







张量
- 张量模态
- Khatri-Rao积(KR积)
- numpy.trace(a, offset=0, axis1=0, axis2=1, dtype=None, out=None)
- np.linalg.norm(求范数)
- RuntimeWarning: invalid value encountered in double_scalars
- A = np.column_stack((x_vals_column, ones_column))
- flatten()函数用法
- set() 函数
- np.arange函数的使用
- numpy.astype() 转换数据类型
- np.tile
- sum(axis=1)
- Numpy tolist() 用法
- np.c_的用法
- np.argmax
- 查准率(Precision) 、召回率(Recall)与F1分数、准确率(Accuracy) | 查准率(Precision) | 查全率(Recall)
- Recall(召回率) Precision(准确率) F-Measure E值 sensitivity(灵敏性) specificity(特异性)漏诊率 误诊率 ROC AUC
- numpy.around()函数
- python csv.reader() 与 pd.read_csv()的区别
- sp.linalg.solve_sylvester
- numpy.diagflat(a,k = 0):
- iloc和loc
- pickle.dump
- numpy.nanstd()函数
- np.ascontiguousarray
- mean() 函数:
- np.tanh
- 优化器keras.optimizers.Adam()详解
- models.Sequential
- keras.callbacks.EarlyStopping
- predict()方法
- 卷积神经网络
- enumerate
张量模态

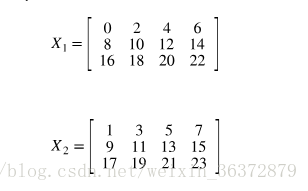
import numpy as np
import tensorly as tl
X = tl.tensor(np.arange(24).reshape(3, 4, 2))
张量矩阵化(Matricization)输出张量的三个矩阵模态
print(tl.unfold(X, mode=0)) #1模展开
print(tl.unfold(X, mode=1))
print(tl.unfold(X, mode=2))

同时使用fold函数可以将矩阵转变为对应模态的张量
unfolding = tl.unfold(X, 1)
original_shape = X.shape
tl.fold(unfolding, mode=1, shape=original_sha
Khatri-Rao积(KR积)

输入:A,B两个矩阵,要求两矩阵列数一致
输出:维度为(A行数B行数)列数的矩阵。
计算过程:A,B矩阵相同列做kron积运算,并逐列摆放组成结果矩阵。
举例:
A=[1 2;3 4],B=[5 6;7 8]
其中AB均为22的矩阵,得到(22)2=42的矩阵。
第一列:用A的第一列和B的第一列做kron积运算
[15=5
17=7
35=15
37=21]
第二列:用A的第二列和B的第二列做kron积运算
[26=12
28=16
46=24
48=32]
最终结果:
[5 12
7 16
15 24
21 32]
Matlab代码:
for k=1:K %K为输入矩阵的列数
C(:,k)=kron(A(:,k),B(:,k));
end
numpy.trace(a, offset=0, axis1=0, axis2=1, dtype=None, out=None)
返回沿数组对角线的和。
np.linalg.norm(求范数)
(1)np.linalg.inv():矩阵求逆
(2)np.linalg.det():矩阵求行列式(标量)
x_norm=np.linalg.norm(x, ord=None, axis=None, keepdims=False)
①x: 表示矩阵(也可以是一维)
②ord:范数类型
向量的范数:

矩阵的范数:
ord=1:列和的最大值
ord=2:|λE-ATA|=0,求特征值,然后求最大特征值得算术平方根(matlab在线版,计算ans=ATA,[x,y]=eig(ans),sqrt(y),x是特征向量,y是特征值)
ord=∞:行和的最大值
ord=None:默认情况下,是求整体的矩阵元素平方和,再开根号。(没仔细看,以为默认情况下就是矩阵的二范数,修正一下,默认情况下是求整个矩阵元素平方和再开根号)
③axis:处理类型
axis=1表示按行向量处理,求多个行向量的范数
axis=0表示按列向量处理,求多个列向量的范数
axis=None表示矩阵范数。
④keepding:是否保持矩阵的二维特性
True表示保持矩阵的二维特性,False相反
代码实现
x = np.array([
[0, 3, 4],
[1, 6, 4]])
#默认参数ord=None,axis=None,keepdims=False
print "默认参数(矩阵整体元素平方和开根号,不保留矩阵二维特性):",np.linalg.norm(x)
print "矩阵整体元素平方和开根号,保留矩阵二维特性:",np.linalg.norm(x,keepdims=True)
print "矩阵每个行向量求向量的2范数:",np.linalg.norm(x,axis=1,keepdims=True)
print "矩阵每个列向量求向量的2范数:",np.linalg.norm(x,axis=0,keepdims=True)
print "矩阵1范数:",np.linalg.norm(x,ord=1,keepdims=True)
print "矩阵2范数:",np.linalg.norm(x,ord=2,keepdims=True)
print "矩阵∞范数:",np.linalg.norm(x,ord=np.inf,keepdims=True)
print "矩阵每个行向量求向量的1范数:",np.linalg.norm(x,ord=1,axis=1,keepdims=True)
结果:

RuntimeWarning: invalid value encountered in double_scalars
-
这是个警告提示(warning),而不是错误(Error)。所以在代码运行时出现这个提示时,代码仍然可以正常运行。但同时因为他不是错误,所以使用try-except是捕获不了异常的。
-
出现这个提示一般是因为出现了0/0导致的。但是出现分母为0的情况时,没有触发ZeroDivisionError(0除异常),这一点也很意外。
-
解决方法:使用if-else语句判断当分母为0时重新给id_col赋值。
下面来简单看看ZeroDivisionError异常和RuntimeWarning警告之间的区别,以及在何种情况下会触发这两类提示。 -
当分母0的数据类型为内置数据类型时,可以触发ZeroDivisionError异常

-
当分母0为numpy中的数据类型时,触发RuntimeWarning警告。

-
当内置数据类型和numpy数据类型计算时,其计算结果的类型为numpy中的计算类型。

A = np.column_stack((x_vals_column, ones_column))
将2个矩阵按列合并
b = np.row_stack((x_vals_column, ones_column))
将2个矩阵按行合并
flatten()函数用法
flatten是numpy.ndarray.flatten的一个函数,即返回一个一维数组。
flatten只能适用于numpy对象,即array或者mat,普通的list列表不适用!。
a.flatten():a是个数组,a.flatten()就是把a降到一维,默认是按行的方向降 。
a.flatten().A:a是个矩阵,降维后还是个矩阵,矩阵.A(等效于矩阵.getA())变成了数组。
>>> a=mat([[1,2,3],[4,5,6]])
>>> a
matrix([[1, 2, 3],
[4, 5, 6]])
>>> a.flatten()
matrix([[1, 2, 3, 4, 5, 6]])
>>> y=a.flatten().A
>>> shape(y)
(1L, 6L)
>>> shape(y[0])
(6L,)
>>> a.flatten().A[0]
array([1, 2, 3, 4, 5, 6])
>>>
set() 函数
set() 函数创建一个无序不重复元素集,可进行关系测试,删除重复数据,还可以计算交集、差集、并集等。

np.arange函数的使用
返回值: np.arange()函数返回一个序列
参数: 有三种情况
1.只有一个参数的时候,默认从0开始到输入的参数,产生序列,步进为默认的1
2.有两个参数的时候,序列中的元素从第一个参数到第二个参数的区间产生,步进为默认的1
3.有三个参数的时候,序列中的元素从第一个参数到第二个参数的区间产生,步进为第三个参数
numpy.astype() 转换数据类型
arr.astype(int32) 将arr(array数组)转化为int32类型
int32 --> float64 完全ojbk
float64 --> int32 会将小数部分截断
string_ --> float64 如果字符串数组表示的全是数字,也可以用astype转化为数值类型
np.tile
b = tile(a,(m,n)):即是把a数组里面的元素复制n次放进一个数组c中,然后再把数组c复制m次放进一个数组b中
sum(axis=1)
默认axis为None,表示将所有元素的值相加
对于二维数组
axis=1表示按行相加 , axis=0表示按列相加
Numpy tolist() 用法
将矩阵(matrix)和数组(array)转化为列表。

np.c_的用法
用于连接两个矩阵,np.c 中的c 是 column(列)的缩写,就是按列叠加两个矩阵,就是把两个矩阵左右组合,要求行数相等。

np.argmax
numpy.argmax(array, axis) 用于返回一个numpy数组中最大值的索引值。当一组中同时出现几个最大值时,返回第一个最大值的索引值。
查准率(Precision) 、召回率(Recall)与F1分数、准确率(Accuracy) | 查准率(Precision) | 查全率(Recall)
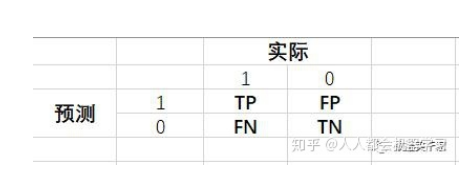






Recall(召回率) Precision(准确率) F-Measure E值 sensitivity(灵敏性) specificity(特异性)漏诊率 误诊率 ROC AUC










numpy.around()函数
函数原型:numpy.around(a, decimals=0, out=None)
参数解析:
a为输入列表或矩阵;
decimals为n对输入近似后保留小数点后n位,默认为0,若值为-n,则对小数点左边第n位近似;
out为可选参数,一般不用,用于保存近似返回结果。
python csv.reader() 与 pd.read_csv()的区别
csv.reader()
返回一个reader对象,该对象将遍历csv文件中的行。从csv文件中读取的每一行都作为字符串列表返回。
import pandas as pd
r = []
with open('train.csv',encoding = 'utf-8') as text:
row = csv.reader(text, delimiter = ',')
for r in row:
print(r)
['姓名', '数学', '语文', '英语']
['小王', '54', '76', '87']
['小李', '32', '34', '69']
['小刚', '78', '28', '77']
#输出的是一行行列表
pd.read_csv()
data = pd.read_csv('train.csv',encoding='utf-8')
print(data)
姓名 数学 语文 英语
0 小王 54 76 87
1 小李 32 34 69
2 小刚 78 28 77
sp.linalg.solve_sylvester


numpy.diagflat(a,k = 0):
创建一个二维数组,其数组输入作为新输出数组的对角线。

iloc和loc
loc函数:通过行索引 “Index” 中的具体值来取行数据(如取"Index"为"A"的行)
iloc函数:通过行号来取行数据(如取第二行的数据)
pickle.dump
pickle.dumps()将对象obj对象序列化并返回一个byte对象
pickle.dump(obj, file)
pickle.dump() 直接把对象序列化后,将对象obj保存到文件file(这里的file是文件句柄) 中去。
import pickle
dict1 = dict(name='八岐大蛇',
age=1000,
sex='男',
addr='东方',
enemy=['八神', '草薙京', '神乐千鹤'])
# print(dict1)
data_dumps = pickle.dumps(dict1)
print(data_dumps)#b'\x80\x03}q\x00(X\x04\x00\x00\x00nameq\x01X\x0c\x00\x00\x00\xe5\x85\xab\xe5\xb2\x90\xe5\xa4\xa7\xe8\x9b\x87q\x02X\x03\x00\x00\x00ageq\x03M\xe8\x03X\x03\x00\x00\x00sexq\x04X\x03\x00\x00\x00\xe7\x94\xb7q\x05X\x04\x00\x00\x00addrq\x06X\x06\x00\x00\x00\xe4\xb8\x9c\xe6\x96\xb9q\x07X\x05\x00\x00\x00enemyq\x08]q\t(X\x06\x00\x00\x00\xe5\x85\xab\xe7\xa5\x9eq\nX\t\x00\x00\x00\xe8\x8d\x89\xe8\x96\x99\xe4\xba\xacq\x0bX\x0c\x00\x00\x00\xe7\xa5\x9e\xe4\xb9\x90\xe5\x8d\x83\xe9\xb9\xa4q\x0ceu.'
print(type(data_dumps)) # <class 'bytes'>
data=pickle.loads(data_dumps )#从字节对象中读取被封装的对象,并返回
print(data)#{'name': '八岐大蛇', 'age': 1000, 'sex': '男', 'addr': '东方', 'enemy': ['八神', '草薙京', '神乐千鹤']}
numpy.nanstd()函数
计算沿指定轴的标准偏差,而忽略NaN。返回非NaN数组元素的标准偏差,即分布分布的度量。默认情况下,将为展平数组计算标准偏差,否则将在指定轴上计算。
用法: numpy.nanstd(arr, axis = None, dtype = None, out = None, ddof = 0, keepdims)
参数:
arr:[数组]计算非NaN值的标准偏差。
axis:[{int,int的元组,None},可选]沿其计算标准偏差的轴。
dtype:[dtype,可选]用于计算标准偏差的类型。对于整数类型的数组,默认值为float64,对于浮点类型的数组,其与数组类型相同。
out:[ndarray,可选]放置结果的备用输出数组。
ddof:[int,可选] ddof表示Delta自由度。计算中使用的除数为N-ddof,其中N表示非NaN元素的数量。默认情况下,ddof为零。
keepdims:[布尔,可选]如果将其设置为True,则缩小的轴将保留为尺寸为1的尺寸。使用此选项,结果将针对原始arr正确广播。
返回:[standard_deviation]如果out为None,则返回包含标准偏差的新数组,否则返回对输出数组的引用。
np.ascontiguousarray




mean() 函数:
numpy.mean(a, axis, dtype, out,keepdims )
mean()函数功能:求取均值
经常操作的参数为axis,以m * n矩阵举例:
axis 不设置值,对 mn 个数求均值,返回一个实数
axis = 0:压缩行,对各列求均值,返回 1 n 矩阵
axis =1 :压缩列,对各行求均值,返回 m *1 矩阵
np.tanh
此函数用于计算作为参数传递的数组的所有元素的双曲正切。
参数
array:要计算切线值(以弧度为单位)的数组元素。
out:输出数组的形状。
返回
返回具有三角正切正弦的数组。
优化器keras.optimizers.Adam()详解
在监督学习中我们使用梯度下降法时,学习率是一个很重要的指标,因为学习率决定了学习进程的快慢(也可以看作步幅的大小)。如果学习率过大,很可能会越过最优值,反而如果学习率过小,优化的效率可能很低,导致过长的运算时间,所以学习率对于算法性能的表现十分重要。而优化器keras.optimizers.Adam()是解决这个问题的一个方案。其大概的思想是开始的学习率设置为一个较大的值,然后根据次数的增多,动态的减小学习率,以实现效率和效果的兼得。
keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.99, epsilon=1e-08, decay=0.0)
lr:float> = 0.学习率
beta_1:float,0 <beta <1。一般接近1。一阶矩估计的指数衰减率
beta_2:float,0 <beta <1。一般接近1。二阶矩估计的指数衰减率
epsilon:float> = 0,模糊因子。如果None,默认为K.epsilon()。该参数是非常小的数,其为了防止在实现中除以零
decay:float> = 0,每次更新时学习率下降
models.Sequential
sequential model就是那种最简单的结构的模型。按顺序一层一层训练,一层一层往前的那种。没有什么环的结构。比如像前馈网络那样。
就像下图这样的,一层层的那种。
Sequential 模型结构: 层(layers)的线性堆栈。简单来说,它是一个简单的线性结构,没有多余分支,是多个网络层的堆叠。

参考博文
首先了解Keras的一个很好的途径就是通过 文档
Keras 中文文档地址: https://keras.io/zh/models/about-keras-models/





fit(x=None, y=None, batch_size=None, epochs=1, verbose=1, callbacks=None, validation_split=0.0, validation_data=None, shuffle=True, class_weight=None, sample_weight=None, initial_epoch=0, steps_per_epoch=None, validation_steps=None, validation_freq=1)

x:输入数据。如果模型只有一个输入,那么x的类型是numpy
array,如果模型有多个输入,那么x的类型应当为list,list的元素是对应于各个输入的numpy array
y:标签,numpy array
batch_size:整数,指定进行梯度下降时每个batch包含的样本数。训练时一个batch的样本会被计算一次梯度下降,使目标函数优化一步。
epochs:整数,训练终止时的epoch值,训练将在达到该epoch值时停止,当没有设置initial_epoch时,它就是训练的总轮数,否则训练的总轮数为epochs - inital_epoch
verbose:日志显示,0为不在标准输出流输出日志信息,1为输出进度条记录,2为每个epoch输出一行记录
callbacks:list,其中的元素是keras.callbacks.Callback的对象。这个list中的回调函数将会在训练过程中的适当时机被调用,参考回调函数
validation_split:0~1之间的浮点数,用来指定训练集的一定比例数据作为验证集。验证集将不参与训练,并在每个epoch结束后测试的模型的指标,如损失函数、精确度等。注意,validation_split的划分在shuffle之前,因此如果你的数据本身是有序的,需要先手工打乱再指定validation_split,否则可能会出现验证集样本不均匀。
validation_data:形式为(X,y)的tuple,是指定的验证集。此参数将覆盖validation_spilt。
shuffle:布尔值或字符串,一般为布尔值,表示是否在训练过程中随机打乱输入样本的顺序。若为字符串“batch”,则是用来处理HDF5数据的特殊情况,它将在batch内部将数据打乱。
class_weight:字典,将不同的类别映射为不同的权值,该参数用来在训练过程中调整损失函数(只能用于训练)
sample_weight:权值的numpy
array,用于在训练时调整损失函数(仅用于训练)。可以传递一个1D的与样本等长的向量用于对样本进行1对1的加权,或者在面对时序数据时,传递一个的形式为(samples,sequence_length)的矩阵来为每个时间步上的样本赋不同的权。这种情况下请确定在编译模型时添加了sample_weight_mode=’temporal’。
initial_epoch: 从该参数指定的epoch开始训练,在继续之前的训练时有用。
fit函数返回一个History的对象,其History.history属性记录了损失函数和其他指标的数值随epoch变化的情况,如果有验证集的话,也包含了验证集的这些指标变化情况
keras.callbacks.EarlyStopping


参数介绍:
monitor: 被监测的数据。
min_delta: 在被监测的数据中被认为是提升的最小变化, 例如,小于 min_delta 的绝对变化会被认为没有提升。
patience: 没有进步的训练轮数,在这之后训练就会被停止。
verbose: 详细信息模式。
mode: {auto, min, max} 其中之一。 在 min 模式中, 当被监测的数据停止下降,训练就会停止;在 max 模式中,当被监测的数据停止上升,训练就会停止;在 auto 模式中,方向会自动从被监测的数据的名字中判断出来。
baseline: 要监控的数量的基准值。 如果模型没有显示基准的改善,训练将停止。
restore_best_weights: 是否从具有监测数量的最佳值的时期恢复模型权重。 如果为 False,则使用在训练的最后一步获得的模型权重。
predict()方法
参考
当使用predict()方法进行预测时,返回值是数值,表示样本属于每一个类别的概率,我们可以使用numpy.argmax()方法找到样本以最大概率所属的类别作为样本的预测标签。下面以卷积神经网络中的图片分类为例说明,代码如下:
卷积神经网络
enumerate
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。














 657
657











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









