






1 骨骼动作识别
由于其广泛的应用场景,例如人机交互、视频监控和犯罪侦查,动作识别是一个热门的研究课题。视频预处理:目的是从视频的底层数据中选取部分特征信息进行动作识别。受视频质量和场景信息复杂的影响,特征提取的方法往往也不相同,光流特征、骨骼特征、RGB特征是目前人体动作识别中最常用的方法。
1、光流特征是人体动作识别中的重要特征,它是通过视频序列中的像素点随时间变化而产生的轨迹特征。光流法是利用图像序列中像素在时间域上的变化以及相邻帧之间的相关性来找到上一帧跟当前帧之间存在的对应关系,从而计算出相邻帧之间物体的运动信息的一种方法。
2、在视频理解领域,为了保留时序信息,需要同时学习时间特征和空间特征,从而获得相邻帧中的运动信息再进行特征聚合,使得到的特征信息更清晰、更有效。随着特征提取方法的日益改进,提取具有价值的时空特征也有了显著进步。
3、在动作识别任务中,基于人体骨骼的动作识别方法相比于基于RGB视频的动作识别方法具有使用成本低、结构信息明显等优点,而且数据集体积小、不受光照影响、良好的结构信息等特点,因为人体3D骨骼中含有关节的位置信息,并且大多数研究也是基于3D骨骼数据来说明不同的人体动作,分析每个关节之间的关系、挖掘出具有典型的一组关节特征来完成动作识别。随着图卷积神经网络的提出,改进提取骨骼特征的方法成为了炙手可热的研究热点。
2 基于骨骼动作识别的研究历史
Yan 等人首次将 GCN 应用于人体骨骼动作识别任务当 中,利用人体骨骼的物理结构特点进行时空建模,提出时空图卷积神经网络(Spatial Temporal Graph Convolutional Networks, ST-GCN)
Shi 等人认为人体骨骼的固定图拓扑结构会影响模型的训练和性能的提升,因此提出双流自适应图卷积神经 网络(Two-Stream Adaptive Graph Convolutional Networks ,2sAGCN),采用固定图拓扑和非固定图拓扑相结合的方式增加图的灵活性,并引入二阶骨骼信息。
Cheng等人(ShiftGCN)引入了两种空间移位图操作来取代计算量大的图卷积,这更有效,并实现了强大的性能。他们还提出了两种时态移位图操作,比以往普通时空模型的性能更好并且有更少的计算量。
STF(SpatioTemporal Focus),用于显式地建模身体关节和身体部位之间的多粒度上下文信息,以实现高效的基于骨架的动作识别我们提出了STF网络的两个关键模块:多粒度上下文聚焦(MCF)和时间分辨聚焦(TDF)。
Liu等将深度图像生成运动历史点云(MHPC,motion history point cloud),保留动作空间与时序信息,以此实现动作的全局表示。
在融合多种数据进行识别方面,毛峡等提出一种基于RGB和骨骼信息的多模态人体行为识别框架。
经总结,骨骼动作识别主要包含的新技术主要有:语义信息,自适应图卷积(卷积),时空融合,多流融合操作,神经架构搜索(NAS)等。
骨骼动作识别中,SGN动作识别流程主要包含数据集的采集、数据预处理、语义信息融合、关节特征提取、时间特征提取、融合分类。

图 1
3 SGN
言归正传,接下来讲解本文的正主,如下图,是语义引导神经网络(SGN)的网络架构图,该网络明确利用了语义(关节类型和帧索引)和动态特性(3D坐标)来实现更高效率的基于骨架的动作识别。
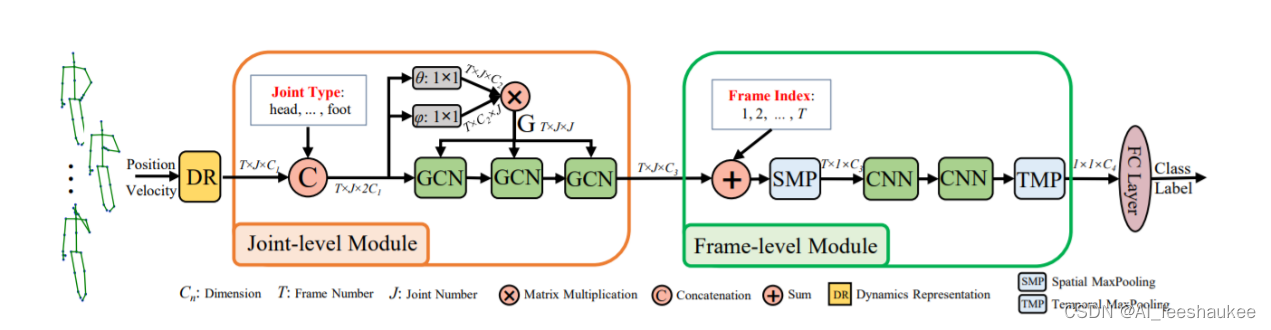
图 2
作者提出的端到端语义引导神经网络的框架。它包括一个关节级别模型和帧级别模型。在DR中,作者通过融合关节的位置(Position)和速度信息(Velocity)来学习关节的动力学表示。有两种类型的语义:关节类型(Joint Type)和帧索引(Frame Index)。他们分别合并到了关节级别模块和帧级别模块。为了在关节模块中对关节间的依赖性建模,作者使用三个GCN层。为了对帧之间的依赖关系进行建模,作者使用两个CNN层。接下来进行各个模块分析:
3-1 在DR之前
将关节位置信息和关节速度信息作为输入之一,骨骼位置信息如图3左侧,关节速度信息如图3右侧所示。
关节位置信息:
bs, step, dim = input.size()
num_joints = dim // 3
input = input.view((bs, step, num_joints, 3))
input = input.permute(0, 3, 2, 1).contiguous() # 关节位置信息
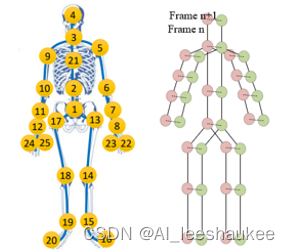
图 3
关节速度信息的代码如下:
input = input.permute(0, 3, 2, 1).contiguous() # 关节位置信息
dif = input[:, :, :, 1:] - input[:, :, :, 0:-1]
dif = torch.cat([dif.new(bs, dif.size(1), num_joints, 1).zero_(), dif], dim=-1)
从该代码可以看出来,关节速度信息是由关节位置信息计算出来的。
作者将关节位置信息和关节速度信息相加后与关节类型信息张量拼接(按通道维度拼接):
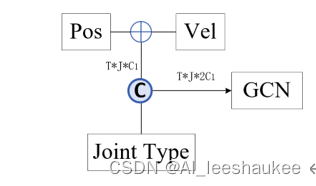
图 4
3-2 Joint-level Module
将Joint-level Module展开细节如下图5所示:
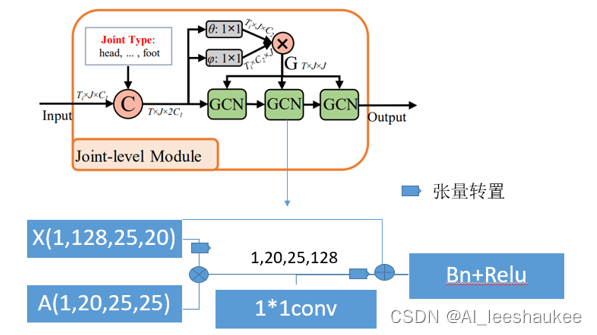
图 5
Joint-level Module模块整体代码如下,上图中的G就是如下代码的g,也就是图卷积中的图拓扑。
# Joint-level Module
input= torch.cat([dy, spa1], 1)
g = self.compute_g1(input) # 计算图拓扑
input = self.gcn1(input, g)
input = self.gcn2(input, g)
input = self.gcn3(input, g)
图拓扑的计算:其原理就是将输入张量转置后进行相乘,得到关节特征之间的关系。
class compute_g_spa(nn.Module):
def __init__(self, dim1 = 64 *3, dim2 = 64*3, bias = False):
super(compute_g_spa, self).__init__()
self.dim1 = dim1
self.dim2 = dim2
self.g1 = cnn1x1(self.dim1, self.dim2, bias=bias)
self.g2 = cnn1x1(self.dim1, self.dim2, bias=bias)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x1):
g1 = self.g1(x1).permute(0, 3, 2, 1).contiguous()
g2 = self.g2(x1).permute(0, 3, 1, 2).contiguous()
g3 = g1.matmul(g2) # 计算A:特征之间的关系
g = self.softmax(g3) # 256
return g
而图卷积的就是将输入张量和图拓扑进行相乘,由此得到新的张量,图卷积的代码如下,和图5中是相对应的。
class gcn_spa(nn.Module):
def __init__(self, in_feature, out_feature, bias = False):
super(gcn_spa, self).__init__()
self.bn = nn.BatchNorm2d(out_feature)
self.relu = nn.ReLU()
self.w = cnn1x1(in_feature, out_feature, bias=False)
self.w1 = cnn1x1(in_feature, out_feature, bias=bias)
def forward(self, x1, g):
x = x1.permute(0, 3, 2, 1).contiguous()
x = g.matmul(x)
x = x.permute(0, 3, 2, 1).contiguous()
x = self.w(x) + self.w1(x1)
x = self.relu(self.bn(x))
return x
其实,SGN作者做了3层图卷积,这个是有实验考证的,图卷积2-3层最好,多层图卷积就是将第1层图卷积的输出作为第2层图卷积的输入,由此类推。
3-3 Frame-level Module
作者设计了一个帧级模块来利用跨帧的相关性。为了让网络知道帧的顺序,结合了帧索引的语义来增强帧的表示能力。
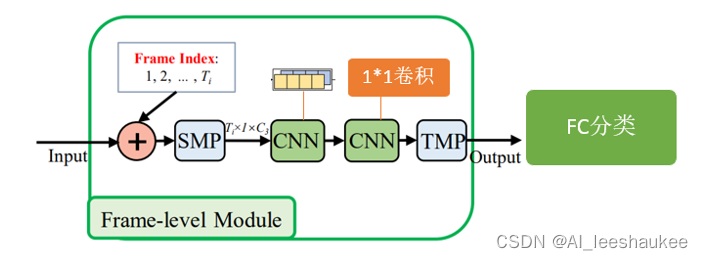
图 6
# Frame-level Module
input = input + tem1
input = self.cnn(input) # 包括SMP和两个CNN
这里没什么可讲的,就是将图卷积的输出作为Frame-level Module的输入,同时将该输入加上帧索引信息(就是包含帧的顺序信息),后续再经过空间最大池化(SMP),两次1*3卷积(提取时间维度的信息特征),再经过时间最大池化(TMP)其具体代码如下:
class local(nn.Module):
def __init__(self, dim1 = 3, dim2 = 3, bias = False):
super(local, self).__init__()
self.maxpool = nn.AdaptiveMaxPool2d((1, 20))
self.cnn1 = nn.Conv2d(dim1, dim1, kernel_size=(1, 3), padding=(0, 1), bias=bias)
self.bn1 = nn.BatchNorm2d(dim1)
self.relu = nn.ReLU()
self.cnn2 = nn.Conv2d(dim1, dim2, kernel_size=1, bias=bias)
self.bn2 = nn.BatchNorm2d(dim2)
self.dropout = nn.Dropout2d(0.2)
def forward(self, x1):
x1 = self.maxpool(x1)
x = self.cnn1(x1)
x = self.bn1(x)
x = self.relu(x)
x = self.dropout(x)
x = self.cnn2(x)
x = self.bn2(x)
x = self.relu(x)
return x
经过时间最大池化(上面代码没显示)后,再经过全连接层,将最后的张量输入到分类器中。当然,模型中的很多细节没有展示,我只是按着网络架构图将模型讲解一遍,具体的实现细节请读者仔细研究代码:GitHub - microsoft/SGN: This is the implementation of CVPR2020 paper “Semantics-Guided Neural Networks for Efficient Skeleton-Based Human Action Recognition”.
4 结尾
人体骨骼动作识别应用很广泛,作为人工智能中一部分,在将来的发展也将会得到越来越多人的重视,大家有喜欢人工智能(图像识别、分类、目标检测、图像分割、超分辨率、自然语言处理、大语言模型等)或者人骨骼动作识别的请学习起来吧。

















 7385
7385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









