







让大模型理解三维世界,NIPS论文《3D-LLM: Injecting the 3D World into Large Language Models》简要解读
本文是关于NIPS最新论文《3D-LLM: Injecting the 3D World into Large Language Models》的简要技术介绍。大模型已经在多个领域斩头露角,但是在三维领域,目前的工作并不算多。将三维与大语言模型结合起来,存在以下难点:
- 三维-语言数据稀缺;
- 三维特征与语言特征的对齐;
- 三维信息的提取;
这篇文章着重解决将三维模型与大语言模型结合时遇到的上述问题。
本文写于2024年4月15日。
有关本专栏的更多内容,请参考大语言模型文献调研专栏目录
文章目录
1. 基本信息
1.1 论文资料
题目:3D-LLM: Injecting the 3D World into Large Language Models
代码:https://github.com/UMass-Foundation-Model/3D-LLM
项目:https://vis-www.cs.umass.edu/3dllm/
引用:
@article{3dllm,
author = {Hong, Yining and Zhen, Haoyu and Chen, Peihao and Zheng, Shuhong and Du, Yilun and Chen, Zhenfang and Gan, Chuang},
title = {3D-LLM: Injecting the 3D World into Large Language Models},
journal = {NeurIPS},
year = {2023},
}
1.2 动机
最新的大语言模型(LLMs,例如GPT4)以及多模态大语言模型(MLLMs,例如BLIP2等)层出不穷,但是它们是基于网络上爬取的大规模数据而非真实三维世界构建的。真实三维世界包含物体位置、功能和物理信息,有助于三维理解和推理任务,因此作者提出3DLLM,输入三维点云及其特征,输出与指令相关的语言序列。将三维表示作为输入有以下优点:
- 完整的长时记忆: 通过获取三维场景的表示,LLMs能够存储整个场景的长时记忆,而不仅仅是片段式的局部观测。
- 三维属性推理: 从三维表示中可以推断出诸如功能性和空间关系等三维属性,远超出基于语言或二维图像的LLMs的范围。
但是为LLM注入三维信息也存在三维数据稀缺的困难和三维特征与语言特征对齐的困难。作者通过以下手段解决:
- **提出三维语言数据生成框架:**作者生成大规模的与语言配对的3D数据。利用ChatGPT并设计了三种有效的提示程序,用于3D数据和语言之间的交流。这种方式能够获取大约一百万条3D语言数据,涵盖了多种任务,包括但不限于3D字幕、密集字幕、3D问答、3D任务分解、3D基础、辅助对话、导航等。
- 利用二维特征。与大规模预训练(如CLIP)不同,作者利用一个3D特征提取器从多视角图像的预训练2D特征中构建特征,这种方法与现有的视觉-语言模型是一致的,可以无缝地与2D VLMs整合,为3D-LLMs的高效训练提供支持。
- 三维位置信息。作者开发了一种3D定位机制,弥合语言和空间位置之间的差距。具体地,作者在提取的3D特征上附加3D位置嵌入,以更好地编码空间信息。此外,作者在3D-LLMs中附加了一系列位置标记,可以通过输出位置标记来训练定位,给定场景中特定对象的语言描述,帮助3D-LLMs更好地捕捉3D空间信息。
2. 研究现状
2.1 大语言模型LLMs
- 大语言模型(LLMs,如GPT-3和PaLM等)能够使用单个模型处理不同的语言任务,并展现出强大的泛化能力。这些模型通常在大规模文本数据上进行训练,自监督的预测下一个标记或重构掩码标记。
- 大模型优化。为使LLMs的预测符合人类指示,并提高模型在未见任务上的泛化能力,一些研究提出了一系列的指导调整方法和数据集。
- 将3D注入LLMs。本论文目标是将3D世界注入到大语言模型中,理解丰富的3D概念,如空间关系、功能性和物理性。
2.2 视觉-语言预训练VLMs
- 一些研究着重基于大规模视觉-语言数据进行预训练,并将这些模型被微调后用于视觉问答、字幕生成和表达理解等下游任务。
- 一些研究人员通过额外模块(感知机和 QFormers),将预训练的视觉模型和预训练的大型语言模型(LLMs)连接起来,利用预训练视觉模型的感知能力以及LLMs的推理和泛化能力。
- 作者收到上述启发,构建一个能够理解3D世界并执行相应3D推理和规划的AI助手。这个任务需要解决如何处理数据稀疏性问题、如何将3D世界与2D图像对齐以及如何捕捉3D空间信息等障碍。
2.3 三维和语言
- ScanQA:让模型回答与3D世界相关的问题。
- ScanRefer:让模型定位文本表达所指的区域。
- 3D captioning :测试模型生成描述3D场景的字幕的能力。
- 作者提出的3DLLM:上述3D任务及模型通常是任务限定的,并且只能处理训练集分布范围内的情况,无法进行泛化。与它们不同,作者构建了一个能够同时处理不同任务的3D模型,并实现新的能力,如3D助理对话和任务分解。
3. 构建三维语言数据集
市面上已经有了大量互联网2D图像及文本数据集,但是对于3D数据集多是任务限定的(例如ScanQA,ScanRefer等)。作者用GPT辅助生成三维语言数据。
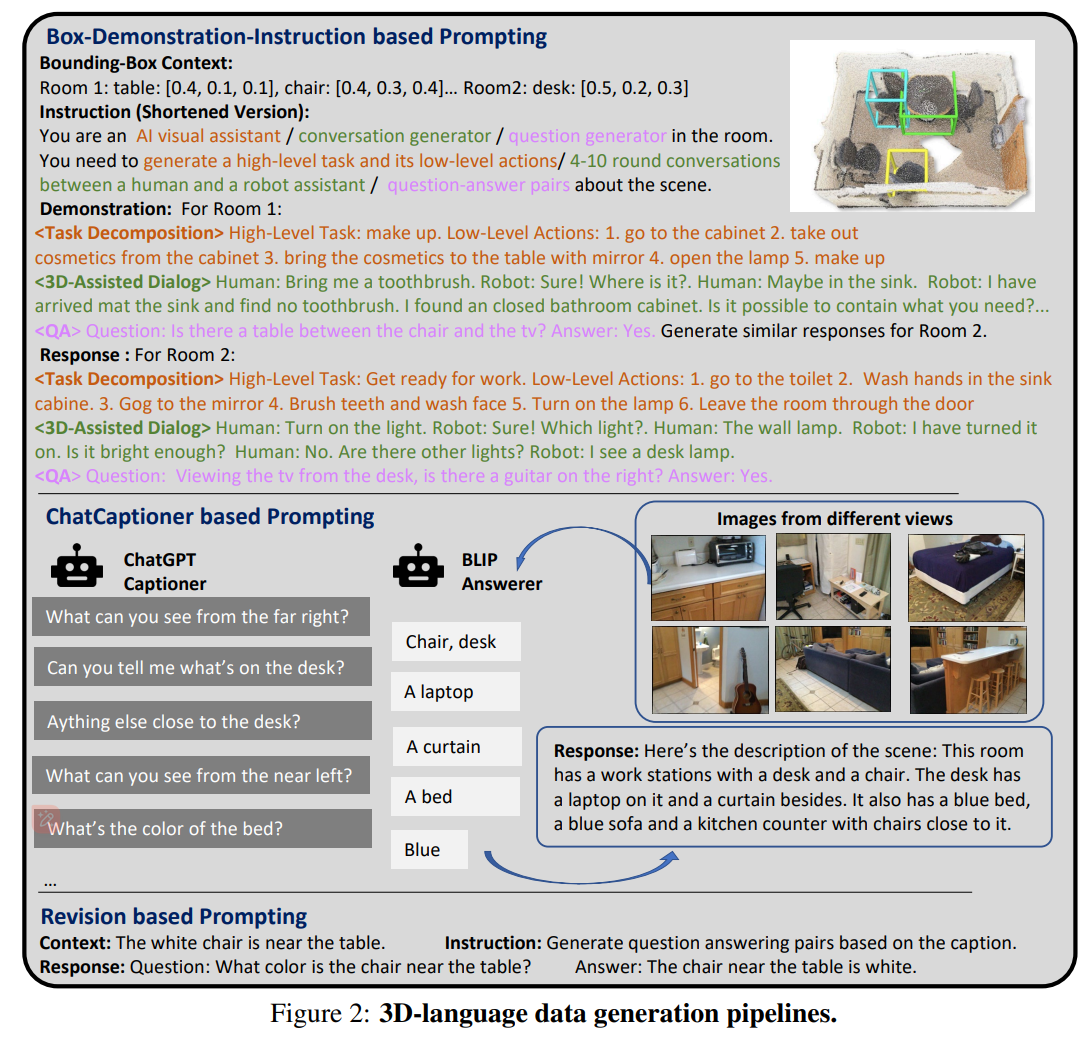
- 基于三维检测框的提示。输入3D场景中房间和物体的三维框,并且提供有关场景的语义和空间位置的信息。然后向GPT模型提供具体的指令,以生成多样化的数据。
- 基于基于ChatCaptioner的提示。作者引导ChatGPT提出有关图像的一系列问题,让BLIP-2则回答这些问题。作者首先从3D场景的不同视角中抽几个图像,并输入到ChatGPT和BLIP-2中得到标题描述文本。,再利用ChatGPT总结所有这些标题文本,这些文本中包含有关不同区域的信息,形成整个场景的全局3D描述。
- 基于修订的提示。它可用于将一种类型的3D数据转换为另一种类型。

以上的三维场景来源于以下数据:
- Objaverse:包含800K个3D对象,由于语言描述是从在线来源提取的,而没有经过人类审查,大多数对象的描述非常嘈杂(例如,包含URL)或没有描述。作者利用基于ChatCaptioner的提示来为场景生成高质量的3D相关描述,并利用基于修订的提示来生成问题。
- **Scannet **:包含大约1k个丰富注释的3D室内场景的数据集,它提供了场景中物体的语义和边界框。
- Habitat-Matterport(HM3D):是一个具有体验智能的3D环境的数据集。HM3DSem进一步为HM3D的200多个场景添加了语义注释和边界框。作者在3D-CLR中使用了HM3D的预分割房间。
4. 3DLLMs
4.1 使用2D方式提取3D特征
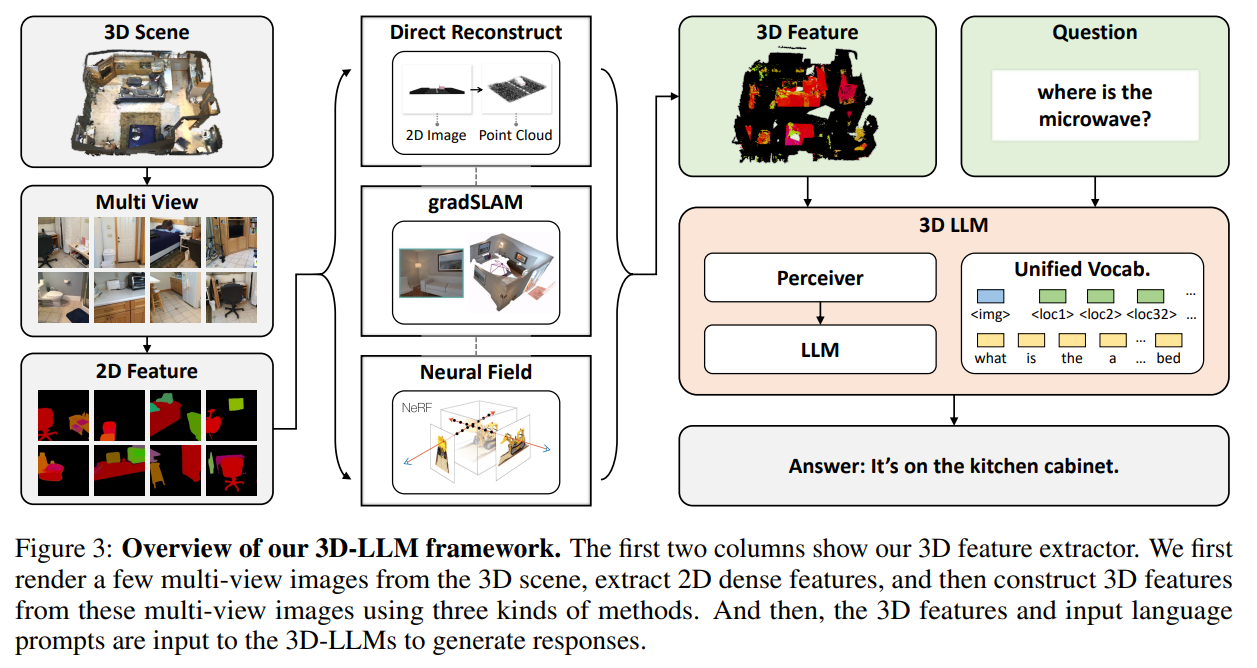
现在的2D特征提取器已经很成熟了,并且是经过大规模预训练的(例如CLIP)。如果从头做3D的大规模预训练,数据短缺成本高昂不现实。因此,作者借鉴了目前很多人利用2D特征提取器提取3D场景特征的方式。作者通过在几个不同的视图中渲染3D场景来提取3D点的特征,并从渲染的图像特征构建3D特征。有了像素级别的2D特征后,作者通过以下方式构建3D特征:
- 直接重建法:使用真实相机参数直接从渲染的RGBD图像中重建点云,特征直接映射到重建的3D点。这种方法适用于带相机姿态和内参的渲染RGBD数据。
- 特征融合:作者用gradslam将2D特征融合到3D映射中,与密集映射方法不同,这些特征与深度和颜色一起融合。这种方法适用于具有嘈杂深度图像渲染或嘈杂相机姿态和内参的3D数据。
- 神经场:使用神经体素场构建3D紧凑表示。具体而言,场中的每个体素都有一个除了密度和颜色的特征。然后使用MSE损失在射线中对齐3D特征,在像素中对齐2D特征。这种方法适用于具有RGB渲染但没有深度数据以及嘈杂相机姿态和内参的3D数据。
4.2 训练3DLLMs
从头训练3D-LLMs不现实,需要使用2D提取:通常情况下,训练使用了约50亿张图像之后,2D VLMs的训练才开始逐渐有效。它们使用冻结和预训练的图像编码器(如CLIP)来提取2D图像的特征。由于3D特征提取器可以将3D特征映射到与2D图像相同的特征空间,因此将这些预训练的2D VLMs用作主干简便而合理。作者设计的2D特征提取器有以下要点:
- 感知器架构:感知器架构利用不对称的注意机制将输入逐步提炼成紧凑的特征,因此能够处理任意大小的非常大的输入并处理不同的模态。这种架构被用于像Flamingo这样的VLMs中。BLIP-2也利用了一个名为QFormer的类似结构。由冻结的图像编码器输出的2D图像特征被展平并送到感知器中以生成固定大小的输入。
- 3D特征提取器与2D特征空间对齐:由于3D特征与3D特征提取器将其映射到与2D图像相同的特征空间中,因此可以将具有任意大小的点云特征输入到感知器中。因此,作者使用3D特征提取器在与冻结图像编码器特征空间相同的特征空间中提取3D特征。
- 使用预训练的2D VLMs作为主干:考虑到感知器可以处理相同特征维度的任意大小的输入,作者将对齐的3D特征输入到预训练的2D VLMs中,用收集的3D-语言数据集训练3D-LLMs。
3D定位。如何将物体的位置信息引入到LLM中是另一个问题,一个简单的思路是,通过已与语言对齐的2D预训练特征提取器(如CLIP和EVA-CLIP)重建3D特征后,可以通过直接计算3D特征与语言特征之间的相似性来进行定位。但是作者更希望模型本身能够捕获3D空间信息。作者提出了一种3D定位机制,增强了3D-LLMs吸收空间信息的能力。该机制包括两个部分:
(1)用位置嵌入增强3D特征;位置嵌入部分是将位置嵌入添加到从2D多视图特征聚合的3D特征中。
(2)用位置标记增强LLM词汇表。位置标记部分则是将3D位置嵌入到词汇表中,使得3D空间位置与LLMs对齐。
5. 实验
5.1 架构和数据集
作者在以下三种2D VLMs架构上进行了3D-LLMs:
- Flamingo 9B:
- BLIP-2 Vit-g Opt2.7B
- BLIP-2 Vit-g FlanT5-XL。
对于BLIP-2,预训练3D-LLMs涉及从LAVIS库中的BLIP-2检查点初始化模型,然后微调QFormer的参数。3D特征为1408维,与BLIP-2使用的EVA_CLIP隐藏特征维度一致。LLMs的大部分部分(Opt和FlanT5)保持冻结状态,除了与输入和输出嵌入中的新添加的位置标记相关的权重。
对于Flamingo,模型从OpenFlamingo存储库中的Flamingo9B检查点初始化。对于感知器、门控交叉注意力层以及输入和输出嵌入中的额外位置标记的权重,参数进行了微调。3D特征为1024维,与Flamingo使用的CLIP隐藏特征维度一致。
数据集:训练和评估数据集及协议涉及将数据集分为两类:持有数据集和留出数据集。
- **持有数据集(Held-out):**这些数据集是通过3D语言数据生成的,涵盖了多个任务。训练集用于预训练基础3D-LLMs,在预训练期间,结合了所有任务的持有数据集。持有数据集的验证集在预训练期间用于持有评估。模型使用标准的语言建模损失进行训练,以生成响应。
- **留出数据集:**这些数据集与持有数据集不同,并且不用于训练基础3D-LLMs。为了留出评估,作者使用了三个3D问答数据集:ScanQA,SQA3D和3DMV-VQA。
5.2 ScanQA结果
基线模型与评估指标:作者将代表性的基线模型纳入我们的基准评估中。
- ScanQA: 这种方法被认为是最先进的,利用VoteNet提出对象提议,然后将它们与语言嵌入融合。
- ScanRefer+MCAN: 这个基线标识了被引用的对象,并将MCAN模型应用于周围定位对象的图像。
- VoteNet+MCAN: 它检测3D空间中的对象,提取它们的特征,并将它们整合到标准VQA模型中。值得注意的是,这些基线模型都从预训练的定位模块中提取显式对象表示。
除了上述基线之外,我们还引入了几个基于LLM的基线:
- LLaVA: 这个模型通过连接视觉编码器和LLM进行通用视觉和语言理解的视觉指令调整。作者使用其预训练模型在作者的数据集上进行零样本评估,输入为单个随机图像。
- ULIP编码器 + LLMs: 这个设置利用现有的预训练3D编码器与LLMs进行比较,用于3D预训练编码器和2D编码器的特征编码。
- 单个图像 + 预训练的VLMs: 作者的2D VLM主干(Flamingo和BLIP-2)将3D-LLMs的3D输入替换为单个图像特征进行训练,然后在ScanQA数据集上进行微调。
- 多视角图像 + 预训练的VLMs: 与前一个基线类似,作者的2D VLM主干将3D输入替换为多视角图像的串联特征进行训练,然后在ScanQA数据集上进行微调。
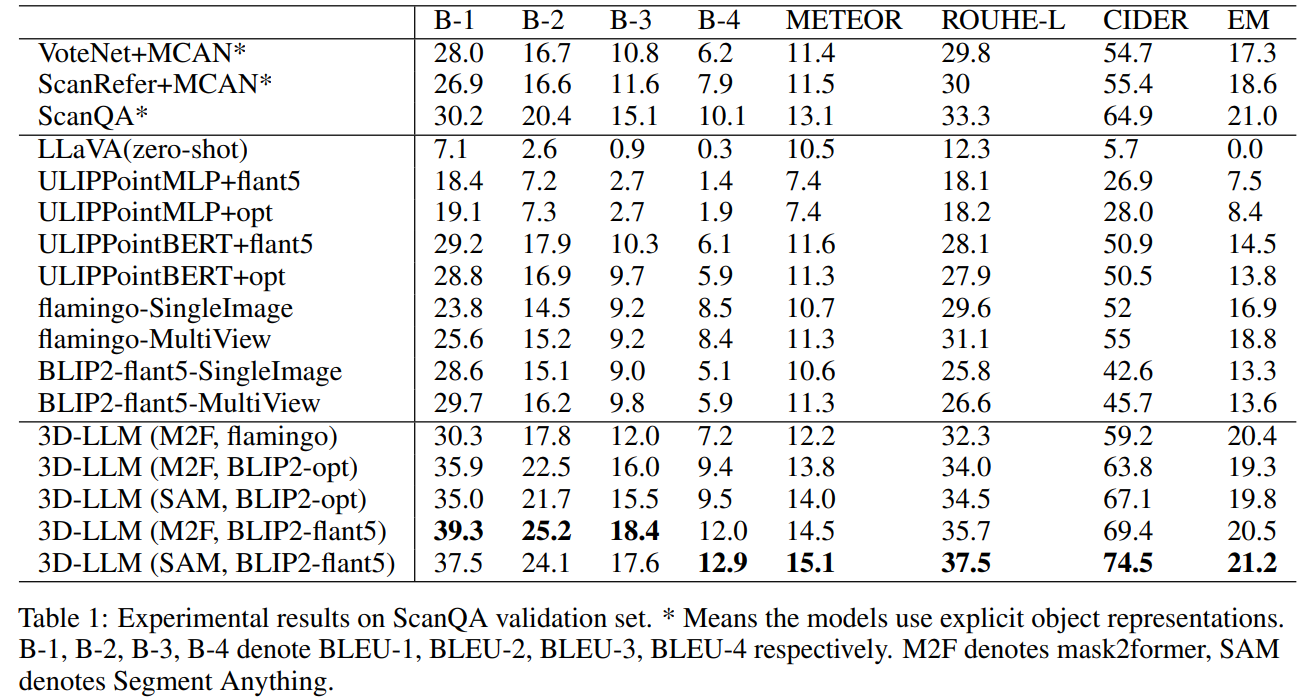
作者使用BLEU、ROUGE-L、METEOR、CIDEr进行稳健的答案匹配评估,以及准确匹配(EM)指标。
在BLEU-1方面,作者的模型在验证集上比最先进的ScanQA模型提高了约9%。在CIDEr方面,作者相比ScanQA报告了约10%的增长,明显优于其他基于3D的基线模型。这些结果表明,将3D集成到LLMs中可以生成更接近于真实答案的答案。
此外,传统的基于3D的基线模型利用对象检测器(如VoteNet)进行对象分割,然后将每个对象的特征输入模型。相比之下,作者的方法使用了没有显式对象表示的整体3D特征,表明作者的模型即使在没有显式对象表示的情况下也能进行关于对象及其关系的视觉推理。
随后,作者调查了2D VLMs是否具有相似的能力。然而,作者观察到当使用单视图或多视图图像作为输入时,性能大幅下降,与3D-LLMs相比。尽管多视图图像包含有关整个场景的信息,但它们的性能远远落后于3D-LLMs,可能是因为多视图图像特征的组织混乱,导致丢失了与3D相关的信息。
5.3 SQA3D结果
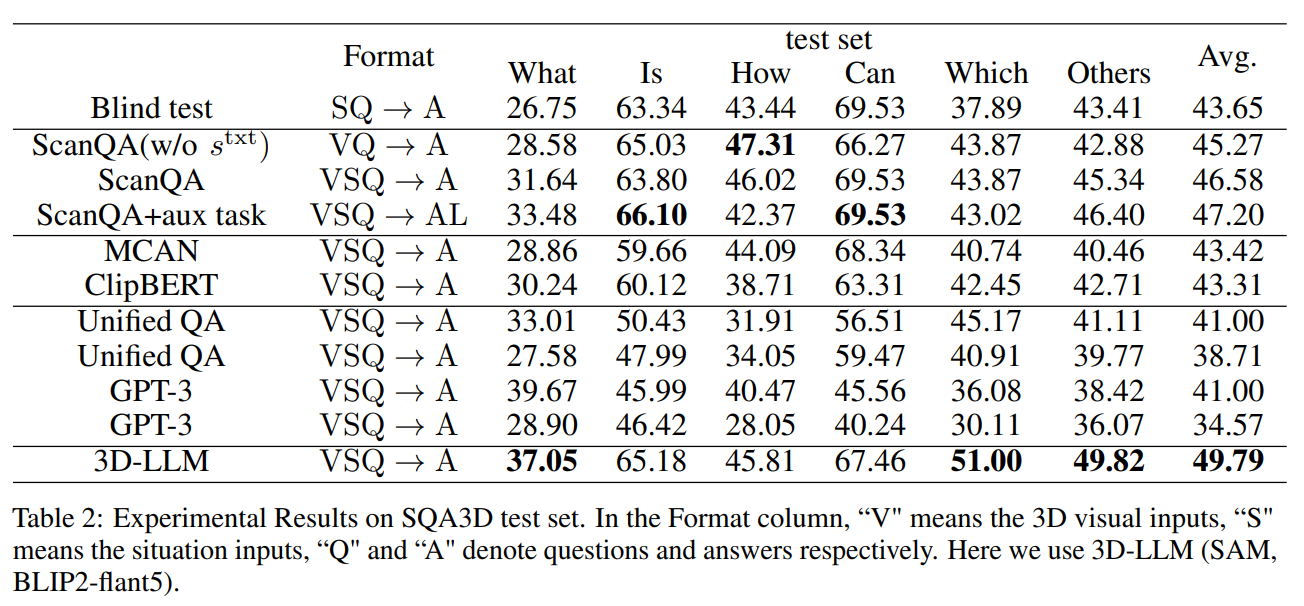
SQA3D 任务描述:SQA3D要求测试代理根据文本描述理解其在三维场景中的空间背景,包括位置和方向。随后,代理必须进行关于周围环境的推理,以准确回答提出的问题。
模型微调与比较:作者的方法涉及在SQA3D数据集上微调预训练的3D语言模型(3D-LLMs),作者的ScanQA+aux任务通过整合两个辅助任务:预测代理在给定情境中的位置和旋转,实现了最先进的性能(SOTA)。即使在训练过程中没有引入辅助任务和相关损失,作者的模型也取得了显著的性能提升。
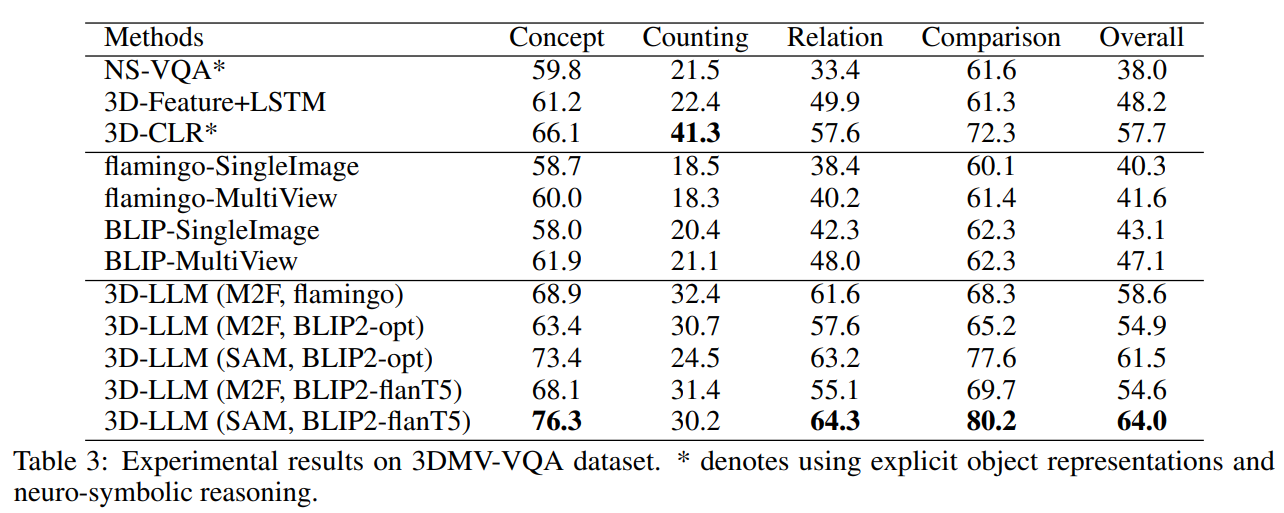
5.4 3DMV-VQA结果
作者对预训练的3D-LLMs在3DMV-VQA数据集上进行微调,并与基准模型进行比较。具体而言,3D-CLR通过基于3D特征的神经符号推理实现了最先进的性能(SOTA)。
3D-LLMs在概念和关系等问题类型上优于最先进的基准模型,并且在整体性能上也表现优异。作者的模型还优于3D-Feature+LSTM,展示了LLMs相对于具有类似3D特征作为输入的普通语言模型的优势。总体而言,基于3D的方法优于基于2D的方法。作者的3D-LLMs在性能上优于相应的2D VLMs与图像输入,进一步证明了3D表示对于3D-LLMs的重要性。
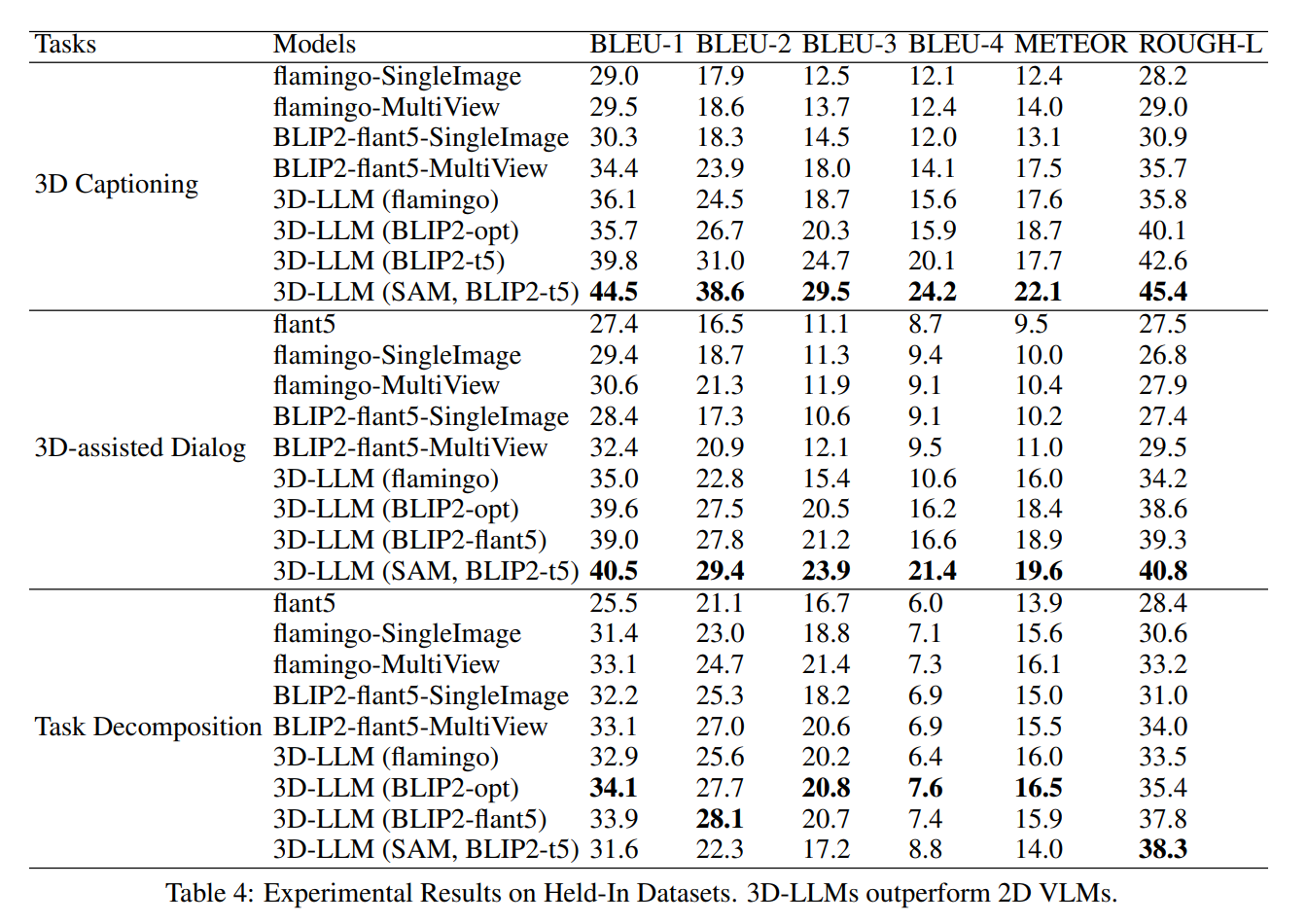
5.5 保留数据
作者在三个任务的保留数据集上进行实验:3D字幕,3D辅助对话和任务分解。保留评估的基准包括2D视觉语言模型(VLMs)。此外,作者引入了一个仅语言的基准,FlanT5,以评估语言模型(LMs)在没有视觉输入的情况下完成任务的能力。
为了评估响应质量,作者采用BLEU、ROUGE-L、METEOR和CIDEr等指标。实验结果表明,3D-LLMs表现出生成高质量响应的能力,超越了2D VLMs和仅语言的LMs。
5.6 可视化效果

有关本专栏的更多内容,请参考大语言模型文献调研专栏目录
者自知才疏学浅,难免疏漏与谬误,若有高见,请不吝赐教,笔者将不胜感激!
softargmax
2024年4月15日


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









