






认识Jupyter Notebook
matplotlib
为什么学matplotlib
1.能将数据进行可视化,更直观的呈现
2.使数据更加客观、更具说服力
什么是matplotlib
matplotlib: 最流行的Python底层绘图库,主要做数据可视化图表,名字取材于MATLAB,模仿MATLAB构建
matplotlib基本要点

可以做得更好
但是目前存在以下几个问题:
- 设置图片大小(想要一个高清无码大图)
- 保存到本地
- 描述信息,比如x轴和y轴表示什么,这个图表示什么
- 调整x或者y的刻度的间距
- 线条的样式(比如颜色,透明度等)
- 标记出特殊的点(比如告诉别人最高点和最低点在哪里)
- 给图片添加一个水印(防伪,防止盗用)
设置图片大小

调整X或者Y轴上的刻度


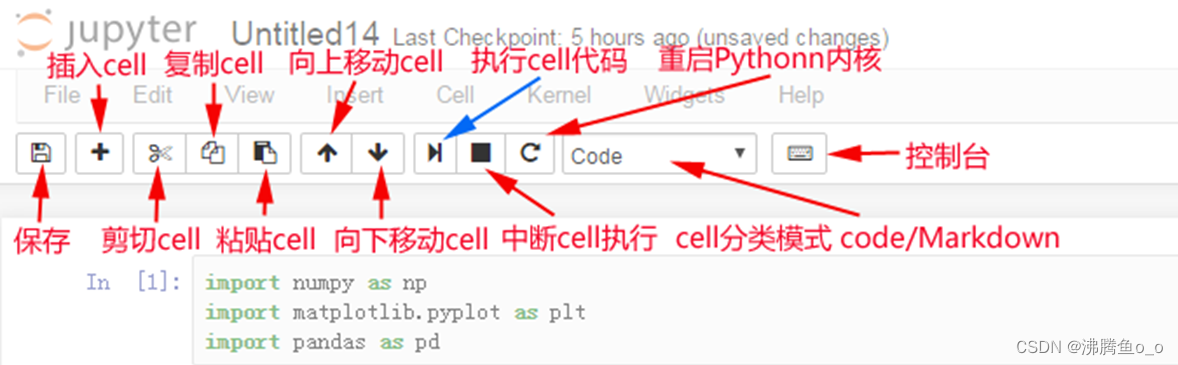
设置中文显示
为什么无法显示中文:
matplotlib默认不支持中文字符,因为默认的英文字体无法显示汉字
查看linux/mac下面支持的字体:
- fc-list 查看支持的字体 fc-list :lang=zh 查看支持的中文(冒号前面有空格)
那么问题来了:如何修改matplotlib的默认字体?
- 通过matplotlib.rc可以修改,具体方法参见源码(windows/linux)
- 通过matplotlib 下的font_manager可以解
给图像添加描述信息

自定义绘制图形风格

添加图例

绘制散点图
技术要点:plt.scatter(x,y)

应用场景
- 不同条件(维度)之间的内在关联关系
- 观察数据的离散聚合程度
绘制条形图




条形图应用场景
- 数量统计
- 频率统计(市场饱和度)
绘制直方图



直方图应用场景
- 用户的年龄分布状态
- 一段时间内用户点击次数的分布状态
- 用户活跃时间的分布状态
更多的绘图工具
- 百度Echarts
- plotly:可视化工具中的github,相比于matplotlib更加简单,图形更加漂亮,同时兼容matplotlib和pandas
- seaborn
Numpy
什么是numpy
一个在Python中做科学计算的基础库,重在数值计算,也是大部分PYTHON科学计算库的基础库,多用于在大型、多维数组上执行数值运算
numpy创建数组(矩阵)

numpy中常见的更多数据类型

数据类型的操作

数组的形状
reshape()里面有几个数就是几维的,注意一位变化时候(24,)不是(24,1)


数组和数的计算



广播原则


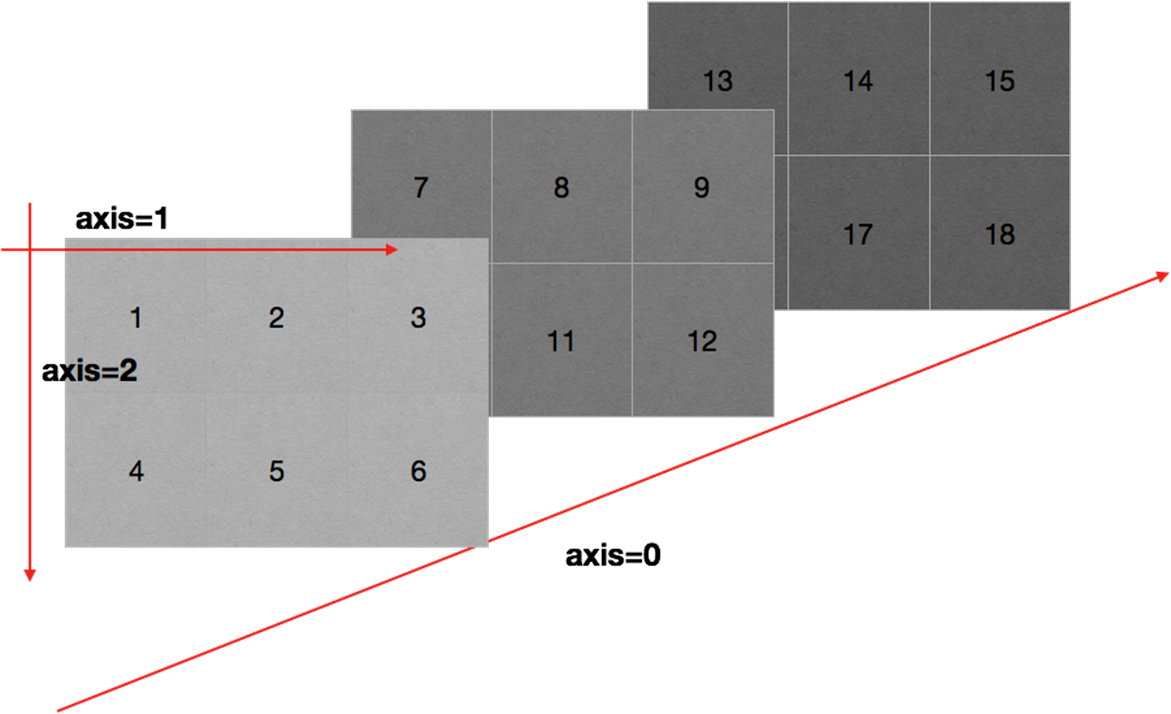
轴
在numpy中可以理解为方向,使用0,1,2…数字表示,对于一个一维数组,只有一个0轴,对于2维数组(shape(2,2)),有0轴和1轴,对于三维数组(shape(2,2, 3)),有0,1,2轴
有了轴的概念之后,我们计算会更加方便,比如计算一个2维数组的平均值,必须指定是计算哪个方向上面的数字的平均值
那么问题来了:
在前面的知识,轴在哪里?
回顾np.arange(0,10).reshape((2,5)),reshpe中2表示0轴长度(包含数据的条数)为2,1轴长度为5,2X5一共10个数据

numpy读取数据
CSV:Comma-Separated Value,逗号分隔值文件
显示:表格状态
源文件:换行和逗号分隔行列的格式化文本,每一行的数据表示一条记录
由于csv便于展示,读取和写入,所以很多地方也是用csv的格式存储和传输中小型的数据,为了方便教学,我们会经常操作csv格式的文件,但是操作数据库中的数据也是很容易的实现的
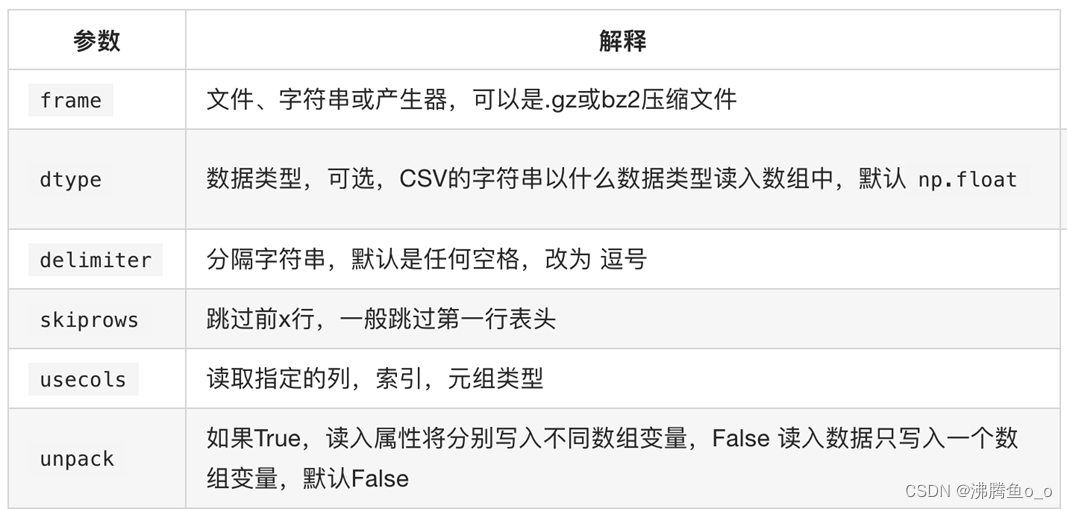
np.loadtxt(fname,dtype=np.float,delimiter=None,skiprows=0,usecols=None,unpack=False)
numpy中的转置
转置是一种变换,对于numpy中的数组来说,就是在对角线方向交换数据,目的也是为了更方便的去处理数据


numpy索引和切片


numpy中数值的修改

numpy中布尔索引
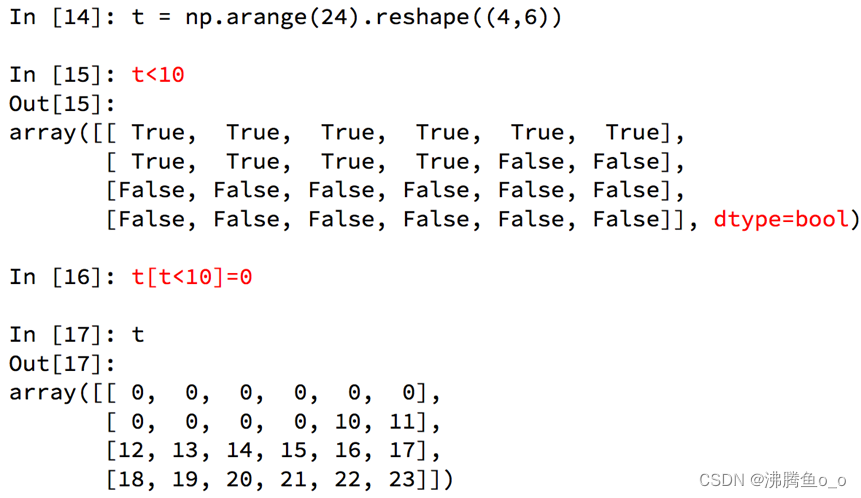
numpy中三元运算符

numpy中的clip(裁剪)

numpy中的nan和inf

numpy中的nan的注意点

那么问题来了,在一组数据中单纯的把nan替换为0,合适么?会带来什么样的影响?
比如,全部替换为0后,替换之前的平均值如果大于0,替换之后的均值肯定会变小,所以更一般的方式是把缺失的数值替换为均值(中值)或者是直接删除有缺失值的一行
那么问题来了:
如何计算一组数据的中值或者是均值
如何删除有缺失数据的那一行(列)[在pandas中介绍]
numpy中常用统计函数

ndarry缺失值填充均值

数组的拼接

数组的行列交换

numpy生成随机数

Pandas
那么问题来了:numpy已经能够帮助我们处理数据,能够结合matplotlib解决我们数据分析的问题,那么pandas学习的目的在什么地方呢?
numpy能够帮我们处理处理数值型数据,但是这还不够
很多时候,我们的数据除了数值之外,还有字符串,还有时间序列等
比如:我们通过爬虫获取到了存储在数据库中的数据
比如:之前youtube的例子中除了数值之外还有国家的信息,视频的分类(tag)信息,标题信息等
所以,numpy能够帮助我们处理数值,但是pandas除了处理数值之外(基于numpy),还能够帮助我们处理其他类型的数据
pandas is an open source, BSD-licensed library providing high-performance, easy-to-use data structures and data analysis tools for the Python programming language.
pandas的常用数据类型
Series 一维,带标签数组
DataFrame 二维,Series容器
pandas之Series创建

pandas之Series切片和索引


pandas之读取外部数据

pandas之DataFrame


pandas之取行或者列

loc

lioc
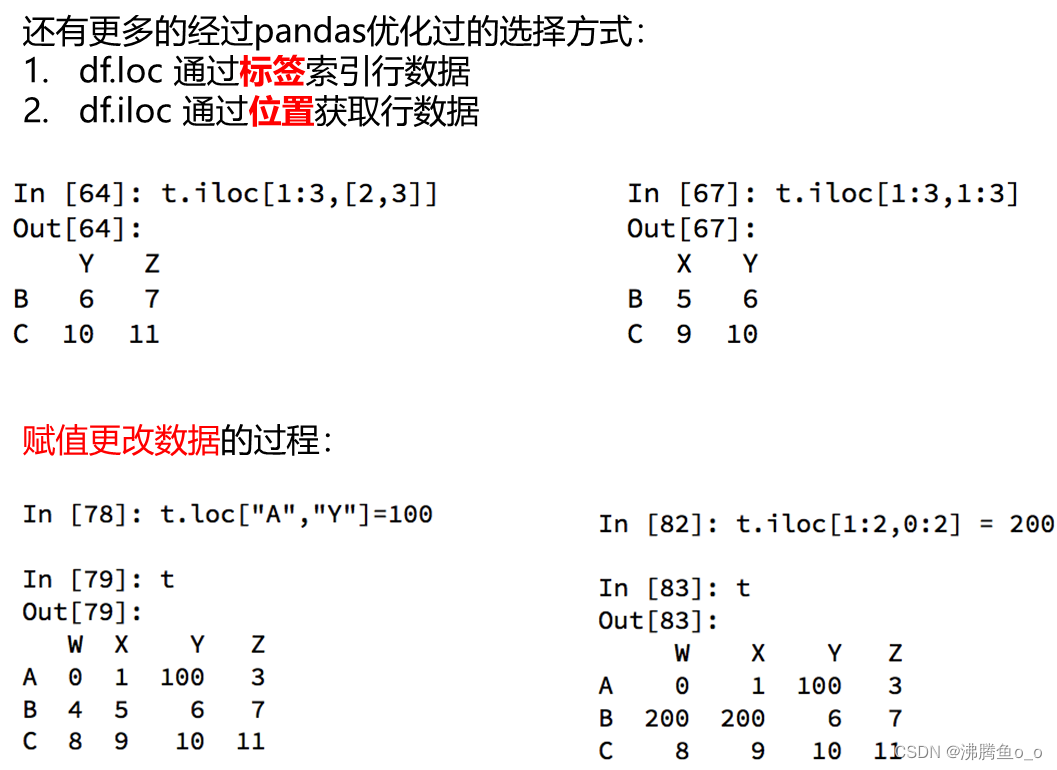
pandas之布尔索引

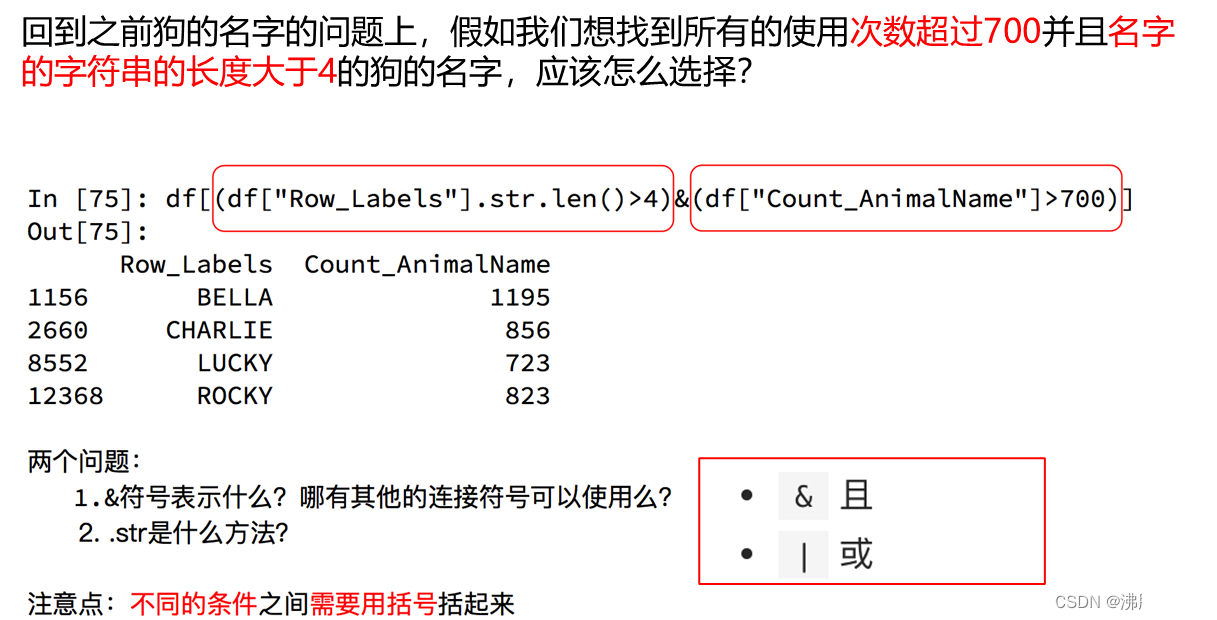
pandas之字符串方法

缺失数据处理
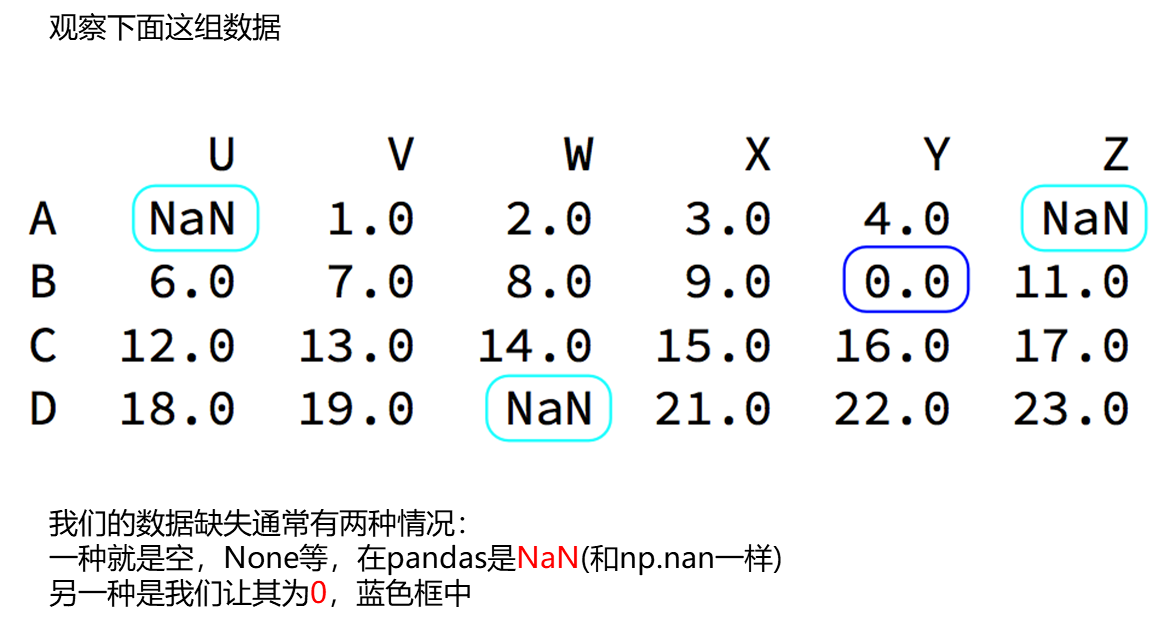
对于NaN的数据,在numpy中我们是如何处理的?
在pandas中我们处理起来非常容易
判断数据是否为NaN:pd.isnull(df),pd.notnull(df)
- 处理方式1:删除NaN所在的行列dropna (axis=0, how=‘any’, inplace=False)
- 处理方式2:填充数据,t.fillna(t.mean()),t.fiallna(t.median()),t.fillna(0)
处理为0的数据:t[t==0]=np.nan
当然并不是每次为0的数据都需要处理
计算平均值等情况,nan是不参与计算的,但是0会
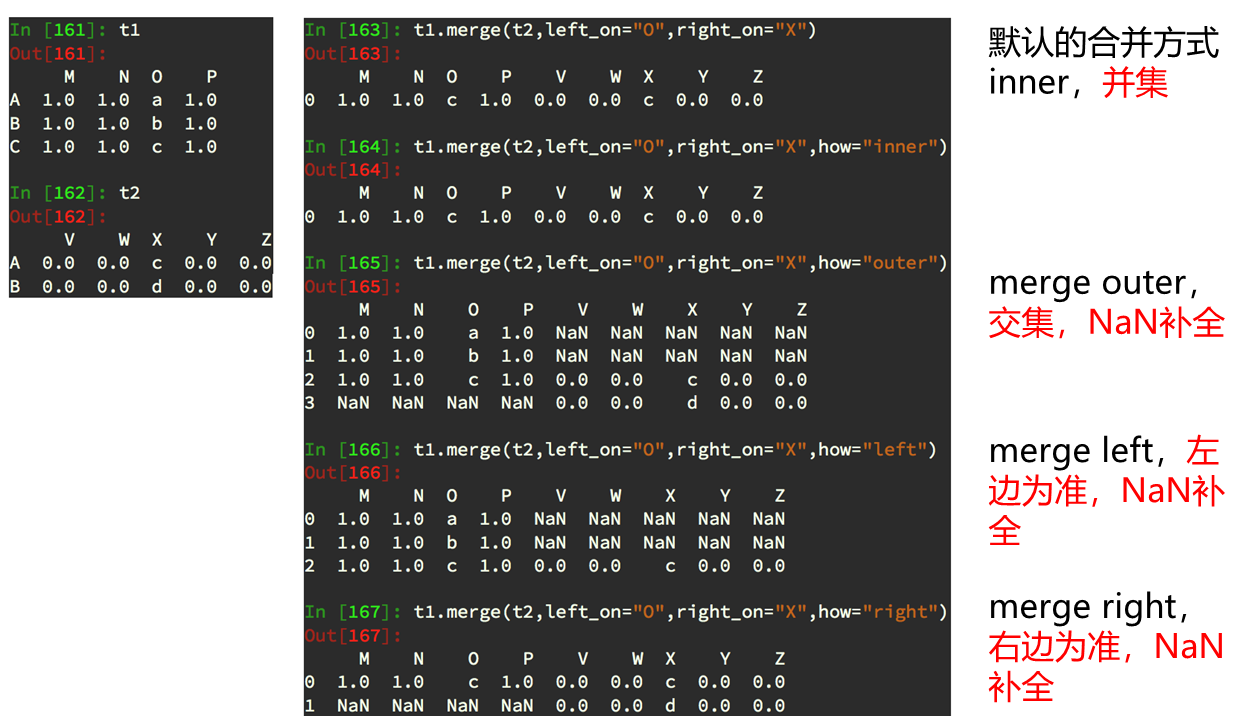
数据合并
join:默认情况下他是把行索引相同的数据合并到一起

merge:按照指定的列把数据按照一定的方式合并到一起
分组和聚合
在pandas中类似的分组的操作我们有很简单的方式来完成
df.groupby(by=“columns_name”)
那么问题来了,调用groupby方法之后返回的是什么内容?




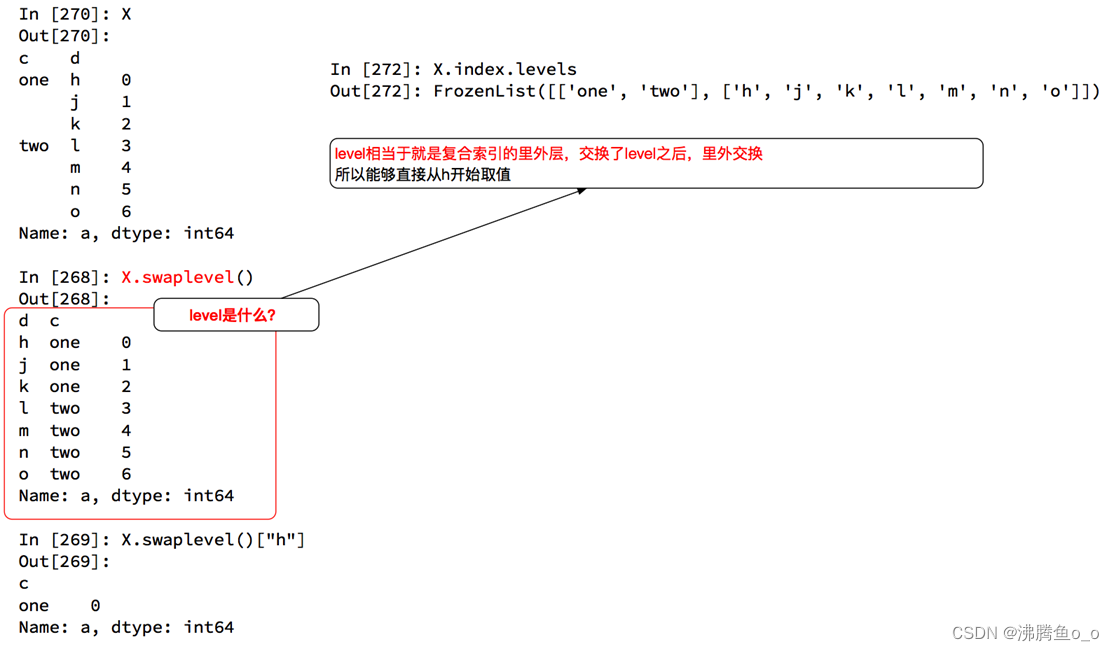
索引和复合索引

















 1362
1362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









