







YOLO
1.YOLOv1

1)论文的思想
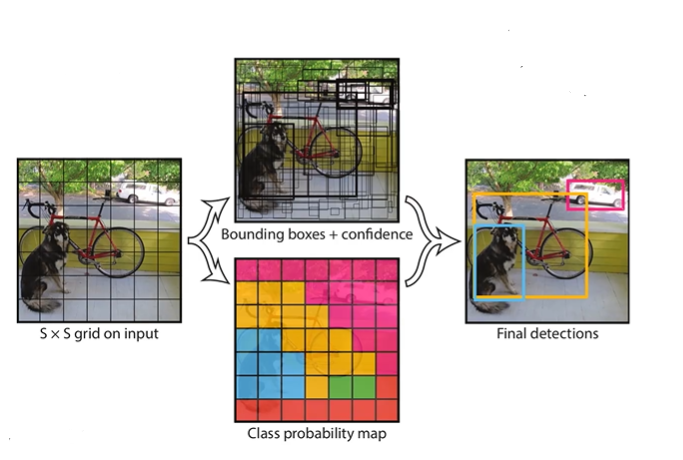
- 将一副图片分为s*s个网格(grid cell),如果某个object的中心就落在这个网格中,则该网格就负责预测这个object。
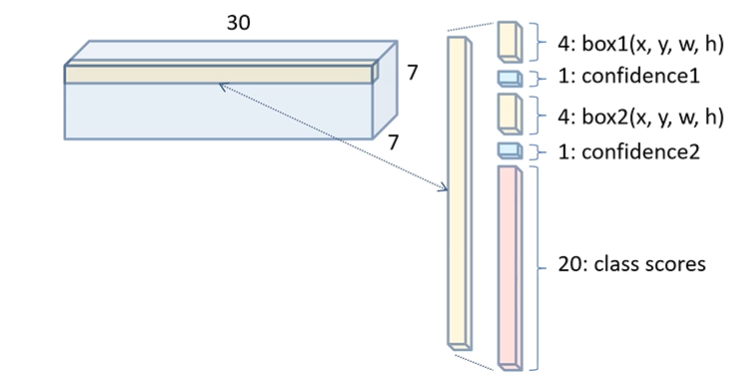
- 每个网格要预测B个bounding box,每个bounding box除了要预测位置之外,还要附带预测一个confidence值。每个网格还要预测C个类别的分数。下面是将图片分为7*7的网格,每个网格预测2个bounding box的情况。x,y是目标中心的位置;w,h是一个相对图片的相对值,取值[0,1]。下方的公式为预测类别分数的公式。
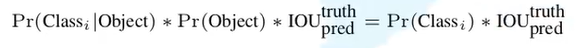
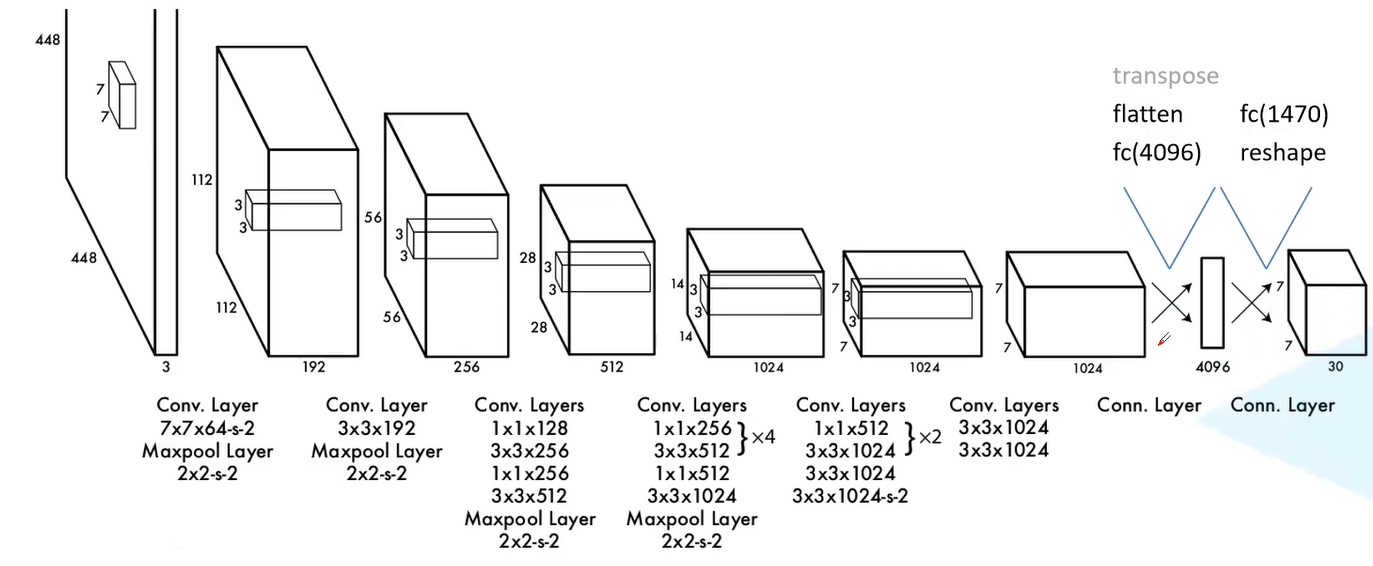
2)网络结构
3)损失函数

损失函数分为3个部分:bbox损失,confidence损失以及classes损失。作者主要使用误差平方和计算。
在宽高的处理上没有直接使用误差平方,而是开根后的误差平方,是因为小目标在偏离相同距离的情况下,IOU下降要比大目标快的多,开根后的计算能够满足上述的情况。
confidence损失中上半部分为正样本的损失,其中c_hat=1;下半部分为负样本的损失,其中c_hat=0。
4)存在的问题
- 对群体的小目标检测效果很差,因为YOLOv1每个cell只预测两个边界框,并且属于同一类别。
- 目标出现新的尺寸配置时效果很差。
- 主要误差是来自定位不准确。
2.YOLOv2

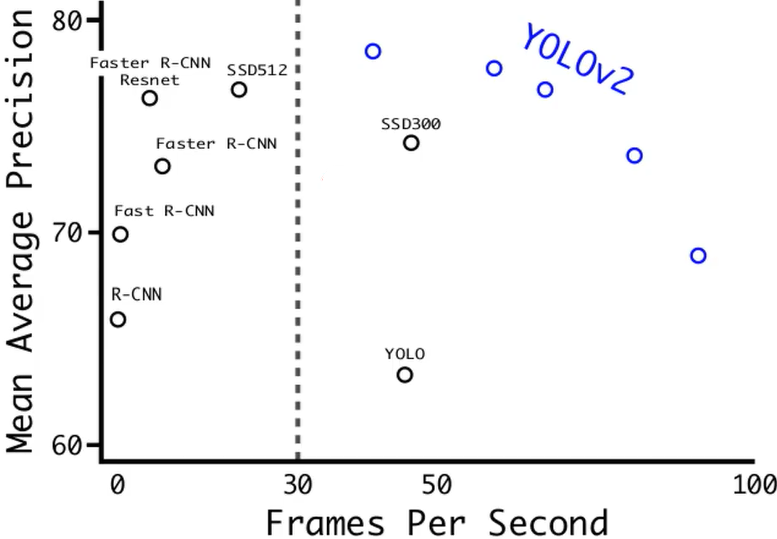
1)优化尝试
上图为YOLOv2与其他算法的对比,相对于v1版本,有很大的提升,下面是作者用到的一些优化尝试。
- Batch Normalization(批归一化)
尽管梯度下降法训练神经网络很简单高效,但是需要人为地去选择参数,比如学习率,参数初始化,权重衰减系数,Dropout比例等,而且这些参数的选择对于训练结果至关重要,以至于我们很多时间都浪费到这些调参上。BN算法的强大之处在下面几个方面:
- 可以选择较大的学习率,使得训练速度增长很快,具有快速收敛性。
- 可以不去理会Dropout,L2正则项参数的选择,如果选择使用BN,甚至可以去掉这两项。
- 去掉局部响应归一化层。(AlexNet中使用的方法,BN层出来之后这个就不再用了)
- 可以把训练数据打乱,防止每批训练的时候,某一个样本被经常挑选到。
- High Resolution classifier(高分辨率预训练)
在Yolov1中,网络的backbone部分会在ImageNet数据集上进行预训练,训练时网络输入图像的分辨率为224*224。在v2中,将分类网络在输入图片分辨率为448*448的ImageNet数据集上训练10个epoch,再使用检测数据集(例如coco)进行微调。高分辨率预训练使mAP提高了大约4%。
- Convolutional With Anchor Boxes
在Yolov1中,每个格点预测两个矩形框,在计算loss时,只让与ground truth最接近的框产生loss数值,而另一个框不做修正。这样规定之后,作者发现两个框在物体的大小、长宽比、类别上逐渐有了分工。**在v2中,神经网络不对预测矩形框的宽高的绝对值进行预测,而是预测与Anchor框的偏差(offset),每个格点指定n个Anchor框。**在训练时,最接近ground truth的框产生loss,其余框不产生loss。在引入Anchor Box操作后,mAP由69.5下降至69.2,原因在于,每个格点预测的物体变多之后,召回率大幅上升,准确率有所下降,总体mAP略有下降。
- Dimension Clusters(Anchor Box的宽高由聚类产生)
Faster R-CNN中的九个Anchor Box的宽高是事先设定好的比例大小,一共设定三个面积大小的矩形框,每个矩形框有三个宽高比:1:1,2:1,1:2,总共九个框。而在v2中,Anchor Box的宽高不经过人为获得,而是将训练数据集中的矩形框全部拿出来,用k-means聚类得到先验框的宽和高。例如使用5个Anchor Box,那么k-means聚类的类别中心个数设置为5。加入了聚类操作之后,引入Anchor Box之后,mAP上升。
需要强调的是,聚类必须要定义聚类点(矩形框 ( ω , h ) (\omega,h) (ω,h))之间的距离函数,使用(1-IOU)数值作为两个矩形框的的距离函数,文中使用如下函数:
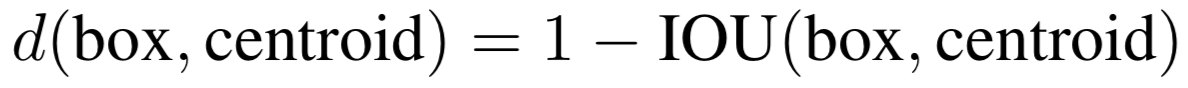
- Direct location prediction(绝对位置预测)
Yolo在模型训练过程中会出现不稳定的情况,其主要原因是由于预测中心位置不准确,通过借鉴Faster R-CNN中的预测框的 x , y x,y x,y位置预测方法: x = ( t x ∗ ω a ) + x a ; y = ( t y ∗ h a ) + y a x=(t_x * \omega_a)+x_a;y=(t_y * h_a)+y_a x=(tx∗ωa)+xa;y=(ty∗ha)+ya直接使用的话会使坐标可能不在该预测区域内。
Yolov2中使用以下公式进行中心位置的调整,将最终结果限制在预测区域内,公式中的
t
x
,
t
y
t_x,t_y
tx,ty为预测的anchor的偏移量,使用sigmoid函数进行约束。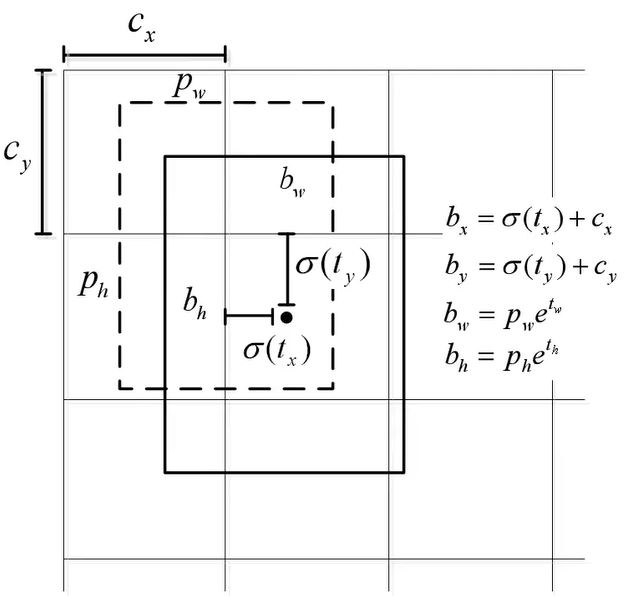
- Fine-Grained Features(细粒度特征)
在26*26的特征图,经过卷积层等,变为13*13的特征图后,作者认为损失了很多细粒度的特征,导致小尺寸物体的识别效果不佳,所以在此加入了passthrough层。passthrough层就是将26*26*1的特征图,变成13*13*4的特征图,在这一次操作中不损失细粒度特征。下面是4*4*1的特征图变为2*2*4的特征图的例子。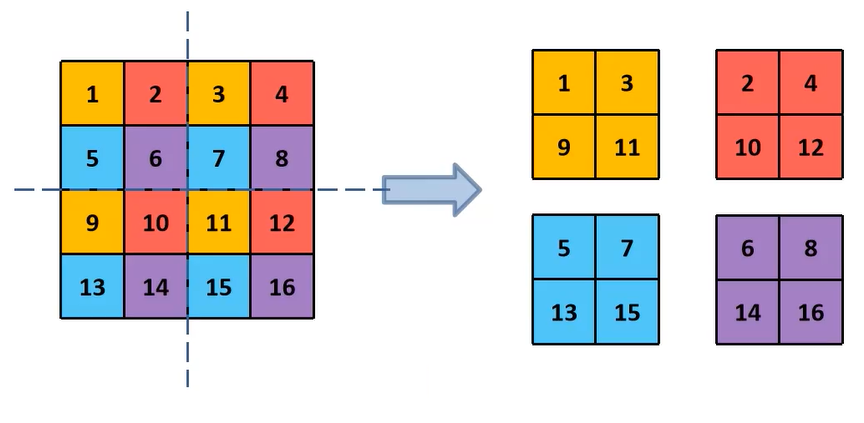
- Multi-Scale Training(多尺寸训练)
Yolo v2中只有卷积层与池化层,所以对于网络的输入大小,并没有限制,整个网络的降采样倍数为32,只要输入的特征图尺寸为32的倍数即可,如果网络中有全连接层,就不是这样了。所以Yolo v2可以使用不同尺寸的输入图片训练。
· 作者使用的训练方法是,在每10个batch之后,就将图片resize成{320, 352, …, 608}中的一种。不同的输入,最后产生的格点数不同,比如,输入图片是320*320,那么输出格点是10*10,如果每个格点的先验框个数设置为5,那么总共输出500个预测结果;如果输入图片大小是608*608,输出格点就是19*19,共1805个预测结果。
在引入了多尺寸训练方法后,迫使卷积核学习不同比例大小尺寸的特征。当输入设置为544*544甚至更大,Yolo v2的mAP已经超过了其他的物体检测算法。
2)网络结构
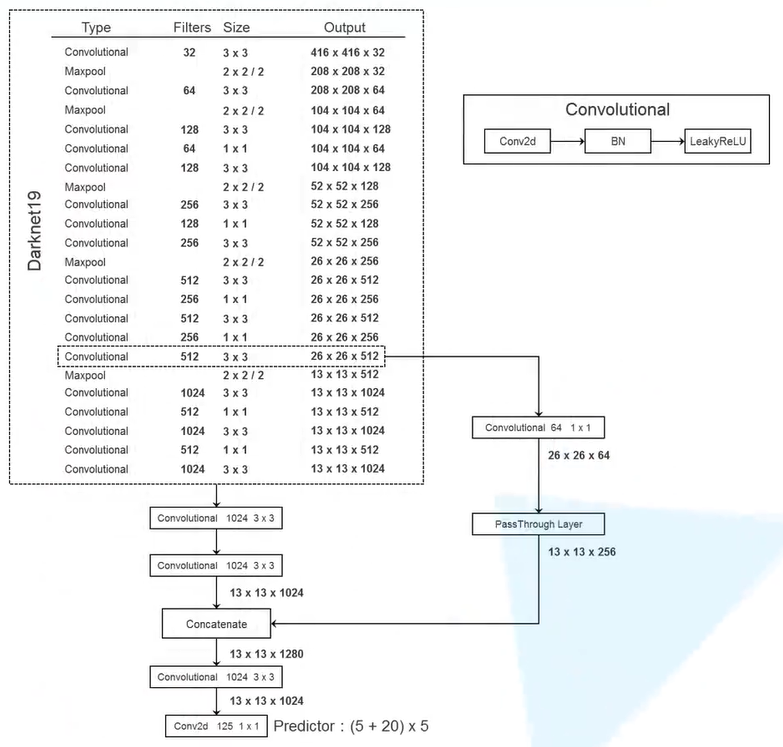
3.YOLOv3

1)优化改进
相对于YOLOv2,v3版本的改动在于主干网络用Darknet53替换了Darknet19,其中的最大池化层全部使用卷积层代替并引入了残差结构,具体部分如下。
- Yolov3中,只有卷积层,通过调节卷积步长控制输出特征图的尺寸。所以对于输入图片尺寸没有特别限制。流程图中,输入图片以256*256作为样例。
- Yolov3借鉴了金字塔特征图思想,小尺寸特征图用于检测大尺寸物体,而大尺寸特征图检测小尺寸物体。特征图的输出维度为 N ∗ N ∗ [ 3 ∗ ( 4 + 1 + 80 ) ] N*N*[3*(4+1+80)] N∗N∗[3∗(4+1+80)] , N ∗ N N*N N∗N为输出特征图格点数,一共3个Anchor框,每个框有4维预测框数值 t x , t y , t ω , t h t_x,t_y,t_\omega,t_h tx,ty,tω,th,1维预测框置信度,80维物体类别数。所以第一层特征图的输出维度为 8 ∗ 8 ∗ 255 8*8*255 8∗8∗255。
- Yolov3总共输出3个特征图,第一个特征图下采样32倍,第二个特征图下采样16倍,第三个下采样8倍。输入图像经过Darknet-53(无全连接层),再经过Yoloblock生成的特征图被当作两用,第一用为经过3*3卷积层、1*1卷积之后生成特征图一,第二用为经过1*1卷积层加上采样层,与Darnet-53网络的中间层输出结果进行拼接,产生特征图二。同样的循环之后产生特征图三。
- concat操作与加和操作的区别:加和操作来源于ResNet思想,将输入的特征图,与输出特征图对应维度进行相加,即 y = f ( x ) + x y=f(x)+x y=f(x)+x;而concat操作源于DenseNet网络的设计思路,将特征图按照通道维度直接进行拼接,例如8*8*16的特征图与8*8*16的特征图拼接后生成8*8*32的特征图。
- 上采样层(upsample):作用是将小尺寸特征图通过插值等方法,生成大尺寸图像。例如使用最近邻插值算法,将8*8的图像变换为16*16。上采样层不改变特征图的通道数。
Yolo的整个网络,吸取了Resnet、Densenet、FPN的精髓,可以说是融合了目标检测当前业界最有效的全部技巧。
2)损失函数

损失主要分为三部分,置信度损失,分类损失和定位损失。
- 置信度损失
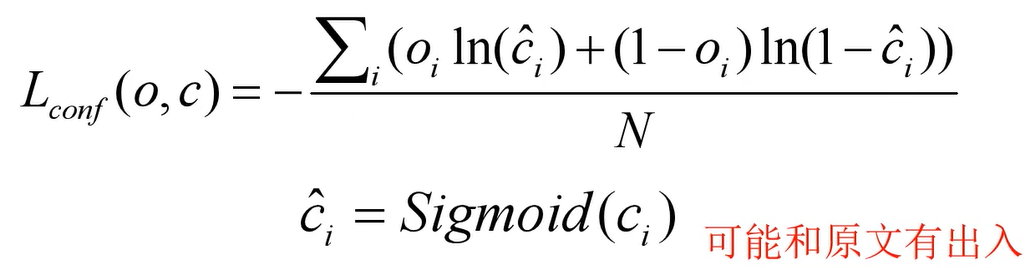
使用的计算公式为二值交叉熵损失计算公式,其中** o i o_i oi表示目标边界框与真实目标边界框的IOU(论文中写置信度非0即1,在SPP版本中为IOU值), c c c为预测值, c i h a t c_i hat cihat为 c c c通过sigmoid函数得到的预测置信度, N N N为正负样本个数**。
- 分类损失

- 定位损失
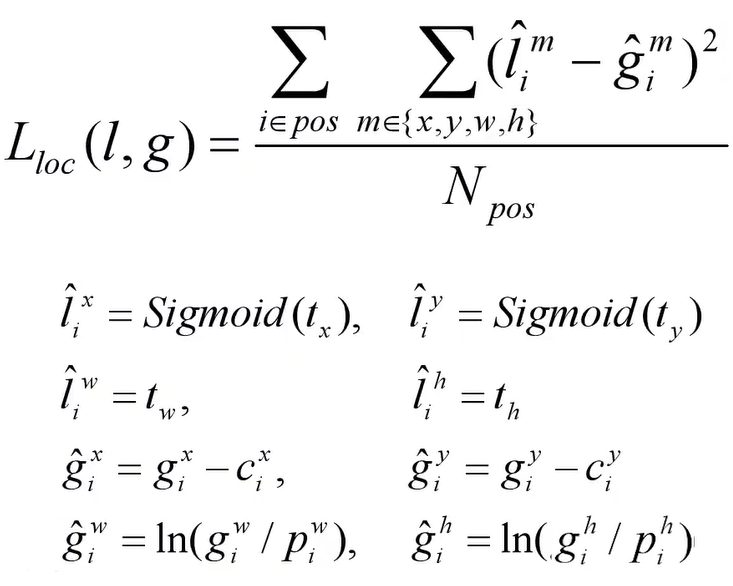
其中l为预测的边界框参数,g为真实的边界框参数, g x g^x gx, g y g^y gy, g ω g^\omega gω, g h g^h gh为真实框的中心坐标位置及大小参数, c x c^x cx, c y c^y cy为该预测区域的左上角坐标, p ω p^\omega pω, p h p^h ph为先验框的大小参数。
3)正负样本选取
预测框一共分为三种情况:正例(positive)、负例(negative)、忽略样例(ignore)。
-
正例:任取一个ground truth,与4032个框全部计算IOU,IOU最大的预测框,即为正例。并且一个预测框,只能分配给一个ground truth。例如第一个ground truth已经匹配了一个正例检测框,那么下一个ground truth,就在余下的4031个检测框中,寻找IOU最大的检测框作为正例。ground truth的先后顺序可忽略。正例产生置信度loss、检测框loss、类别loss。预测框为对应的ground truth box标签(使用真实的 x , y , w , h x,y,w,h x,y,w,h计算出 t x , t y , t ω , t h t_x,t_y,t_\omega,t_h tx,ty,tω,th);类别标签对应类别为1,其余为0;置信度标签为1。
-
忽略样例:正例除外,与任意一个ground truth的IOU大于阈值(论文中使用0.5),则为忽略样例。忽略样例不产生任何loss。
-
**负例:**正例除外(与ground truth计算后IOU最大的检测框,但是IOU小于阈值,仍为正例),与全部ground truth的IOU都小于阈值(0.5),则为负例。负例只有置信度产生loss,置信度标签为0。
4)v3 加强版

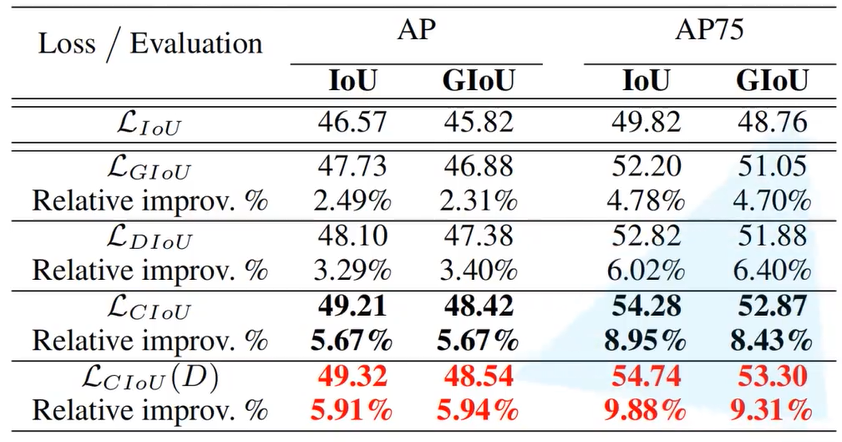
在上面的表格可以看出SSP-U版的准确度有大幅度的上升,其中在v3
基础上的改进有以下几个方面:Mosaic图像增强,SPP模块,CIOU Loss,Focal loss。
- Mosaic图像增强
将多张图片拼接在一起,源码中默认使用四张拼接,增加了样本的多样性,增加了检测目标个数,使用BN层时使得能够更贴近数据集的均值和方差。
- SPP模块
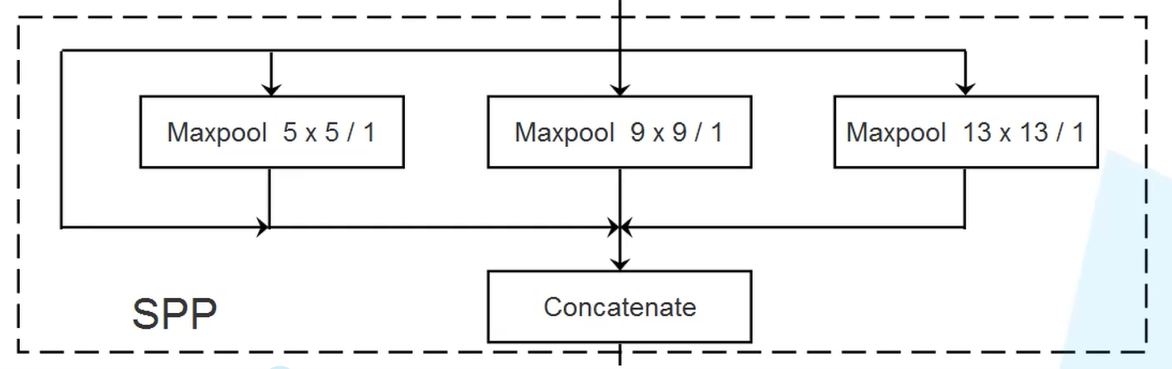
实现了不同尺度的特征融合,在后面的网络结构中只有第一个预测特征层接了SPP结构,剩余两个也可以接,会有所提升,但没有必要。
- CIOU Loss
- IOU: 两 个 框 的 交 集 两 个 框 的 并 集 , [ 0 , 1 ] \frac {两个框的交集}{两个框的并集},[0,1] 两个框的并集两个框的交集,[0,1],故不相交时值都为0
- GIOU: I O U − ( A c − u A c ) , [ − 1 , 1 ] IOU-(\frac {A^c-u} {A^c}),[-1,1] IOU−(AcAc−u),[−1,1],其中 A c A^c Ac为能框住两个框最小框的面积, u u u为两个框的并集的面积,这样就能判断在不相交时的损失。
- DIOU:GIOU收敛速度慢,当两框重合时不能继续判断。DIOU解决了这一问题,对比如下图:
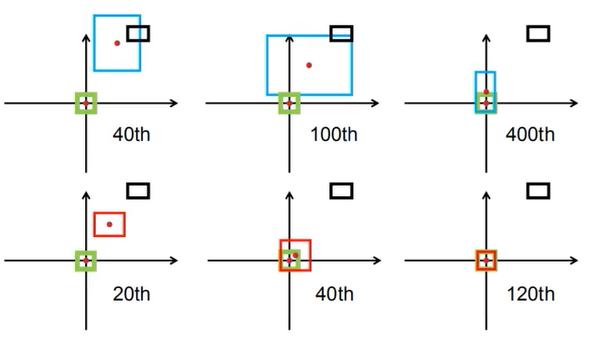
下面是计算公式,因为能够直接计算两个边界框的距离,故能更快的收敛。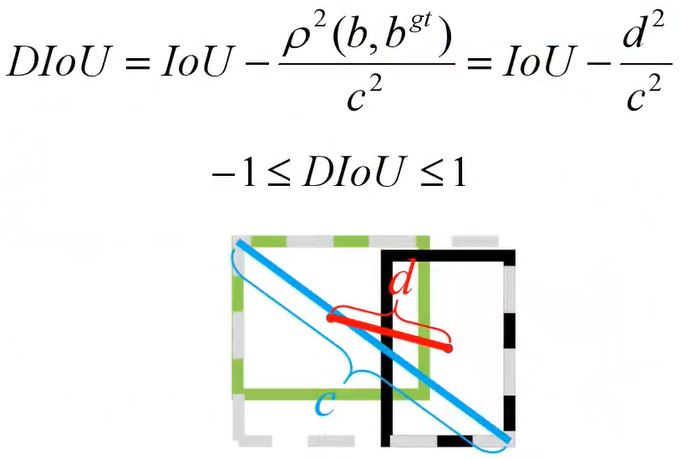
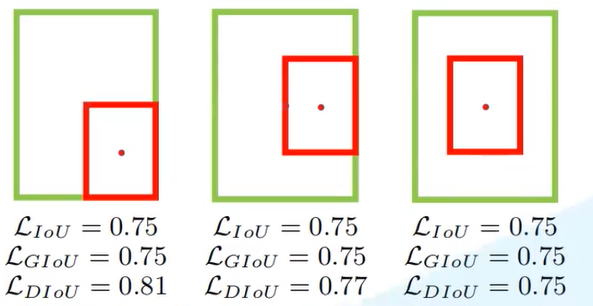
- CIOU:作者在文章中指出,一个优秀的回归定位损失应该包含三种几何参数:重叠面积,中心点距离,长宽比,据此提出CIOU计算公式:(其中IOU可更换为GIOU)
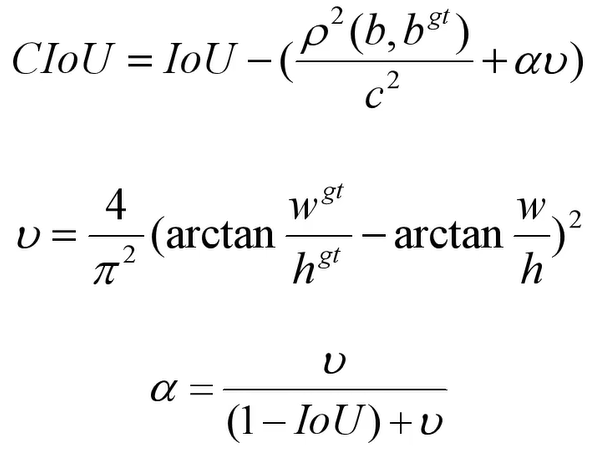
对于以上几种方式定义损失函数为1-损失的形式,对比效果如下,可以看出CIOU的提升相对于IOU很大。
- Focal loss
能够更好的区分难以分解的样本,但在使用过程中对噪声的抗干扰能力较差,故训练集必须标注的准确才能有好的效果。
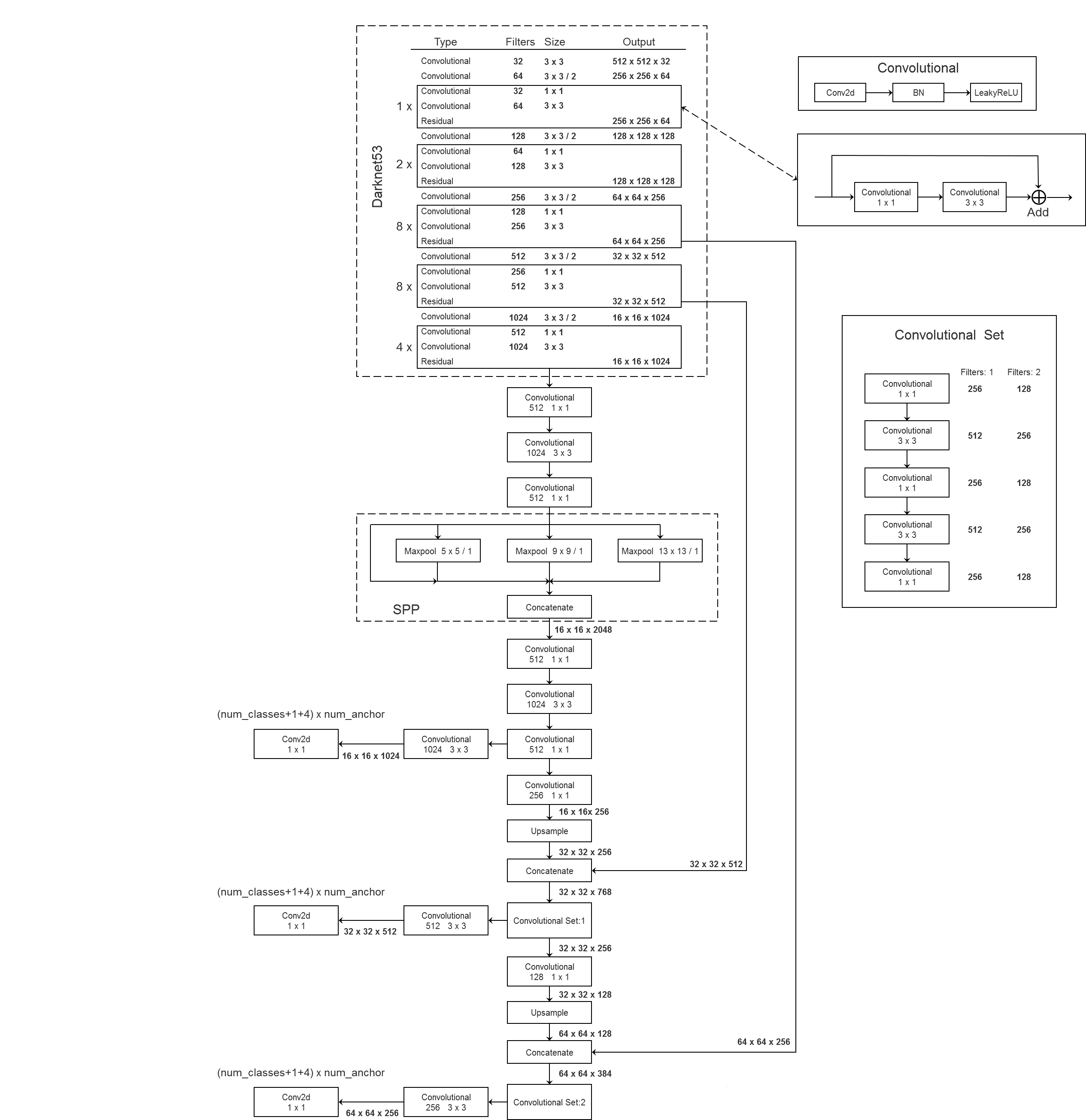
5)最终网络结构















 2997
2997











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









