







 超级会员免费看
超级会员免费看
前面讲到过chatgpt的知识,提到了chatgpt的实现原理包含了transformer内容,所有非常有必要来补充一下这部分的内容。
资料:一文读懂「Attention」注意力机制
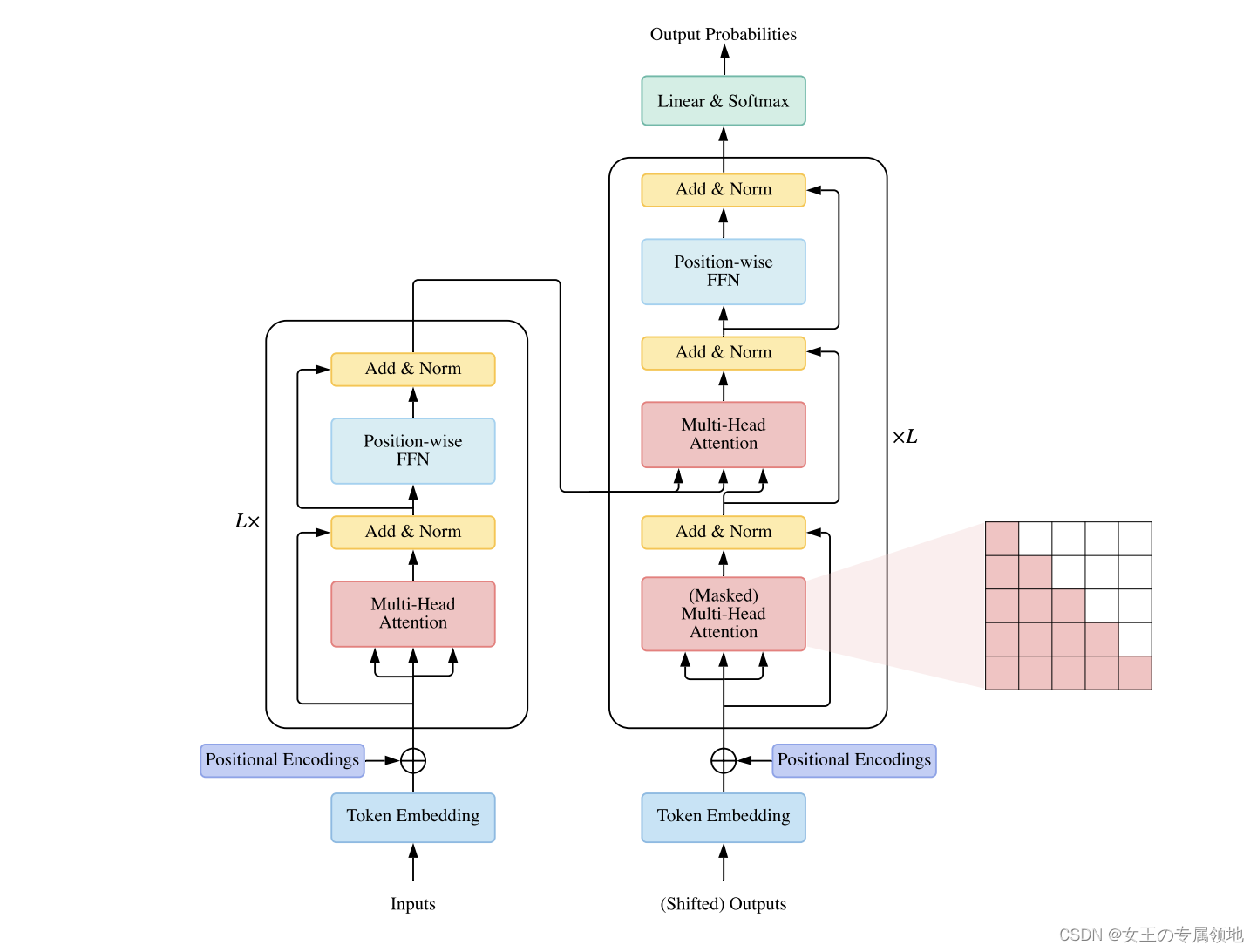
一、什么是Transformer?
Transformer 是 Google 的团队在 2017 年提出的一种 NLP 经典模型,现在比较火热的 Bert 也是基于 Transformer。Transformer 模型使用了 Self-Attention 机制,不采用 RNN 的顺序结构,使得模型可以并行化训练,而且能够拥有全局信息。
🔍 Why Transformer?
- RNN:能够捕获长距离依赖信息,但是无法并行计算;
- CNN:能够并行,无法捕获长

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 5383
5383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











