







比赛名称:RecSys Challenge 2022
推荐指数:4颗星
这个比赛是非常典型的top-k推荐的比赛,也是最能模拟一个实际推荐全流程的比赛,相似的比赛还有很多,就比如2020年的KDD的Debias比赛,还有最近在Kaggle上举行的H&M时尚推荐等等,通过对这类top-k推荐问题的学习,可以很好的理解推荐系统的全流程中的各阶段的算法,可以让大家对推荐系统有一个整体的认识。
1.赛题介绍
我们将通过算法使零售商能够更准确地预测产品需求和尺寸比例,做出更好的购买和营销决策。 我们通过在我们收集和创建的数据中采取特定领域的方法来实现这一目标,我们如何构建这些数据以及我们建立的模型?我们要做的是经过优化,处理时尚的细微差别。当给定用户会话、购买数据和物品的内容数据时,你能准确预测在会话结束时将购买哪件时尚物品吗?
该比赛是一个非常典型的top-k推荐比赛,不过与寻常推荐比赛不同的是,该比赛并没有直接给出用户的id,而是直接给出了用户在一天内浏览的商品的列表,要求我们根据用户当天浏览的商品的列表推荐100个用户最可能购买的商品,这就要求我们对用户浏览序列进行很好的建模,非常有利于我们入门推荐比赛
赛题提供者:Dressipi是时尚界的AI专家,为全球领先的零售商提供产品和服装推荐。
2.赛题难点
重要的是能够根据用户在当前会话期间所做的事情提出建议,以创造可能导致购买的最佳体验。 时尚领域的细微差别使得准确的会话预测比其他领域更重要:
- 平均 51% 的访客是新访客(Dressipi 数据),这意味着没有可用的历史数据,我们只能依赖当前会话活动。
- 即使对于拥有历史数据的另一半访问者来说,趋势和其他外部因素也会比其他领域更快地改变用户偏好,这意味着历史数据可能不再代表用户的兴趣。 这使得拥有一个高度准确的会话推荐器更加重要,该推荐器可以被拉入组合中。
- 会话可能很短,因此我们需要能够在用户反弹之前尽早做出准确的预测。
3.赛题类型
本赛题是典型的基于session的推荐,在本次赛题中的session的概念是用户在一天内点击过的所有的item的集合,我们的任务是根据用户的session来推荐100个用户最可能购买的item,这是一个典型的top-k推荐的问题
4.评价指标
其中:
表示查询的总数
表示第一个相关结果的排序
5.常见的思路
- 最简单也是最有效的思路:
- ItemCF:ItemCF是一种完全基于统计的方法,他通过统计的方法得到俩俩item之间的相似性,然后根据item相似度去推荐和用户历史点击过相似的item,该方法思路简单,可解释性强,而且往往在数据量较小的情况下其效果会稳压其他机器学习/深度学习的方法
- 序列召回思路:
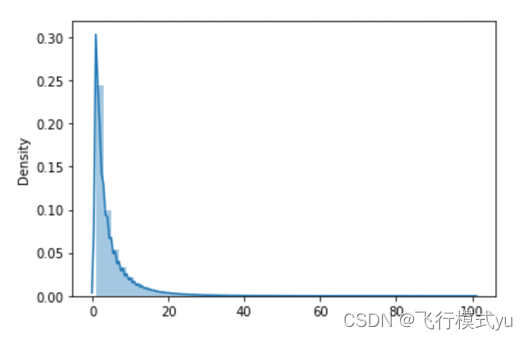
- 由于该赛题的输入是用户一天内交互过的item,可以认为是一个序列,而且我们的任务是要给用户推荐100个item,所以我们可以将其视作是序列召回任务,但是由于本次赛题的sesion的长度大多数都比较短(见图1 session长度分布图),所以这种思路在实践的时候效果并不好,但作为学习而言,其思路是值得大家学习的,下面列出一些常见的序列召回方法:
- youtubednn: https://dl.acm.org/doi/10.1145/2959100.2959190
- GRU4Rec: https://arxiv.org/pdf/1511.06939
- MIND: https://arxiv.org/pdf/1904.08030
- Comirec: https://arxiv.org/abs/2005.09347
- 多路召回:
- 上面介绍了两大类的召回思路,多路召回就是用多个召回算法,每一个召回算法召回一部分的item,最后把所有召回算法的结果汇总起来,这就是多路召回,通俗点可以认为是召回层面的模型融合,这里可以融合多个不同的itemcf
- 召回+排序两阶段
- 前面着重减少了召回的一些思路,同样的,可以在召回之后接一个排序的算法,排序主要就是一个二分类任务,由于这里缺少了user侧的信息,只有sesion的信息,可能无法直接使用LGB这一类的树模型来直接进行二分类建模,这里的排序模型主要是使用一些序列模型来进行建模
6.基于ItemCF的Baseline
ItemCF是一种基于统计的方法,其核心步骤有两步:
- 第一步:根据用户的历史记录(session)来构建Item-Item的相似矩阵,这个相似矩阵是通过item-item的共现次数来构建的
def get_sim_item(df, session_col, item_col, use_iif=False):
user_item_dict = df.groupby(session_col)[item_col].agg(list).to_dict()
sim_item = {}
item_cnt = defaultdict(int)
for user, items in tqdm(user_item_dict.items()):
for i in items:
item_cnt[i] += 1
sim_item.setdefault(i, {})
for relate_item in items:
if i == relate_item:
continue
sim_item[i].setdefault(relate_item, 0)
if not use_iif:
sim_item[i][relate_item] += 1
else:
sim_item[i][relate_item] += 1 / math.log(1 + len(items))
sim_item_corr = sim_item.copy()
for i, related_items in tqdm(sim_item.items()):
for j, cij in related_items.items():
sim_item_corr[i][j] = cij / math.sqrt(item_cnt[i] * item_cnt[j])
return sim_item_corr
- 第二步:根据Item-Item相似矩阵与session来进行召回,具体做法就是遍历session中的所有item,然后根据item-item相似矩阵来推荐与session中相似的item
def recommend(sim_item_corr, popular_items, top_k, session_item_list, item_num=300):
rank = {}
for i in session_item_list:
if i not in sim_item_corr.keys():
continue
for j, wij in sorted(sim_item_corr[i].items(), key=lambda d: d[1], reverse=True)[0:item_num]:
if j not in session_item_list:
rank.setdefault(j, 0)
rank[j] += wij
rank = sorted(rank.items(), key=lambda d: d[1], reverse=True)[:top_k]
rank = np.array(rank)
item_list = list(rank[:,0].astype('int32'))
score_list = rank[:,1]
#可能会出现推荐的item个数不够100个的情况,这个时候用最热门的item进行逐一补充
if len(item_list)<top_k:
index = 0
while(len(item_list)<top_k):
item_list.append(popular_items[index])
item_list = list(set(item_list))
index +=1
return item_list, score_list
基础版本的itemcf线上得分0.165
问题收集
推荐系统中如何消除长尾分布带来的影响?
可以尝试Debias方法,具体详见资料补充。
有什么好的推荐系统论文吗?
相比于复现,推荐系统方面的论文更值得借鉴其中的思想,修改后适配到自己的作业环境中。这里推荐了排序和debias的一些论文,学有余力的同学可以一看,具体详见资料补充。
线下训练可以选用自己的评价指标吗?
可以。
有什么好的会话推荐的论文吗?
具体详见资料补充。
多臂老虎机推荐?
可以尝试:
(1)epsilon -Greedy 算法 (随机探索)
(2)Upper Confidence Bounds算法 (UCB)
(3)Thompson Sampling 算法
(4)Contextual MAB-LinUCB 算法
有什么好的推荐可解释性的论文?
具体详见资料补充.
构造共现矩阵时,为何要把purchase加在session的后面?以及为何不推荐session中出现的物品?
官方给出的数据集构造设计如此,详见:RecSys Challenge 2022
本次比赛的奖金/奖励设置?
虽然主办方说具体奖励细则to be continued,但是top团队应该大概率有机会发一篇workshop。
Recsys是什么级别的会议/期刊?
RecSys是ACM主办的推荐系统旗舰会议,其征文范畴包含推荐系统的各个领域,包括算法设计、系统实现、理论推导和评估测试等。RecSys是推荐系统领域最好的专门会议,另外KDD、WWW和ICML跟推荐系统相关的track也属A+级别。
怎么融合内容理解与排序模型?
通过预训练bert或无监督方法得到embedding后,作为一路embedding召回或者concatenate到排序模型提取的特征上。更多相关解决方案详见资料补充。
资料补充
KDD Debias 解决方案:
KDD Cup 2020 Challenges for Modern E-Commerce Platform: Debiasing-天池大赛-阿里云天池
https://www.logicjake.xyz/2020/06/16/KDD-debias-TOP13/#排序
KDD CUP 2020之Debiasing赛道方案 (Rush)_风度78的博客-CSDN博客
A Simple Recall Method based on Network-based Inference,score:0.18 (phase0-3)-天池技术圈-天池技术讨论区
A simple itemCF Baseline, score:0.1169(phase0-2)-天池技术圈-天池技术讨论区
KDD Cup 2020 Debiasing赛道解析及baseline代码解释(线上0.33) - 知乎
Debias Paper:
Bias and Debias in Recommender System: A Survey and Future Directions
Graph Debiased Contrastive Learning with Joint Representation Clustering
Bias and Debias in Recommender System: A Survey and Future Directions
Fairness in Recommendation Ranking through Pairwise Comparisons
会话推荐:
A Survey on Session-based Recommender Systems
Heterogeneous Global Graph Neural Networks for Personalized Session-based Recommendation
GNN DAGNN: Demand-aware Graph Neural Networks for Session-based Recommendation
S-Walk: Accurate and Scalable Session-based Recommendation with Random Walks
推荐可解释性:
What is Event Knowledge Graph: A Survey
Explainable Reasoning over Knowledge Graphs for Recommendation
内容理解相关的解决方案:


















 164
164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









