







RLSV (IJCAI2018)
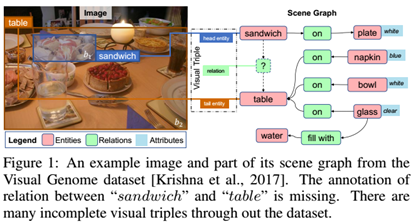
本文将知识图谱补全中的著名的Trans系列的算法之一TransD用到了Scene Graph Completion(简称SGC)中。顾名思义,SGC是在已经有了生成好的scene graph的基础上对其进行补充,发掘检测到的物体之间遗漏掉的关系。
首先介绍一下TransE模型,对于知识图谱中的一个三元组(head,relation,tail),将relation看作从head到tail的翻译,即满足h+r≈t,其中h、r与t分别代表三个元素的向量形式。之后TransR对TransE进行了改进,因为每个实体其实是有多种属性的,而不同的关系考虑的是实体的不同属性,因此TransR中每个关系不仅有一个向量r表示,还有对应的映射矩阵M_r描述这个关系所处的关系空间,即需要满足hW_r+r≈tW_r。但是由于TransR的参数过多,于是又出现了TransD对其进行改进,TransD中不管是关系还是实体,都用两个向量表示,一个是普通的嵌入h、r、t,另一个则是用于得到TransR中的转换矩阵的表示,h_p、r_p和t_p(问题是如何得到这些表示)。比如对于实体h和关系r, 转换矩阵W_rh=r_p*h_p’。

上图是RLSV的架构,主要有两个模块
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 889
889











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









