









PVNet论文笔记
论文主页,包括了一个实时AR demo:https://zju3dv.github.io/pvnet/
论文代码:https://github.com/zju3dv/pvnet
作者还开源了他们用blender合成数据代码:https://github.com/zju3dv/pvnet-rendering
主要贡献
本文解决了在严重遮挡或截断情况下从单个RGB图像进行6DoF姿态估计的挑战。作者认为解决遮挡和截断需要密集的预测,即最终输出或中间表示的逐像素或逐块估计。 为此,提出了
- 一种使用逐像素投票网络(PVNet)进行6D姿态估计的新颖框架,该框架学习了用于鲁棒2D关键点定位的矢量场表示,并自然地处理了遮挡和截断。
- 我们提出基于PVNet的密集预测,利用不确定性驱动的PnP算法来解决2D关键点定位中的不确定性。
介绍和现状
传统方法表明: 可以通过建立对象图像与对象模型之间的对应关系来实现姿势估计。 他们依靠手工制作的特征,这些特征对图像的变化和背景杂乱不敏感。
基于深度学习的方法: 训练以图像为输入,输出相应姿态的端到端神经网络。但是,泛化能力仍然是一个问题,因为尚不清楚这种端到端方法是否可以学习足够的特征表示来进行姿势估计。
近期的方法: 先用CNN回归2D点,再运用Perspective-n-Point(PnP) algorithm来计算6D姿态参数。但是,由于这些方法的某些关键点是看不见的,因此它们在处理遮挡物和截断物方面存在困难。
本文的方法: 解决遮挡和截断需要密集的预测,即最终输出或中间表示的逐像素或逐块估计。 为此,提出了一种使用逐像素投票网络(PVNet)进行6D姿态估计的新颖框架。PVNet 预测表示从对象的每个像素到关键点的方向的单位矢量。 然后,运用这些表示根据RANSAC为关键点方向投票。该方法实质上是为关键点定位创建矢量场表示,与基于坐标或热图的表示形式不同
相关工作
总体的方法:在给定一幅图像的情况下,一些方法的目的是估计物体在一次拍摄中的三维位置和方向。
基于关键点的方法:不是直接从图像中获取姿态,而是采用两步骤:首先对目标进行预测,然后用PnP算法通过二维到三维的对应关系计算姿态。
密集的方法:每一个像素或补丁产生对期望输出的预测,然后在广义霍夫(Hough)投票方案中对最终结果进行投票[使用随机森林预测每个像素的三维对象坐标,并使用几何约束生成二维-三维对应假设。但由于输出空间较大,回归目标坐标比关键点检测更困难
方法
6自由度(Dof)目标姿态估计: 给定图像,姿势估计的任务是检测对象并估计其方向和3D平移。 具体来说,从物体坐标系到摄像机坐标系的刚性变换(R; t)表示6D姿态
本文的方法是使用类似于RANSAC方式的像素级投票网络(PVNet)来检测2D关键点,并鲁棒地处理被遮挡和被截断的对象。 基于RANSAC的投票还给出了每个关键点的空间概率分布,从而使我们能够利用不确定性驱动的PnP来估算6D姿态。
论文的方法也分为两步: 首先,使用PVNet(Pixel-wise Voting Network)进行2D目标关键点检测,;然后,使用PnP算法计算 6D 位姿。

Voting-based key-point localization
PVNet逐像素的预测对象标签和单位矢量,它们代表每个像素到每个关键点的方向。 给定属于某个对象的所有像素到该对象关键点的方向,我们针对该关键点生成2D位置的假设以及通过基于RANSAC的投票的置信度得分。基于这些假设,我们估计每个关键点的空间概率分布的均值和协方差。
( RANSAC: 随机抽样一致算法是为了排除数据集中的异常数据,它是根据一组包含异常数据(外点)的样本数据集,计算出数据的数学模型参数,得到有效样本数据的算法。RANSAC通过选择数据中的一组随机子集作,被选取的子集被假设为局内点,根据这些内点计算模型,并进行评估,模型去测试所有数据,将满足模型的点作为内点,反复迭代一定的次数。)
PVNet分为两个任务,1.语义分割,2.向量场预测。对于每一个像素,生成一个语义标签和一组单位向量,每个单位向量vk(p )表示该像素p到该像素所属对象的关键点xk的方向。
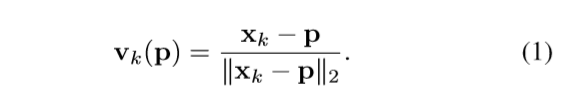
通过语义标签就可以找到这个对象,然后在对象上随机选取两个像素点p1,p2,把vk(p1)和vk(p2)的交点作为关键点xk的一个假设点hk,i.重复N次生成一组假设点,表示该关键点的可能位置。
最后,对象的所有像素为这些假设点进行投票,hk,i的投票分数wk,i: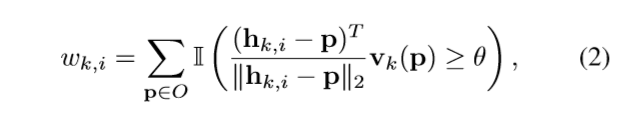
公式表明投票机制为:PVNet预测的某一像素点到第k个关键点的方向与实际该像素点到该关键点的第i个假设点的方向,相似度达到达到θ,这该像第素为这个假设点投一票。

所得到的假设描述了图像中关键点的空间概率分布,其均值 µk 和协方差Σk 计算方式如下:

Key-point selection
本文通过简单实验证明,选取目标表面点比选取模型bounding box的角点进行关键点预测出来的分布,方差更小,更稳定。本文采取在目标表面选取关键点,遍布整个目标是PnP算法更稳定。文中使用最远点采样(farthest point sampling ,FPS )算法选取K个keypoint。
FPS : 选取一个点(本文选取目标的中心)添加到集合中进行初始化,然后,选取离当前集合最远的(文中采取的是目标表面)点加入到集合中,反复进行直到选满K个。(点与集合的距离定义为点与集合中所有点的距离的最小值)
Uncertainty-driven PnP
给定每个对象的2D关键点位置,其6D位姿可以通过使用现成的PnP求解器解决PnP问题来计算,例如之前那些方法大多使用EPnP,但是,它们大多忽略了不同的关键点可能具有不同的置信度和不确定性模式,这是解决PnP问题时应该考虑的问题。
Perspective-n-Point(PnP): 根据n个3D-2D匹配点对,利用最小化重投影误差来求解相机外参的算法。
我们基于投票的方法估计每个关键点的空间概率分布。给定被估计的 µk 和协方差矩阵Σk (k = 1,···, K),我们通过最小化马氏距离计算出6D姿态(R, t):

Xk 是关键点的3D坐标, x˜ k i是Xk的2d映射,π是透视映射函数,参数R和t由EPnP初始化。我们用Levenberg-Marquardt算法通过最小化重映射误差来求解(5),这个算法也同样考虑到了特征的不确定性。
实现细节
C:对象的种类个数
K:每个对象关键点个数
Input: H × W × 3 的RGB图像
output:
- H × W × (K × 2 × C)的张量表示单位向量;
- H×W ×(C+1) 的张量表示所属类别类别的概率
实验中使用预训练的ResNet-18作为骨架网络,但是进行了改动:
- 当网络的feature map的大小为H/8×W/8时,丢弃后续的pooling层来,不再对feature map进行下降采样。为了不改变感受野,取而代之的是:接下来的卷积使用空洞卷积
- 将原ResNet-18中全连接层替换为卷积层。
然后,对特征图反复的执行skip connection, convolution and upsampling 知道特征图大小恢复到 H × W 。通过1×1的卷积在最终的特征图来获得单位向量和类别概率。
使用EPnP进行姿态估计的初始化,使用迭代求解器Ceres来最小化马氏距离(5)。
训练策略
使用平滑 L1 损失来学习单位向量。定义相应的损失函数为:
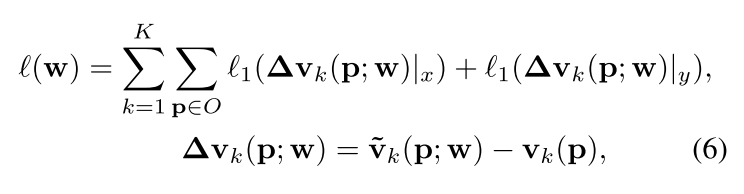
其中,w表示PVNet的参数,v˜k是预测向量,vk是地面真实单位向量。
使用 softmax cross-entropy 损失来训练语义标签。
实验
数据集
在训练中只使用LINEMOD进行训练,并测试Occlusion和Truncation LINEMOD数据集
LINEMOD: 6D目标姿态估计的标准基准。
Occlusion LINEMOD: 是通过对LINEMOD图像附加标注而创建的一个子集。每个图像包含多个带标注的对象,这些对象被严重遮挡,这对姿态估计提出了很大的挑战
Truncation LINEMOD; 本文创建的一个数据集,通过随机裁剪,只保留目标的40%到60%的区域在图像中。
YCB-Video: 是最近提出的数据集。由于不同的光照条件、严重的图像噪声和遮挡,使该数据集具有挑战性。
评价指标
2D Projection metric: 在给定估计姿态和地面真实姿态的情况下,计算三维模型点投影之间的平均距离。如果距离小于5像素,则姿态被认为是正确的。
ADD metric: 分别通过估计位姿和地面真实位姿对模型点进行变换,并计算两个变换点集之间的平均距离。
消融研究
在 Occlusion LINEMOD数据集上比较不同的关键点检测方法、关键点选择方案、关键点个数和PnP算法的影响。
结论:1.逐素级的投票检测键点对遮挡更有鲁棒性;2.FPS方案选取关键点可以得到更好的姿态估计。3.随着关键点数目的增加,姿态测量的精度也提高了,但“FPS 8”和“FPS 12”之间的差距可以忽略不计。4.考虑关键点位置的不确定性,提高了姿态估计的精度。
对比实验
- LINEMOD数据集的在2D projection metric.指标下表现:

- LINEMOD数据集的在 ADD(-S) 指标下表现:

- Robustness to occlusion.


- Robustness to truncation

- Performance on the YCB-Video dataset

- Running time
给定一个480×640的图像,文中方法在一个带有Intel i7 3.7GHz的CPU和GTX 1080 Ti GPU的台式机上以每秒25帧的速度运行,能够满足实时的姿态估计















 749
749











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









