







Lesion-Aware Transformers for Diabetic Retinopathy Grading
Transformer用于糖尿病视网膜病变分级
cvpr2021
Abstract
糖尿病性视网膜病变是致人群永久性失明的主要原因,自动DR诊断可以辅助医生为眼病患者量身定制治疗方案,主要包括DR分级和病变发现。但是目前大多数方法都将DR分级和病变发现看做两个独立的任务限制了实际应用。为了解决这一问题本文提出了一种新的基于损伤的Transformer(LAT)用于DR分级和病变发现。
LAT是一个编解码结构,编码器负责建模像素关系,解码器则是一个损伤滤波器。LAT有以下优势:首先这是首个将病变发现作为一个弱监督任务解决的工作六七次为了深入学习图像级标签的信息来训练decoder本文使用两种有效的机制分别是病变置信度和病变多样性来帮助识别不同的病变区域。在Messidor-1/2和EyePACS这三个基准数据集上的实验结果表明本文提出的LAT优于最先进的DR分级和病变发现模型。
Section I Introduction
糖尿病性视网膜病变(DR)是糖尿病引起的血管损伤最严重的的并发症之一,可致永久失明。医生通常会根据相关病变症状出现的类型和数量,如微动脉瘤、出血、软深处和应伸出来确定DR的严重程度,参考Fig1(a).DR可分为5个级别,分别为:正常、轻微、中度、重度-非增殖性、重度-增殖性。也可分为两类:DR正常和DR异常。
 Fig 1对眼底图像病变进行了标注,黄色代表出血 红色代表微动脉瘤 蓝色代表渗出物
Fig 1对眼底图像病变进行了标注,黄色代表出血 红色代表微动脉瘤 蓝色代表渗出物
近期随着深度学习的发展,基于像素级或patch级的快速自动DR分级诊断模型也被提出。但是由于需要专家标注结果所以限制了这些模型的临床部署。此外对于病变区域的识别也十分重要,因为这会为眼科医生提供视觉指导来辅助他们进行疾病的诊断,现阶段大多数算法将这两个任务独立进行,虽然他们都需要病变注释信息。为了解决这一问题,有的工作提出一个弱监督模型同时进行DR分级和病变区域的划分,但是效果是偏向最重的病变区域而忽略了一些零碎的病变区域,这可能会影响病变的哦凝固。并且这些被忽略的病变区域可能对DR分级也有重要的影响,因此本文希望能设计一个更有效的模型来更完整的划分病变区域以及对DR进行正确的分级。
基于上述对问题的讨论 为了获得更精确的DR分级效果同时获得完整的病变区域划分,需要考虑一下三个问题:
(1)病变区域的分布区域相对稀疏。可以看到同一病变区域内虽然与背景像素不同,但是彼此像素比较接近,需要对像素之间的相关性进行学习;
(2)需要考虑图像中不同病变区域的重要性,可以看到并不是所有的病变信息都影响DR的严重程度,有些病变信息是噪声信号。因此模型应自适应评估每个病变区域的贡献
(3)如Fig 1(a)所示,每个眼底图像可能包含多种不同的病变,而相同级别的DR图像也有可能包含的病变类型和病变数量不一致,因此模型应尽可能感知多样化特征,尽可能从多的病变区域捕获相应的病变特征。
此外由于每个区域都代表一种特定的病变类型或者一组病变的组合,那么比病变区域的致密性也应考虑在内。因此病变滤波器应使得相近的病变更为接近,这样使得每种病变区域可以拥有更为明确的病变语义,将不同区域组合起来就是一个完整的病变发现,参考Fig 1©。
基于以上观察,本文提出基于病变区域的LAT模型用于DR分级和病变诊断。LAT是一个编解码结构,编码器负责学习像素之间的关联,本文使用了一种适应像素外观变化的自注意力机制,即会对像素之间的相关性进行建模来捕获全局的上下文关系,这样实现了外观相似的病变像素的聚集,抑制了杂乱的背景像素。
解码器则是病变区域的滤波器,本文设计了一个自注意模块和交叉注意模块来学习给定数据及中的病变信息在自注意力模块中主要对病变之间的依赖进行建模,在交叉注意模块会将输入的眼底 图像的特征图作为k,v然后将病变过滤器作为q,通过计算查询与k之间的相似性来得到对应的激活图。每一个病变区域的激活图代表某种病变的分布。
利用区域激活图可以获得病变感知特征,如果没有特定的病变信息作为监督信息,就难以了解decoder的工作机理。
在decoder部分使用两种信息来约束decoder的学习,首先是病变区域置信度,本文引入一个重要性预测模块来评估每个病变区域的贡献;对于病变多样性的学习本文采用triplet loss来学习病变区域的多样性和紧凑型。然后基于上述特征添加一个全局一致性约束损失的分类模块用于DR分级,整个编解码结构+分类模块组成了病变感知滤波器,因此可以同时进行DR分级和病变发现。
本文工作总结如下:
(1)提出一个基于病变的Transformer模型-LAT可以同时实现DR分级和病变发现
(2)据我们所知这是首个将病变发现作为弱监督实现的工作,为了更好的学习图像级别标签提供的信息,本文使用了两种机制,分别是病变区域置信度和病变区域多样性
(3)在三个基准数据集上取得了SOTA结果
Section II Related Work
本节简要介绍DR评估方法、弱监督定位和基于注意力的Transformer。
DR Assessment
早期的DR评估主要分为DR分级和病变发现两个任务。DR分级主要基于像素级或patch级注释信息来进行学习,当前基于深度学习已经是主流方法;当前的方法分为两类,一是借助病变信息辅助分级,比如借助微动脉瘤的位置或者病变信息;二是仅使用图像级的标签实现DR分级,比如Li等探究了糖尿病黄斑水肿与疾病等级之间的关系。但是都是将DR分级与病变发现分成两个任务来进行。
后面也有研究逐渐将两个任务同时解决,比如Yang等人搭建了一个两阶段的框架,或者借助协同学习同时完成两个任务,但是都需要像素级或patch级的标注信息,费时费力。近期Wang等人提出使用注意力来突出可疑区域,基于可疑版块来预测DR分级,但是不可避免会倾向于最重要的病变区域,损害其他零散病变区域的发现,为了更好的仅使用图像级标签完成病变发现,本文将病变发现看做一个弱监督的定位问题,并且提出两种机制来训练filter,分别是病变区域的置信度和多样性。
Weakly Supervised Object Localization
弱监督定位是紧接著图像级标签同时推断对象的位置和类别,Zhou等人使用类别激活映射(CAM)来实现对象的定位和分类,还有Grad-CAM,CCAM等进一步提升鲁棒性。但是他们的局限在于倾向于关注更具鉴别的对象区域,导致了定位性能交叉。为了缓解这一问题,有的研究尝试使用对象的上下文信息来讲最具区别性的区域扩展到整个对象。受此启发,本文将病变发现看做一个弱监督的定位问题,因此设计了一种新的病变相关的Transformer同时考虑了病变区域的置信程度和多样性,仅使用图像级标签来进行学习。
Attention-based Transformer
Transformer被提出后广泛用于机器翻译、语音识别等任务。Transformer引入了多头注意力层,类似于非局部神经网络,会扫描序列中素有元素,利用全局信息来进行更新,本文利用了Transformer的思想,搭建了编解码结构来学习病变区域的信息,从全局的视角尽可能多的发现病变并预测每一块病变的严重程度。
Section III Lesion-Aware Transformer Network
本节将介绍LAT框架的详细信息以及如何通过这个编解码网络结构同时进行DR分级和病变发现,包括学习像素间关系的encoder和病变滤波的decoder。
Part 1 Overview
对于眼底图像I,F表示特征图,每一张图像都有一张像素级的标签z,C代表病变等级。整个测试流程是输入眼底图像后输出预测的DR分级水平和对应的病变激活图,如Fig 2所示。LAT包含一个学习像素关联的encoder和一个基于病变滤波器的decoder。

Part 2 Pixel Relation based Encoder
为了获得全局上下文信息,本文对像素关联进行建模,通过自注意力机制生成增强后的特征图去。首先会使用卷积层将特征映射到更低维度,然后将空间变换为1维重新生成新的特征映射F;然后根据特征图F获得对应的Q,K,V进行多头自注意力的计算。
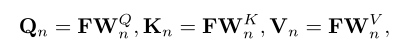
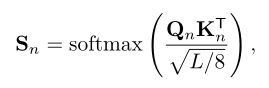
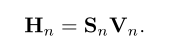
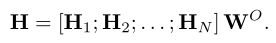
N代表注意力的头数,本文的注意力头数为8.随后会计算注意力权重Sn,与V相乘后获得加权后的输出。最终将每个头的输出在通道维级联后获得最终输出。
随后从入包含两个全连接层的FFN即得到了增强后的特征图F。
通过自注意力机制可以获得外观相近的病变区域,这样可以更好的抑制因为曝光不足或过曝、失焦等引起的背景混乱问题。
Part 3 Lesion Filter based Decoder
为了识别不同的病变区域,本文设计了基于病变滤波器的decoder来学习病变感知的信息。
首先会学习一组病变感知的filterP,每一个p代表一个L维向量,说明图像中的像素是否属于此种病变区域。然后本文使用自注意力机制来进一步获取来自其他filter的上下文信息,来增加他们之间的差异性,只不过将特征图F替换为本文的滤波器p。
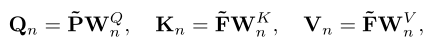
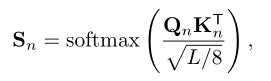
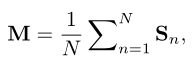
然后本文提出使用交叉注意力获得病变感知的激活图M,也就是使用p作为query,F作为key和value来进行注意力的计算。这样获得病变感知激活图M也是多个注意力头级联后的结果,每个filter表示一个特定病变的空间分布,如果属于此类病变那么对应像素会有较高的响应值,在得到相似性Sn(注意力系数)会加权到特征图上。
在经过前馈网络获得一组病变感知特征X。
在获得病变感知特征后,如果没有病变信息作为监督信号就难以学习病变filter,因此本文设计了两种机制来约束病变感知特征。
Lesion Region Importance Learning Mechanism
考虑到并非素有的病变信息都对DR分级有用,因此需要评估每个病变区域的重要性,即设计了一个重要性预测模块g来评估每一个病变区域的重要性,并生成重要性权重,这个预测模块是一个线性层+sigmoid操作,输出0-1的概率分布。
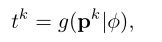
Lesion Region Diversity Learning Mechanism
在特征多样性方面采用了triplet loss来表征病变区域的多样性和紧凑型。triplet loss会基于一小批T图像,每一个数据包含标签k,正样本特征和负样本特征,分别计算positive pair distance和negative pair distance.
triplet loss的目的就是减小positive的距离,增加negative的距离。
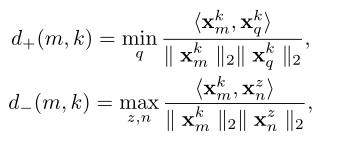
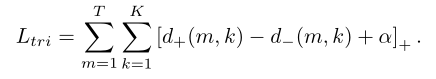
这样每个病变区域都具有更明确的语义特征,将不同的病变区域结合起来就形成了一个完整的病变发现。
Part 4 DR Grading
为了进行DR分级本文添加了一个分类模块,包含基于区域感知特征的全局一致性损失,输入的是病变感知特征,输出的是DR的严重程度,主要是K个全连接层组成:
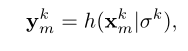
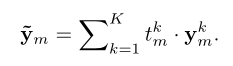
损失函数就是交叉熵损失函数。
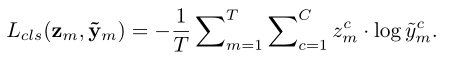
Part 5 Joint Trainging and Inference
通过联合优化encoder和分类器模块,可以在训练过程中通过整个数据集学习病变感知滤波器,LAT的损失函数表示为:
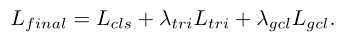
其中λ权重分别为0.04和0.01。
Section IV Experiments
Part 1 Datasets and Evaluation Metrics
Messidor-1:
包含1200张眼底图像 但是其分级只有4级与国际的5级分级不同,因此本文重新对齐进行了分类,其中0-1级被标记为non-referable,2-3级被认为是referable
Messidor-2:
是Messidor-1的扩展,包含1748张眼底图像并且是5级分级。本文主要在该数据集上进行消融实验,来衡量LAT每个模块的有效性。
EyePACS:包含35126张训练图像,10906张验证图像和42670张测试图像,提供5级分级。
Evaluation Metrics:
本文使用的评估指标是二次加权 kappa指标,可以有效反应模型在不均衡数据集上的性能,kappa值会在0-1之间变化,值越大说明模型性能越高。对于分类则使用AUC进行度量。
Part 2 Implementation Details
本文以ResNet50作为特征提取器,移除掉GAP和FC层。输入图像为512x512大小 数据增强:random horizontal lips, vertical lips and random cropping,color jitter 重要性预测模块g有一个共享的全连接层组成,输出通道维1;分类模块h包含K个C通道的全连接层。
Part 3 Comparisons with SOTA

DR Grading
Table 1展示了与目前一些SOTA模型的DR分级比较结果,注释部分表明分别使用像素级还是patch级的标注信息。对比结果表明本文的LAT在两类分类面前都优于基线方法,仅使用图像级标签的LAT在正常AUC指标上超出Semi_Adv 2%。
因为LAT通过全局一致性损失可以有效解决0-1级之间的差距,此外可以看在Referable AUC任务中提升了4.2%,主要得益于编解码结构可以关注到不同的病变区域并且自适应的融合响应的病变特征,从而进行更加全面的DR分级。
此外本文还邀请了专家对Messidor-1进行分类,本文的LAT比专家标注的性能提升了4.7%和4.1%。
Table 2展示了在EyePACS数据集上的实验结果,主要为了验证LAT每一部分的作用,可以看到由于数据集图像质量较低,包含较多的过曝/欠曝的图像,但本文依旧在验证集和测试集上达到了89.3%和88.4%的kappa指标,比Semi-Adv提升了1.2%,充分说明LAT的自注意力机制可以适应像素外观的变化,聚集外光相似的病变区域的像素,并且可以抑制由过曝/欠曝导致的噪声背景像素。

Lesion Discovery Performance
为了验证LAT在病变发现任务的能力,本文与CAM进行了比较,FIG 3可视化了不同病变filter生成的病变区域激活图,可以看到不同的filter可以成功的识别不同区域,如微动脉瘤、出血和渗出物。主要是因为本文建模了一组病变filter并基于编解码结构进行学习,从而关注不同的病变类型。而CAM和Zoom-in-Net并不限制获得的注意力图,因此只能关注到DR分级中最重要的病变其余。


Part 4 Ablation Studies
本文还以ResNet50为基准在Messidor-2数据集上进行了一系列消融实验。
Lesion region diversity mechanism for lesion discovery.
首先验证病变区域的多样性对病变发现的有效性。主要对比了CAM,不使用多样性的LAT和使用了多样性的LAT,参见Fig 4,可以看到CAM只关注了最重要的病变区域,而LAT-效果优于CAM,因为decoder中的自注意力机制可以参考其他filter的上下文信息,来增加他们之间的差异。加入多样性后会进一步明确约束不同病变特征之间的差异,并使用不同的filter找到包含更明确语义变化的病变区域。

Other parameters
从Table 3中的index2可以看出,如果只使用encoder学习像素之间的关系,与基线模型相比会提升1.2%的kappa指标,说明学习像素之间关联后可以生成更鲁邦的特征来适应像素的外观变化。
从index1和index3中可以看出加入病变filter后AUC提升了1.8%,kappa提升了3.6%,说明自注意力可以结合来自其他filter的上下文信息,增加他们之间的差异。
而从idnex5和index6可以看到加入多样性之后AUC提升了1.2%,说明添加病变区域多样性指标可以引导filter发现不同的病变区域,并将从病变区域提取到的特征自适应的融合在一起,提高DR分级性能。
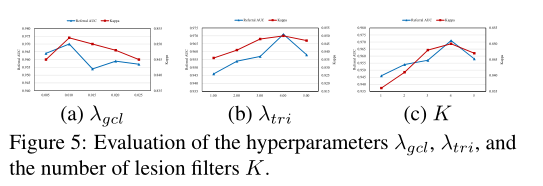
Hyperparameters
还有就是λtri和λgcl如何影响模型性能,其中λtri控制病变多样性的权重,λgcl控制全局一致性损失的权重。从Fig 5可以看到二者分别取0.04和0.01时性能最好,并且还测试了病变filter数量K=4时效果最好,之后不再增长,说明4个filter足以识别病变区域。
Section V Conclusion
本文提出一种病变感知的Transformer模型,通过编解码结构的网络模型同时实现DR分级和病变识别。具体来说学习像素关联的encoder可以有效适应像素外观的变化,而基于病变filter的decoder负责识别病变区域,在三个数据集上的实验结果证明LAT模型优于其他SOTA模型。















 544
544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









