







1. 前言
什么是 Transformer?如果希望深入理解可以参考:
《NLP深入学习:大模型背后的Transformer模型究竟是什么?(一)》
《NLP深入学习:大模型背后的Transformer模型究竟是什么?(二)》
本文主要介绍常常听到的 Transformer Block 的概念,以及如何实现一个 Transformer Block。
2. Transformer Block
回顾一下 Transformer 的完整模型:
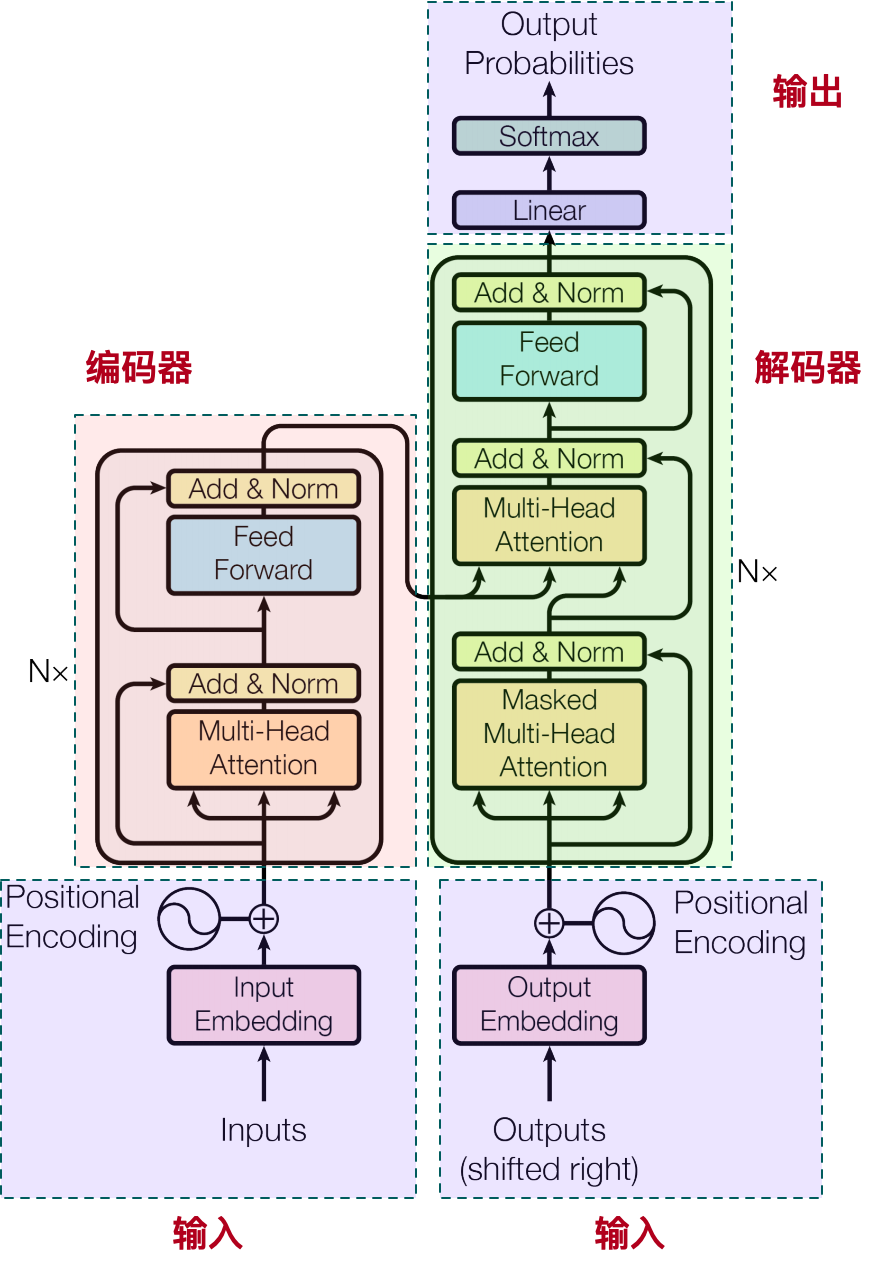
我们常说的 Transformer Block 对应图中解码器的上部分。为了具体展示流程,我们假设有一句话:“Every effort moves you” 作为输入,经过蓝色框中的 Transformer Block 之后输出,如下图:

图中蓝色的部分就是所谓的 Transformer Block。
3. 代码实现
BERT 源码已经实现了 Transformer 的细节,完整源码参考 Pytorch Bert,这里把 Transformer Block 实现的框架贴出来
import torch.nn as nn
from .attention import MultiHeadedAttention
from .utils import SublayerConnection, PositionwiseFeedForward
class TransformerBlock(nn.Module):
"""
Bidirectional Encoder = Transformer (self-attention)
Transformer = MultiHead_Attention + Feed_Forward with sublayer connection
"""
def __init__(self, hidden, attn_heads, feed_forward_hidden, dropout):
"""
:param hidden: hidden size of transformer
:param attn_heads: head sizes of multi-head attention
:param feed_forward_hidden: feed_forward_hidden, usually 4*hidden_size
:param dropout: dropout rate
"""
super().__init__()
self.attention = MultiHeadedAttention(h=attn_heads, d_model=hidden)
self.feed_forward = PositionwiseFeedForward(d_model=hidden, d_ff=feed_forward_hidden, dropout=dropout)
self.input_sublayer = SublayerConnection(size=hidden, dropout=dropout)
self.output_sublayer = SublayerConnection(size=hidden, dropout=dropout)
self.dropout = nn.Dropout(p=dropout)
def forward(self, x, mask):
x = self.input_sublayer(x, lambda _x: self.attention.forward(_x, _x, _x, mask=mask))
x = self.output_sublayer(x, self.feed_forward)
return self.dropout(x)
4. 参考
《NLP深入学习:大模型背后的Transformer模型究竟是什么?(一)》
《NLP深入学习:大模型背后的Transformer模型究竟是什么?(二)》
欢迎关注本人,我是喜欢搞事的程序猿; 一起进步,一起学习;
欢迎关注知乎/CSDN:SmallerFL;
也欢迎关注我的wx公众号(精选高质量文章):一个比特定乾坤


















 3135
3135

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











