器以及耗材,基本同“短序列大规模平行测序技术“的要求类似,例如核酸片段化设备仍是Covaris公司产品的天下,但不是我们熟悉的基于AFA原理的核酸片段化仪器,而是一种打断管—g-TUBE(主要用于6~20k的主流SMRT文库构建,如insertion<6K,则使用Covaris AFA设备进行片段化,如果>20k则推荐使用Diagenode公司的核酸片段化设备)。
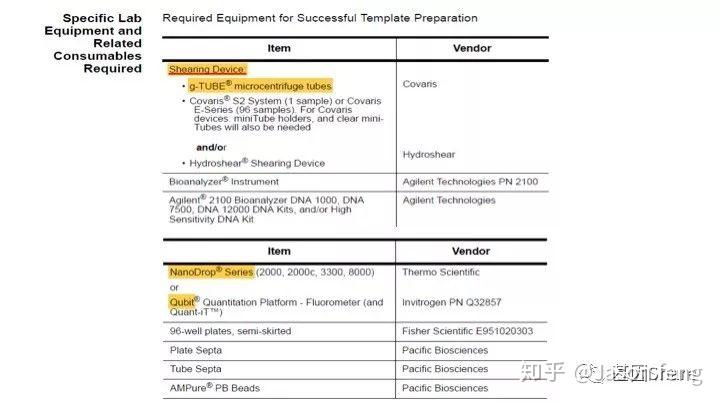
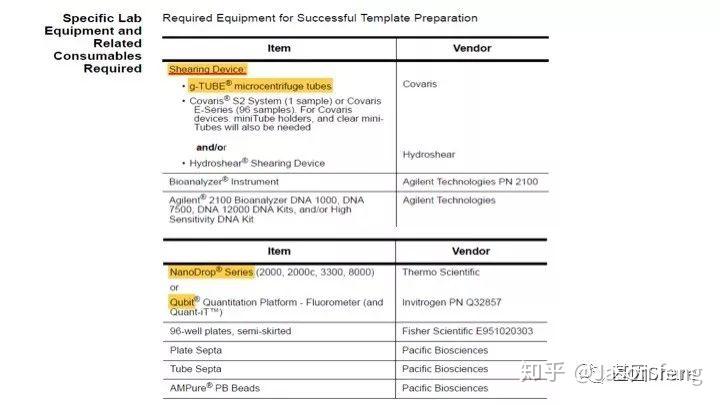
下面简单介绍一下g-TUBE,其只需要配合一台桌面式离心机在3min内即可完成多达24个样品的片段化工作(是不是比AFA的好用多了?),通过控制离心时间和RPM即可得到不同长度的DNA片段,但其售价也非常感人,分为10个/包和100个/包两种规格,平均400块软妹币1个!为何这么贵?难道是因为每个管里都有一个红宝石?(真的有,红宝石的硬度仅次于钻石,用于切断DNA)但是问了问玩表的老伙计说:“一个百元左右的日本产NH35A自动机械表芯,红宝石数就达24颗(手表上常标注的XX JEWELS即指机芯所含红宝石轴承数)。”那么看来红宝石不值钱呐,这个管就是纯贵。


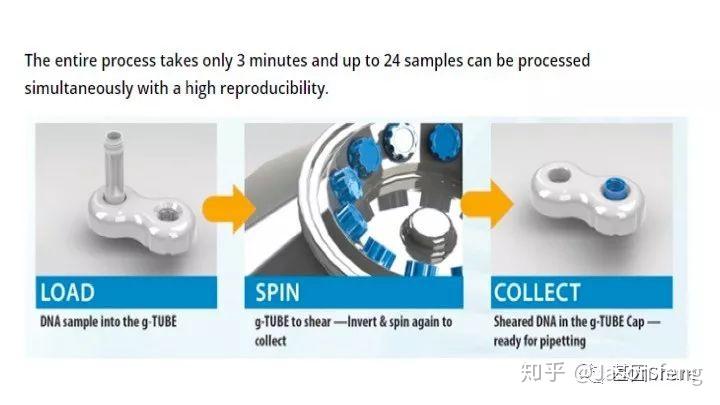
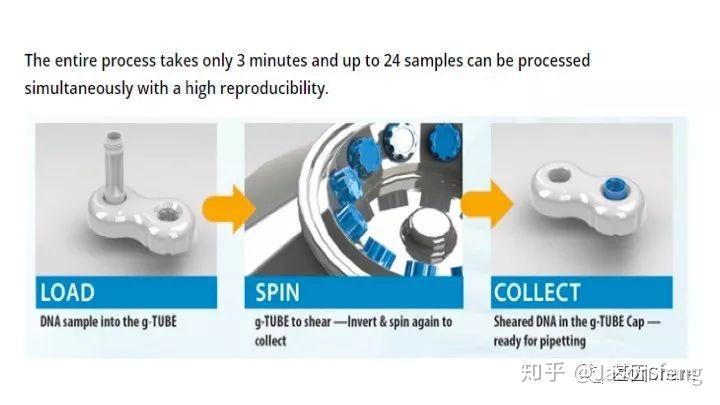
(在离心机上完成打断后,将打断产物倒置放置在像隐形眼镜盒的底座上,然后用移液枪吸走打断产物)
PB建库要求的DNA起始量高、完整性好一直是一个比较头疼的问题,Bio-nano的光学图谱也面临同样的难题,一般测序公司对于起始量要求是10ng以上的纯净gDNA(10k文库),一般insertion越长对于核酸起始量要求会进一步增高。






下图详细展示了DNA起始量、离心时间、RPM三者的关系,目前g-TUBE支持最多30ug的起始DNA。
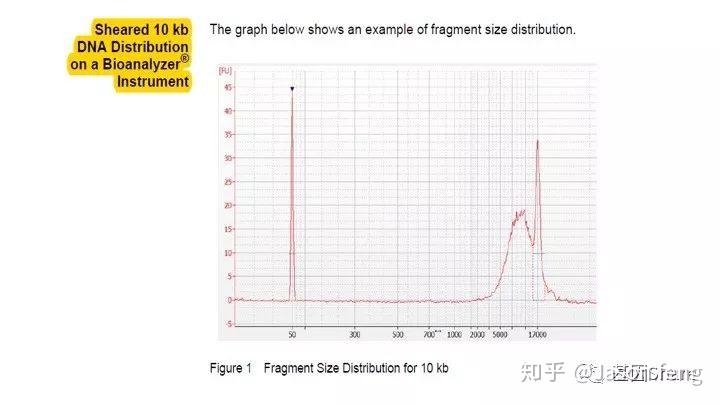
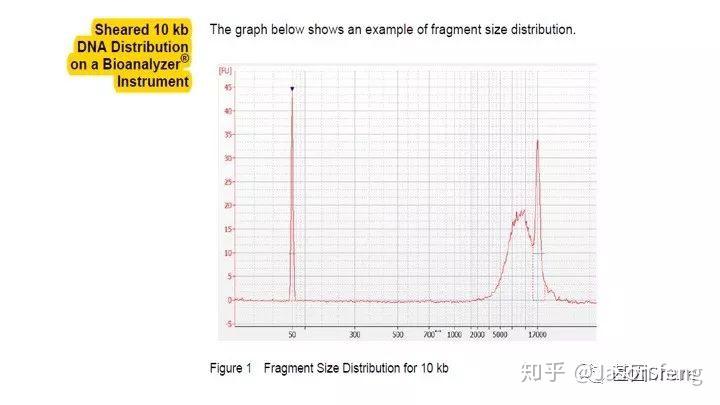
得到片段化产物后通过磁珠纯化和质控,接下来进行DNA的损伤修复、末端修复与接头连接。对于>20k的insertion,在进行损伤、末端修复之前,我们还会对片段化产物用Exo VII(单链核酸外切酶,可以水解5'或3'末端的单链状态的DNA链)来处理一下,尽量减少下图所示的情况发生(大片段的overhang较长,容易self-anneal并在后续的Damage repair阶段形成单端闭环,从来无法正常连接接头)




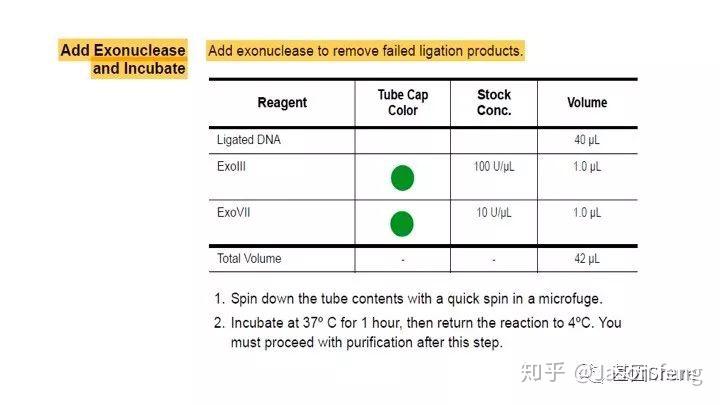
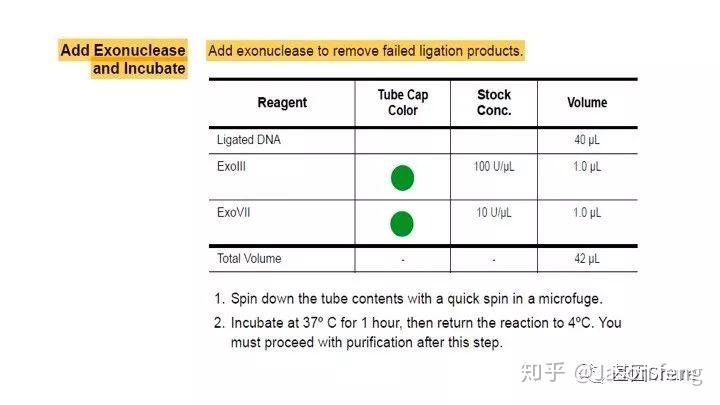
对于损伤修复,PB建议insertion>2k的文库必须使用损伤修复试剂对DNA进行损伤修复(这些损伤主要是来自于核酸提取与PCR的过程),接头连接完成后SMRT bell文库基本成型,这时使用再使用ExoIII和ExoVII处理,消化掉部分副产物。
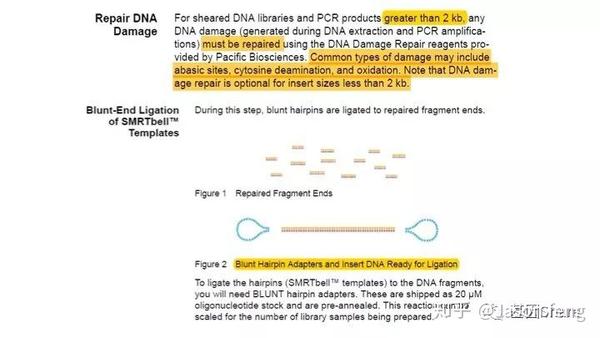
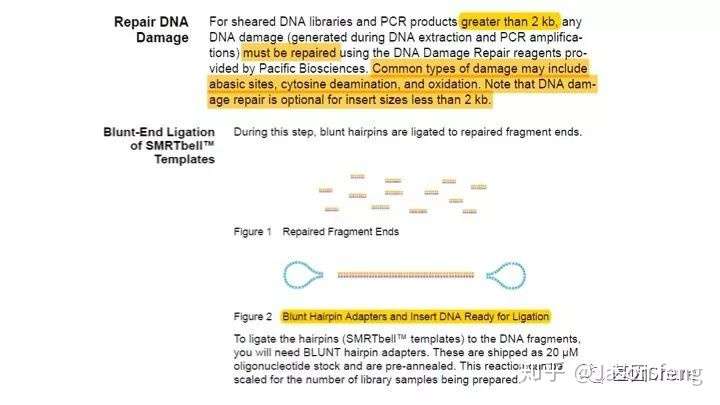


完成发卡状接头连接后,接来下待测模板要依次与测序通用引物、DNA聚合酶(具有链置换性且生物素修饰)进行结合,形成Primer-Template-Polymerase的Complex(理论上1个bell文库双链模板,两端接头各结合1条测序引物和1个DNA聚合酶分子)
关于Primer:Template比例和Polymerase:Template比例根据insertion大小和文库Loading方式的不同而不同,具体可参见下方相关材料。




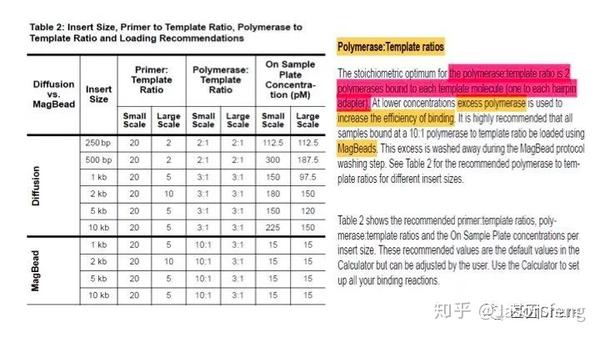
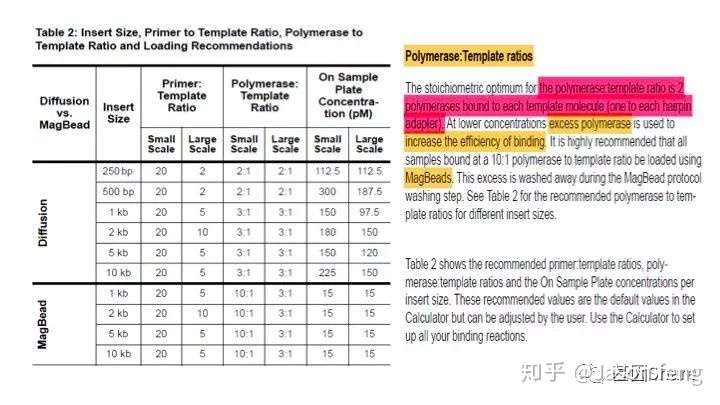


在正式开始测序之前,需要将Template:Polymerase的Complex加载到SMRT Cell上,目前PB提供两种加载方式,Diffusion和MagBead,Diffusion是目前“短读长大规模平行测序技术”中常用的一种样品加载方式(可以通过电场控制待测模板在Flow cell上的扩散速度,减少非单克隆的产生),在一定范围内,我们可以通过控制文库(或者混合物)的浓度来调整单个Cell的数据产量(但通常需在数据产量和测序读长两者之间做权衡,理论上随着文库浓度的提高,单个Cell的产量上升,但平均测序读长却会下降)。


下面主要介绍一下基于磁珠的MagBead样品加载方法(类似于Oligo dT磁珠富集mRNA的原理),下方视频非常清晰的说明了MagBead的加载原理,使用MagBead方法的优势如下 1)去掉游离的DNA聚合酶 2)去除短插入片段污染 3)减少接头二聚体,总体来说MagBead的方式使得insertion范围更加集中,但显然短插入片段的bell文库不适合此类上样方法。




如前所述,DNA聚合酶被生物素修饰,而ZMW底部有链霉亲和素,两者发生结合从而将bell文库牢牢固定在ZMW底部,ZMW Loading符合泊松分布,以Pacbio Sequel每张SMRT cell芯片约100万的ZMW计算,理论上有1/3孔是空孔(无效孔)。1/3孔有且仅有一个待测单分子模板(有效孔),1/3孔有两条以上的单分子模板产生杂和荧光(无效孔),三个值分别对应下机报告中Productivity0 、1、2。


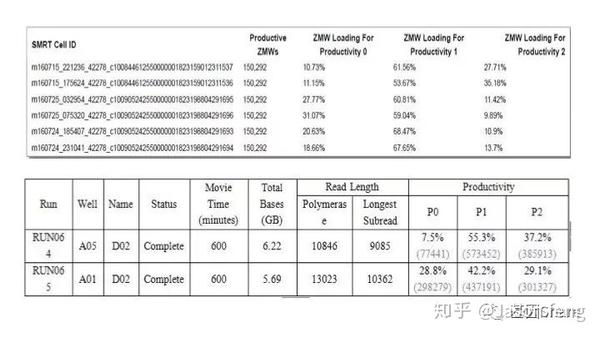
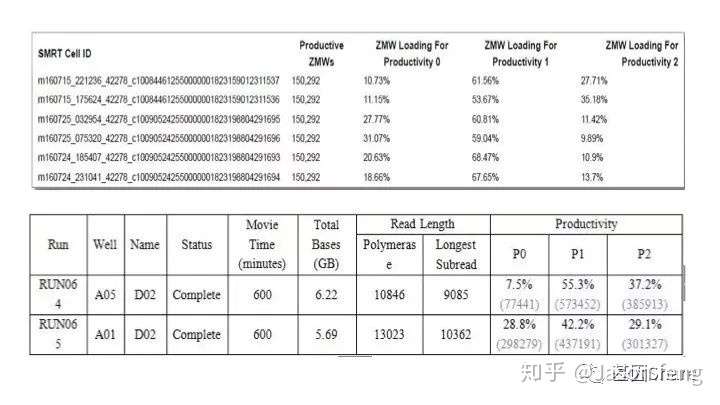
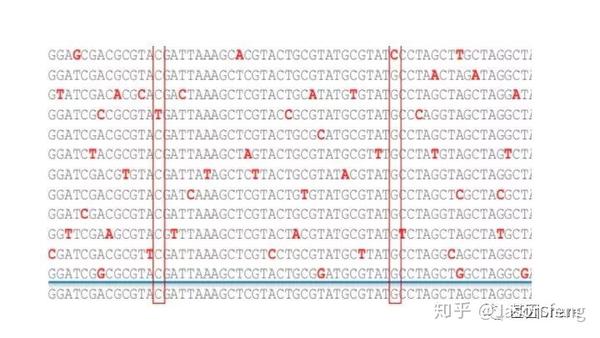
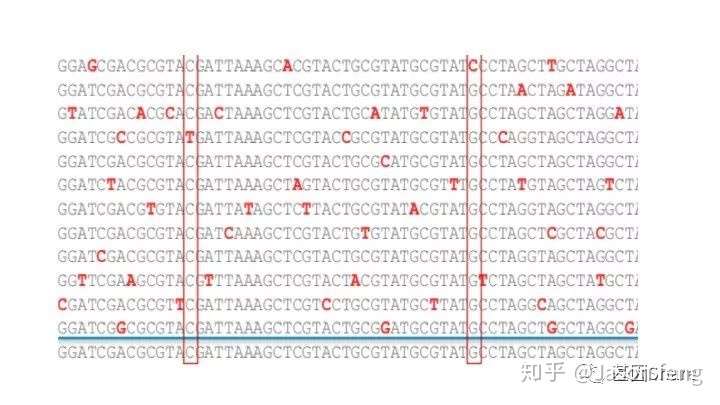
另外还需要关注的是ZMW Loading Bias的问题,SMRT bell文库Loading ZMW是一个具有模板尺寸依赖属性的过程。例如,利用限制性内切酶酶切18.5k的质粒,酶切片段长度范围在160bp~4kb之间并分别构建SMRT bell文库、上机测序,测出的数据如下图所示:随着插入片段的增大loading率变小。即insertion越小掉到孔里就越容易。也正因为如此,全长转录组测序时(ISO-seq),我们不能直接构建一个1~10k的文库来几乎覆盖所有长度的转录本,而是需要利用BluePippin将全长cDNA分选为1~2K、2~3k 、3K~6K、5~10K 4个区段并分别构建SMRT 文库进行测序,否则得到了都是小片段信息。
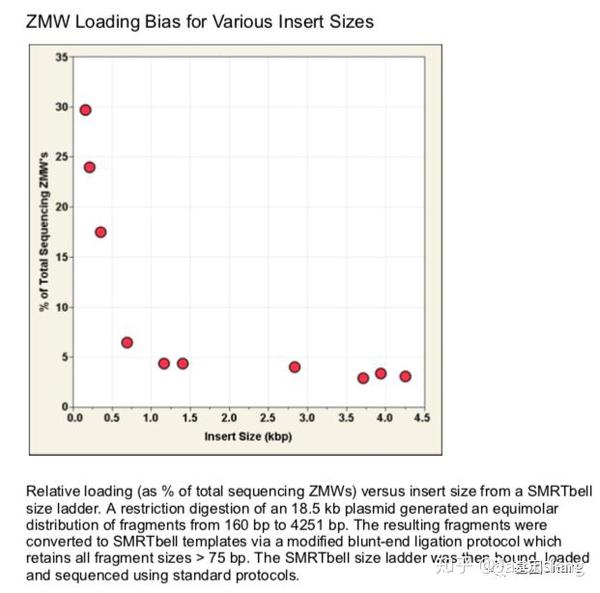
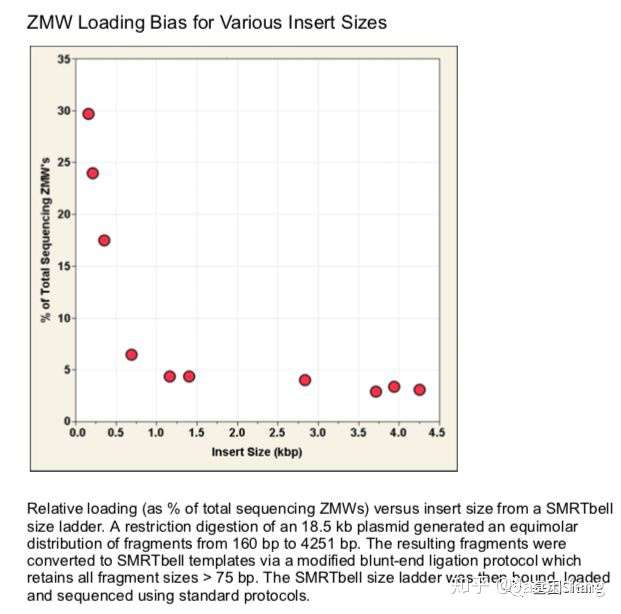
完成ZMW Loading,接下来就是最后的Sequencing,下图为SMRT bell文库的序列读取示意图,样的文库结构拥有众多优势,文库两端接头为测序通用引物提供了结合位点,具有链置换性的聚合酶将双链解开进行聚合反应(SBS),滚环测序可以得到插入片段正负链信息,例如聚合酶活性(Polymerase Read)可支持30k的读长反应,插入片段长度5k,那么理论上可获得6X的insertion信息即正负链各读取3次(不计算接头),6X的insertion序列信息称之为CCS序列(Circular Consensous Sequence)
虽然PB的1X测序错误率很高(15%)但因其错误是随机的,所以有CCS的加持,碱基的Q值也会瞬间爆表!
(Continuous Long Read ,CLR序列不再赘述)
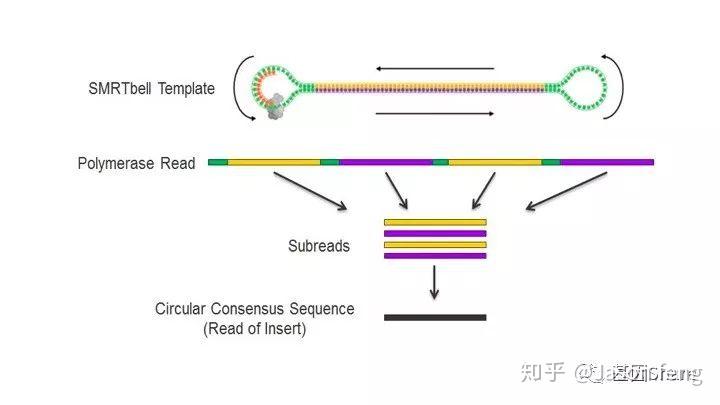
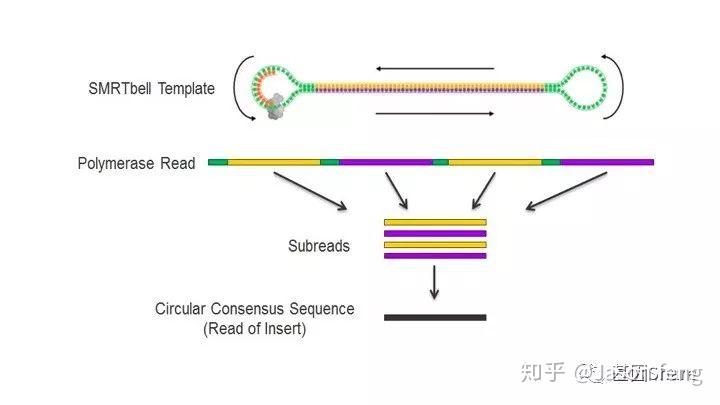
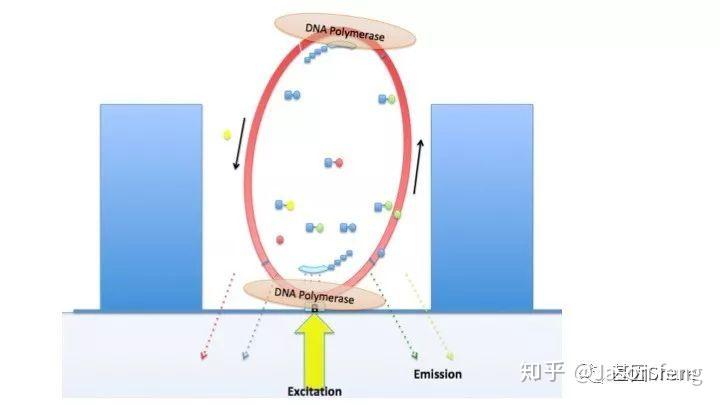
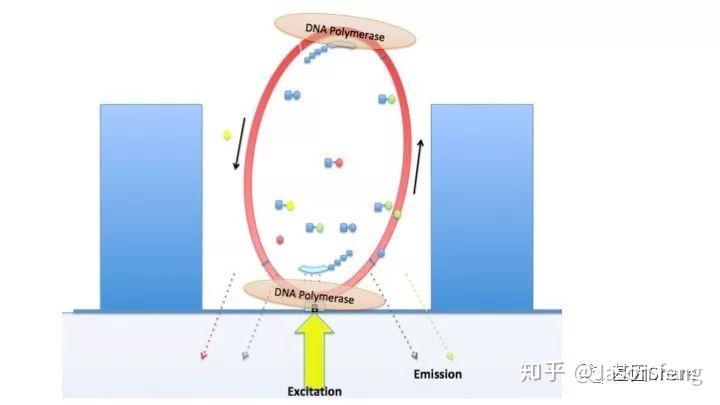
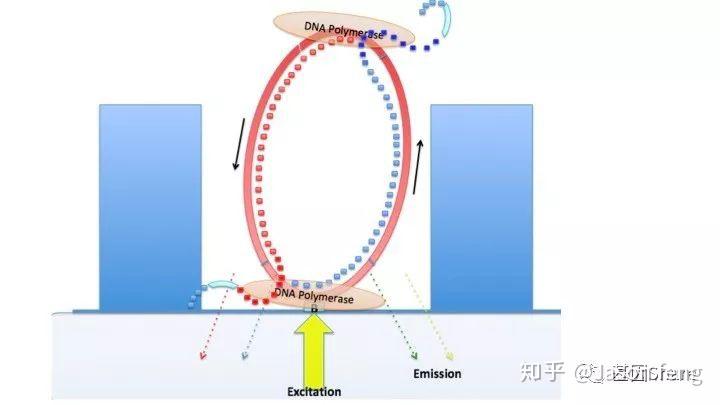
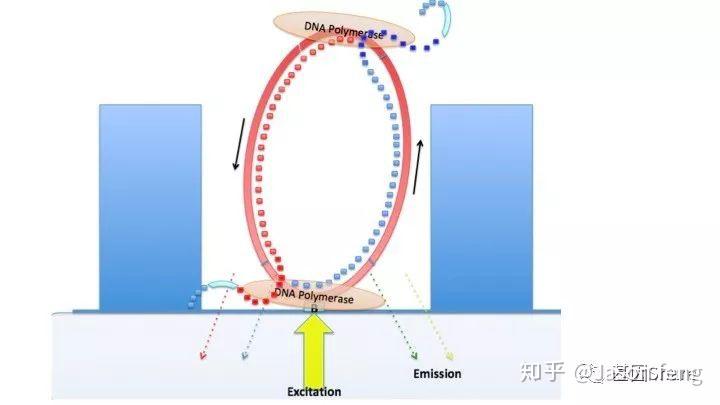
下面的视频简单介绍了Pacbio的测序原理,视频中描述了激光从ZMW的底部照入,ZMW直径远小于激光的波长,激光不能穿过小孔且只能照亮孔底的一小部分区域,因此孔中大部分游离的dNTP的荧光基团将不会被激光激发,只是黑暗中的匆匆过客。在ZMW孔底动弹不得的DNA聚合酶根据碱基互补原则“抓住”对应的dNTP准备发生聚合反应,酶从抓住到开始聚合反应的时间大概约10ms(此时该目标碱基的荧光基团被持续激发),而ZMW孔底部游离的dNTP即使可以被激光激发但整个过程在1~2ms左右,将被当作背景噪音来处理。
DNA聚合酶活性是Pacbio读长长短的决定性因素,激光的持续照射会影响酶的活性,因此PB也在不断对聚合酶进行改进(例如加保护碱基)以便减少持续的激光照射对酶活的影响。
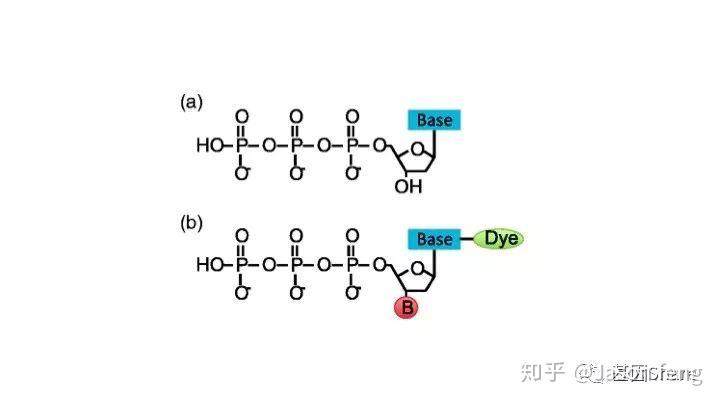
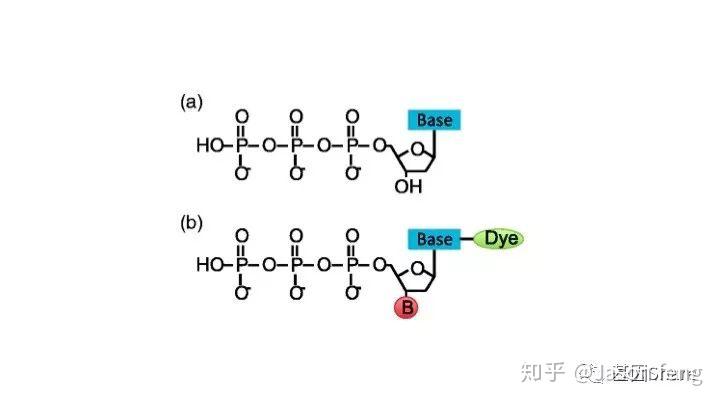
另外,在荧光基团标记的位置上PB与“短读长大规模平行测序技术”是不同的,如下图所示,PB的荧光基团标记在了核苷酸的磷酸基团上,而后者则标记在含N碱基上。聚合酶“抓取”对应的dNTP后,荧光基团会在发生聚合反应生成磷酸二酯键时自然脱落,因此PB测序的聚合反应是完全自然状态的,而不需要在3'加BLOCK待相机完成采图后再切断(每个纳米孔中的待测片度每增加1个碱基,相机将整张芯片划分为几排几列的拍照单元依次进行拍照来记录碱基信息,因此每1个测序Cycle得到的是记录碱基信息的一张张图片),这种完全自然状态下的聚合反应是PB实现超长读长的基础(其超长读长的实现还与单分子的碱基信号采集单元等因素有关,Cluster或者DNA Nanoball等多分子信号采集单元的Phasing / Prephasing现象很大程度的限制了测序读长的进一步升级)
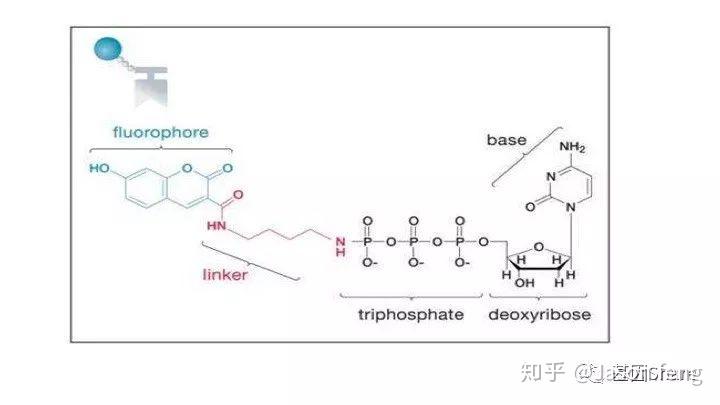
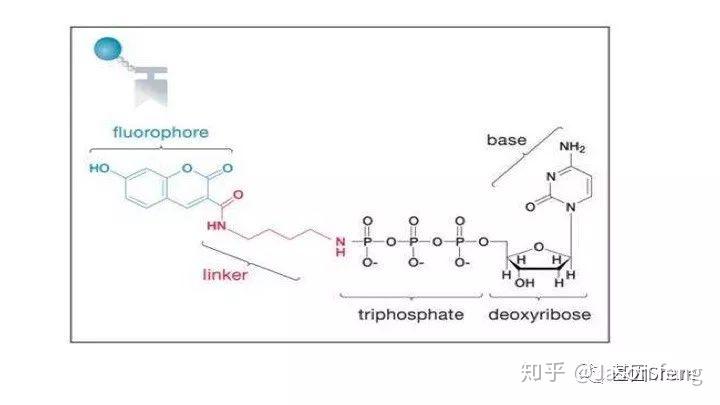
Pacbio的聚合酶快速、不间断的进行聚合反应,为可以实时的记录聚合信息,PB的红绿激光同时从激光器中射出,在某个阶段合并为红绿混合激光持续不断的激发碱基上的荧光基团来实现Real Time Sequencing(这意味着激光照射需一次性覆盖整张芯片,而不是1个Tile或者FOV)。
为了配合CMOS光转电信号的处理速率问题,PB对聚合酶的合成速度进行大降速,从几百bp/s降速到3bp/s,即聚合酶平均每秒钟完成3个聚合反应。
下图1~4为测序聚合反应的简略示意图(图3~4中Bell文库实际应为哑铃状,即正负链成互补状态,具有链置换性的聚合酶在聚合反应开始后将正负链解链),从图中可以看出1分子Template(Prmier):Polymerase复合物被固定在了ZMW底部,理论上SMRT bell文库两端发卡状接头均会结合测序引物和聚合酶,因此文库的两端均会发生聚合反应并生成对应的测序链,但只有在ZMW底部的聚合链的碱基信息可以被采集。




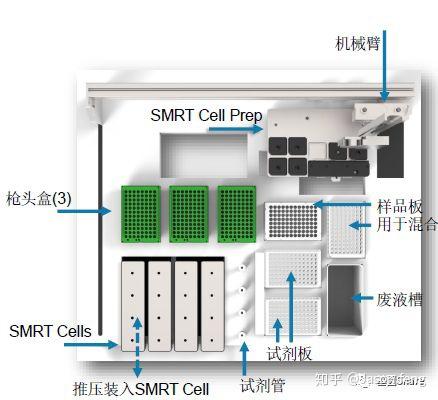
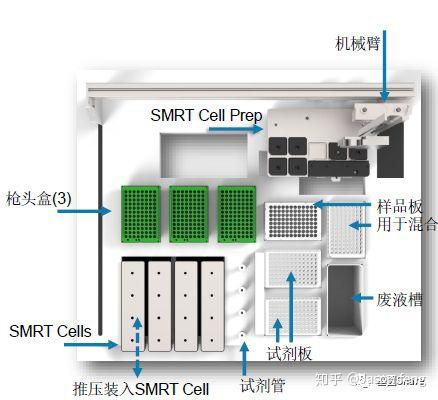
目前PacBio Sequel每个SMRT Cell的运行时间在0.5~10小时,可灵活选择(时间越长得到的测序reads越长),所以科技服务公司一般都会选择600min即10小时的运行时间以便获得最长的测序序列。Sequel的塑料托盘一排装载了4个Cell,操作台共可放置4排共16个cell的卡位以及对应的试剂用量,但每次运行只能完成一张cell的测序工作,5~10G/Cell。


Sequal的构造整体上来看上层是自动化样品处理工作台(无氧环境),下层是光学系统与服务器。


PacBio Sequel的SMRT Cell芯片相较上一代的RSII大了一些,样子变化也较大。
芯片上黑色柱状体用于机械臂插取、移动芯片。右下角的圆形凹槽为激光射入点,红绿混合激光从该点射入均匀的照射在金灿灿的芯片底部(图中闪着金光的矩形部分即为拥有100万个ZMW的测序芯片)芯片作为一个独立的无盖长方体反应槽的底部,机器臂将待测模板以及相应的测序试剂Mix加入该长方体反应槽中即可,其不同于“短读长大规模平行测序技术”(每个测序Cycle都需要加入新的dNTP、二价金属离子、聚合酶等,待完成采图再做Washing)所有物料只需添加一次即可完成整个测序反应,因此SMRT Cell叫Cell,而不能叫Flowcell。


从芯片的背面可以看出,CMOS与测序Cell结合,即Sequel并不靠相机拍照来记录碱基信息,每一个ZMW底部都对应一个CMOS感受器,可以将荧光信号转化为电信号从而完成碱基的识别与储存,这与ion Torrent、iseq100的原理类似,这也意味着Pacbio对于文库多样性要求更低。


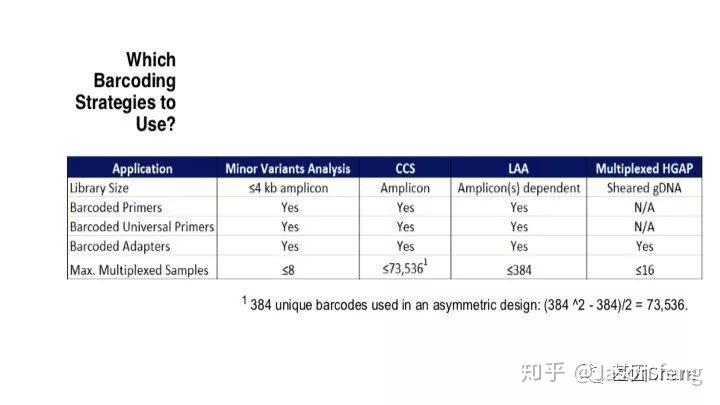
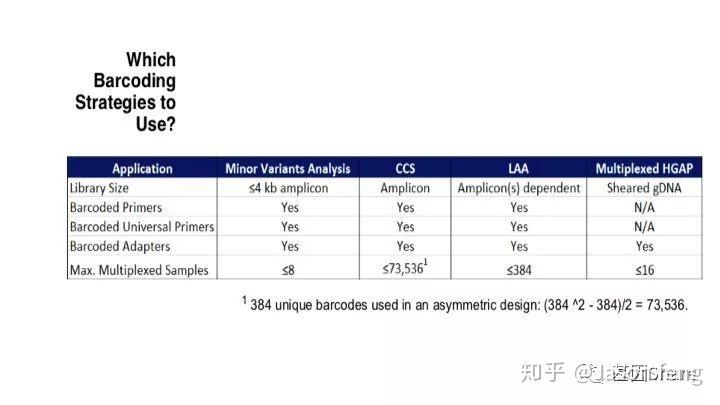
PB目前的Barcode策略(不在赘述,与其他技术基本类似)
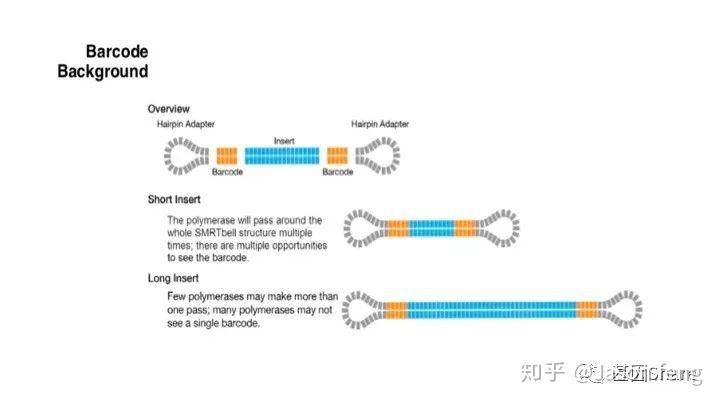
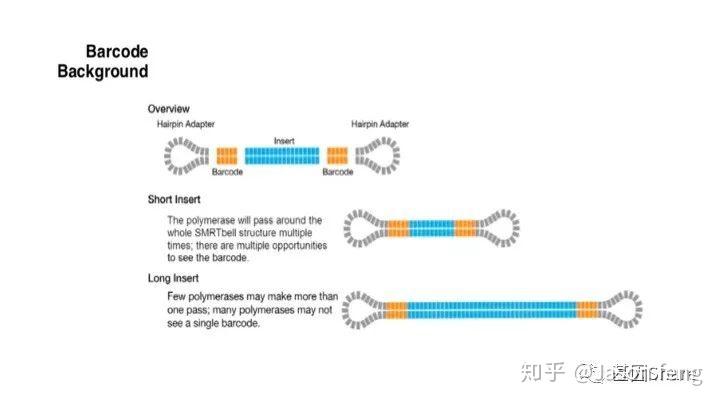
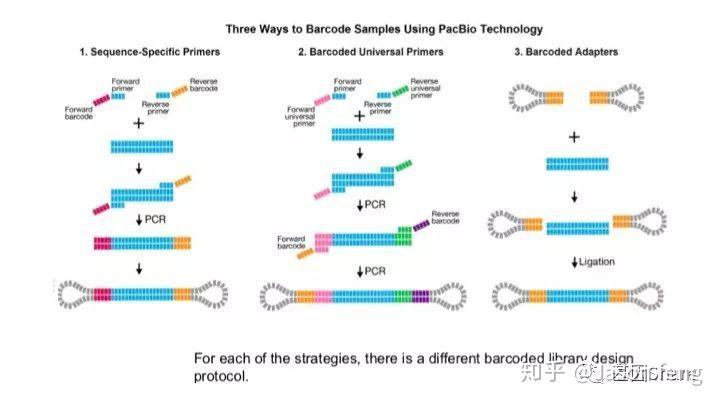
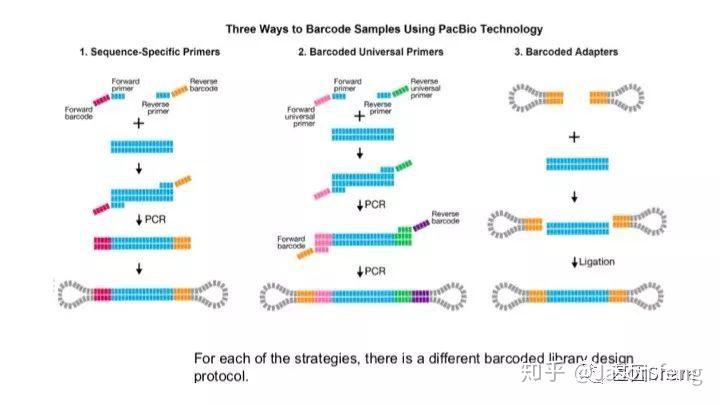
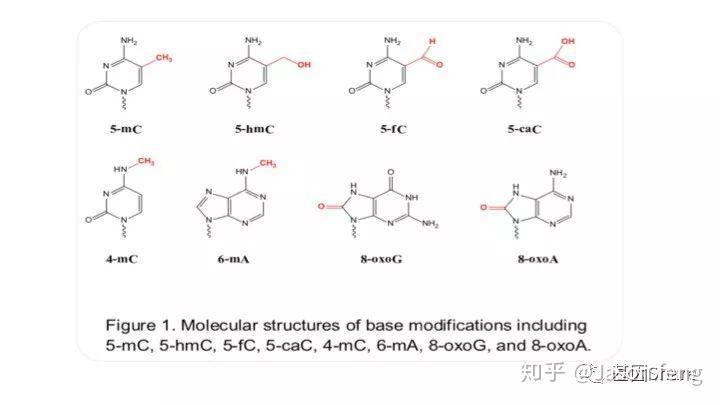
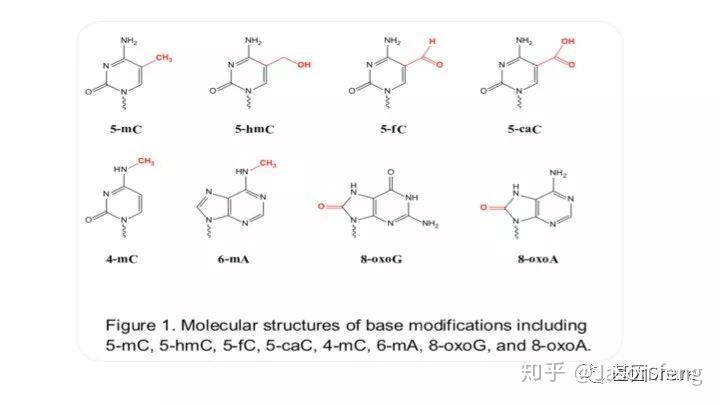
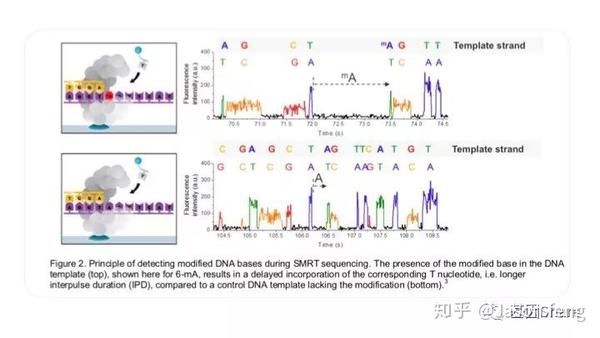
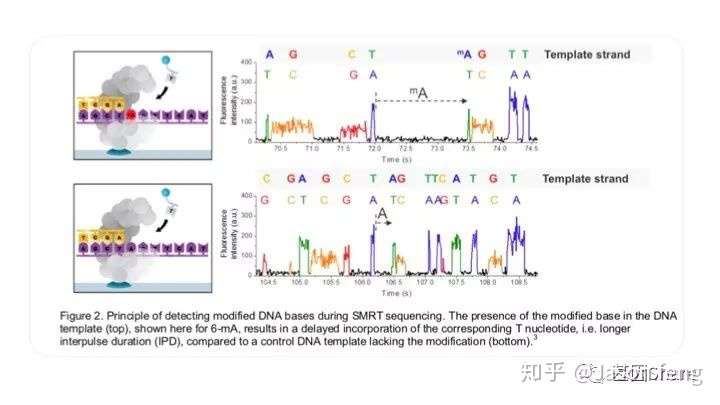
PB可直接读取碱基修饰信息(具体原理及应用不再赘述,可参考其他相关材料)


华大科技武汉交付中心的Sequel实验室
说明:1.由于篇幅限制,对部分内容进行了省略、简述处理,如文章内容表述有不当之处,烦请拨冗指正,互相交流。
2. 部分图片来自于网络,如有侵权请联系删除。
最后,感谢华大科技 Sequel组的吴传文老师的指导与帮助,谢谢大家支持,欢迎关注“基因Share”
追求极致的匠人精神

















 1147
1147











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









