







 超级会员免费看
超级会员免费看
一、研究背景
现有模型主要通过提取特定的伪造模式进行深度伪造检测,导致学习到的表征与训练集中已知的伪造类型高度相关,因此模型难以泛化到未知的伪造类型上使用。
二、研究动机
1.真实样本的特征分布相对更为紧凑,因此学习真实人脸之间的共同特性比学习训练集呈现出的过拟合伪造特性更为合适。
2.为习得真实人脸与伪造人脸的本质区别,需要提高对伪造线索的推理能力。
3.不同的伪造技术会产生不同尺度的伪造痕迹,因此需要设置多尺度机制。
4.伪造区域会产生重构差异,因此可利用重构差异引导分类学习。
5.伪造线索往往出现在连续区域,因此在对信息进行聚合时需要保持空间一致性( N \mathcal{N} N)。
6.经过损失的约束,decoder层也具有鉴别性信息,因此可以用decoder特征对encoder特征进行丰富。
三、研究目标
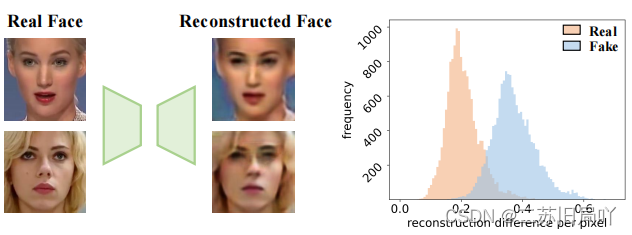
只对真实样本

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 1207
1207











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











