







paper:https://arxiv.org/pdf/1503.02531.pdf
CSDN:https://blog.csdn.net/xbinworld/article/details/83063726 https://blog.csdn.net/weixin_41761357/article/details/113719963
知乎:https://zhuanlan.zhihu.com/p/127036442
PPT:https://qdata.github.io/deep-learning-undergrad-reading-group/notes/week15-distilling-the-knowledge-in-a-neural-network-ivey.pdf
知识蒸馏(Knowledge Distilling)是模型压缩的一种方法,
是指利用已经训练的一个较复杂的Teacher模型,指导一个较轻量的Student模型训练,
从而在减小模型大小和计算资源的同时,尽量保持原Teacher模型的准确率的方法。
1、动机
Knowledge Distill是一种简单弥补分类问题监督信号不足的办法。
传统的分类问题,模型的目标是将输入的特征映射到输出空间的一个点上,例如在著名的Imagenet比赛中,就是要将所有可能的输入图片映射到输出空间的1000个点上。
这么做的话这1000个点中的每一个点是一个one hot编码的类别信息。这样一个label能提供的监督信息只有log(class)这么多bit。
然而在KD中,我们可以使用teacher model对于每个样本输出一个连续的label分布,这样可以利用的监督信息就远比one hot的多了。
另外一个角度的理解,大家可以想象如果只有label这样的一个目标的话,那么这个模型的目标就是把训练样本中每一类的样本强制映射到同一个点上,这样其实对于训练很有帮助的类内variance和类间distance就损失掉了。
然而使用teacher model的输出可以恢复出这方面的信息。
具体的举例就像是paper中讲的, 猫和狗的距离比猫和桌子要近,同时如果一个动物确实长得像猫又像狗,那么它是可以给两类都提供监督。
综上所述,KD的核心思想在于”打散”原来压缩到了一个点的监督信息,让student模型的输出尽量match teacher模型的输出分布。
其实要达到这个目标其实不一定使用teacher model,在数据标注或者采集的时候本身保留的不确定信息也可以帮助模型的训练。
2、方法


使用soft targets将复杂模型的泛化能力迁移到小模型中。
原因有二,一是软化的标签有很高的熵,每个训练阶段提供更多的信息。二是训练阶段之间梯度方差更小,训练更加稳定。这样的好处是要求训练的数据更少,可以使用更高的学习率。
作者对softmax进行改造,引入温度系数
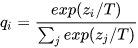
通常 是为1的,当使用更高的温度时,会得到类间更加软化的概率分布。
训练过程中,作者说直接使用两个不同的目标函数加权的方式更好。
令大模型logits 经过有温度的softmax输出
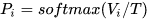
,小模型logits 经过有温度softmax输出
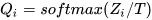
其中两个的温度要一致。
最终
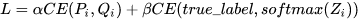
作者说第二个目标函数权重小时通常结果更好,但要注意soft targets的梯度量级乘以了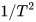
,所以在二者同时使用时,第一个目标函数梯度要乘以 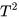
保证贡献基本一致。















 18万+
18万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









