






 本文介绍了如何在GitHub上使用yolov7PyTorch库进行深度学习项目,包括环境配置(如Anaconda和PyCharm)、训练VOC数据集(包括VOC07+12和自定义数据集)以及评估过程,重点讲解了训练参数调整和模型预测方法。
本文介绍了如何在GitHub上使用yolov7PyTorch库进行深度学习项目,包括环境配置(如Anaconda和PyCharm)、训练VOC数据集(包括VOC07+12和自定义数据集)以及评估过程,重点讲解了训练参数调整和模型预测方法。
代码仓库:GitHub - bubbliiiing/yolov7-pytorch: 这是一个yolov7的库,可以用于训练自己的数据集。
论文链接:YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
一、所需环境
当然深度学习环境的搭建是基础,详情可见(win10):
【深度学习】windows10环境配置详细教程_anaconda3环境变量配置win10-CSDN博客
Unbutun搭建深度学习环境可以参考:
Ubuntu20.04配置pytorch深度学习环境(亲测有效)_ubuntu20.04 cuda 11.6 torch安装哪个版本-CSDN博客
PyCharm:2022.2.2版本
torch==1.2.0+
为了使用amp混合精度,推荐使用torch1.7.1以上的版本。
scipy==1.2.1
numpy==1.17.0
matplotlib==3.1.2
opencv_python==4.1.2.30
tqdm==4.60.0
Pillow==8.2.0
h5py==2.10.0
二、训练步骤
a、训练VOC07+12数据集
数据集的准备
本文使用VOC格式进行训练,训练前需要下载好VOC07+12的数据集,解压后放在根目录
VOC数据集下载地址如下,里面已经包括了训练集、测试集、验证集(与测试集一样),无需再次划分:
![]()
链接: https://pan.baidu.com/s/19Mw2u_df_nBzsC2lg20fQA
提取码: j5ge
数据集的处理
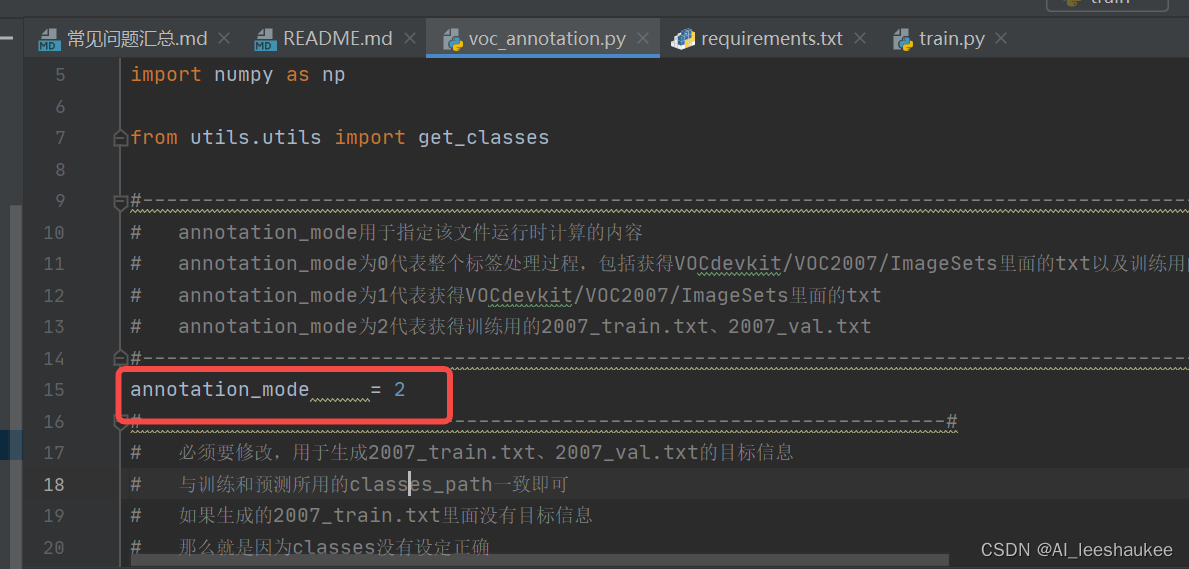
修改工程主目录中的voc_annotation.py里面的annotation_mode=2,运行voc_annotation.py生成根目录下的2007_train.txt和2007_val.txt。
开始网络训练
train.py的默认参数用于训练VOC数据集,直接运行train.py即可开始训练。
不出意外,接下来就一定有意外:
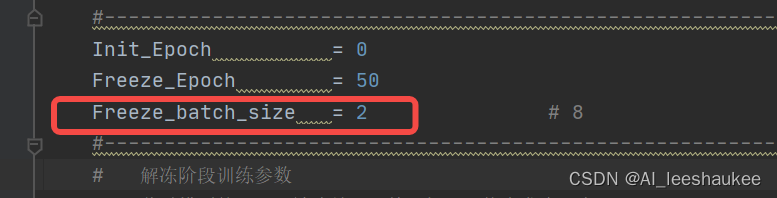
 很明显,我的笔记本显卡不行哦,显卡内存太小,可以调整batch_size。
很明显,我的笔记本显卡不行哦,显卡内存太小,可以调整batch_size。

看到batch_size等于Freeeze_batch_size,将Freeze_batch_size=2
开始训练:
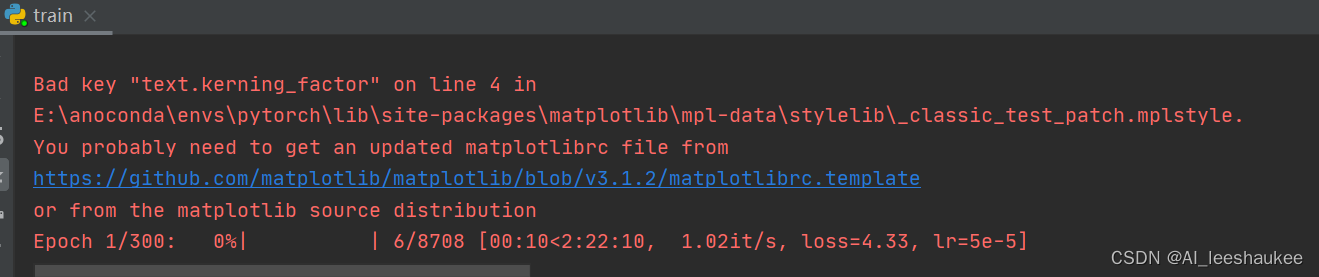
训练结果预测
训练结果预测需要用到两个文件,分别是yolo.py和predict.py。我们首先需要去yolo.py里面修改model_path以及classes_path,这两个参数必须要修改。
model_path指向训练好的权值文件,在logs文件夹里。
classes_path指向检测类别所对应的txt。
完成修改后就可以运行predict.py进行检测了。运行后输入图片路径即可检测。
b、训练自己的数据集
数据集的准备
本文使用VOC格式进行训练,训练前需要自己制作好数据集,
训练前将标签文件放在VOCdevkit文件夹下的VOC2007文件夹下的Annotation中。
训练前将图片文件放在VOCdevkit文件夹下的VOC2007文件夹下的JPEGImages中。
数据集的处理
在完成数据集的摆放之后,我们需要利用voc_annotation.py获得训练用的2007_train.txt和2007_val.txt。
修改voc_annotation.py里面的参数。第一次训练可以仅修改classes_path,classes_path用于指向检测类别所对应的txt。
训练自己的数据集时,可以自己建立一个cls_classes.txt,里面写自己所需要区分的类别。
model_data/cls_classes.txt文件内容为:

修改voc_annotation.py中的classes_path,使其对应cls_classes.txt,并运行voc_annotation.py。
三、预测
a、使用预训练权重
下载完库后解压,在百度网盘下载权值,放入model_data,运行predict.py,输入img/street.jpg
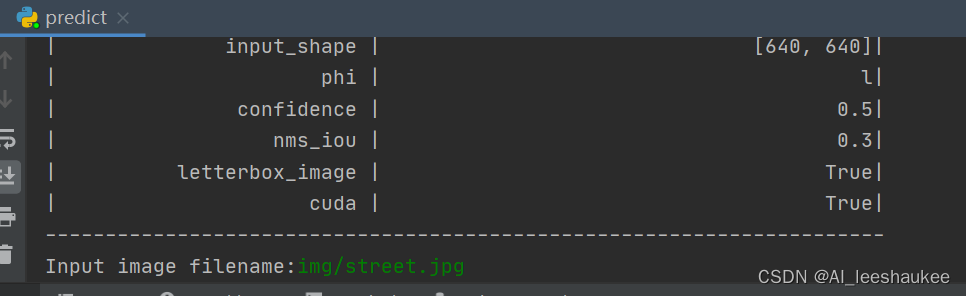
在predict.py里面进行设置也可以进行fps测试和video视频检测。

b、使用自己训练的权重
按照训练步骤训练。
在yolo.py文件里面,在如下部分修改model_path和classes_path使其对应训练好的文件;model_path对应logs文件夹下面的权值文件,classes_path是model_path对应分的类。
更改位置如下:
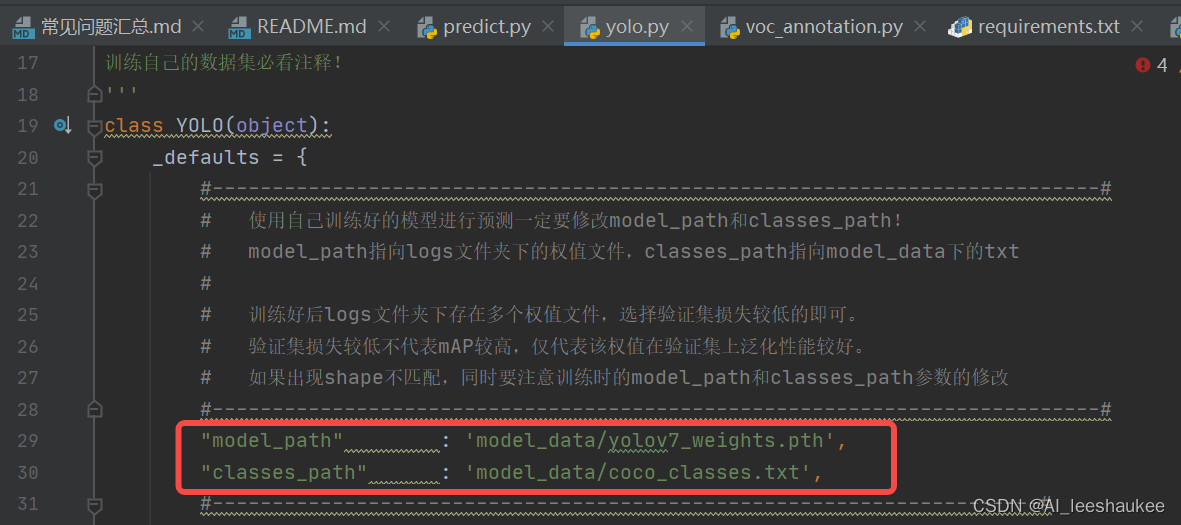
接下来就是运行predict.py,输入预测的图片位置:img/street.jpg,或者:在predict.py里面进行设置可以进行fps测试和video视频检测。
四、评估步骤
a、评估VOC07+12的测试集
- 本文使用VOC格式进行评估。VOC07+12已经划分好了测试集,无需利用voc_annotation.py生成ImageSets文件夹下的txt。
- 在yolo.py里面修改model_path以及classes_path。model_path指向训练好的权值文件,在logs文件夹里。classes_path指向检测类别所对应的txt。
- 运行get_map.py即可获得评估结果,评估结果会保存在map_out文件夹中。
b、评估自己的数据集
- 本文使用VOC格式进行评估。
- 如果在训练前已经运行过voc_annotation.py文件,代码会自动将数据集划分成训练集、验证集和测试集。如果想要修改测试集的比例,可以修改voc_annotation.py文件下的trainval_percent。trainval_percent用于指定(训练集+验证集)与测试集的比例,默认情况下 (训练集+验证集):测试集 = 9:1。train_percent用于指定(训练集+验证集)中训练集与验证集的比例,默认情况下 训练集:验证集 = 9:1。
- 利用voc_annotation.py划分测试集后,前往get_map.py文件修改classes_path,classes_path用于指向检测类别所对应的txt,这个txt和训练时的txt一样。评估自己的数据集必须要修改。
- 在yolo.py里面修改model_path以及classes_path。model_path指向训练好的权值文件,在logs文件夹里。classes_path指向检测类别所对应的txt。
- 运行get_map.py即可获得评估结果,评估结果会保存在map_out文件夹中。

















 5785
5785

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









