







1.导包
import os
import glob
import time
import random
import argparse
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
import scipy.sparse as sp
parser = argparse.ArgumentParser()
parser.add_argument('--no-cuda',action = 'store_true',default = True,help = 'Use Cuda')
parser.add_argument('--fastmode',action = 'store_true',default = False,help = 'Validate during training pass.')
parser.add_argument('--sparse',action = 'store_true',default = False,help = 'GAT with sparse version or not.')
parser.add_argument('--seed',type = int,default = 72,help = 'Random seed.')
parser.add_argument('--epochs',type = int,default = 2,help = 'Number of epochs to train.')
parser.add_argument('--lr',type = float,default = 0.005,help = 'Initial learning rate.')
parser.add_argument('--weight_decay',type = float,default = 5e-4,help = 'Weight decay (L2 loss on parameters).')
parser.add_argument('--hidden',type = int,default = 8,help = 'Number of hidden units.')
parser.add_argument('--nb_heads',type = int,default = 8,help = 'Number of head attentions.')
parser.add_argument('--dropout',type = float,default = 0.6,help = 'Dropout rate (1 - keep probability).')
parser.add_argument('--alpha',type = float,default = 0.2,help = 'Alpha for the leaky_relu.')
parser.add_argument('--patience',type = int,default = 100,help = 'Patience')
args = parser.parse_args(args = [])
args.cuda = not args.no_cuda and torch.cuda.is_available()
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
if args.cuda:
torch.cuda.manual_seed(args.seed)
2.数据处理
def encode_onehot(labels):
classes = set(labels)
classes_dict = {c:np.identity(len(classes))[i,:] for i,c in enumerate(classes)}
labels_onehot = np.array(list(map(classes_dict.get,labels)),dtype = np.int32)
return labels_onehot
#labels = ['a','b','b']
#encode_onehot(labels)
if args.cuda:
torch.cuda.manual_seed(args.seed)
邻接矩阵与特征标准化
def normalize_features(mx):
# 对每一行求和
rowsum = np.array(mx.sum(1))
# 求倒数
# print(rowsum)
r_inv = np.power(rowsum,-0.5).flatten()
# 无穷位置为0
r_inv[np.isinf(r_inv)] = 0
# 构建对角矩阵
r_mat_inv = sp.diags(r_inv)
mx = r_mat_inv.dot(mx)
return mx
def normalize_adj(mx):
# 对邻接矩阵标准化
rowsum = np.array(mx.sum(1))
r_inv_sqrt = np.power(rowsum,-0.5).flatten()
# 无穷大制成0
r_inv_sqrt[np.isinf(r_inv_sqrt)] = 0
# 对角矩阵
r_mat_inv_sqrt = sp.diags(r_inv_sqrt)
return mx.dot(r_mat_inv_sqrt).transpose().dot(r_mat_inv_sqrt)
加载数据并处理
def load_data(path = './data/cora/',dataset = 'cora'):
print('Loading {} dataset..'.format(dataset))
idx_features_labels = np.genfromtxt('{}{}.content'.format(path,dataset),dtype = np.dtype(str))
# 存储csr型稀疏矩阵
features = sp.csr_matrix(idx_features_labels[:,1:-1],dtype = np.float32)
labels = encode_onehot(idx_features_labels[:,-1])
idx = np.array(idx_features_labels[:,0],dtype = np.int32)
# old_id:number
idx_map = {j:i for i,j in enumerate(idx)}
# 读取边表 <paper_id> <paper_id>
edges_unordered = np.genfromtxt('{}{}.cites'.format(path,dataset),dtype = np.int32)
# 通过id转化边
edges = np.array(list(map(idx_map.get,edges_unordered.flatten()))).reshape(edges_unordered.shape)
# 建立稀疏邻接矩阵
adj = sp.coo_matrix((np.ones(edges.shape[0]),(edges[:,0],edges[:,1])),shape = (labels.shape[0],labels.shape[0]),dtype = np.float32)
# 生成max对称矩阵
adj = adj + adj.T.multiply(adj.T > adj) - adj.multiply(adj.T > adj)
# 特征标准化
features = normalize_features(features)
# 邻接矩阵标准化
adj = normalize_adj(adj + sp.eye(adj.shape[0]))
# 切分数据集
idx_train = range(140)
idx_val = range(200,500)
idx_test = range(500,1500)
# 处理成tensor的形式
adj = torch.FloatTensor(np.array(adj.todense()))
features = torch.FloatTensor(np.array(features.todense()))
labels = torch.LongTensor(np.where(labels)[1])
print('adj.shape:',adj.shape)
print('features.shape:',features.shape)
print('labels.shape:',labels.shape)
idx_train = torch.LongTensor(idx_train)
idx_val = torch.LongTensor(idx_val)
idx_test = torch.LongTensor(idx_test)
return adj,features,labels,idx_train,idx_val,idx_test
adj,features,labels,idx_train,idx_val,idx_test = load_data()
3.模型定义
GraphAttentionLayer

import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
class GraphAttentionLayer(nn.Module):
def __init__(self,in_features,out_features,dropout,alpha,concat = True):
super(GraphAttentionLayer,self).__init__()
self.dropout = dropout
self.in_features = in_features
self.out_features = out_features
# 学习因子
self.alpha = alpha
self.concat = concat
# 建立zero矩阵
self.W = nn.Parameter(torch.empty(size = (in_features,out_features)))
nn.init.xavier_uniform_(self.W.data,gain = 1.414)
self.a = nn.Parameter(torch.empty(size = (2 * out_features,1)))
nn.init.xavier_uniform_(self.a.data,gain = 1.414)
self.leakyrelu = nn.LeakyReLU(self.alpha)
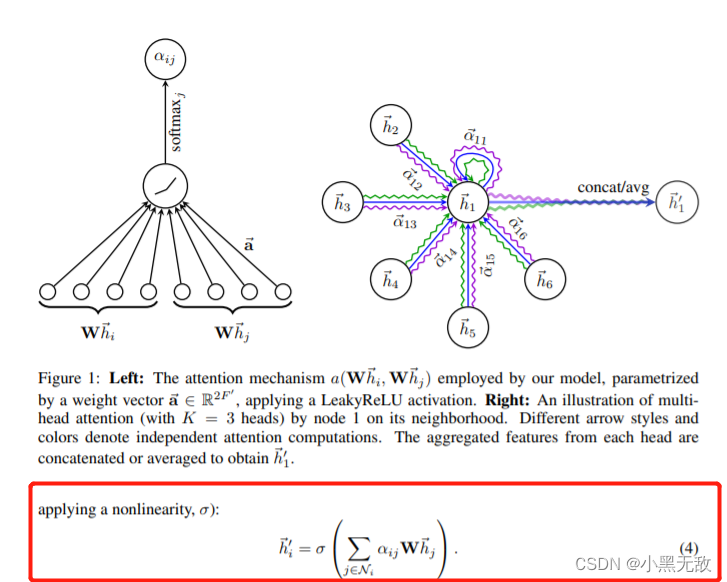
def _prepare_attentional_mechanism_input(self,Wh):
N = Wh.size()[0]
# Wh_repeated_in_chunks:[N * N,out_features]
# {e1 e1 ....e1},{e2,e2....e2}.....e3....en....
Wh_repeated_in_chunks = Wh.repeat_interleave(N,dim = 0)
# Wh_repeated_alternating:[N*N,out_features]
# {e1 e2 e3...en} ...{e1 e2 e3...en}.........
Wh_repeated_alternating = Wh.repeat(N,1)
# all_combinations_matrix:[N*N,2*out_features]
# {e1 || e1,e1 || e2 ....e1 || en}......en||en
all_combinations_matrix = torch.cat([Wh_repeated_in_chunks,Wh_repeated_alternating],dim = 1)
# [N,N,2*out_features]
return all_combinations_matrix.view(N,N,2*self.out_features)
# 小黑根据广播机制实现的与_prepare_attentional_mechanism_input作用一致的方法
def _pare2(self,Wh):
# Wh:[N,out_feature]
N = Wh.size()[0]
# W1:[1,N,out_feature]
W1 = Wh.unsqueeze(0).repeat(N,1,1)
# W2:[N,1,out_feature]
W2 = Wh.unsqueeze(1).repeat(1,N,1)
all_combinations_matrix = torch.cat([W2,W1],dim = -1)
return all_combinations_matrix
def forward(self,h,adj):
# h:[N,in_feature]
# adj:[N,N]
# W_h:[N,out_feature]
Wh = torch.mm(h,self.W)
# a_input:[N,N,2 * out_features]
a_input = self._prepare_attentional_mechanism_input(Wh)
# e:[N,N]
e = self.leakyrelu(torch.matmul(a_input,self.a).squeeze(2))
# zero_vec:[N,N]
zero_vec = -9e15 * torch.ones_like(e)
# attention:[N,N]
attention = torch.where(adj > 0,e,zero_vec)
attention = F.softmax(attention,dim = 1)
attention = F.dropout(attention,self.dropout,training = self.training)
# h_prime:[N,out_feature]
h_prime = torch.matmul(attention,Wh)
if self.concat:
return F.elu(h_prime)
else:
return h_prime
def __repr__(self):
return self.__class__.__name__ + ' (' + str(self.in_features) + ' -> ' + str(self.out_features) + ')'
np.random.seed(args.seed)
torch.manual_seed(args.seed)
#gal = GraphAttentionLayer(1433,200,0,0.2)
#gal.eval()
#print(gal(features,adj).shape)
#test_Wh = torch.mm(features,gal.W)
#a = gal._pare2(test_Wh)
#b = gal._prepare_attentional_mechanism_input(test_Wh)
# 看看小黑的_pare2方法与_prepare_attentional_mechanism_input方法是否输出一致
#print(a==b)
GAT整体模型
多头注意力合并:
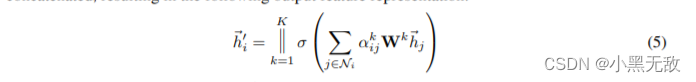
class GAT(nn.Module):
def __init__(self,nfeat,nhid,nclass,dropout,alpha,nheads):
super(GAT,self).__init__()
self.dropout = dropout
# 输入到隐藏层
self.attentions = [GraphAttentionLayer(nfeat,nhid,dropout = dropout,alpha = alpha,concat = True) for _ in range(nheads)]
for i,attention in enumerate(self.attentions):
self.add_module('attention_{}'.format(i),attention)
self.out_att = GraphAttentionLayer(nhid * nheads,nclass,dropout = dropout,alpha = alpha,concat = False)
def forward(self,x,adj):
# x:[N,num_features]
x = F.dropout(x,self.dropout,training = self.training)
# 多头attention计算与拼接
# x:[N,out_feature * nheads]
x = torch.cat([att(x,adj) for att in self.attentions],dim = 1)
x = F.dropout(x,self.dropout,training = self.training)
# x:[N,nclass]
x = F.elu(self.out_att(x,adj))
return F.log_softmax(x,dim = 1)
#adj = torch.ones([8,8])
#x = torch.randn([8,10])
#model = GAT(10,8,4,0.1,0.5,8)
#model(x,adj).shape
4.模型训练
# adj:对称max邻接矩阵
# features:样本特征
# labels:样本标签
# idx_train:训练集索引列表
# idx_val:验证集索引列表
# idx_test:测试集索引列表
adj,features,labels,idx_train,idx_val,idx_test = load_data()
# Model and optimizer
# 模型和优化器
# GAT模型
# nfeat输入单元数,shape[1]表示特征矩阵的维度数(列数)
# nhid中间层的单元数量
# nclass输出单元数
# dropout参数
# nheads多头注意力数量
model = GAT(
nfeat = features.shape[1],
nhid = args.hidden,
nclass = int(labels.max()) + 1,
dropout = args.dropout,
nheads = args.nb_heads,
alpha = args.alpha
)
optimizer = optim.Adam(
model.parameters(),
lr = args.lr,
weight_decay = args.weight_decay
)
if args.cuda:
model.cuda()
features = features.cuda()
adj = adj.cuda()
labels = labels.cuda()
idx_train = idx_train.cuda()
idx_val = idx_val.cuda()
idx_test = idx_test.cuda()
features,adj,labels = Variable(features),Variable(adj),Variable(labels)
def accuracy(output,labels):
preds = output.max(1)[1].type_as(labels)
correct = preds.eq(labels).double()
correct = correct.sum()
return correct / len(labels)
def train(epoch):
# 返回当前时间
t = time.time()
model.train()
# 梯度清零
optimizer.zero_grad()
# 前向传播
output = model(features,adj)
# 损失函数
loss_train = F.nll_loss(output[idx_train],labels[idx_train])
# 准确率
acc_train = accuracy(output[idx_train],labels[idx_train])
# 反向传播
loss_train.backward()
# 更新参数
optimizer.step()
if not args.fastmode:
model.eval()
output = model(features,adj)
loss_val = F.nll_loss(output[idx_val],labels[idx_val])
# 准确率
acc_val = accuracy(output[idx_val],labels[idx_val])
print('Epoch:{:04d}'.format(epoch+1),
'loss_train:{:.4f}'.format(loss_train.data.item()),
'acc_train:{:.4f}'.format(acc_train.data.item()),
'loss_val:{:.4f}'.format(loss_val.data.item()),
'acc_val:{:.4f}'.format(acc_val.data.item()),
'time:{:.4f}s'.format(time.time() - t)
)
return loss_val.data.item()
t_total = time.time()
loss_values = []
bad_counter = 0
best = args.epochs + 1
best_epoch = 0
# epoch数
for epoch in range(args.epochs):
# 训练
loss_values.append(train(epoch))
if loss_values[-1] < best:
best = loss_values[-1]
best_epoch = epoch
bad_counter = 0
else:
bad_counter += 1
if bad_counter == args.patience:
break
输出:
Epoch:0001 loss_train:1.9473 acc_train:0.1786 loss_val:1.8979 acc_val:0.4433 time:10.4272s
Epoch:0002 loss_train:1.8933 acc_train:0.2857 loss_val:1.8609 acc_val:0.5000 time:10.3096s















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









