







论文标题:《Competition-Level Code Generation withAlphaCode》
DeepMind 发表于2022年2月19号
AlphaCode在OpenAI的CodeX工作的基础上前进了一大步,运行有更长的文档,并且能生成更复杂的文档
摘要
现在的工作只是将简单的描述或指令转换成代码,并不能理解并完成真的很复杂并没有见过的问题,比如程序竞赛,作者提出的AlphaCode在最近的Codeforces竞赛中能打败54.3%的对手(5000多参赛选手)
工作的核心:
1)有一个很好的数据集
2)有一个简单有效地基于transformer的架构
3)需要有一个高效的采样方法,能够生成大量的候选答案
导言
AlphaCode性能与Codex差不多,但能解决更难更复杂的问题,比如在编程竞赛中能取得还算不错的成绩
程序竞赛
题目:给定一段题目介绍和题目限制(时间复杂度和空间复杂度以及输出格式),并给予一些测试样例,写出问题所需的代码
怎么评估模型:
n@k:采样k个输出算法,并对其排序,若前n(n
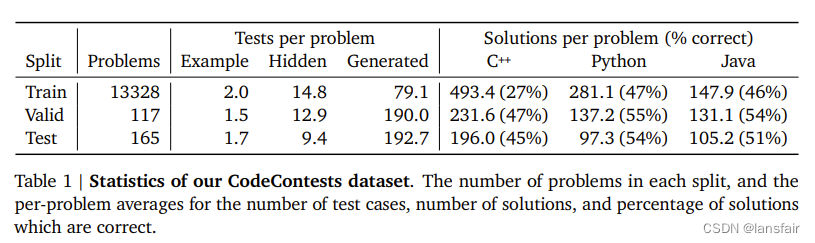
数据集
预训练数据集:收集了github上的主流语言代码,并做了简单过滤,总计715.1GB
微调数据集:CodeContest数据集:主要来自Codeforces。
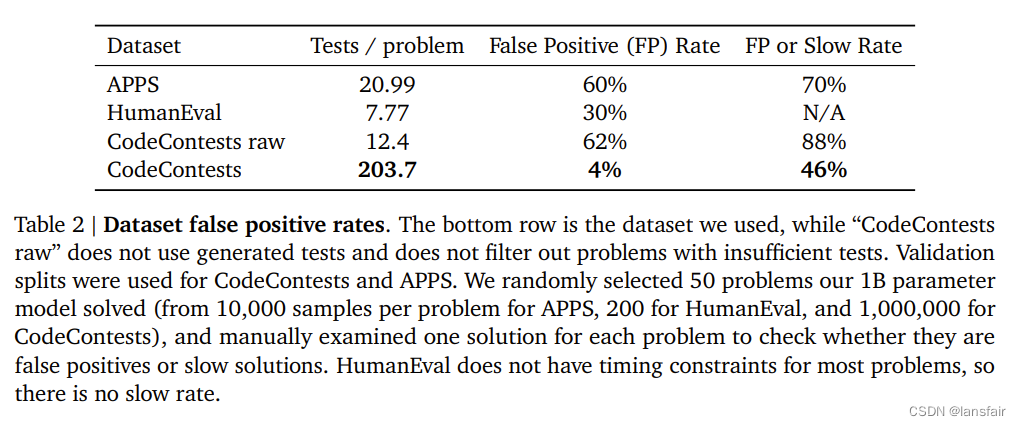
如果不为数据集生成额外的测试样例,那么很有可能出现通过测试,但实际是错误或超时的算法
模型
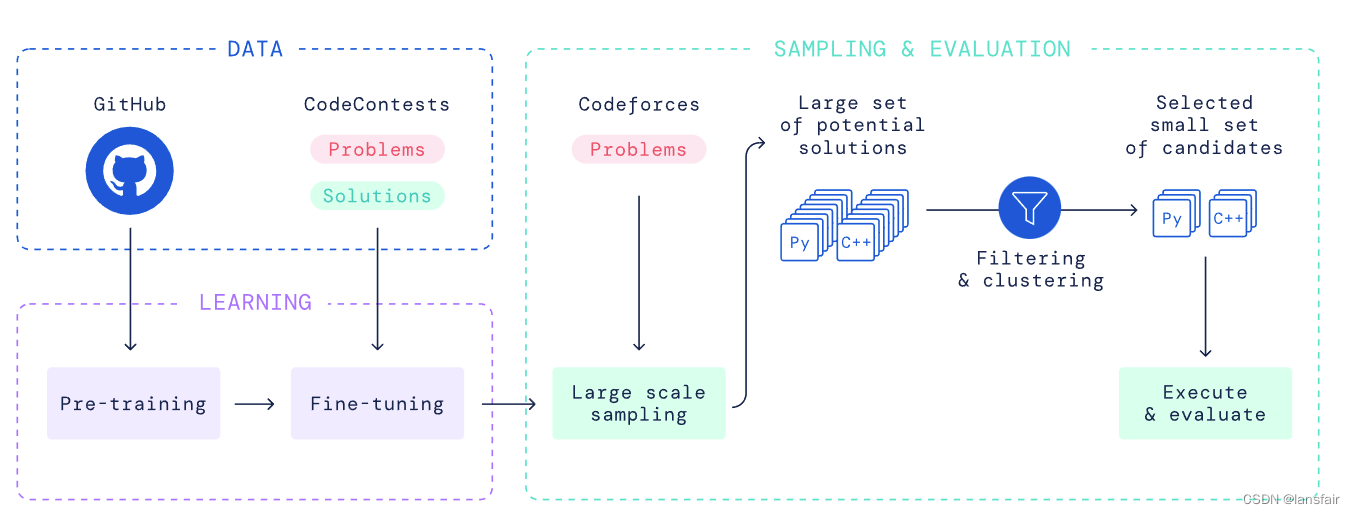
基于标准transformer架构(包括编码器和解码器),并做了一些改动:
1)k和v使用同一个投影矩阵,而不是多头,降低计算量
2)解码器层数比编码器高大约6倍,因为关键在于生成代码
3)非对称机制:编码器输入长度1536 token,解码器输入长度768,因为生成的代码通常比问题描述短
4)tokenization使用SentencePiece(8000个 tokens)

预训练:由于资源有限,训练最大的模型,训练的token数比上一个模型还少
微调:
1)使用Tempering,相对采样的文本长度较长,所以使用一个小一点的温度(0.2)作为超参
2)数据集中问题有多个解,有对的,也有不对,保留不对的解也有一定的好处,但对于不对的解增加判别方法
在输入前面加入前置:CORRECT SOLUTION
加入一个新的目标损失函数,判断当前解释正解还是错误解
3)GOLD
模型只需要找到一个正确的解,而不需要把所有的解都找出来,但是训练时,问题和某一个解都是一对一放进来的,因此算法就会倾向于把所有正确的解和错误的解都拟合出来,这并没有必要。
对每一个样本,放置一个权重,如果对于某一个问题,模型对于其中一个正确解的预测已经足够好的情况下,就将权重调高,而将其他的解的权重调低,使用GOLD算法实现(一个离线的增强学习算法)
怎么生成提交的候选:
1. 生成一半的python,一半的C++
2. 随机化提示中的一些标签
3. 使用稍微高一点的温度(0.25或0.12),还是比CodeX低很多
4. 也尝试了top-k和CodeX中的核采样方法(作者感觉没必要,可能作者生成了成千上万的样本,不在意这些小细节)
从候选中找出正确的解:
1. 过滤,使用给定的样例来测试候选,只保留正确的输出,可以过滤掉99%的输出,但是还有10%的问题没有任何一个输出能通过给定的测试样例,并且对于一些问题,即使过滤掉了99%的输出,还是会有长百上千的候选
2. 聚类,训练了一个额外的模型,做同样的预训练,但是微调时去预测测试样例,将生成测试样例放进生成代码的模型中得到输出,根据输出的样例对模型进行聚类,可以认为每一个类代码差不多,在每个类中挑出一个算法,并按类大小进行排序,类最大的那个解作为第一个输出,第二大的类作为第二个输出,以此类推
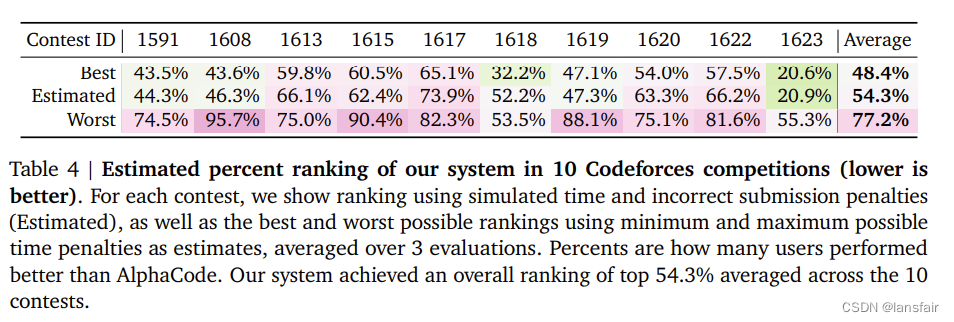
实验
模拟比赛下预估的成绩
不同大小的模型采样不同数量输出的结果
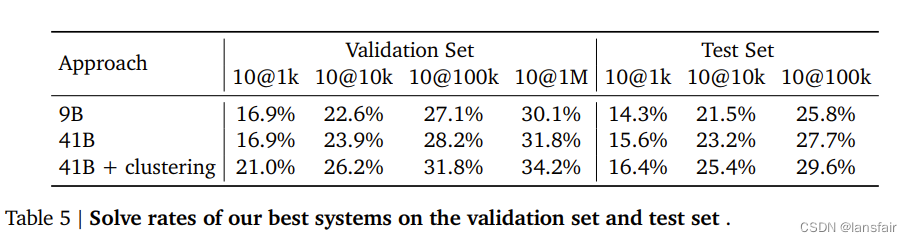
模型越大,采样数越多,效果越好
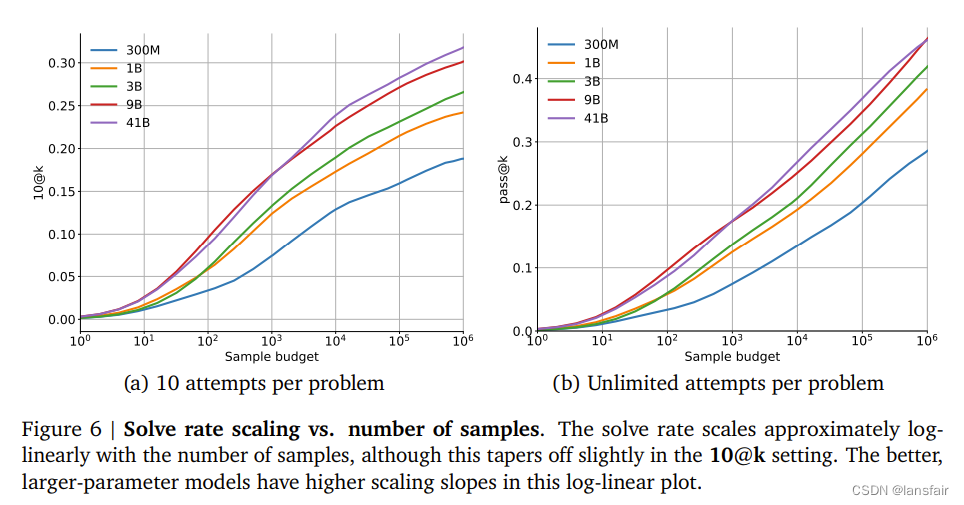
对比只使用解码器或者标准的多头自注意力架构
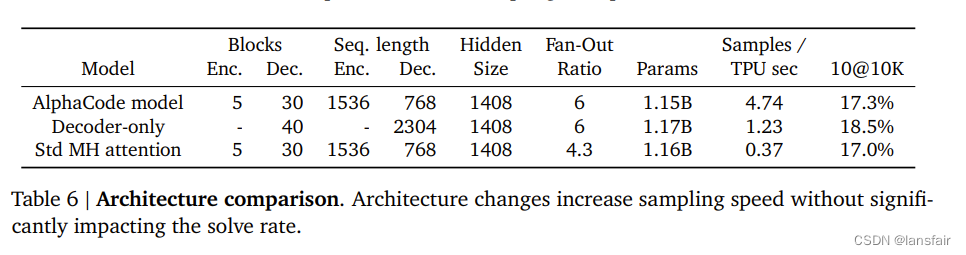
预训练模型的影响
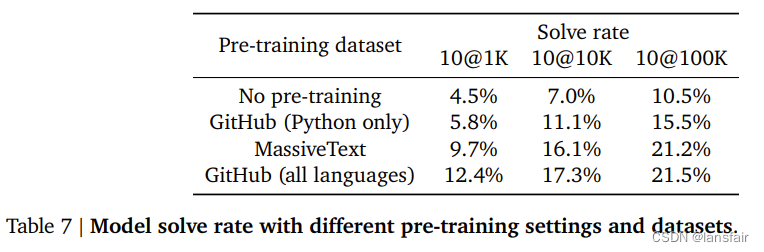
使用的trick以及带来的提升

定性分析(能力和局限性)
1. 模型会不会从训练数据中复制代码
人给的答案和生成的答案的代码重合度
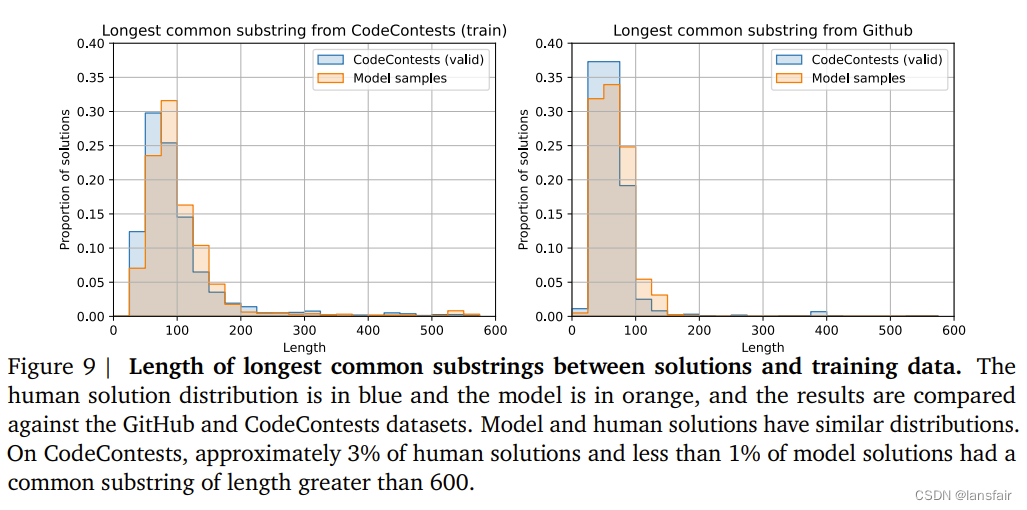
2. 是否有很多冗余无用的代码
对于python来说,可以将代码转换到Abstract Syntax Tree (ast) ,再转换回来(没有使用的枝就会被去掉)

3. 对于问题的描述是否很敏感
感觉还不错。简化问题后会提高通过率,但如果将题中的重要部分描述改变以后,模型精度也会降低,说明模型确实真的在理解哪些重要的点
4. 对于元数据的敏感程度
更换tag和难易程度,确实对生成代码有影响
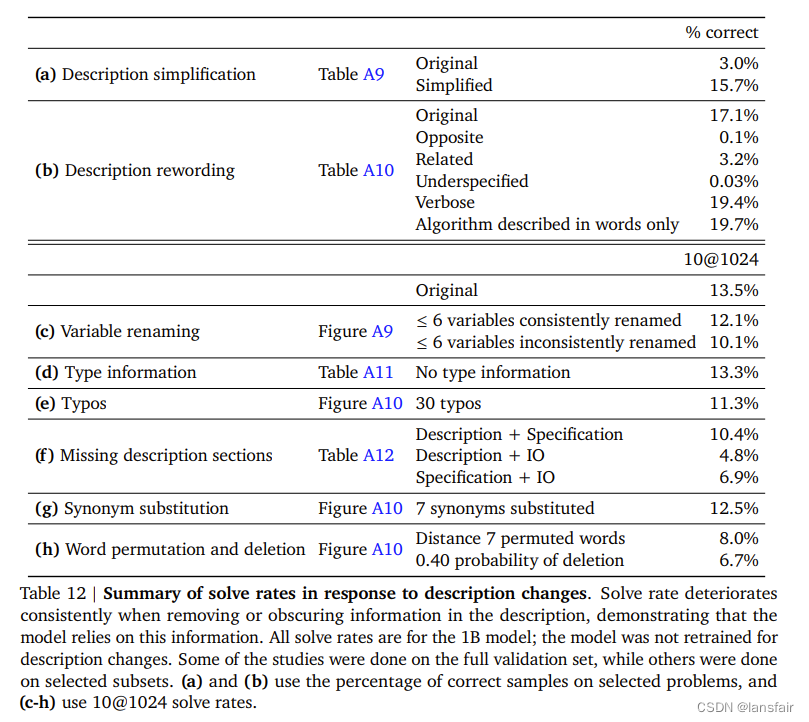

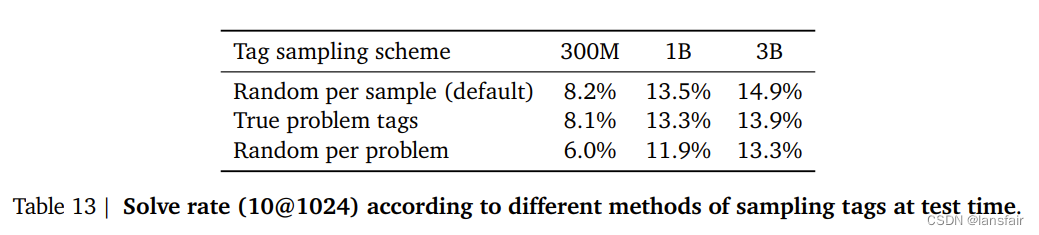
5. 损失是解决率的一个不那么好的近似

影响
跟CodeX差不多
总结
使用完整的编码器与解码器架构,因为编码器在处理长文本上更加有效一点,如果使用跟GPT一样的纯解码器架构,对于长文本会多付出2-3倍的代价,AlphaCode采样数从10到100万,因而性能差别还是比较巨大。由于采样了更大的解,因此在排序上面使用更多的技术来做优化
OpenAI选题时选择一个了更加容易产品化的路线,跟github开源的同时发布了产品Copilot
DeepMind选题反而选择参加程序竞赛,跟产品化相比又比较远了,当然也容易刷头条















 1288
1288











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









