







文章目录
TensorFlow是一个面向深度学习算法的科学计算库,内部 数据保存在张量(tensor)对象上,所有的运算操作(operation,简称OP)也都是基于张量对象的。复杂的神经网络本质上就是各种张量相乘、相加等基本运算操作的组合。
一、数据类型
TensorFlow中的基本数据类型:数值类型,字符串类型和布尔类型。
1.1 数值类型
数值类型的张量是TensorFlow的主要数据载体,根据维度区分:
- 标量:shape为[],维度数为0,代表单个的实数。如1.2,3.4等。
- 向量:shape为[n],维度数为1,代表n个实数的有序集合。如[1.2] , [1.3,1.5,5.2]
- 矩阵:shape为[n,m],维度数为2,代表n行m列实数的有序集合。如[[1,2][3,4]]也可写成:
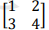
- 张量:shape为[n,m…],维度数dim>2。张量的每个维度叫做轴。例shape为[2,32,32,3]的张量为4维的,如果表示图片,每个维度的含义为图片数量、图片高度、图片宽度、图片通道数。
TensorFlow为了方便表示,将标量,向量,矩阵,张量统称为张量。
import tensorflow as tf
########################创建标量(张量)##########################
a=1.2#python方式创建标量
aa=tf.constant(1.2)#tf方式创建标量
#如果想使用tensorflow提供的功能必须使用tensorflow方式创建标量
print(type(a))#<class 'float'>
print(tf.is_tensor(a))#False
print(type(aa))#<class 'tensorflow.python.framework.ops.EagerTensor'>
print(tf.is_tensor(aa))#True
########################创建向量(张量)###########################
#向量的定义必须通过list容器传给tf.constant()函数。
a=tf.constant([1.2,5])
print(a,a.shape)#tf.Tensor([1.2 5. ], shape=(2,), dtype=float32) (2,)
########################创建矩阵(张量)############################
a=tf.constant([[1.2,3],[4,3.1]])
print(a,a.shape)
#输出:
# tf.Tensor(
# [[1.2 3. ]
# [4. 3.1]], shape=(2, 2), dtype=float32) (2, 2)
########################创建三维张量(张量)#########################
a=tf.constant([[[1.2,3],[3.6,1]],[[4.4,2.1],[5.2,6]]])
print(a,a.shape)
# tf.Tensor(
# [[[1.2 3. ]
# [3.6 1. ]]
#
# [[4.4 2.1]
# [5.2 6. ]]], shape=(2, 2, 2), dtype=float32) (2, 2, 2)
########################张量转换为数组##############################
x=tf.constant([1,2.0,3.3])
print(x)#tf.Tensor([1. 2. 3.3], shape=(3,), dtype=float32)
x.numpy()#返回Numpy.array类型数据,方便导入数据到其他模块
print(x.numpy())#[1. 2. 3.3]
1.2 字符串类型
通过传入字符串对象可以创建字符串类型的数据。
tf.strings模块中提供了常见的字符串类型的工具函数,比如小写lower(),拼接join(),长度length(),切分split()
import tensorflow as tf
#创建
x=tf.constant('HELLO,world')
print(x)#tf.Tensor(b'HELLO,world', shape=(), dtype=string)
#tf.strings模块中提供了常见的字符串类型的工具函数,比如小写lower(),拼接join(),长度length(),切分split()
#例将字符串小写
a=tf.strings.lower(x)
print(a)#tf.Tensor(b'hello,world', shape=(), dtype=string)
1.3 布尔类型
布尔类型的数据,只要传入Python语言的布尔类型数据,转换成tensorflow内部布尔类型即可。Python的布尔类型数据和Python的布尔类型数据不相等,不能通用。
import tensorflow as tf
#创建布尔类型的标量
a=tf.constant(True)
print(a)#tf.Tensor(True, shape=(), dtype=bool)
#创建布尔类型的向量
a=tf.constant([True,False])
print(a)#tf.Tensor([ True False], shape=(2,), dtype=bool)
#Python的布尔类型和tensorflow的布尔类型的比较
b=tf.constant(True)
print(b is True)#与Python中的布尔类型比较 False
print(b == True)#值比较 tf.Tensor(True, shape=(), dtype=bool)
二、数值精度
tensorflow中基本数据类型:数值类型,字符串类型和布尔类型,对于数值类型的张量数据,可以保存不同字节长度的精度。位越长,精度越高,占用内存越大。常用的精度类型:tf.int16、tf.int32、tf.int64、tf.float16、tf.float32、tf.float64=tf.double等
创建张量时可以设定精度:
#创建张量时可以设定精度:
import tensorflow as tf
a=tf.constant(12345789,dtype=tf.int16)
b=tf.constant(12345789,dtype=tf.int32)
print(a)#tf.Tensor(25021, shape=(), dtype=int16)可见数据发生溢出,得到错误数据
print(b)#tf.Tensor(12345789, shape=(), dtype=int32)
#高精度的张量表示更精确的数据
import numpy as np
c=tf.constant(np.pi,dtype=tf.float32)
d=tf.constant(np.pi,dtype=tf.float64)
print(c)#tf.Tensor(3.1415927, shape=(), dtype=float32)
print(d)#tf.Tensor(3.141592653589793, shape=(), dtype=float64)
2.1 读取精度
访问张量的dtype成员,判断张量保存的精度
import tensorflow as tf
import numpy as np
a=tf.constant(np.pi,dtype=tf.float16)
print('before',a.dtype)#before <dtype: 'float16'>
if a.dtype!=tf.float32:
a=tf.cast(a,tf.float32)#tf.cast(张量,dtype)用于精度转换,将传入的张量转为dtype类型、
print('after',a.dtype)#after <dtype: 'float32'>
2.2 类型转换
系统的每个模块使用的数据类型、数值精度可能不相同,这可能需要对张量进行转换,转换通过tf.cast() 完成。
import tensorflow as tf
import numpy as np
a=tf.constant(np.pi,dtype=tf.float16)
print(a)
#(1)精度转换-变为高精度
a=tf.constant(np.pi,dtype=tf.float16)
print(a)
a1=tf.cast(a,dtype=tf.double)
print(a1)
#(2)精度转换-变为低精度,可能会发生数据溢出隐患
a=tf.constant(123456789,dtype=tf.int32)
print(a)
a1=tf.cast(a,dtype=tf.int16)
print(a1)
#(3)精度转换-布尔类型与整型转换。一般默认0为False,1为True,在tensorflow中非0数字都视为True
a=tf.constant([True,False])
print(a)#tf.Tensor([ True False], shape=(2,), dtype=bool)
a1=tf.cast(a,dtype=tf.int32)
print(a1)#tf.Tensor([1 0], shape=(2,), dtype=int32)
a=tf.constant([-1,2,0,3],dtype=tf.int32)
print(a)#tf.Tensor([-1 2 0 3], shape=(4,), dtype=int32)
a1=tf.cast(a,dtype=tf.bool)
print(a1)#tf.Tensor([ True True False True], shape=(4,), dtype=bool)
三、 待优化张量-变量Variable
为了区分计算梯度的张量和不需要计算梯度的张量,tensorflow增加了一种专门的数据类型来支持梯度信息的记录:tf.Variable。tf.Variable类型在普通的张量类型基础上添加了name、trainable等属性来支持计算图的构建。梯度运算会自动更新相关参数,对于不需要优化的张量,不需要通过tf.Variable来封装,对于需要计算梯度并优化的张量,需要通过tf.Variable来包裹,以便tensorflow跟踪相关梯度信息。
通过tf.Variable()函数将普通张量转化为待优化可以跟踪的张量
import tensorflow as tf
a=tf.constant([-1,2,3,0])
'''通过tf.Variable()函数将普通张量转化为待优化可以跟踪的张量'''
#通过张量创建待优化张量
aa=tf.Variable(a)
print(aa.name,aa.trainable)#Variable:0 True
#直接创建待优化张量
a=tf.Variable([[1,2.0],[3,2.0]])
print(a)
# <tf.Variable 'Variable:0' shape=(2, 2) dtype=float32, numpy=
# array([[1., 2.],
# [3., 2.]], dtype=float32)>
'''
待优化张量即变量,可以视为普通张量的特殊类型,普通张量也可以通过GradientTape.watch()方法临时加入
跟踪梯度信息,从而支持自动求导功能。
'''
四、创建张量
4.1从数组、列表对象创建
numpy array和list是常见的数据载体容器,很多程序都是讲数据加载到numpy array或list容器,再转换到tensor,通过tensorflow运算后,再导入到array或者list容器,方便使用。
通过tf.convert_to_tensor函数可以创建新tensor并将array或者list中的数据导入到新tensor中。
import tensorflow as tf
import numpy as np
#从list列表创建张量
a=tf.convert_to_tensor([1.2,3.8])
print(a)
# tf.Tensor([1.2 3.8], shape=(2,), dtype=float32)
#从array数组创建张量
b=tf.convert_to_tensor(np.array([[2.3,5],[4,6]]))
print(b)
# tf.Tensor(
# [[2.3 5. ]
# [4. 6. ]], shape=(2, 2), dtype=float64)
4.2创建全0或者全1张量
(1)通过tf.zeros()和tf.ones()可以创建任意形状,且内容全0或全1的张量。
import tensorflow as tf
import numpy as np
#创建全0全1标量
a=tf.zeros([])
b=tf.ones([])
print(a)#tf.Tensor(0.0, shape=(), dtype=float32)
print(b)#tf.Tensor(1.0, shape=(), dtype=float32)
#创建全0全1向量
a=tf.zeros([2])
b=tf.ones([2])
print(a)#tf.Tensor([0. 0.], shape=(2,), dtype=float32)
print(b)#tf.Tensor([1. 1.], shape=(2,), dtype=float32)
#创建全0全1矩阵
a=tf.zeros([2,3])
b=tf.ones([2,2])
# print(a)tf.Tensor(
# [[0. 0. 0.]
# [0. 0. 0.]], shape=(2, 3), dtype=float32)
print(b)
# tf.Tensor(
# [[1. 1.]
# [1. 1.]], shape=(2, 2), dtype=float32)
(2)通过tf.zeros_like()和tf.ones_like()可以创建与某个张量shape一致,但内容全0或全1的张量。
import tensorflow as tf
import numpy as np
#创建一个矩阵张量a
a=tf.ones([2,3])
print(a)
# tf.Tensor(
# [[1. 1. 1.]
# [1. 1. 1.]], shape=(2, 3), dtype=float32)
#创建一个与a相同形状但是数值全为0的张量
b=tf.zeros_like(a)
print(b)
# tf.Tensor(
# [[0. 0. 0.]
# [0. 0. 0.]], shape=(2, 3), dtype=float32)
4.3创建自定义数值张量
通过tf.fill(shape,value) 可以创建全为自定义数值value的张量,形状由shape参数指定。
import tensorflow as tf
import numpy as np
#创建一个元素为-1的标量
a=tf.fill([],-1)
print(a)#tf.Tensor(-1, shape=(), dtype=int32)
#创建所有元素是-1的向量
b=tf.fill([6],-1)
print(b)#tf.Tensor([-1 -1 -1 -1 -1 -1], shape=(6,), dtype=int32)
#创建所有元素是6的矩阵
c=tf.fill([3,2],6)
print(c)
# tf.Tensor(
# [[6 6]
# [6 6]
# [6 6]], shape=(3, 2), dtype=int32)
4.4创建已知分布的张量
常见分布有正太分布和均匀分布
(1)通过tf.random.normal(shape,mean=0.0,stddev=1.0) 创建形状为shape,均值为mean方差为stddev的正太分布。
import tensorflow as tf
import numpy as np
#创建正太分布张量
a=tf.random.normal([2,3])
print(a)
a=tf.random.normal([2,3],mean=1,stddev=2)
print(a)
(2)通过tf.random.uniform(shape,minval=0,maxval=None,dtype=tf.float32) 创建形状为shape,采样自[minval,maxval)区间的均匀分布的张量。
import tensorflow as tf
import numpy as np
#创建均匀分布张量
b=tf.random.uniform([2,3])
print(b)
# tf.Tensor(
# [[0.51622546 0.4342208 0.6783649 ]
# [0.1861167 0.03041935 0.5599642 ]], shape=(2, 3), dtype=float32)
b=tf.random.uniform([2,3],maxval=10)
print(b)
# tf.Tensor(
# [[6.715001 4.171973 0.683769 ]
# [3.4922767 4.572345 7.6029243]], shape=(2, 3), dtype=float32)
4.5创建序列
tf.range(limit,delta=1)创建[0,limit)之间步长为delta的整形序列。
tf.range([start,limit),delta)创建[start,limit)之间步长为delta的整形序列。
import tensorflow as tf
import numpy as np
#创建序列
a=tf.range(10)
print(a)#tf.Tensor([0 1 2 3 4 5 6 7 8 9], shape=(10,), dtype=int32)
b=tf.range(10,delta=2)#步长为2
print(b)#tf.Tensor([0 2 4 6 8], shape=(5,), dtype=int32)
#创建[start,limit)步长为delta的序列
c=tf.range(1,10,delta=2)
print(c)#tf.Tensor([1 3 5 7 9], shape=(5,), dtype=int32)
五、张量典型应用
5.1标量
标量的典型应用就是简单数字,维度为0,shape为[]。标量的典型应用就是误差值的表示、各种测量指标的表示(准确度,精度,召回率)等。
标量应用-损失值:
import tensorflow as tf
out=tf.random.uniform([4,10])#随机模拟网络输出
y=tf.constant([2,3,2,0])#随机构造真实样本
y=tf.one_hot(y,depth=10)#够着one_hot编码
loss=tf.keras.losses.MSE(y,out)#计算每个样本的均方误差
loss=tf.reduce_mean(loss)#平均MSE,结果为标量
print(loss)#tf.Tensor(0.29316294, shape=(), dtype=float32)
5.2向量
向量在神经网络中经常作为偏置的载体。
向量应用-偏置:
import tensorflow as tf
z=tf.random.normal([4,2])#随机激活函数的输入z=wx
b=tf.zeros([2])#创建偏置向量
z=z+b#累加偏置
#通过dense创建网络层,张量w和b存储在类的内部,由类自定创建并管理。通过全连接层的bias来查看偏置标量。
fc=tf.keras.layers.Dense(3)#创建一层Wx+b,输出节点为3
fc.build(input_shape=(2,4))#通过build函数创建W,B张量,输入节点为4
print(fc.bias)#查看偏置
#tf.Variable 'bias:0' shape=(3,) dtype=float32, numpy=array([0., 0., 0.], dtype=float32)>
5.3 矩阵
矩阵:比如全连接层的批量输入张量的形状[batchsize,d]
import tensorflow as tf
x=tf.random.normal([2,4])#两个样本,特征长度为4
w=tf.ones([4,3])#定义权重w的张量
b=tf.zeros([3])#定义偏置b的张量
o=x@w+b
fc=tf.keras.layers.Dense(3)
fc.build(input_shape=(2,4))#定义全连接网络的输入为4个节点
print(fc.kernel)#查看权值矩阵
# <tf.Variable 'kernel:0' shape=(4, 3) dtype=float32, numpy=
# array([[-0.12153035, 0.05188364, -0.35507244],
# [ 0.65036714, 0.06633306, 0.6742104 ],
# [ 0.8456427 , -0.44762874, -0.87994945],
# [-0.6184335 , -0.3198318 , -0.5791565 ]], dtype=float32)>
5.4 三维张量
三维张量的一个典型应用就是序列信号,格式[b,sequence len,feature len],b表示序列信号的数量,sequence len表示序列信号在时间维度上的采样点数或步数,feature len表示每个点的特征长度。例情感分析,两个等长(单词数量为5)的句子序列表示为[2,5,3],3表示词嵌入。
import tensorflow as tf
(x_train,y_train),(x_test,y_test)=tf.keras.datasets.imdb.load_data(num_words=10000)#自动加载IMDB电影评价数据集
x_train=tf.keras.preprocessing.sequence.pad_sequences(x_train,maxlen=80)#将句子填充截断为等长80个单词的句子
print(x_train.shape)#(25000, 80)
embadding=tf.keras.layers.Embedding(10000,100)#创建词向量embadding层
out=embadding(x_train)#将数字编码的单词转换为词向量
print(out.shape)#(25000, 80, 100)
5.5 四维张量
四维张量在卷积神经网络中因应用广泛,用于保存特征图数据,格式为[b,h,w,c]b代表样本数量,h,w代表图像的高和宽,c代表通道数。
import tensorflow as tf
#创建彩色输入,个数为4
x=tf.random.normal([4,32,32,3])
#创建卷积网络
layer=tf.keras.layers.Conv2D(16,kernel_size=3)
out=layer(x)
print(out.shape)#(4, 30, 30, 16)















 1264
1264











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









