








主要贡献
- 提出一种新的基于学习的多视图2D / 3D刚性配准方法,该方法通过利用X射线和DRR之间的点对点对应关系直接测量3D对齐误差,从而避免了昂贵且不可靠的迭代姿势搜索,从而提供了更快,更可靠的配准。
- 提出一种新颖的POI跟踪网络,该网络使用具有兴趣点(POI)卷积的Siamese U-Net构建,从而能够进行细化的特征提取和有效的POI相似性度量,更重要的是,它提供了对以下各项具有鲁棒性的平移不变二维失准度量:
- POI跟踪器和三角测量层的统一框架,可实现(i)端到端的2D特征学习和(ii)3D姿态估计
- 对大规模且具有挑战性的临床锥形束CT(CBCT)数据集进行了广泛的评估,结果表明,所提出的方法比基于最新学习方法的方法性能显着提高,并且在用作初始方法时姿态估计器,它也大大提高了基于最新优化的方法的鲁棒性和速度。
相关工作总结
- Optimization-based approaches
需要进行大量DRR渲染和相似性度量计算花费高,花费时间太多,且对初始参数比较敏感,鲁棒性不高。一些方法提出来加速DRR渲染,但配准总体时间难以满足达到实时的要求。另外一些方法来提高鲁棒性,但是这些方法通常要花费更长的时间。 - Learning-based approaches
训练网络直接预测3D姿势,这种方法往往过于自信并且依赖于不透明物的存在。一种替代的方式将配准描述成一个马尔可夫决策过程。但是这种方法代理在大量数据集上训练来让配准向期望的方向进行,尽管通过多代理设计可以得以缓解[,但是,邻域搜索可能会达到一个无法预见的状态并且使配准失败。所以此方法通常在配准中用于寻找一个好的初始姿势。
方法
由于单视图2D / 3D配准是一个不适定的问题(由于平面外的偏移引入了模糊性),因此在干预期间通常会捕获来自多个视图的X射线。这篇文章根据“ A review of 3d/2d registration methods for imageguided interventions”解决一个多视角配准问题。
- 问题描述
- 2D/3D Rigid Registration with DRRs.:
在2D / 3D刚性配准中,患者和CT体V之间的不对准是通过转换矩阵T来解决的,该转换矩阵T将V从其初始位置移至患者的所在坐标系下的的同一位置。T如下公式,主要由旋转矩阵和平移向量构成,T可以通过六个参数计算得来,分别是沿着三个周偏移量和旋转量。
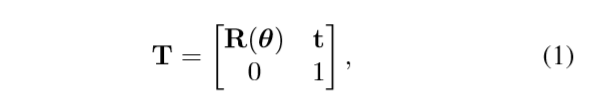
- X-Ray Imaging Model

在规范视角下, DRR成像模型如下公式:
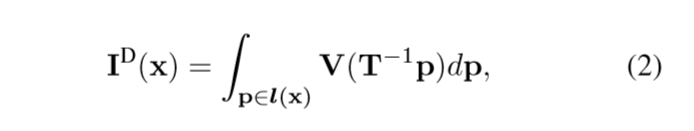
在 isocenter 坐标系中的点X =(X,Y,Z)T被映射到检测器的齐次坐标通过下面公式计算:

这里 x′ = (x′,y′,z′) 是齐次坐标,转化成检测器坐标为:x = (x,y) = (x′/z′,y′/z′).,
在非规范视角下,点X映射的齐次坐标公式和成像公式变为:
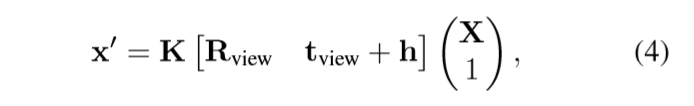
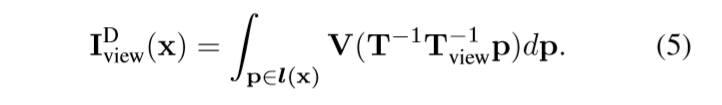
- The Proposed POINT2 Approach
该方法大致流程:
(a)给定一组不同视角的DRR和X-Ray图对,首先从CT体中选择一组三维兴趣点(POI),并使用方程(4)将它们投影到每个DRR,如图所示。
(b)追踪这些POIs对应于X-ray图上的点,
(c)根据X-ray图上跟踪到的POIs,通过三角测量来估计其在患者身上的相应3D POIs
(d)通过将CT 的POI与患者POI对齐,可以计算出CT与患者之间的姿势偏差T*

- POINT.
该方法的关键组成部分之一是用于跟踪感兴趣点的网络,寻找两幅图像之点与点的对应关系。网路结构如下:

- 输入为: DRR(ID), X-ray (Ix)和一组映射到DRR上的POIs{x1D,…,xmD}。
- 网络再经过两个权值共享的U-net网络分别对ID和Ix进行特征提取,得到 FD 和 Fx。根据DRR上的POIs提取出 FD对应位置以及领域像素作为特征向量FD (xiD),称作特征核。
- POIs conv layer: 将上面提取出的特征核与Fx的每个位置进行相似性计算,取相似性最大的位置作为匹配点,这种操作类似与卷积操作,因此把他设计成一个卷积层,输出是每个DRR图的POI与X-ray图每个位置的相似度分数的热图。
W的值表示特征核对应位置上的重要性,此方式来代替相似性度量,是否有更好的方法来近似相似性度量?

其中U-net结构为: 分为两个阶段收缩和扩展,收缩层依次进行 3x3conv. + 3x3conv. + ReLu + maxpooling;扩展层依次进行 反卷积(上采样)+ concatenate + 3x3conv.+ReLu +3x3conv.+ReLu)
- POINT2
通过跟踪不同视角X-ray图的POIs,使用Triangulation获得它们在患者身上的3D位置。但是,本文寻求一个统一的解决方案,使在同一框架下制定POINT网络和三角剖分,以便可以以端到端的方式共同训练这两项任务,这可能有益于跟踪网络的学习。如下图所示,注意,两个网络权值并不共享,因为他们分别设计用来追踪不同视点的POIs。
当获得heatmaps后,本文运用三角剖分层,通过跟踪多视角X-ray的POI,形成三角形来定位三维点。

追踪X-ray的POI通过以下(重心)计算可得:
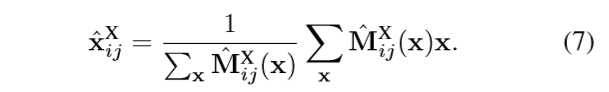
个人疑问:heatmaps的每个值表示相似性分数,对于某一个兴趣点来说,其heatmap上对应点以及周围的区域的值应该较大,但是在X-ray上很有可能有多个相似度比较高的点,这样heatmap上存在多个分数较高的区域使重心发生偏移,找到的对应点并不在这些高相似性分数区域,反而可能在相似性分数低的地方,这可能与事实不太符合,可能不能正确的找到对对应点的位置。
然后文中将公式(4)改写为:
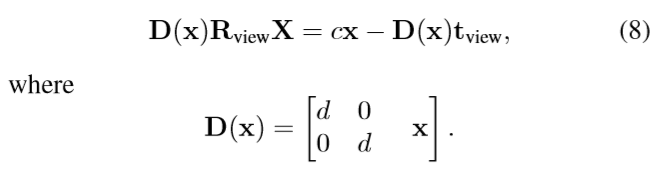

这样改写的目的是: 我们需要通过被追踪的X-ray的POIs定位patient对应兴趣点的空间坐标,也就是求(8)中的X,通过这样的转换,可以根据以(7)得到的x直接构建一个线性方程,方便接下来的求解,在多视角下可得线性方程组:

就可以通过(11)直接解的X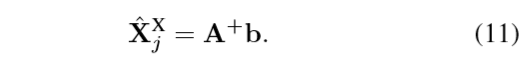
训练时,把triangulation 加入到loss中正则化POINT网络:
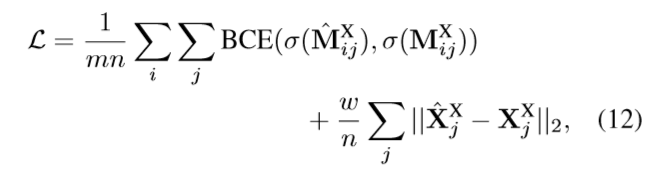
5**. 形状对齐**
通过以上方式计算得到了patient身上的坐标值PX,然后用现有方法寻找一个转换矩阵T*将 PD和PX,通过Procrustes分析可以解决此问题。
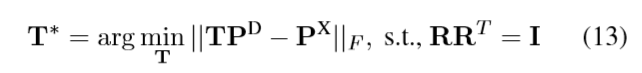
实验
到这里全文整个方法讲解完毕,实验中证明了方法中W是否有作用,特征核大小的选取,以及兴趣点的选择方式,最后通过mTRE,GFR(总错误率)以及配准时间跟现有算法做比较,总体有一个很好的结果。














 2289
2289











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









