







今天在分析数据的时候遇到一个样本数据不平衡的问题,以前在学习机器学习的时候有学到样本数据不平衡的原因和解决方法,不过因为那时候并不在意,觉得数据多得是嘛,不平横就随机训练和丢弃一些就好了,根本没仔细考虑到数据量小的情况。
有时候数据量呈现8比2的比例,也就是正样本与负样本的数量比为8:2,这时候在做机器学习就需要考虑如何合理的训练与分配数据了,值得一提的是,样本不平衡的情况十分常见。
不过样本不平衡会带来什么问题呢,这也是今天想讲的一点故事,举个十分简单又实际的例子
假设有10个人 8个好人和2个坏人
如果存在一个机器学习模型,遇到人就说好人,那么模型的预测结果将会是 好人, 好人, ......
利用准确率的计算方式 ACC = 8个好人预测正确/总共有10个人 = 0.8 得这个机器模型的预测准确率为80%
有没有感觉很奇怪,我猜硬币才只有50%正确率,怎么这个模型只说好人,准确率这么高的?
而且,这个模型是不是不能够识别坏人?
其实原因有两个 1. 数据不平衡 2. 准确率不适合数据不平横的情况
准确率是非常直观的度量指标,也是我们接触的最多的,不过在对付数据不平衡的问题下,准确率就难以反映真实情况。
准确率,在二分类任务中,因为总共只有好或者坏,所以 准确率 = 准确预测好人的能力 + 准确预测坏人的能力
不知道大家有没有发现,虽然不能够识别坏人,但是准确预测好人的能力这个可以拉分,只要好人多过坏人,那么我就可以保证我的预测能力大于50%,如果全是好人,那么我的准确率就100%。准确率就是这么被直接拉高了。因为在数据不平衡的情况下,预测好人的能力的占比可能大于一半,从而掩盖了预测坏人能力比较弱的事实。
这就是为什么在数据不平衡的情况下,准确率无法体现模型的真实水平。
不过还是有多人直接在数据不平衡下用准确率作为指标,在某些准确率高达95,96%的实验结果上,连样本数据都是不平横的。这样的准确率是无意义的。
对于上述情况,我们可以从两个方面解决 1. 解决数据不平衡问题 2. 细化评估指标
-
解决数据不平衡问题
最简单的方法就是补6个坏人平衡数据,那么总共就有16个人,模型的准确率就变为8/16 = 0.5,一半准确率那就等于随便猜了。数据不平横的方法还有很多,以后会深入研究 -
细化评估指标
在现实生活中,解决数据不平衡数据是一个比较麻烦的问题,如果可以通过其他更详细的指标来评估,而不是去修改数据本身,那么是比较节省时间的。
于是乎才有我们今天要说的东西 - 评估指标 (这才是今天的重点)
我们知道 准确率 = 准确预测好人的能力 + 准确预测坏人的能力。把准确率细化为两个指标,分别是 指标1. 准确预测好人的能力 , 指标2. 准确预测坏人的能力
其实,准确预测好人的能力实际上就是敏感度,而准确预测坏人的能力就是特异度,都是机器学习上非常常用的度量指标
-
敏感度 sensitivity
样本实际值为好人,模型把它预测为好人的正确率。公式:Sensitivity = True positives / (True positives + False negatives)。 -
特异度 specificity
样本实际值为坏人,模型把它预测为坏人的正确率。公式:Specificity = True negatives / (True negatives + False positives)
如果敏感度高,特异度低,那么模型只会看好人,不会看坏人。
如果敏感度低,特异度高,模型只会看坏人,不会看好人。
只有敏感度和特异度都比较高,模型既可以分辨好人,也可以分辨坏人,才是一个有用的模型。
我们将这两个指标应用到上面的例子上,敏感度 = 8/8 = 1 ,特异度 = 0/2 = 0
可以看出,虽然敏感度特别高,但是特异度为0,说明这个模型不具备识别坏人的能力,所以这个模型是没有用的。
如果理解了敏感度和特异度,我们就可以开始了解一下混淆矩阵,解释一下上面的公式在说什么
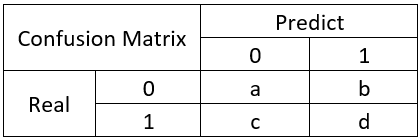
左边 Real 表示实际值, Predict 表示预测值
我们把0看为好人,1看为坏人,那么
- a:实际为好人,预测也为好人 - 叫作 真阳性 True Positive
- b:实际为好人,预测为坏人 - 叫作假阴性 False Negative,也叫作误报 Type 1 error
- c:实际为坏人,预测为好人 - 叫作假阳性 False Positive,漏报 Type 2 error
- d:实际为坏人,预测为坏人 - 叫做真阴性 True Negative
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4048
4048

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









