







提示:能力有限,有误之处,还请指出!
文章目录
前言
数据结构:Array(数组),ArrayList(动态数组),List(泛型列表),LinkedList(双向链表),Queue(队列),Stack(栈),Dictionary<K,T>(字典),Hashtable(哈希表)、二叉树(binary tree)
一、Array(数组)
长度固定,需要在初始化时指定长度。
遍历速度快,增加删除元素慢,即增删慢,改差快。
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
public class Test : MonoBehaviour
{
// Start is called before the first frame update
void Start()
{
//1.声明大小
int[] Array01 = new int[3];
//赋值
Array01[0] = 0;
Array01[1] = 1;
Array01[2] = 2;
//打印查看
for (int i = 0; i < Array01.Length; i++)
{
Debug.Log("Array01=" + Array01[i]);
}
//2.声明并赋值
string[] str01 = new string[] {"A","B"};
//3.多维数组
int[,] str02 = new int[2, 2];
str02[0, 0] = 1;
str02[0, 1] = 2;
str02[1, 0] = 3;
str02[1, 1] = 4;
int a = str02[0, 0];
//打印结果:a=1
Debug.Log("a="+a );
}
}
二、ArrayList(动态数组)
ArrayList类相当于一种高级的动态数组,它是Array类的升级版本。
可以使用索引在指定的位置添加和移除项目,动态数组会自动重新调整它的大小。它也允许在列表中进行动态内存分配、增加、搜索、排序各项。
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
public class Test : MonoBehaviour
{
// Start is called before the first frame update
void Start()
{
ArrayList arrayList01 = new ArrayList();
//添加值
arrayList01.Add("A");
arrayList01.Add(1);
//Insert()方法用来将元素插入ArrayList集合的指定索引处
arrayList01.Insert(1, "B");//在ArrayList对象索引值=1处添加元素"B"
//删除ArrayList对象指定元素
arrayList01.Remove("A");
//RemoveAt()方法用来移除ArrayList的指定索引处的元素
arrayList01.RemoveAt(0);
for (int i = 0; i < arrayList01.Count; i++)
{
Debug.Log(arrayList01[i]);
}
//移除所有元素
arrayList01.Clear();
}
}
三、List(泛型列表)
List泛型集合是C#编程中的经常使用的集合之一,相对数组它可以动态的添加元素而不是声明的时候就必须指定大小。相对于ArrayList集合和Hashtable集合的优势是其元素的数据类型可以确定。而不是默认的父类类型object。
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
public class Test : MonoBehaviour
{
// Start is called before the first frame update
void Start()
{
//用法一
ArrayList arrayList01 = new ArrayList();
for (int i = 0; i < 10; i++)
{
arrayList01.Add(i);
}
ArrayList arrayList02 = new ArrayList();
arrayList02.Add("A");
arrayList02.Add("B");
arrayList02.Add("C");
List<ArrayList> Liat01 = new List<ArrayList>();
Liat01.Add(arrayList01);
Liat01.Add(arrayList02);
//打印
for (int i = 0; i < Liat01.Count; i++)
{
for (int j = 0; j < Liat01[i].Count; j++)
{
Debug.Log(Liat01[i][j]);
}
}
//创建Person对象
Person p1 = new Person();
p1.Name = "张三";
p1.Age = 18;
//创建类型为Person的对象集合
List<Person> persons = new List<Person>();
//将Person对象放入集合
persons.Add(p1);
Debug.Log(persons[0].Name);
}
}
class Person
{
public string Name;
public int Age;
}
四、Queue(队列)
代表一个先进先出的对象集合,队列只能在一端进行插入操作,在另一端进行删除操作,队列是通过地址指针进行遍历的,只能从头或者从尾开始遍历,但不能同时开始遍历,无需开辟临时空间
1.添加元素
使用 Enqueue 方法
Queue qu = new Queue();
qu.Enqueue(1);
qu.Enqueue("w");
qu.Enqueue(2);
2.取出元素
取出元素后,元素会自动从 Queue 中删除
Queue qu = new Queue();
qu.Enqueue(1);
qu.Enqueue("w");
qu.Enqueue(2);
var str= qu.Dequeue();
Debug.Log(str);
3.读取元素
读取最先添加的一个元素,读取后,元素不会从 Queue 中删除,但是只能读取一个元素
Queue qu = new Queue();
qu.Enqueue(1);
qu.Enqueue("w");
qu.Enqueue(2);
var str02= qu.Peek();
Debug.Log(str02);
Debug.Log(qu.Count);
4.剩余方法和其他集合差不多
//Contains 来判断元素是否存在
queue.Contains (“w”);
//清空队列
queue.Clear();
//foreach 和for 循环遍历
Queue qu = new Queue();
qu.Enqueue(1);
qu.Enqueue("w");
qu.Enqueue(2);
foreach (var item in qu)
{
Debug.Log(item);
}
for (int i = 0; i < qu.Count; i++)
{
Debug.Log(qu.ToArray()[i]);
}
五、Stack(栈)
非常适合用于UI返回逻辑:链接: unity UI 多个次级界面返回逻辑 (新加悔步骤)
堆栈(Stack)代表了一个后进先出的对象集合。
当需要对各项进行后进先出的访问时,则使用堆栈。
当在列表中添加一项,称为推入元素,
增加对象时要压入(push)
当从列表中移除一项时,称为弹出元素。
删除对象时要弹出(pop)
Stack 类的方法和属性
Count,代表了Stack中的元素个数
Clear(),清除所有Stack中的元素
Contains(Obj),判断obj(代表元素)是否存在于stack中
Peek(),返回在 Stack 的顶部的对象,但不移除它
Pop(),移除并返回在 Stack 的顶部的对象
Push( obj ),向 Stack 的顶部添加一个对象
ToArray(),复制所有的stack元素到一个数组中
六、LinkedList(双向链表)
数组需要一块连续的内存空间来存储,对内存的要求比较高。链表并不需要一块连续的内存空间,通过“指针”将一组零散的内存块串联起来使用。链表的节点可以动态分配内存,使得链表的大小可以根据需要动态变化,而不受固定的内存大小的限制。特别是在需要频繁的插入和删除操作时,链表相比于数组具有更好的性能。最常见的链表结构分别是:单链表、双向链表和循环链表。
LinkedList是一个C#为我们封装好的类,它的本质是可变类型的泛型双向链表。
链表对象需要掌握两个类,一个是链表本身,一个是链表节点类LinkedListNode
LinkedList<int> linkedList = new LinkedList<int>();
//1.在链表尾部添加元素
linkedList.AddLast(10);
//2.在链表头部添加元素
linkedList.AddFirst(20);
//3.在某一个节点之后添加一个节点,要指定节点先得到一个节点
LinkedListNode<int> n = linkedList.Find(20);
linkedList.AddAfter(n, 15);
//4.在某一个节点之前添加一个节点,要指定节点先得到一个节点
linkedList.AddBefore(n, 11);
//5.移除头节点
linkedList.RemoveFirst();
//6.移除尾节点
linkedList.RemoveLast();
//7.移除指定节点
linkedList.Remove(20);
//8.清空
linkedList.Clear();
//9.查头节点
LinkedListNode<int> first = linkedList.First;
//10.查尾节点
LinkedListNode<int> last = linkedList.Last;
实现一个链表:
源地址: C#数据结构学习笔记——链表
写的很好,大家可以去看看。
using System;
using System.Collections.Generic;
using System.Text;
namespace LinkedList
{
class LinkedList1<E>//泛型链表类
{
private class Node//结点内部类
{
public E e;//存储的元素e
public Node next;//当前结点的下一个结点
public Node(E e,Node next)//构造函数初始化
{
this.e = e;
this.next = next;
}
public Node(E e)//没有下一结点的构造
{
this.e = e;
this.next = null;
}
public override string ToString()//打印
{
return e.ToString();
}
}
private Node head;//链表头部
private int N;//存储的元素个数
public LinkedList1()//构造函数
{
head = null;
N = 0;
}
public int Count//属性:链表元素个数
{
get { return N; }
}
public bool IsEmpty//属性:是否空
{
get { return N == 0; }
}
public void Add(int index,E e)//插入结点
{
if (index < 0 || index > N)
throw new ArgumentException("非法索引");
if (index == 0)//往头部插入结点
{
Node node = new Node(e);//创建新结点
node.next = head;//新结点next指向头结点
head = node;//更新头结点
//head = new Node(e, head); 这里复用了之前写的public Node(E e,Node next)构造方法,等同于上面三行代码一样
}
else//往中间或尾部插入
{
Node pre = head;//临时结点pre
for (int i = 0; i < index-1; i++)//找到要插入的索引位置的结点的前一个结点
pre = pre.next;
Node node = new Node(e);//创建新结点
node.next = pre.next;//新结点指向临时结点下一结点
pre.next = node;//更新临时结点下一结点指向新结点
//pre.next = new Node(e, pre.next);同理等同于上面三句代码
}
N++;//链表元素个数更新
}
public void AddFirst(E e)//头部插入
{
Add(0, e);
}
public void AddLast(E e)//尾部插入
{
Add(N, e);
}
public E Get(int index)//查询结点
{
if (index < 0 || index >= N)
throw new ArgumentException("非法索引");
Node cur = head;//临时变量结点cur指向结点head
for (int i = 0; i < index; i++)//找到对应索引结点
cur = cur.next;
return cur.e;
}
public E GetFirst()
{
return Get(0);
}
public E GetLast()
{
return Get(N - 1);
}
public void Set(int index,E newE)//修改结点元素
{
if (index < 0 || index >= N)
throw new ArgumentException("非法索引");
Node cur = head;//临时变量结点cur指向结点head
for (int i = 0; i < index; i++)//找到对应索引结点
cur = cur.next;
cur.e = newE;
}
public bool Contains(E e)//判断包含
{
Node cur = head;
while (cur != null)
{
if (cur.e.Equals(e))//如果结点与元素相同返回true
return true;
cur = cur.next;
}
return false;
}
public E RemoveAt(int index)//删除
{
if (index < 0 || index >= N)
throw new ArgumentException("非法索引");
if (index == 0)//删除头结点
{
Node delNode = head;//delNode指向head结点
head = head.next;//更新头结点
N--;
return delNode.e;//返回被删除的结点元素
}
else
{
Node pre = head;
for (int i = 0; i < index - 1; i++)//找到删除索引结点的前一个结点
pre = pre.next;
Node delNode = pre.next;//delNode指向pre结点的下一个结点
pre.next = delNode.next;//pre下一个结点指向delNode的下一个结点
N--;
return delNode.e;
}
}
public E RemoveFirst()
{
return RemoveAt(0);
}
public E RemoveLast()
{
return RemoveAt(N - 1);
}
public void Remove(E e)
{
if (head == null)//头结点空,说明链表没有结点
return;
if (head.e.Equals(e))//删除的元素是头结点
{
head = head.next;
N--;
}
else
{
Node cur = head;
Node pre = null;
while (cur != null)//查找要删除的元素的结点
{
if (cur.e.Equals(e))//找到元素退出循环
{
pre.next = cur.next; //pre下一结点指向cur的下一结点
break;
}
pre = cur;
cur = cur.next;
}
//if (cur != null)
//{
// pre.next = pre.next.next;//pre下一结点指向cur的下一结点
// N--;
//}
}
}
public override string ToString()//打印
{
StringBuilder res = new StringBuilder();
Node cur = head;
while (cur != null)
{
res.Append(cur + "->");
cur = cur.next;
}
res.Append("Null");
return res.ToString();
}
}
}
调用
using System;
namespace LinkedList
{
class Program
{
static void Main(string[] args)
{
LinkedList1<int> l = new LinkedList1<int>();//创建链表
for (int i = 0; i < 5; i++)
{
l.AddFirst(i);//头部插入
Console.WriteLine(l);
}
l.AddLast(60);//尾部插入
Console.WriteLine("尾部插入");
Console.WriteLine(l);
l.Add(2, 99);
Console.WriteLine("索引2位置插入99结点");
Console.WriteLine(l);
l.Set(1, 100);
Console.WriteLine("修改索引1位置的结点元素");
Console.WriteLine(l);
l.RemoveAt(2);
Console.WriteLine("删除索引2位置的结点");
Console.WriteLine(l);
l.RemoveFirst();
Console.WriteLine("删除头结点");
Console.WriteLine(l);
l.RemoveLast();
Console.WriteLine("删除尾部结点");
Console.WriteLine(l);
l.Remove(0);
Console.WriteLine("删除结点0");
Console.WriteLine(l);
Console.Read();
}
}
}
常用场景:摘链接: 深度解析C#中LinkedList<T>的存储结构
文章开头介绍了链表的基础特性,基于链表的基础特性来展开分析C#的LinkedList结构,重点说明了LinkedList的元素插入、查询、移除和存储对象。链表在实际的应用中比较广泛,尤其是在缓存的处理方面。缓存是一种提高数据读取性能的技术,在硬件设计、软件开发中都有着非常广泛的应用,比如常见的 CPU 缓存、数据库缓存、浏览器缓存等等。缓存的大小有限,当缓存被用满时,哪些数据应该被清理出去,哪些数据应该被保留?这就需要缓存淘汰策略来决定。常见的策略有三种:先进先出策略 FIFO(First In,FirstOut)、最少使用策略 LFU(Least Frequently Used)、最近最少使用策略 LRU(LeastRecently Used)。
这里我们以简单实现方式说明一下LRU缓存的实现逻辑。
1、 如果此数据之前已经被缓存在链表中了,则遍历得到这个数据对应的结点,并将其从原来的位置删除,然后再插入到链表的头部。
2.、如果此数据没有在缓存链表中,则分为两种情况:
(1)、如果此时缓存未满,则将此结点直接插入到链表的头部;
(2)、如果此时缓存已满,则链表尾结点删除,将新的数据结点插入链表的头部。
对于链表的基础应用场景中如:单链表反转;链表中环的检测;有序的链表合并等较为常用的算法。
以上内容是对C#中LinkedList的存储结构的简单介绍,如错漏的地方,还望指正。
七、二叉树(binary tree)
在 C# 中,二叉树是一种常见的数据结构,它由节点组成,每个节点最多有两个子节点:左子节点和右子节点。
在 C# 中,可以使用类来实现二叉树的节点,并且通过引用连接节点来构建整棵树。
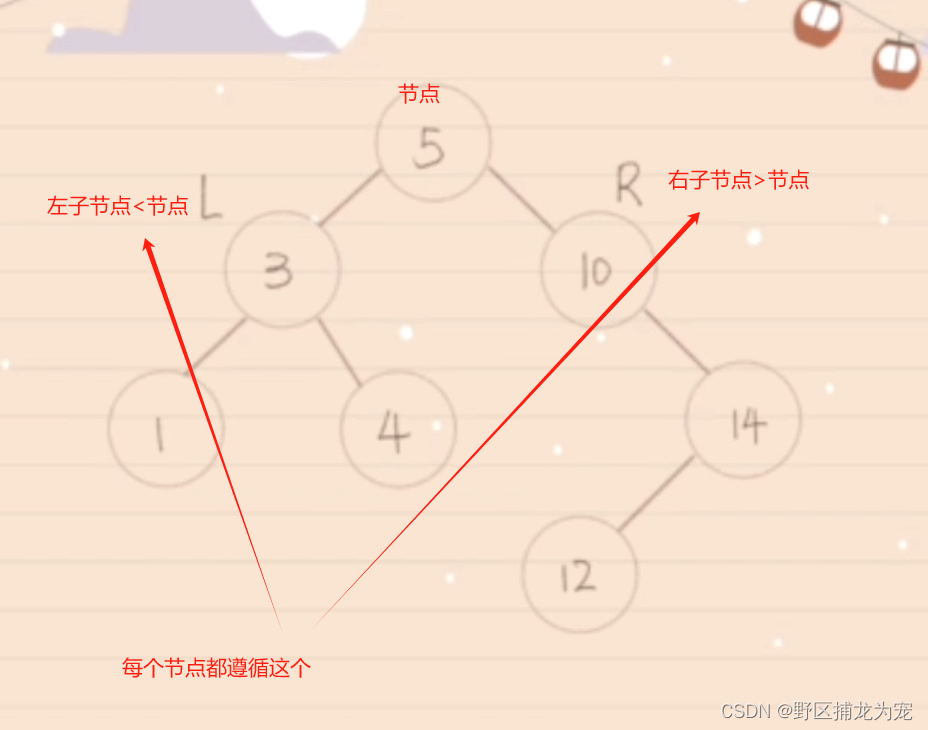
1.先(根)序遍历的递归算法定义:
若二叉树非空,则依次执行如下操作:
⑴ 访问根结点;
⑵ 遍历左子树;
⑶ 遍历右子树。
2.中(根)序遍历的递归算法定义:
若二叉树非空,则依次执行如下操作:
⑴遍历左子树;
⑵访问根结点;
⑶遍历右子树。
3.后(根)序遍历得递归算法定义:
若二叉树非空,则依次执行如下操作:
⑴遍历左子树;
⑵遍历右子树;
⑶访问根结点。
using System;
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
public class Test : MonoBehaviour
{
// Start is called before the first frame update
void Start()
{
BinaryTree tree = new BinaryTree();
tree.Insert(45);
tree.Insert(33);
tree.Insert(21);
tree.Insert(45);
tree.Insert(76);
tree.Insert(62);
tree.Insert(89);
//tree.PreOrderTraveral(tree.root);
// tree.InOrderTraveral(tree.root);
tree.PostOrderTraveral(tree.root);
}
}
/// <summary>
/// 链表节点
/// </summary>
/// <typeparam name="T"></typeparam>
class BdNode<T>
{
public T Data { get; set; }
public BdNode<T> Next { get; set; }
public BdNode<T> Prev { get; set; }
public BdNode(T data, BdNode<T> next, BdNode<T> prev)
{
Data = data;
Next = next;
Prev = prev;
}
}
class TreeNode
{
public int data;
public TreeNode left;
public TreeNode right;
public TreeNode(int value)
{
data = value;
left = null;
right = null;
}
}
class BinaryTree
{
public TreeNode root;
public BinaryTree()
{
root = null;
}
public void Insert(int value)
{
root = InsertRec(root, value);
}
private TreeNode InsertRec(TreeNode root, int value)
{
if (root == null)
{
root = new TreeNode(value);
return root;
}
if (value < root.data)
{
root.left = InsertRec(root.left, value);
}
else if (value > root.data)
{
root.right = InsertRec(root.right, value);
}
return root;
}
/// <summary>
/// 前序遍历
/// </summary>
public void PreOrderTraveral(TreeNode node)
{
if (node == null)
{
return;
}
Debug.Log(node.data);
PreOrderTraveral(node.left);
PreOrderTraveral(node.right);
}
/// <summary>
/// 中序遍历
/// </summary>
public void InOrderTraveral(TreeNode node)
{
if (node == null)
{
return;
}
InOrderTraveral(node.left);
Debug.Log(node.data);
InOrderTraveral(node.right);
}
/// <summary>
/// 后序遍历
/// </summary>
public void PostOrderTraveral(TreeNode node)
{
if (node == null)
{
return;
}
PostOrderTraveral(node.left);
PostOrderTraveral(node.right);
Debug.Log(node.data);
}
}
在这个示例中,我们定义了一个 TreeNode 类来表示二叉树的节点,以及一个 BinaryTree 类来表示整个二叉树。我们可以使用 Insert 方法向二叉树中插入新的节点,并使用 InOrderTraversal 方法进行中序遍历。
这是一个简单的二叉树示例,实际上,二叉树还有许多其他操作,比如删除节点、搜索节点等,可以根据实际需求来实现。
八、Hashtable(哈希表)
Hashtable 键值对集合,对键和值的类型没有要求;在键值对集合中,是根据键去找值的;键值对对象[键]=值;
注意:键值对集合中,键必须是唯一的,而值是可以重复的
实现方式:
using System;
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
public class Test : MonoBehaviour
{
// Start is called before the first frame update
void Start()
{
Hashtable hashtable = new Hashtable(); //创建了一个键值对集合对象,
hashtable.Add("张三", "男");
hashtable.Add("李四", "女");
foreach (var item in hashtable.Keys)
{
Debug.Log("姓名:"+ item+" 性别:"+ hashtable[item]);
}
var a = hashtable["张三"];
Debug.Log(a);//打印结果:男
}
}
总结
好记性不如烂笔头!
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











