






一篇论文引发的讨论:
Q:Transformer Layer 和Transformer Block是什么意思?
A: Transformer Layer表示Transformer层,Transformer Block表示Transformer块。
Q:我不是来学英语的,Transformer Layer 和Transformer Block是什么,有什么区别,这张网络图里的哪个部分是Transformer Layer 和Transformer Block?
A: 每个Encoder Block就是一个Transformer block,4个Encoder block 组成一个Transformer Layer。(按照block和layer一样的说法,这里没毛病吧,一百个人一百个哈姆雷特?)
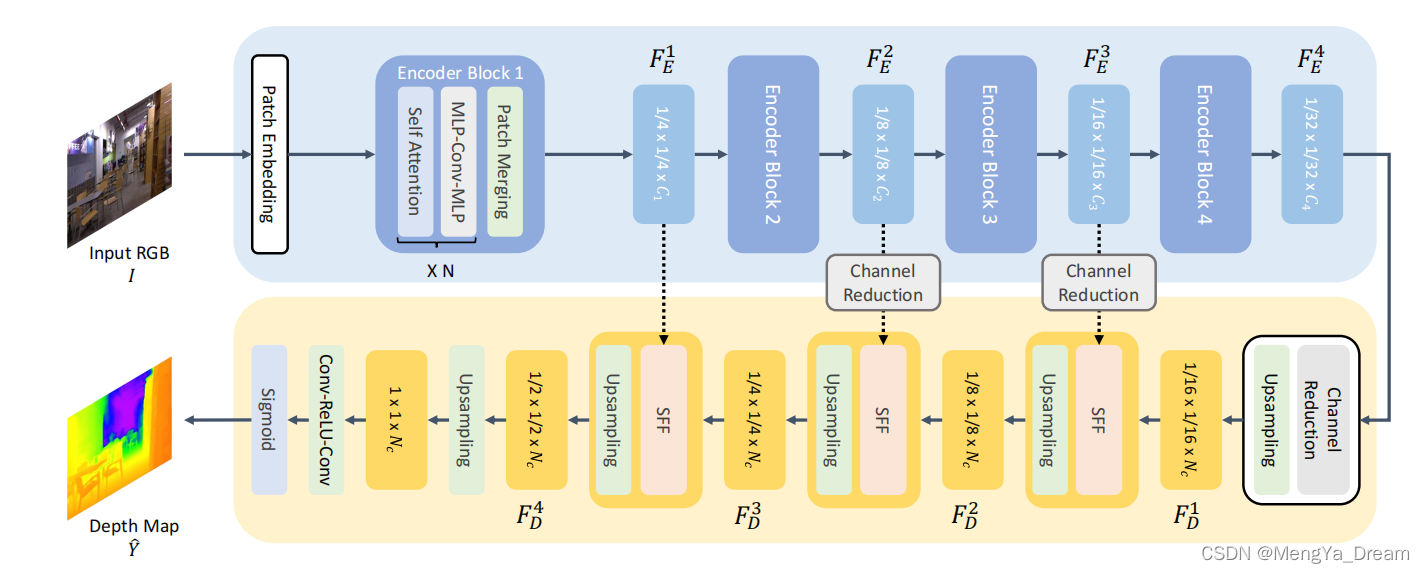
Q:你确定吗?嗯?
A: 没问题啊。
Q:再给你一次机会,Transformer Layer 和Transformer Block是什么,有什么区别?
A: 静默-我搜一下。
Q:别搜了,你看群里我发的图,再解释一下,到底什么是Trans
弄懂Transformer Layer 和Transformer Block的关系后,豁然开朗
最新推荐文章于 2025-03-24 11:47:10 发布

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2006
2006

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











