









大模型评测指标集
- (☆)SuperCLUE
- (1)SuperCLUE-V(中文原生多模态理解测评基准)
- (2)SuperCLUE-Auto(汽车大模型测评基准)
- (3)AIGVBench-T2V(文生视频基准测评)
- (4)SuperCLUE-Coder(代码助手测评基准)
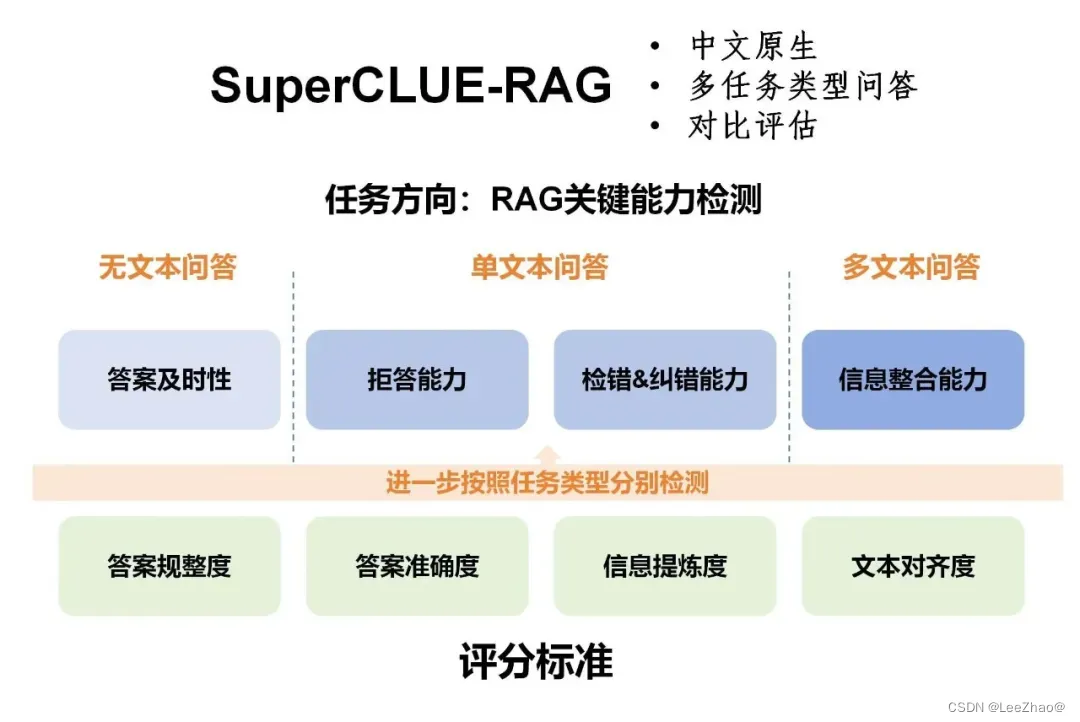
- (5)SuperCLUE-RAG(中文原生检索增强生成测评基准)
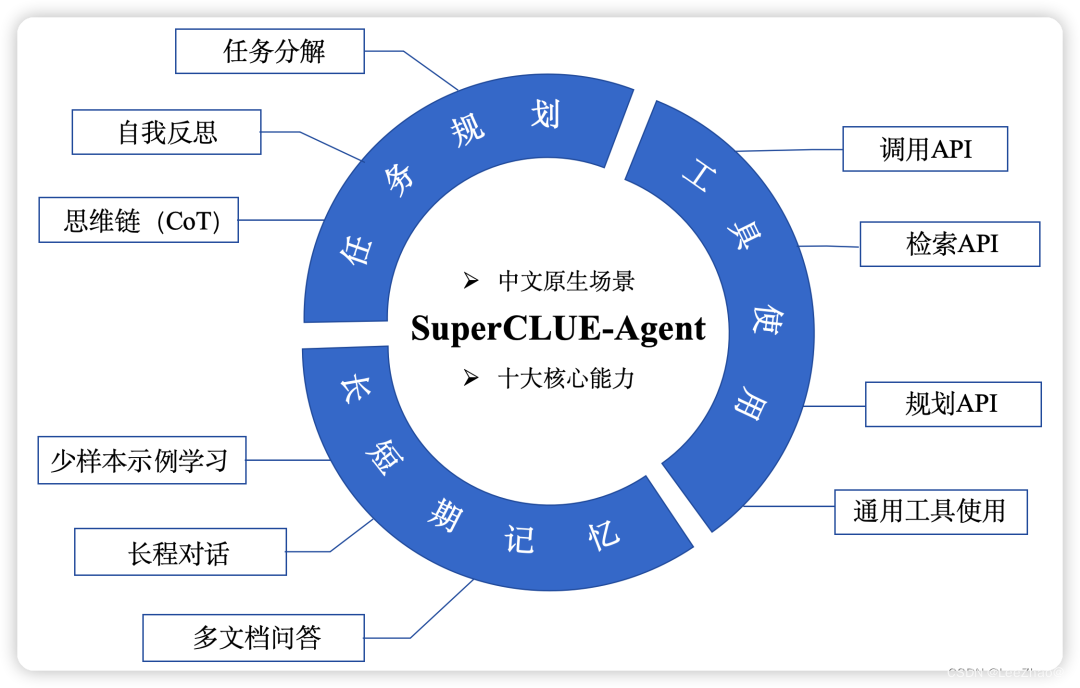
- (6)SuperCLUE-Agent(Agent能力测评基准)
- (7)SuperCLUE-Image(中文原生文生图测评基准)
- (8)“巢燧”(大模型测评基准)
- (9)RAGAs(RAG性能测评)
- (10)社交智能评测基准(情商评测基准)
- (11)SuperCLUE-Reasoning(链式推理测评基准)
- (12)SuperCLUE-T2V(文生视频测评基准)
- (13)SuperCLUE-TTS(中文原生语音合成测评基准)
- (14)SuperCLUE-Voice(实时语音交互中文测评基准)
(☆)SuperCLUE
- CLUE官网: https://www.CLUEBenchmarks.com
- SuperCLUE排行榜网站: https://www.superclueai.com
- Github地址: https://github.com/CLUEbenchmark/SuperCLUE

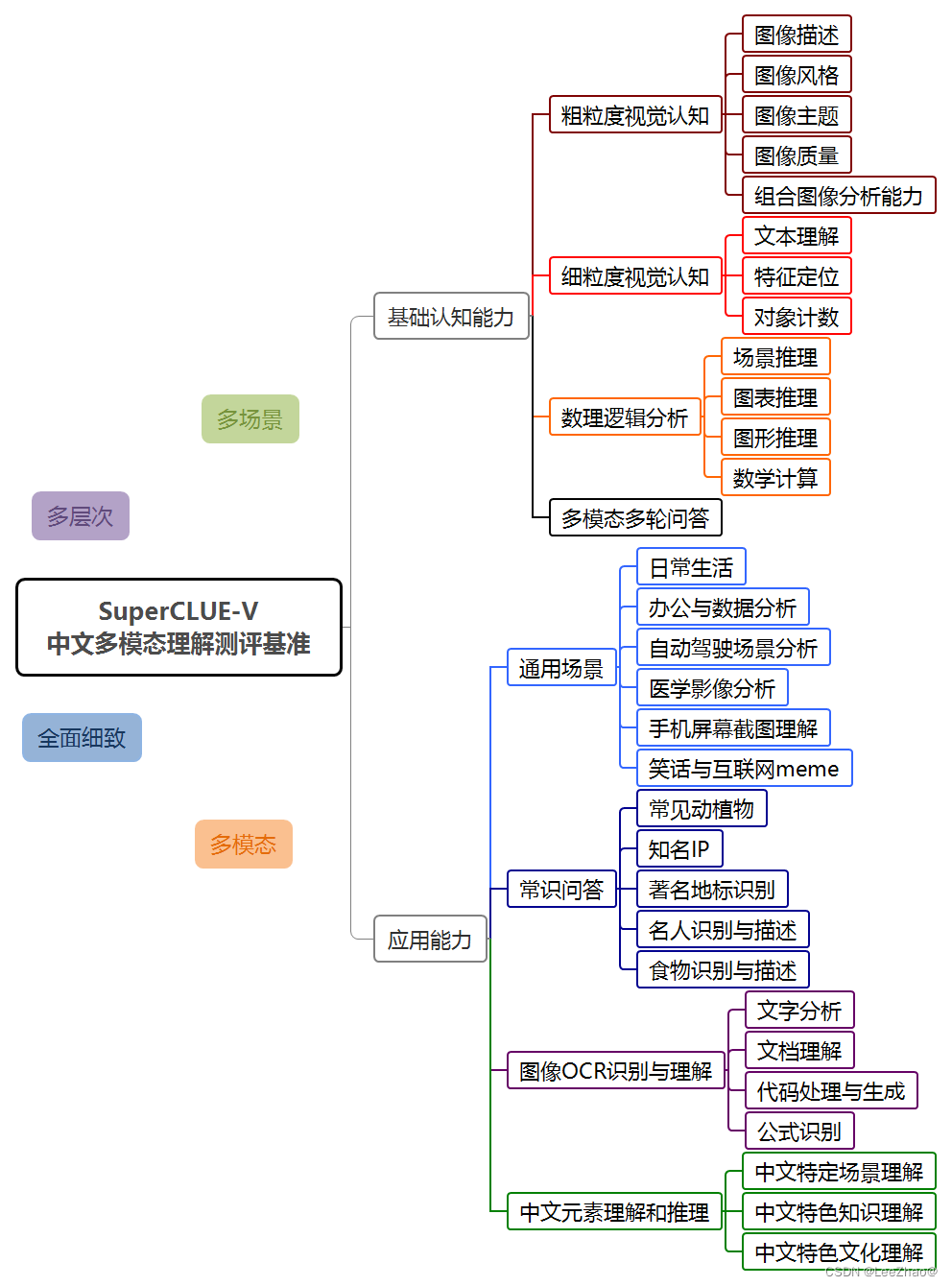
(1)SuperCLUE-V(中文原生多模态理解测评基准)
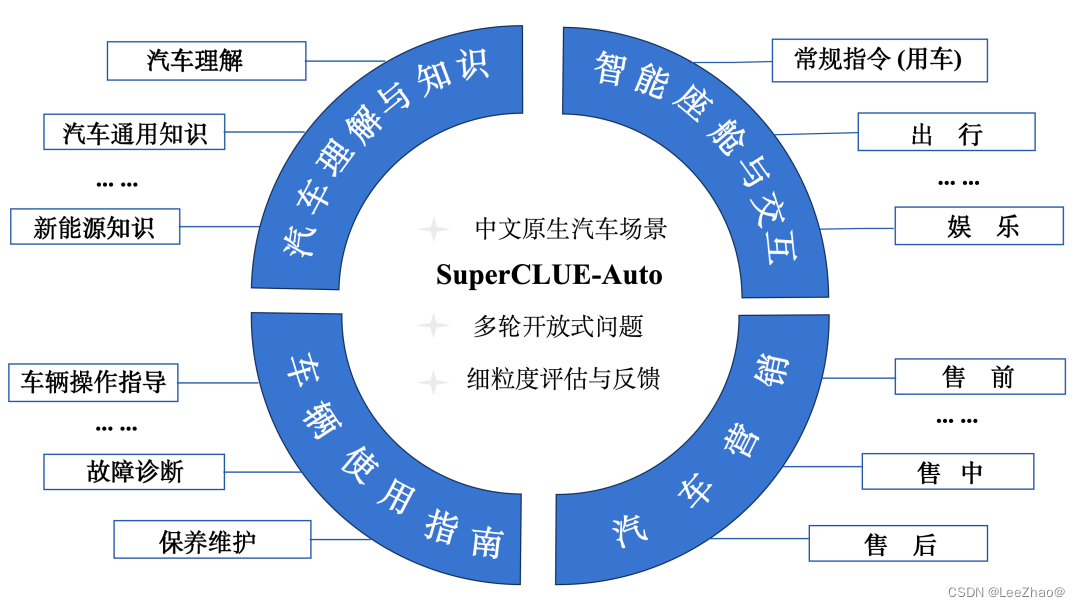
(2)SuperCLUE-Auto(汽车大模型测评基准)
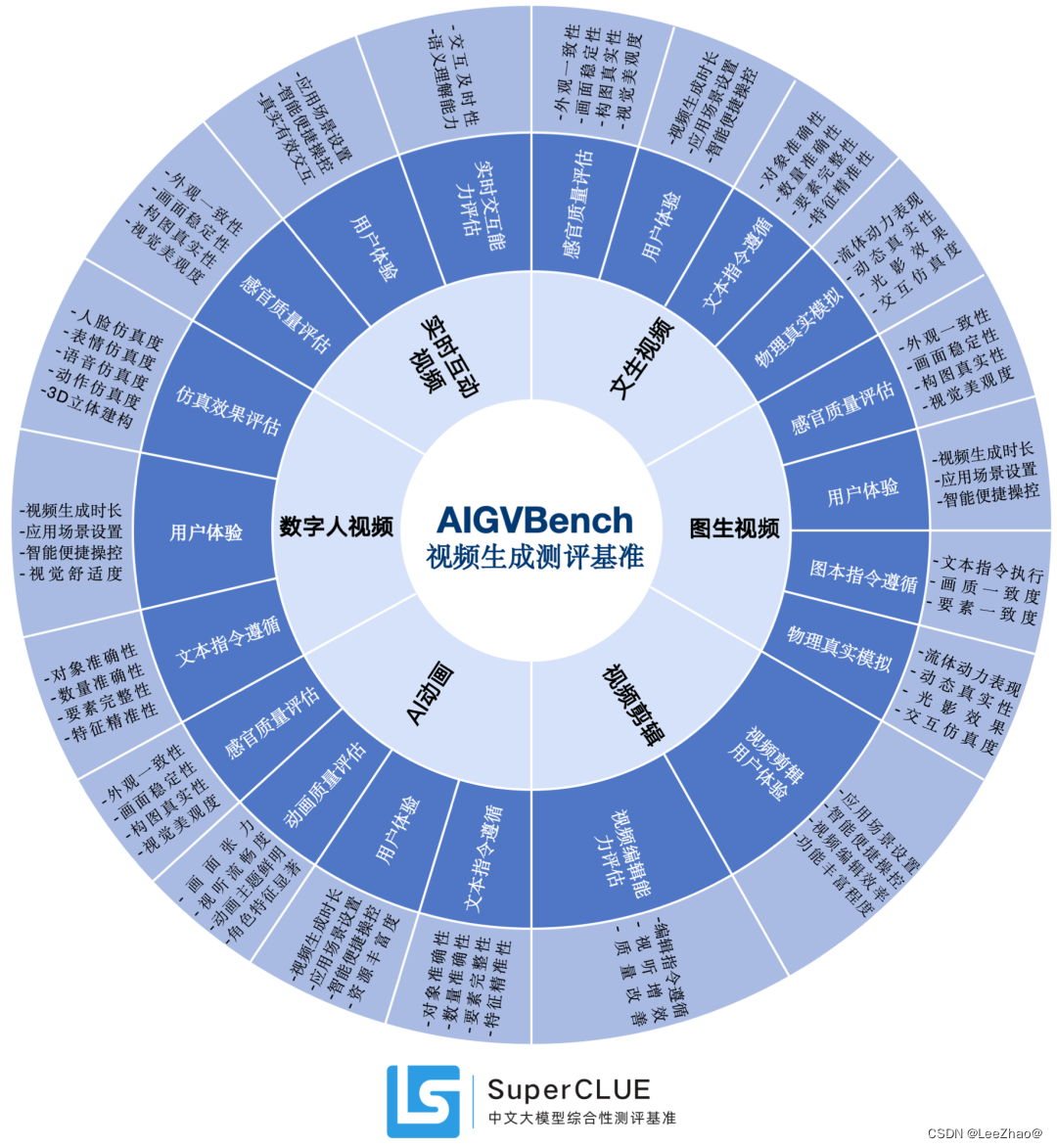
(3)AIGVBench-T2V(文生视频基准测评)
- 推荐文章: AIGVBench文生视频测评首期结果公布,1000个AI视频对比,最高72.9分,Luma仅第3
- AIGVBench登录页: www.AIGVBench.com
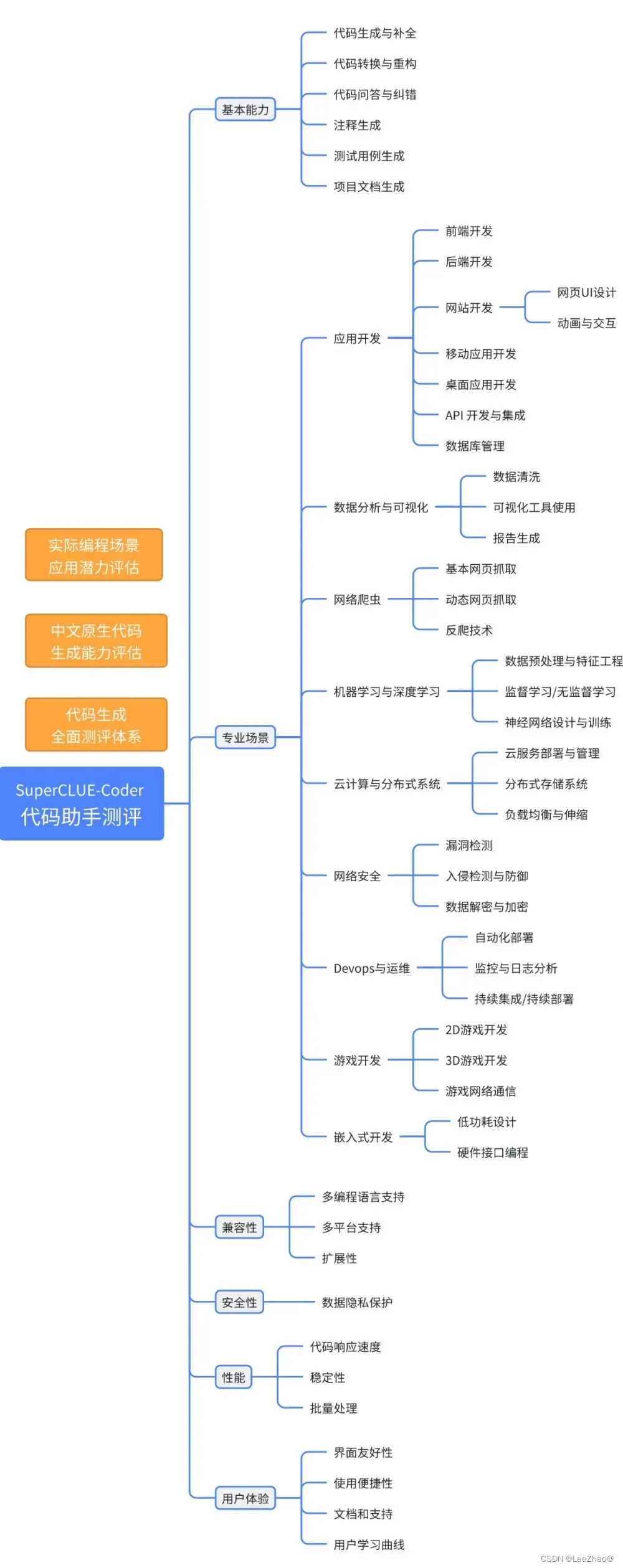
(4)SuperCLUE-Coder(代码助手测评基准)
- 推荐文章: 代码助手测评」启动,SC-Coder测评方案公布
(5)SuperCLUE-RAG(中文原生检索增强生成测评基准)
(6)SuperCLUE-Agent(Agent能力测评基准)
- 推荐文章:
- SuperCLUE-Agent: Agent智能体中文原生任务能力测评基准
- 文生视频大模型测评结果8月首发!AIGV-t2v基准新增4大模型
- 项目地址: https://github.com/CLUEbenchmark/SuperCLUE-Agent
(7)SuperCLUE-Image(中文原生文生图测评基准)
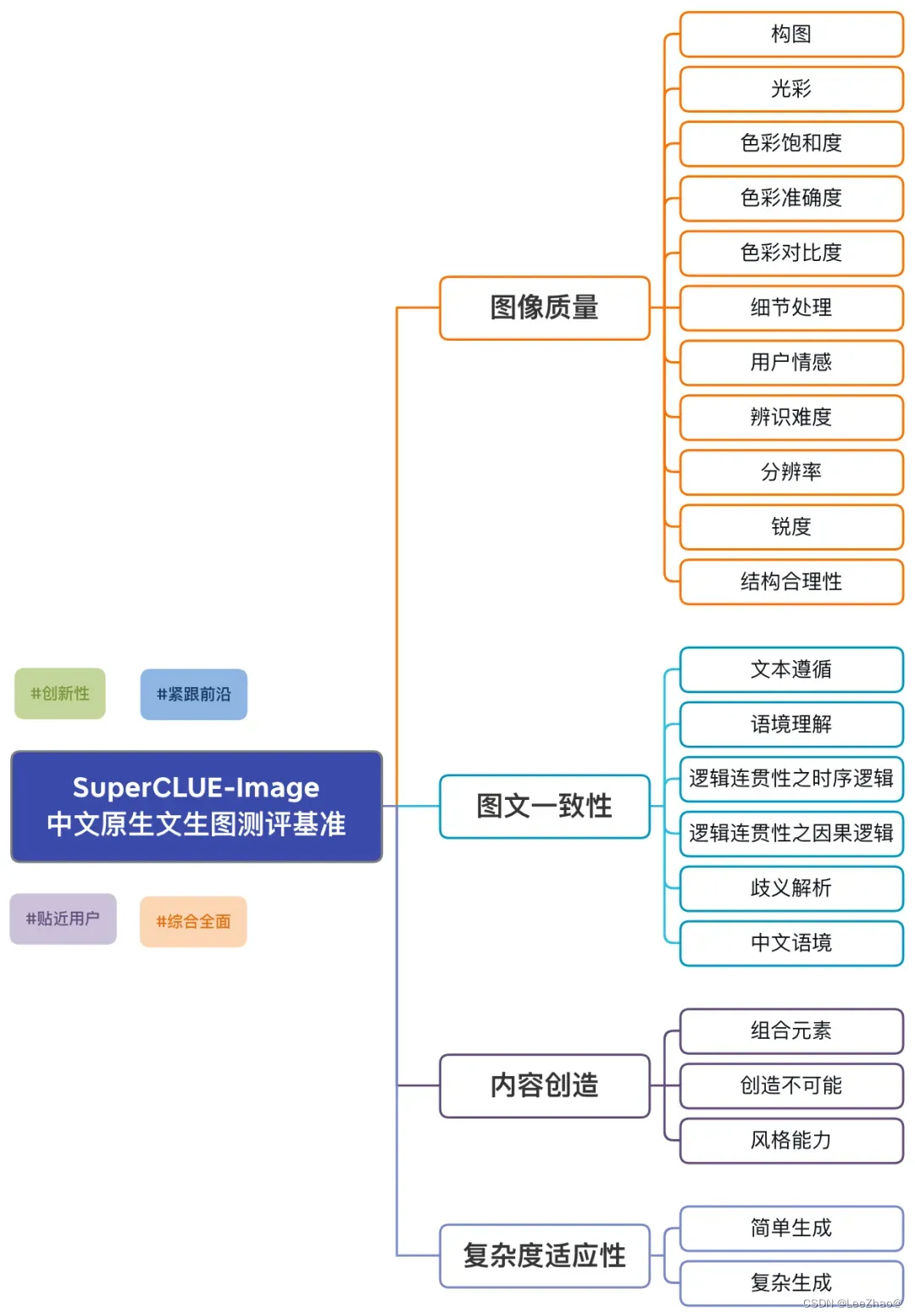
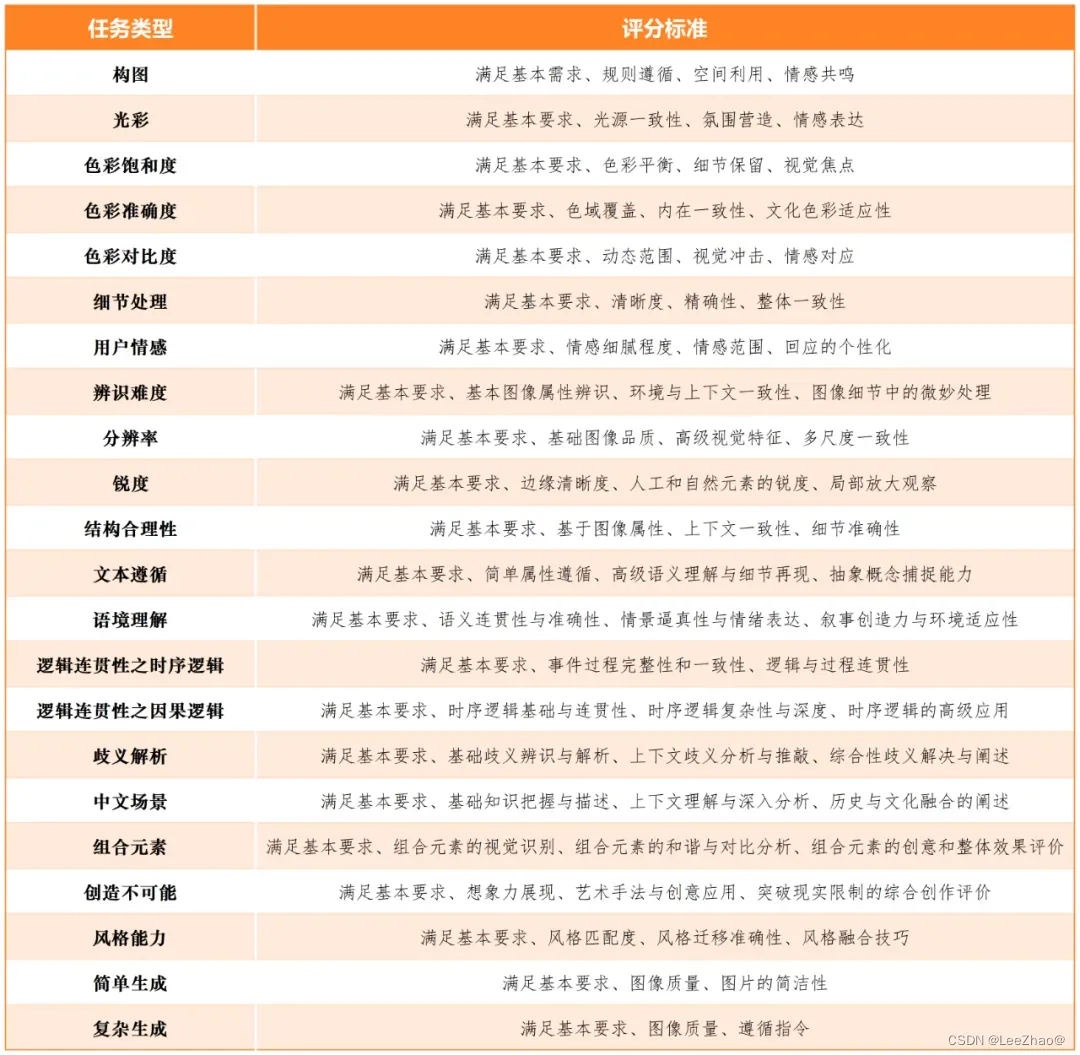
(8)“巢燧”(大模型测评基准)

(9)RAGAs(RAG性能测评)
(10)社交智能评测基准(情商评测基准)
- 推荐文章: 14款大模型“高情商”大比拼:SuperBench大模型社交智能评测报告发布
- 参考文献:
https://arxiv.org/pdf/2402.15052
https://arxiv.org/pdf/2402.12071
(11)SuperCLUE-Reasoning(链式推理测评基准)
- 推荐文章: 中文大模型「链式推理」基准测评方案发布,引入思维链和反思能力考察
- 参考文献: /
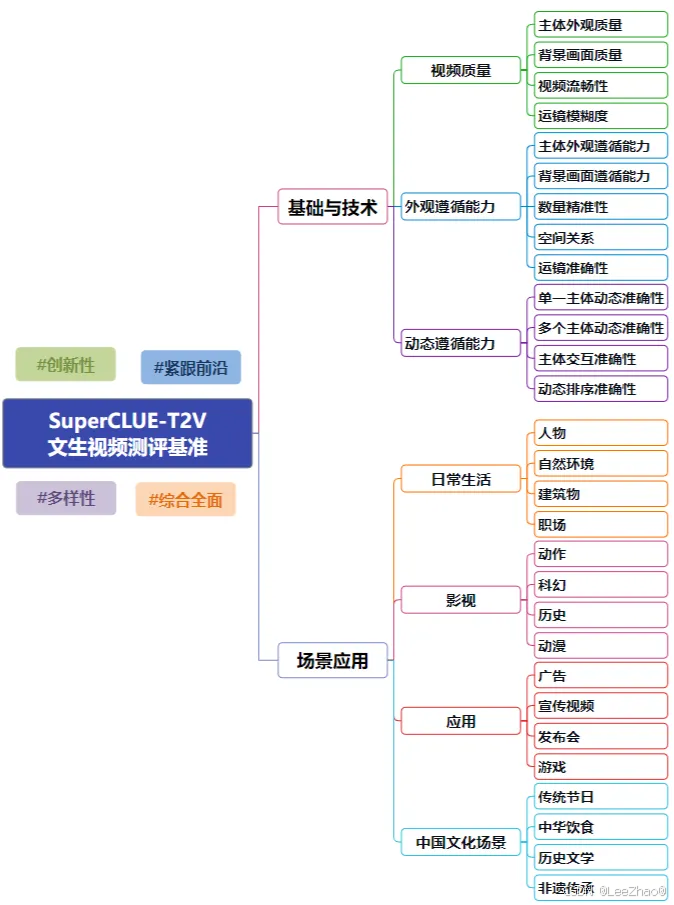
(12)SuperCLUE-T2V(文生视频测评基准)
- 推荐文章: 文生视频大模型「新版」测评基准(方案)发布
- 参考文献: www.SuperCLUEai.com
(13)SuperCLUE-TTS(中文原生语音合成测评基准)
中文原生语音合成测评基准(SuperCLUE-TTS),旨在深入评估新一代语音模型的中文语音合成能力。该基准不仅全面衡量模型在准确性、清晰度、自然度和情感表现等基础能力方面的表现,还重点考察其在语音导航、有声读物、语音播报、内容配音、直播广告等场景应用的适用性。同时,本次测评还单独设置了声音复刻任务,选取了8种不同音色(4男声4女声,分别取自现实名人、网络红人、影视人物、卡通人物,每段素材时长约30秒),用以评估模型对声音的还原与模仿能力。


参考博客: 中文原生「语音合成」测评基准榜单发布!首期声音复刻榜单同步揭晓,豆包模型双榜夺冠!
(14)SuperCLUE-Voice(实时语音交互中文测评基准)
中文原生实时语音交互测评基准(SuperCLUE-Voice)旨在深入评估新一代实时语音交互产品在中文语音交互中的整体表现。该基准不仅全面考察产品在打断、说话风格等语音交互核心能力上的表现,还重点评估其在记忆能力、联网能力等通用能力上的综合水平。同时,测评还特别关注产品在实时翻译、教育辅导等五大实际应用场景中的表现,旨在为语音交互技术的多场景落地提供全面的评判标准。



参考博客: 实时语音交互中文基准12月测评结果出炉,4大维度15项能力8款应用,讯飞星火领跑,国内产品延时、打断和场景应用表现出色


















 1205
1205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









