









如果只是简单看看条件随机场和最大熵模型的原理。我打赌绝大多数人没有意识到我下面提到的公式是这个意思。自己实现算法涉及到细节时稀里糊涂写出来,最近看到一个最大熵模型的实现想不通的时候,才慢慢想明白为什么这样写。
正文:
之前看条件随机场的时候计算特征函数模型期望是下面这样的公式:
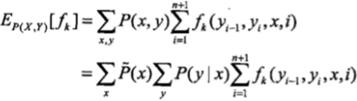
计算先验模型期望时看到这样的公式:
![]()
式子中有先验分布,实现算法时,p(x)和p(x,y)对于先验分布的遍历我一直很懵逼,到底这里的x和y是序列的遍历还是x概率分布或者x和y的概率分布的遍历。以至于之前我写的时候默认就写的对于序列的遍历。
但回想起概率论中求期望这个过程一定是在一个概率分布上进行的啊。
比如:
| A | X |
| 0 | 0.2 |
| 1 | 0.1 |
| 2 | 0.3 |
| 3 | 0.4 |
计算A在随机变量X上的期望,毫无疑问:
E = 0*0.2 + 1*0.1 + 2 * 0.3 + 3 * 0.4 = 1.9
所以一定要相信科学啊!!!上面的式子中也是这样的,只不过我们可以把这个过程在整个训练数据序列中进行。下面以最大熵模型中求特征函数期望为例来解释。
最大熵模型中,求特征函数模型期望公式如下:
![]()
求先验期望如下:
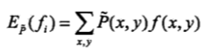
先说先验期望:
看下面一段代码:

这里empiricalE就是先验期望,i是遍历所有特征函数,featureCountList.get(i)指的是特征函数i在训练数据中出现的次数。InstanceList.size()是样本的总个数。注意到特征函数由一个x和y来决定。这里你可以看到,featureCountList.get(i) / instanceList.size()不就是求了一个p(x,y)的概率值吗?怎么就成了期望了?
再次想想上面说的求期望过程:
我们知道p(x,y)这个分布中x,y的值和特征函数中x0和y0的值(假设这个特征函数中的x和y是x0和y0)完全对应的只有一个。那就是p(x0,y0)而特征函数的值又为1,所以就是一个概率值p(x0,y0)了。
也就是说这个求期望的过程是这样的:
E = 1 * p(x0,y0) + 0 *p(x1,y1)+….
_再看看这个求先验期望的公式:
这里对x和y的遍历是再p(x,y)分布上,而非序列上进行的。
再来看看求模型期望的过程:

对照公式:
![]()
先解释一下,每个instance就是一个样本,而fieldList就是一个样本中的所有特征值,比如x1,x2,x3…
calProb就是计算公式中的p(y|x), Feature是特征函数,featureList是特征函数集合。
仔细看看,最外层的循环是整个序列的遍历,第2层是对一个样本中的特征数的遍历,这2层合起来就是对x的遍历,最内层的是对标签y的遍历。
这里的x是整个序列。最内层判断如果该特征函数存在就累加对应特征函数的期望值,看到里面的计算可能懵了,pro[k] * 1/instanceList.size(),先验概率p(x)跑哪里去了??
实际上这里的累加隐含了求先验概率p(x)。
假设某个x0的先验概率是1/5,这里只不过加了很多次,最后累积起来还是1/5。
还有值得注意的一点是:这里的p(y|x)中x是单个样本中的所有特征。我们这里求模型的期望依然是特征函数关于p(x,y)的期望。注意因为x是多维度,这里假设有2个维度,那么
P(x,y) = p(x1,x2,y) = p(x1,x2) * p(y|x1,x2),这里的p(x1.x2)就是先验概率了,求特征函数f(x,y)关于p(x1,x2,y)的期望,需要注意最大熵中,特征函数中的x是单个维度的,比如现在求的是f(x1=a,y=b)关于p(x1,x2,y)的期望。我们不关心先验p(x1,x2),只要这个样本的x1=a并且y=b,那么特征函数就为1,先验概率自然会被累积。我们能在分布先对x,y遍历吗,那样应该简单多了。当然不行,那样就变成先验分布,我们要的就是根据模型参数来计算期望。最后尽可能的优化到使模型期望和先验期望一样。
2019.8.8
补充解释:因为求模型期望并不能直接在p(x,y)上直接进行,那样就成了先验期望,所以必须在序列上完成求模型的期望,和求先验期望相比,我们并不能直接得到先验p(x=a),而是在序列中的哪些出现x=a的位置上去每次单个计算这个先验,比如序列长度为5,在位置1,4出现了a,就相当于每次出现a时累加一次1/5,那么共出现了2次,最后也会得到2/5,这个和先验期望中的p(x)概率是一样的.
对同一特征函数求期望,pro[k]中的k都是一样的,k是标签y,pro[k]是p(y|x),但是区别于样本又不太一样,因为p(y|x)计算的是p(y|x1,x2,x3...)。特征函数只关乎某个维度的x和一个标签y。这里举的例子只是好直白的解释,你也可以理解为每出现这样一个特征函数,对模型期望就贡献1/instanceList.size(),只是不能这么直白就说是相加,最后优化的目标是调整特征函数权重使得模型期望尽可能和先验期望一样。某个特征函数先验期望是2/5,那么模型期望就是1/5*a+1/5*b
感谢观看,觉得不错的话可以考虑支持下我,用我的AI大师码0415在滴滴云上购买GPU/vGPU/机器学习产品可享受9折优惠,点击www.didiyun.com前往滴滴云官网。















 481
481











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









