






Relational learning module(CVPR2018)
文章
本文的基础的visual relationship detection框架还是iterative message passing那套,不过想办法加入了relationship的分布先验知识
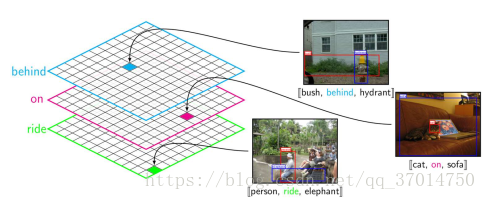
如果对整个数据集分析的话,假设一共有n类object,m类predicate,统计不同的sub-pre-obj,可以得到一个nxnxm的张量,这个张量可以看作m个nxn的矩阵堆叠的,每个矩阵对于一种predicate,假设第k个矩阵,其第(i,j)个元素则表示visual phrase (i-k-j)的出现次数。这个张量有一个特点就是很稀疏,而且不对称,因为有很多物体之间的某些关系在数据集出现很少甚至没有。事实上几乎只有约1%的可能关系被dataset包含了,也就是有很多数据缺失。
直接用上面这个稀疏的张量当做先验的话几没有太大用处,因为很多0,于是paper想办法先将其分解,然后重组。由于张量很稀疏,每个object都可以有r维的隐藏表示,于是可以将所有物体的表示设为A(nxr的矩阵),对于每个关系k,有一个关系因子矩阵R_k(rxr矩阵),至于为什么要这么做可以参看交替最小二乘法ALS,于是分解的模型可以写为:
为了得到这个结果,优化目标是:
上式可以用交替最小二乘法解决,但是好像由于二次项的存在不好解?因此paper用的方法是,先用SVD分解得到的值作为初始值,然后梯度下降。并且为了保证解的唯一性,还加入了正则项,至于为什么这样做是合理的,论文给了详细的证明,但博主并没有看懂。。有兴趣的小伙伴可以去查看一下,最后的优化函数为:
B是为了计算方便进行的合并。算法具体如下:
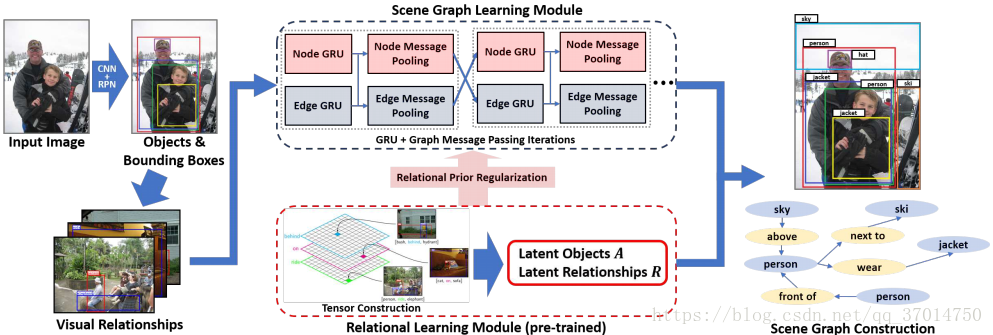
得到了relationship的先验知识之后,使用点乘(Hadamard积)将其整合到iterative message passing的架构中,方法很简单粗暴
架构如上,公式如下
k_SG是iterative message passing模块得到的relationship类别概率向量,当然是经过softmax了的,另外k_RL是在得到了主语和宾语的类别之后从relationship的tensor中提取的,当然也进行了softmax的。D(y,θ)叫y-or-1函数,即D以θ的概率为y,以1-θ的概率为1,也就是相当于随机地把先验概率施加在了网络得到的后验概率上。训练时先不加RL模块,训练100k轮,然后加上训练50k轮,并将θ取为0.2时效果最好。
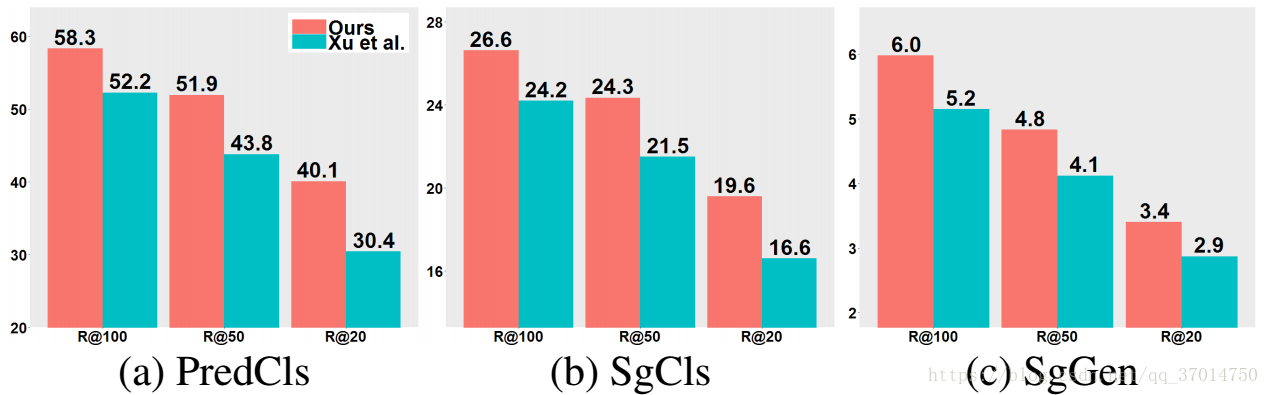
最后在visual genome数据集上和iterative message passing比较,各个任务的准确率都有所提高。但是比不上neural-motif
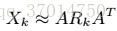
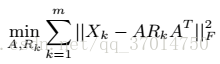
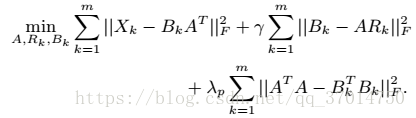

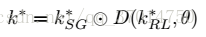















 2082
2082











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









