






 本文详细介绍了用户画像的构建过程,包括用户标签系统的分类方式,如事实类、规则类和模型类标签的获取。讨论了文本挖掘算法如LSA、PLSA、LDA以及词嵌入表示如word2Vec和DeepWalk。同时,阐述了用户画像在用户分析、精准营销和风控领域的应用,并提出了相关思考练习。
本文详细介绍了用户画像的构建过程,包括用户标签系统的分类方式,如事实类、规则类和模型类标签的获取。讨论了文本挖掘算法如LSA、PLSA、LDA以及词嵌入表示如word2Vec和DeepWalk。同时,阐述了用户画像在用户分析、精准营销和风控领域的应用,并提出了相关思考练习。
目录
前言
用户:产品的使用者
数据收集方为了退关产品同时持续维护和改善用户体验需要对由用户操作而产生的数据进行挖掘,以期从中发现群体乃至个体的行为偏好,形成数据层面上的所谓画像。
主要内容:用户画像、标签系统、用户画像数据特征、用户画像应用、思考练习。
7.1 用户画像
用于商业分析和数据挖掘的用户画像。
7.2 标签系统
核心就是给用户打标签,用来分析社会属性、社会习惯、生活习惯、消费行为。
7.2.1 标签分类方式
举例
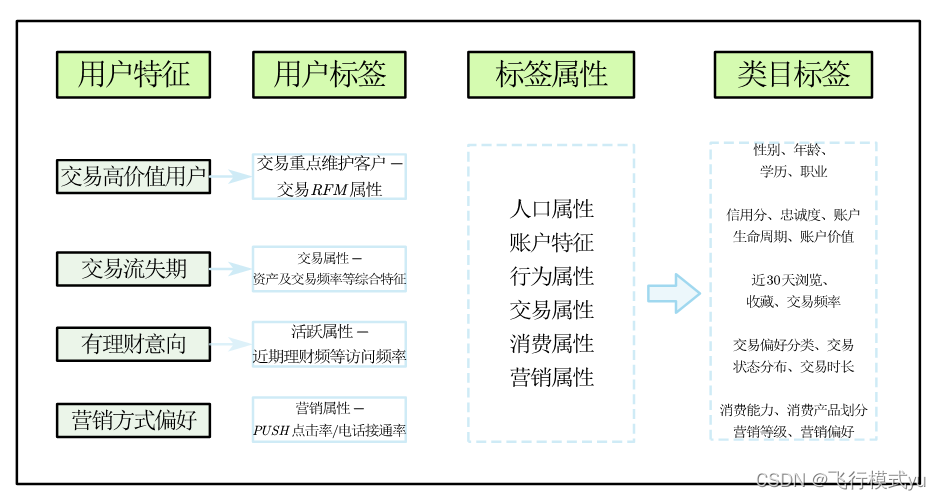
7.2.2 多渠道获取标签
(1)事实类
直接来自原始数据,比如性别、年龄、会员等级。也可以进行简单统计,比如用户行为次数、消费总额。
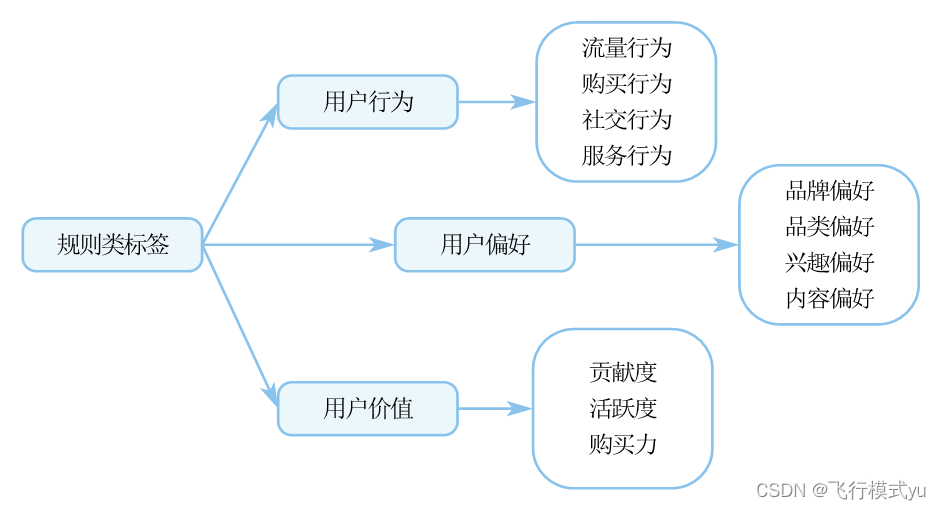
(2)规则类
由运营人员和数据人员经过共同协商设定。例如,地域属性、家庭类型、年龄层等。
所用技术知识:数理统计类,如基础统计、数值分层、概率分布、均值分析、方差分析等。
(3)模型类
经过机器学习和深度学习等模型处理后,二次加工生成的洞察性标签。比如预测用户状态、预测用户信用分、划分兴趣人群和对评论文本进行分类。
特点:综合程度高、复杂,依托数学建模,多种算法组合。
比如:基于模型类标签可以使用RFM模型来衡量用户价值和用户创利能力、对用户行为信息建模预测用户生命周期变化情况、通过模型预测用户信用评分、使用图嵌人或用户分层模型划分兴趣人群。除此之外还有很多通过模型来得到标签的方法。
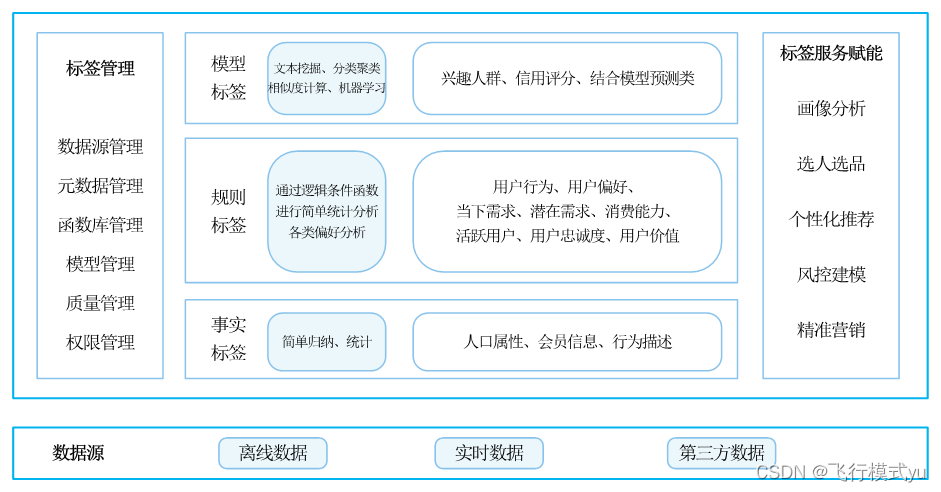
7.2.3 标签体系框架
7.3 用户画像数据特征
7.3.1 常见的数据形式
- 数值型
- 类别型
- 多值型:需要特别的数据结构如稀疏矩阵
- 文本型:需要NLP知识,例如jieba中文分词工具
下面介绍常见的特征提取算法:
7.3.2 文本挖掘算法
文本表示模型(1):主题模型LSA、pLSA、LDA_SunnyGJing的博客-CSDN博客_plsa
LSA
非概率主题模型,与词向量有关,主要用于文档的话题分析。其核心思想是通过矩阵分解的方式发现文档和词之间基于话题的语义关系。
具体:将文档集表示为词-文档矩阵,对矩阵进行SVD(奇异值分解),从而得到话题向量以及文档在话题向量的表示。
举例:2020腾讯广告大赛,首先构造用户点击的广告素材id序列(creative_id),然后进行TF-IDF计算,最后经过SVD得到结果。
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
# 稀疏特征降维 TruncatedSVD
from sklearn.decomposition import TruncatedSVD
from sklearn.pipeline import Pipeline
# 提取用户点击序列
docs = data_df.groupby(['user_id'])['creative_id'].agg(lambda x:"".join(x)).reset_index()['creative_id']
# tf-idf
tfd = TfidfVectorizer()
svd = TruncatedSVD(n_components=100, n_iter=50, random_state=2020)PLSA
PLSA(概率潜在语义分析)模型为了克服LSA模型潜在存在的一些缺点而提出的。
PLSA通过一个生成模型来为LSA赋予概率意义上的解释。该模型假设每一篇文档都包含一系列可能的潜在话题,文档中的每一个词都不是凭空产生的,而是在潜在话题的指引下通过一定的概率生成的。
LDA
LDA(潜在狄利克雷分布)是一种概率主题模型,与词向量无关,可以将文档集中的每篇文档的主题以概率分布的形式给出。通过分析一批文档集,抽取出他们的主题分布,就可以根据主题进行聚类或分类。同时,它是一种典型的词袋模型,即一篇文档由一组相互独立的词构成,词和词之间没有先后顺序。
7.3.3 神奇的嵌入表示
word2Vec
原理略
可调用gensim包,参数:窗口大小、模型类型选择、生成词向量长度
对于Skip-Gram和CBOW:
- CBOW在训练时比Skip-Gram快
- CBOW可以更好地表示常见单词
- Skip-Gram在少量的训练集中可以表示稀有单词或短语
DeepWalk
def deepwalk_walk(walk_length, start_node):
walk = [start_node]
while len(walk) <= walk_length:
cur= walk[-1]
try:
cur_nbrs = item_dict[ cur]
walk.append(random.choice(cur_nbrs))
except:
break
return walk
def simulate_walks(nodes,num_walks,walk_length):
walks =[]
for i in range(num_walks):
random.shuffle(nodes)
for v in nodes:
walks.append(deepwalk_walk(walk_length=walk_length,start_node=v))
return walks
if __name__ =="__main__":
# 第一步:生成图网络(省略)
# 构建item_dict保存图中的节点关系,即字典结构存储,key为节点,value为领域
# 第二步:通过DeepWalk生成商品序列
nodes =[k for k in item_dict] # 节点集合
num_walks =5 # 随机游走轮数
walk_length = 20 # 随机游走长度
sentences = simulate_walks(nodes,num_walks,walk_length) #序列集合
#第三步:通过word2Vec训练商品词向量
model = Word2Vec(sentences,size=64,window=5,min_count=3,seed=2020)对于Word2Vec的衍生Item2Vec以及更多图嵌入方法,比如LINE、Node2Vec和SDNE
7.3.4 相似度计算
欧式距离
余弦相似度
jaccard相似度
。。。
7.4 用户画像的应用
7.4.1 用户分析
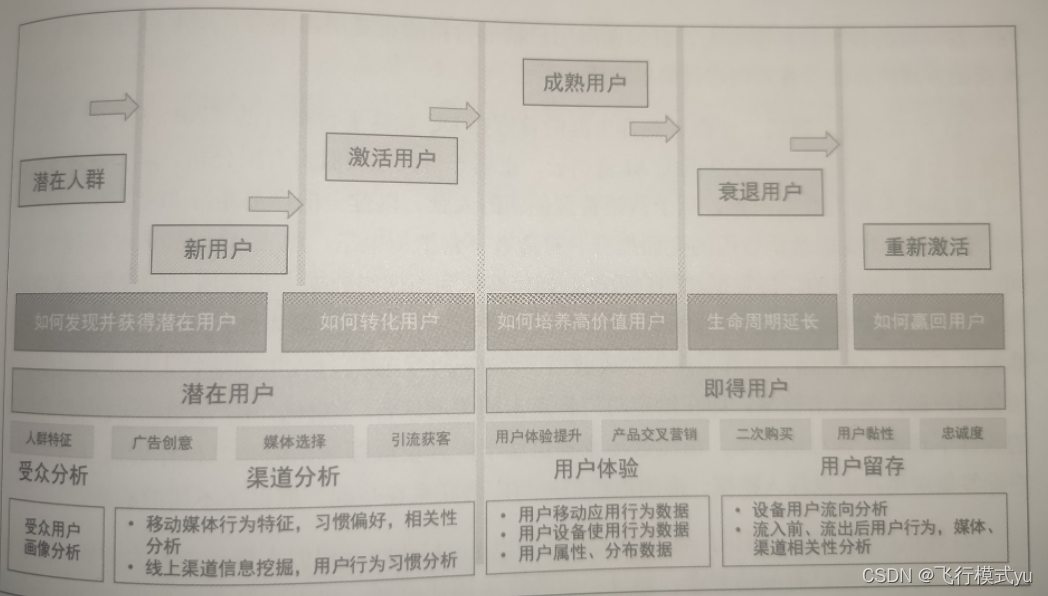
(1)京东JDATA平台2019年的“用户对品类下店铺的购买预测”;
(2)腾讯广告“2020腾讯广告大赛”
7.4.2 精准营销
2018科大讯飞AI营销算法大赛
2018腾讯广告算法大赛
7.4.3 风控领域
DF竞赛平台的“消费者人群画像-信用智能评分”
拍拍贷“第四届魔镜杯大赛”
特点:
业务对模型解释性比较高,对时效性有一定要求,需要权衡模型复杂度和精度,并且适当优化算法内核
业务模型多样,需要紧密结合业务
负样本极少,均衡学习算法
7.5 思考练习
1.你觉得用户画像是想体现用户的共性还是个性,为什么?
共性:对同一类人群进行推荐,省时省力
个性:精准化服务,高投入高回报
2.就你日常使用的App,思考其算法与运营团队会如何给你画像呢?
除去基本的信息,还有在使用过程中产生的数据,对物品的喜好等等
3.文本挖掘算法也是非常多的,尝试整理这些算法调用方法,并且结合原理去熟悉参数的设置。
- 基于概率统计的贝叶斯分类
- ID3决策树分类
- 基于粗糙集理论Rough Set的确定型知识挖掘
- 基于k-means聚类
- 无限细分的模糊聚类Fuzzy Clustering
- SOM神经元网络聚类
- 基于Meaning的文本相似度计算
- 文本模糊聚类计算
- 文本k-means聚类
- 文本分类
- 关联模式发现
- 序列模式发现
- PCA主成分分析
4.嵌入方式被广泛应用,除了Word2Vec和DeepWalk以外,还有哪些嵌入算法,具体原理是什么样的?
参照《深度学习推荐系统》
5.相似度计算方法非常多,但要从大量数据中检索出最为相似的或者相似度排前N位的并不是件容易的事情,所以有什么好的检索算法吗?
Kd树?

















 9667
9667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









