







AutoFormer:搜索Transformer用于视觉识别任务
from ICCV2021
Abstract
最近一些纯Transformer结构在计算机视觉领域的一些任务中大放异彩,如图像分类、目标检测。但是Transformer结构的设计仍然具有挑战性,其中网络深度、嵌入维度、注意力头的数目都会显著影响ViT的性能,之前的模型大多是人工基于经验选定这些参数配置,而本文则提出了一种新的one-shot架构搜索方法,称之为AutoFormer,专门用于搜索Vision Transformer的结构。
AutoFormer在超网训练过程中会将同一层不同blcok的权重混合起来,得益于这种策略,超网下的成千上万的子网可以获得较好的训练,因为这些子网从超网继承网络权重,其性能比从头训练的子网要更好。此外最终搜索的网络模型,被成为AutoFormers。比当前的一些SOTA结果(如Deit,ViT)还好,搜索得到的tinty/small/base结构分别在ImageNet上达到了74.7%/81.7%/82.4%的精度。最后本文还将AutoFormer迁移到下游任务,通过知识蒸馏验证了AutoFormer的可迁移性。
Section I Introduction
Vision Transformer在计算机视觉领域备受关注,因为其在捕获长程关系方面展现的强大建模能力,代表性框架有ViT,DeiT。但是Transformer神经网络结构的设计并不容易,比如如何选择网络深度、嵌入层的维度以及注意力的头数,而这些参数都显著影响着模型的建模能力。
如Fig 2所示,随着网路深度的增加、注意力头的增加以及MLP宽长比(hidden dimension/embedding dimension)都会带来精度的增长但是之后就过拟合了。这些现象搜说明设计最优的Transformer结构十分具有挑战性。
前人的工作主要基于人工设计,需要大量的经验、试错。也有基于NAS做的一些尝试,如Envolved Transformer和HAT,但都是聚焦于NLP任务,并不是针对计算机视觉任务。因此很难将前人的工作迁移到CV任务中。

本文则提出一种新的搜索算法,称之为AutoFormer,用于纯视觉Transformer的设计。主要解决搜索transformer过程中的两大挑战:
(1)如何选定Transformer的配置组合,如网络深度、嵌入维度、注意力的头数等;
(2)如何有效的根据不同资源限制、应用场景选定Transformer
为了解决以上难题,本文设计了一个大的都锁空间包含了Transformer的主要部分,如嵌入维度、注意力头数、q/k/v的维度,网络深度等,从而可以组成不同结构不同复杂度的transformer;尤其是允许使用不同结构的Transformer block,从而打破了Transformer设计中使用相同结构block的设定。
为了提升搜索效率,受BigNAS启发本文提出基于超网的训练策略-weight entanglement。核心思想是使得不同的transformer模块共享超网的权重,某一模块的权重更新会影响全体的权重,因此使得不同模块的权重在训练时最大限度的混合在一起。这一策略不同于之前的one-shot NAS方法,因为他们同一层不同block的权重是互相独立的。
本文还观察到一个惊人的实验现象:使用weightentanglement,可以允许超网中大量子网得到很好的训练,这些使用来自超网权重的子网的性能与那些从头训练的子网性能相当,这样使得本文的方法可以获得数以千计满足不同资源约束的网络架构,同时与从头训练的子网保持相近的精度水平。
本文基于进化搜索来寻找Transformer架构,Fig 1展示了在ImageNet上的搜索结果,可以看到搜索的结果超过了DeiT和ViT;迁移到下游任务也显示出可以以更少的参数达到与EfficientNet相近的精度。

本文主要贡献总结如下:
(1)据我们所知这是第一篇搜索vision Transformer结构的工作;
(2)本文提出一种简易但高效的训练方法,无需额外的重训练或微调就能从超网获得数以千计高质量的子网,适用于不同资源约束的情况
;
(3)本文搜索的结果-AutoFormer在ImageNet数据集上达到了SOTA,并且可以迁移到下游任务中。
Section II Background
Part 1 Vision Transformer
Transformer最初为NLP任务而设计的,最近的ViT和DeiT显示了在CV领域的巨大潜力。
Transformer的基本流程:对于一张2D图像,会首先将其切分成2D patch序列,类似NLP中的token序列;
然后将patch展平成D维度,这一映射过程可以通过线性映射也可通过CNN处理;
随后会嵌入一个可训练的cls embedding和positional embedding。
随后将组合后的结果送入Transformer encoder中进行学习;经过线性层获得最终的预测结果。
Transformer encoder中包含:MSA和MLP模块。
在送入模块之前经过LN,每一个模块的输出会进行残差连接。
MSA用来计算多头注意力
MLP包含两层全连接层和激活函数,与NAS相关的是每一层的MLP ratio。
Part 2 One-Shot NAS
One-Shot NAS主要采用权重共享的思想来避免从头训练每一个子网络。对于某个搜索空间A将其编码成一个超网N,W就是超网的权重,所有候选网络会继承超网的网络权重。因此one-shot NAS是一个两阶段的优化过程:
Stage 1:优化超网权重
为了减少内存使用,one-shot NAS通常采样子网进行优化。
Stage 2:对子网进行排序选择候选子网
因为不可能对所有子网都进行评估。
因此之前的工作主要采用随机搜索、进化算法或强化学习来找到最可能的一些子网。
Section III AutoFormer
本节将首先叙述,按照传统的权重共享策略对不同block进行one-shot NAS是不现实的,因为在每一层使用不同的权重会使得训练时间很长、收敛很慢、性能也不理想。
因此本文提出使用weight-entanglement策略来解决上述问题。最后叙述搜索空间和搜索策略。

Part 1 One-Shot NAS with Weight Entanglement
One-Shot NAS会在超网中共享网络权重,但会解耦同一层不同操作符的权重,这种方法在CNN上表现良好,但是在Transformer搜索空间中会遇到以下问题:
(1)收敛过慢
Fig4左侧图可以看出来训练超网收敛很慢,可能是因为Transformer每个模块独立更新导致的
;
(2)性能低下
通过继承超网权重的子网络性能远远低于从头训练的性能,这样就会影响子网排序的精度
此外,因为权重没有完全被优化搜索结束后还需要额外的重训练。
受BigNAs启发本文提出weight-entanglement的搜索策略,核心思想是不同的transformer block的公共部分共享权重。在搜索过程中,每一层所有多个block的选择,因此a和w实际上是从属于搜索空间的n个候选快中进行选择的。
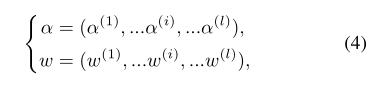

weight-entanglement策略会使得同一层不同候选模块尽可能的共享权重,这样训练当前blcok的权重时也会影响其他候选模块。
参见Fig5的示意图,这一点不同于之前的one-shot NAS,不同block之间是独立的。
需要注意的是本文提出的weightentanglement是用于构建模块结构的,比如搜索MSA中注意力头的数目,根本原因是同质模块内部在结构上是兼容的,这样权重就可以相互共享;在具体实现中,可以对每一层存储n个候选模块中最大块的权重即可,因为其他模块可以从最大的模块中提取获得。
这样通过weight entanglement,one-shot可以高效的进行搜索。weight-entangelemt有以下3点优势:
(1)收敛更快
因为每一个模块在 有限的训练时间内更新的更多
;
(2)更低的内存消耗
只需要存储最大模块的权重、参数即可
;
(3)子网性能很高
本文发现通过weight entanglement训练得到的子网可以获得与从头开始训练的子网相当的性能
Part 2 Search Space
Transformer搜索空间包含5大主要候选参数: 嵌入维度、Q/K/V的维度、注意力头的数目、MLPratio,网络深度。详情参见Table 1。


这些参数对网路性能至关重要,比如注意力头是用来捕获不同关联关系的,但是最近也有工作证明许多head是冗余的,因此本文来弹性搜索head的数目;
另一方面因为不同层的特征表述能力不同,因此使用动态的隐藏层尺寸可能比固定的隐藏层维度要好;
此外AutoFormer还增加了新的搜索维度,就是Q-K-V的嵌入维度,这样分离了不同头的含义,有助于稳定梯度。
此外本文还设定了MLP层中的维度,比使用fix的维度要进一步扩大了搜索空间。
随后就是遵循one-shot的搜索步骤,将搜索空间编码成一个超网,Fig 3展示了超网的结构,超网包含最多的网络模块、最多的嵌入维数等。

训练期间所有可能的子网搜会被均匀采样并更新对应位置的权重。
根据对模型参数的约束条件,将搜索空间划分成三部分,编码成三个相互独立的超网。
这样使得搜索算法可以聚焦于一定参数范围的优化,也可以使得用户根据自己的资源和应用需求来选择。
总的来说本文的超网共包含1.7*10^6个候选网络架构。
Part 3 Search Pipeline
搜索流程包含两步
Phase 1:
超网训练 会随机采样子网并更新子网权重,使用weight-entanglement
Phase 2:
资源约束下的进化搜索
在得到训练后的超网后会对其进行进化搜索从而得到最优子网。
会根据进化算法来评估子网性能并进行选择。优化目标是最大限度提升分类精度,同时最小化模型大小。
进化算法就是会随机选择N个架构作为父代,然后通过交叉变异获得下一代;交叉就是随机挑选两个候选网络,并产生新的;对于变异则是对弈一定的概率改变自身深度,从而产生新的网络结构。
Part 4 Discussion
下面探讨一下为什么weight entanglement有效?本文认为主要由以下两方面的原因:
(1)训练时的正则化
不同于CNN,Transformer根本没有卷积操作,基本组件是MSA和MLP只采用全连接层。weight-entanglement可以看做是Transformer引入了正则化策略,一定程度上类似drop-out的效果;当对子网进行采样时当前的单元不能依赖其他单元进行分类,减少了对其他unit的依赖。
(2)对于更深、更细子网的优化
一些研究表明Transformer较难训练的原因是反向传播时梯度可能会在较深、较细网络层中爆炸或消失;通过增加网络宽度或“过度参数化”将有助于这类网络的优化,本文的weight entanglement通过更新更宽网络的权重来优化这种更细网络的权重;此外采用弹性的深度具有和随机深度、深度监督类似的效应,同时可以监督浅层网络层。
SectionIV Experiments
本节会首先介绍实现细节、实验配置;然后通过实验证明weight-wntanglement的有效性,并在一些基准测试上进行验证。
Part 1 实验细节
超网训练 训练与DeiT类似,详细配置信息参见Table 3.patch大小为16x16 训练卡V100 进化搜索 与SPOS类似,种群大小设置为50,每次生成子代数目为20,每次选择top-10作为下一代的父代.
Part 2 消融实验
weight-entanglement
对比了AutoFormer,随机搜索和SPOS
SPOS超网中的每一层不同的transformer module权重是不共享的,对SPOS超网训练后会同样适用进化搜索来搜索候选子网络,并对选择的子网络重新进行训练。
Table 2展示了不同实验的对比结果,可以看到本文比随机搜索和SPOS的性能提升了2.5%和1.3%
如果不进行重训练,直接从超网继承网络权重,weight-entanglement比传统的权重共享性能好得多,与从头开始训练的性能差不多。


我们认为SPOS性能相对较差的原因就是搜索空间训练时训练不充分,可以看到如果SPOS超网训练更多epochs性能也会缓慢提升,但是这训练成本会远远高于本文的weight-entanglement。Fig6绘制了从超网训练时采样子网的性能,可以看到使用进化搜索比随机搜索更有效,搜索出的子网性能更高。
Subnet Performance without Retraining
本文惊奇的发现,大量子网直接继承超网权重时取得了非常好的性能,不用微调或者重训练。Fig 7展示了从超网中采样的1000个高性能自己,这些自己均能达到80.1-82%的top-1精度,超过了最近的DeiT,RegNetY.这些结果充分证明了本文这种one-shot+weight-entanglement的训练策略的有效性。
Table 4展示了如果进一步对搜索到的子网络进行重训练,性能提升并不大,可以忽略不计,这也说明了在超网中训练得到的子网是已经较为充分训练后的,因此最终Trasformer不再需要额外的训练或调整。


Part 3 Results on ImageNet
本文还试验了不同规模的AutoFormer模型在ImageNet上的表现。AutoFormer均直接继承了超网的权重,没有进行任何重训练。Table 5显示了不同规模与SOTA网络的对比结果,可以看到本文在不同规模上均达到了最优,领先于DeiT和ViT等模型,即使在timy模型上也是达到了最优的精度。
与CNN模型相比AutoFormer的性能也十分具有竞争力,也展示了纯Transformer网络结构在视觉任务中强大的潜力。

Part 4 迁移学习结果
Classification
Table 6展示了迁移到CIFAR数据集、以及细粒度图像数据集Standford-CAR,Flowers等的结果。可以看到与SOTA CNN相比,AutoFormer与最优的结果接近,同时参数量更少;而与同样基于Transformer模型比则取得了最优的性能,并且参数量减少了4x.

Distillation
AutoFormer的优化方向与知识蒸馏切好是正交的,因为AutoFormer旨在搜索高效的架构,KD则聚焦于更好的训练一个给定的网络结构,如果将AutoFormer与KD结合,借助教师网路可以进一步提升网络性能。
Section V Related Work
Vision Transformer
Transformer最初 提出用来语言建模的,最近被用于视觉任务并显示出巨大的潜力。最直接的使用方法是将卷积层与SA模块结合。
ViT则是第一个纯Transformer结构用于计算机数据任务,没有用任何卷积操作。ViT通过堆叠trnasformer模块,取互不重叠patch线性映射后的结果,在JFT-300M数据集上取得了优异的成绩。
DeiT则无需在大型数据集上预训练,只在ImageNet上训练即可,但是这些改进大多基于手工设计,需要经历大量的试错尝试,本文则是首个基于神经架构搜索来设计Vision Transformer的结构。
Neural Architecture Search
早期的NAS主要基于强化学习、进化算法,近期则更多聚焦于权重共享的one-shot方法,核心思想是训练一个过参数化的超网模型,然后子网继承超网的权重。SPOS就是其中的代表,每一次迭代都会随机采样一条路径并用一批数据训练该路径;训练结束后,子网就会继承共享权重并排序。但是大多数权重共享都需要重新训练。
近期,OFA,BigNAS等通过训练一个once-for-all的超网来解决这一问题,AutoFormer与他们类似但是搜索的不再是CNN而是Transformer;并且BigNAS,OFA等都使用一些特殊的搜索方法,如蒸馏、正则化、逐步搜索等,但是AutoFormer无需这些额外的设计、搜索方式,更容易拓展到其他transformer 变体的搜索中。
此外,目前使用NAS搜索Transformer的工作也不多,并且主要聚焦于NLP任务;与本文最相近的是HAT,除了处理的任务不同,HAT还需要额外的重训练或者微调,AutoFormer并不需要。另一个关键的区别是搜索空间,HAT搜索的是Transformer 编解码结构,本文只搜索了encoder部分。
还有两个同期工作,BossNAS搜索的是CNN-Transformer混合结构,CvT则是提出在architecture family中搜索步长、核等参数。
因此本文与prior work主要由两方面不同:
(1)本文提出一种简洁高效的搜索cision Transformer的方式
;
(2)提出的weight-entanglement使得超网中的子网得到良好的训练,可以直接继承超网权重,无需二次训练或微调。
据我们所知这是在架构搜索中第一次实现once-for-all Transformer的训练。
Section VI Conclusion
本文提出一种新的one-shot架构搜索方法-AutoFormer,核心是weight-entanglement训练策略。基于此种训练策略搜索空间下的所有子网都可以得到充分训练。
实验结果显示本文提出的搜索方法可以显著提升超网的训练,搜索到性能优异的网络。
本文搜索到的AutoFormers框架在ImageNet视觉任务中达到了SOTA,并且可以迁移到下游的其他任务中。
未来本文将进一步丰富搜索空间,将卷积也作为候选操作;以及对weight-entanglement进行理论分析、探索其他潜在的研究方向。















 395
395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









