







NIPS2023文章《VisionLLM: Large Language Model is also an Open-Ended Decoder for Vision-Centric Tasks》简要技术介绍
本文写于2024年4月9日。
本文是关于NIPS2023论文VisionLLM的简要介绍。VisionLLM是一个多模态的大语言模型框架,可以借助大语言模型的力量,实现自定义的传统视觉任务,例如检测、分割、图像标题等。框架最大的特点就是灵活性和适应性,通过语言指令让模型做不限定的视觉任务。本文按照论文顺序和主要内容做介绍。
有关本专栏的更多内容,请参考大语言模型文献调研专栏目录
文章目录
1. 基础信息
1. 资源
论文题目:VisionLLM: Large Language Model is also an Open-Ended Decoder for Vision-Centric Tasks
论文代码:https://github.com/OpenGVLab/VisionLLM
论文引用(BibTex):
@article{wang2024visionllm,
title={Visionllm: Large language model is also an open-ended decoder for vision-centric tasks},
author={Wang, Wenhai and Chen, Zhe and Chen, Xiaokang and Wu, Jiannan and Zhu, Xizhou and Zeng, Gang and Luo, Ping and Lu, Tong and Zhou, Jie and Qiao, Yu and others},
journal={Advances in Neural Information Processing Systems},
volume={36},
year={2024}
}
1.2 论文的动机
大型语言模型(LLMs)显著推动了人工通用智能(AGI)的进展,展现出令人瞩目的zero-shot能力,可供用户处理定制任务,这样的特性在各种应用中具有巨大潜力。然而,在计算机视觉领域,尽管存在许多强大的视觉基础模型(VFMs),任务的形式仍然是提前定义好的,并不能像LLMs那样解决开放式任务。
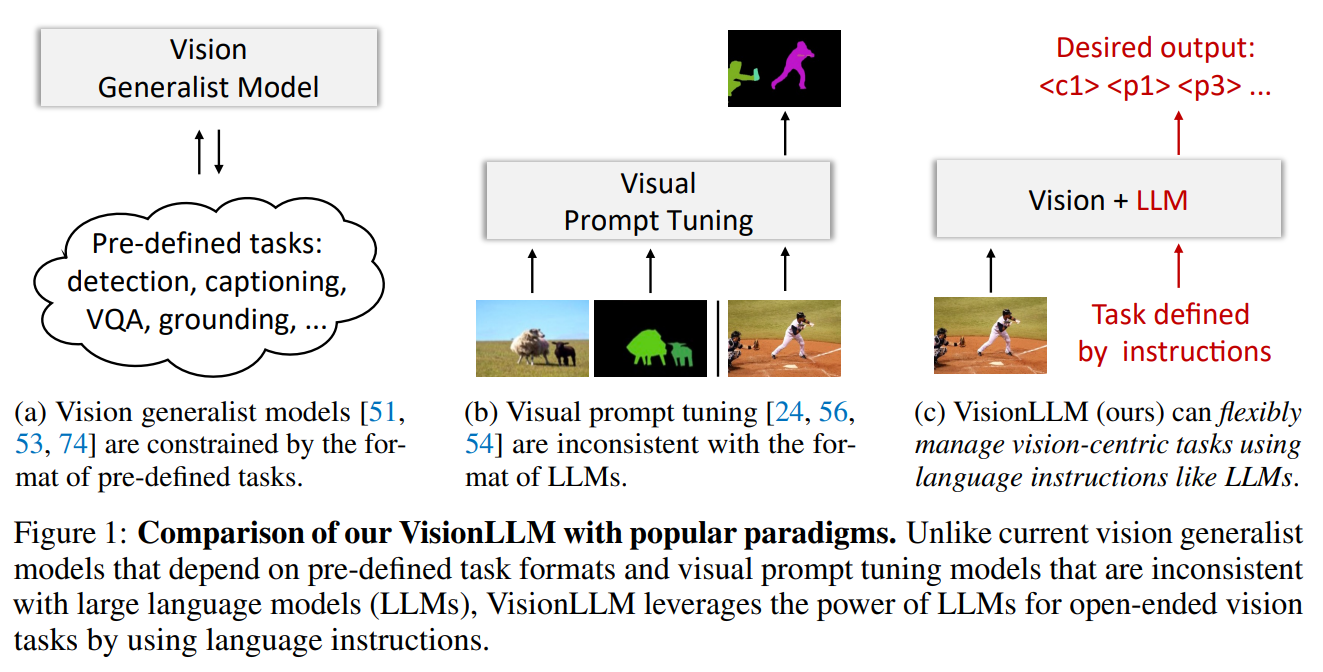
视觉提示微调(Visual Instruction Tuning)已经成为一种灵活勾勒纯视觉任务的方式,例如利用视觉掩码进行目标检测、实例分割和姿态估计。然而,视觉提示的格式与语言指令差异很大,这使得直接将LLMs的推理能力和世界知识应用于视觉任务变得具有挑战性。因此,迫切需要一个统一的通用框架,可以无缝地整合LLMs的优势和视觉中心任务的特定要求。
基于此,作者提出VisionLLM,这是一个基于LLM的解决视觉中心任务的框架。VisionLLM将图像视为一种外语,将视觉中心任务与语言任务对齐,这种对齐允许使用语言指令灵活定义和管理任,基于LLMs的解码器然后根据这些指令预测开放式任务的结果。实验证明了通过语言指令实现各种级别的任务定制的VisionLLM的能力,从细粒度的对象级别到粗粒度的任务级别定制,都取得了良好的结果。
2. 前人工作
2.1 大语言模型
LLM在语言生成、上下文学习、世界知识和推理方面表现出色,GPT系列是代表作,包括GPT-3、ChatGPT、GPT-4和InstructGPT,其他LLMs如OPT、LLaMA、MOSS和GLM也较为著名。
近期出现了基于API的应用程序,解决了以视觉为中心的任务,这些应用程序将视觉API与语言模型结合,以进行决策或规划。使用基于语言的指令描述视觉元素便利,但仍面临细节捕捉和复杂背景理解的限制, 这些限制影响了视觉和语言模型的有效连接。
因此, LLMs在
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 817
817

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









