







总结

神经网络
概念
机器学习的本质就是从数据中寻找解决方案。
先决知识
分类(classification)
分类问题是有监督学习的问题。
- 二元分类(Binary Classification):将输入数据分为两个互斥的类别。例如,判断一个电子邮件是否为垃圾邮件。
- 多类分类(Multiclass Classification):将输入数据分配到多个互斥的类别之一。例如,在图像识别中,将图像分类为狗、猫、汽车等不同的类别。
- 多标签分类(Multilabel Classification):每个输入样本可以同时属于多个类别。例如,在新闻分类中,一篇新闻报道可能同时涉及政治、经济、体育等多个领域。
回归(regression)
回归问题是有监督学习的问题。
根据x值预测实数值y。
目标:找到拟合给定数据的函数。
聚类(clustering)
聚类问题是无监督学习的问题,算法的思想就是“物以类聚,人以群分”。聚类算法感知样本间的相似度,进行类别归纳,对新的输入进行输出预测,输出变量取有限个离散值。
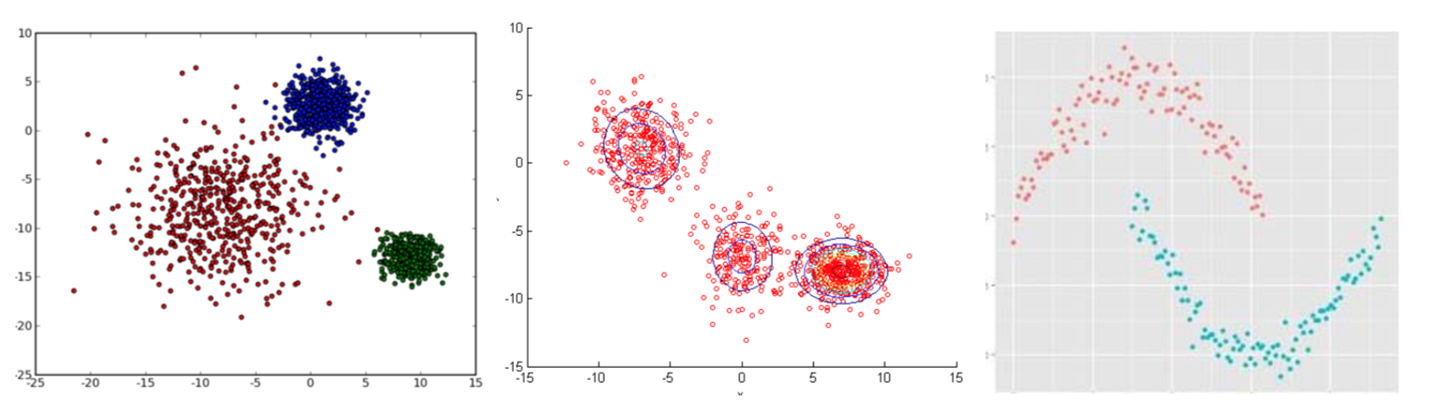
有监督学习与无监督学习
有监督学习:输入数据有标签
无监督学习:输入数据无标签

无监督学习:对抗学习。
线性变换(linear transformation)
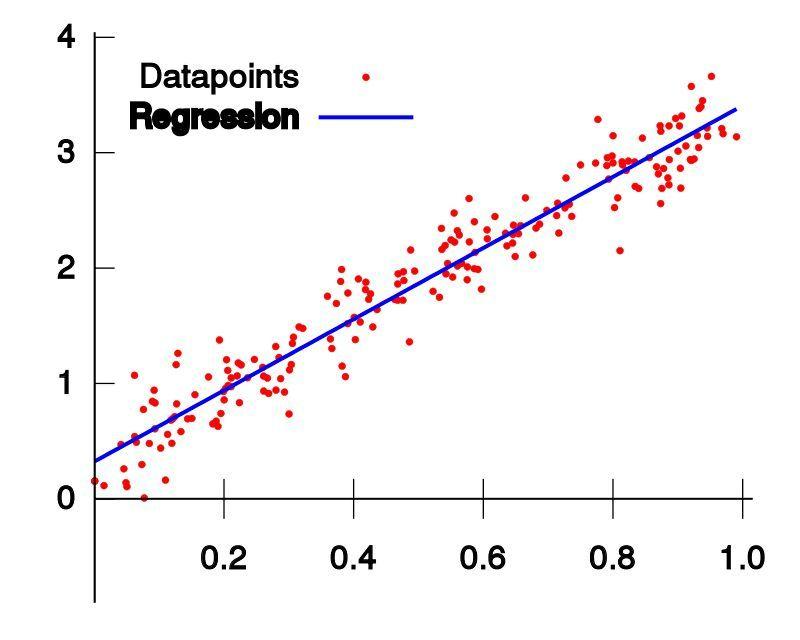
y = wx + b
- 其中w在数学公式中称为斜率(Slope),它决定了直线相对于x轴的倾斜程度;b称为截距(Intercept),它决定了直线与y轴的交点。
- 其中w在神经网络中称为权重(Weight),b称为偏置(Bias)。
这种变换叫做线性变换(linear transformation)或仿射变换(affine transformation)。
非线性变化(non-linear transformation)
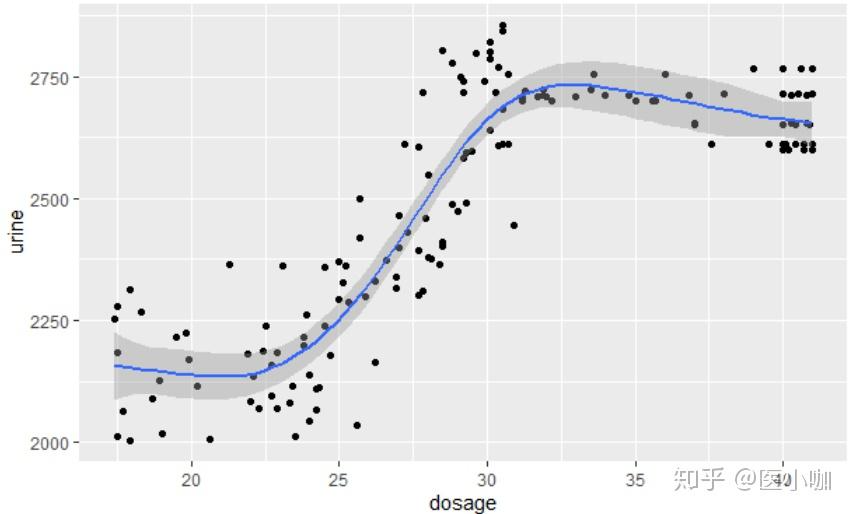
x与y不呈现线性关系。
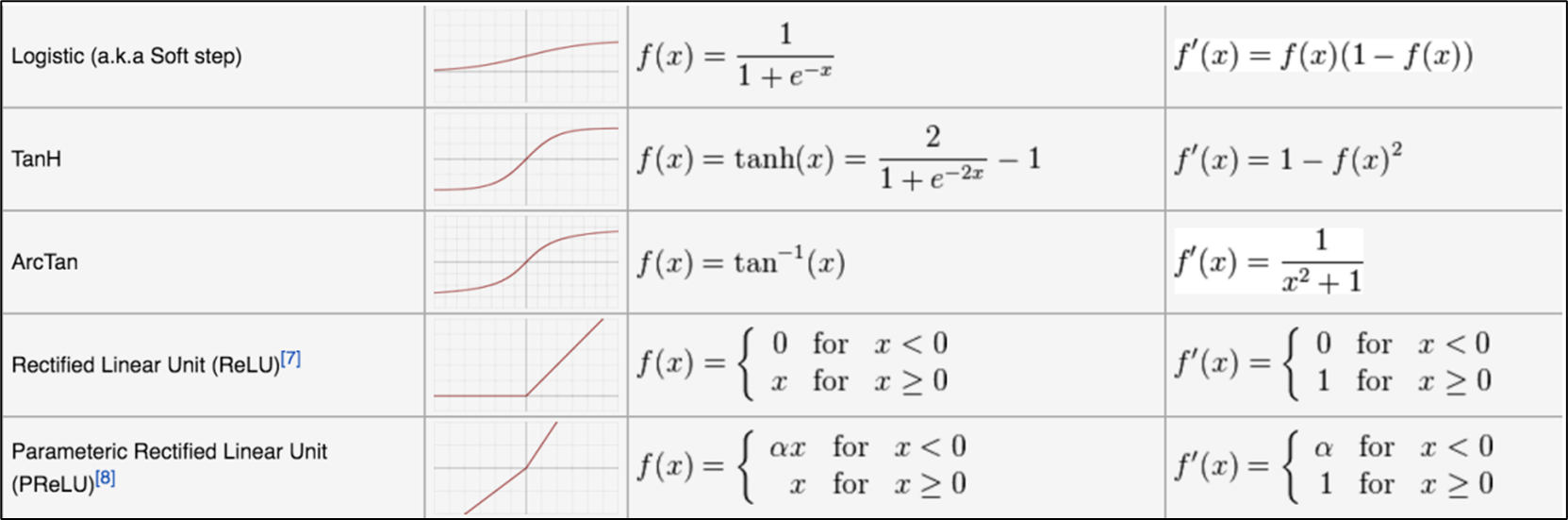
激活函数(Activation Function)
神经网络对线性变换的输出进行非线性变换。这种非线性变化叫做激活函数。典型激活函数有ReLU和sigmoid函数。
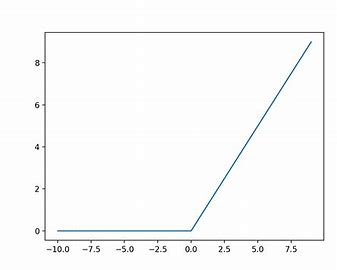
ReLU(Rectified Linear Unit)
ReLU函数在输入大于0时按原样输出,在输入小于0时输出0.
公式: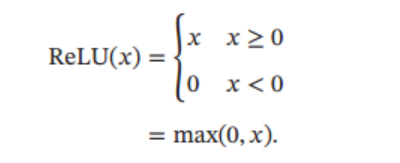
sigmoid
公式: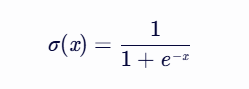
其中,x 是输入值(可以是任何实数),σ(x) 是输出值,其范围在 0 和 1 之间。
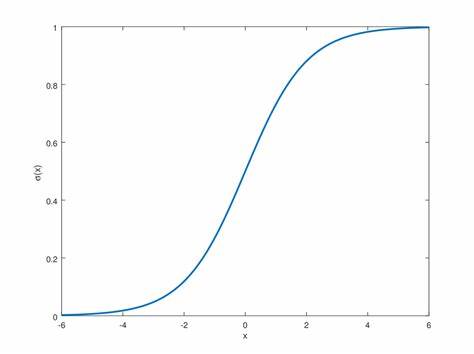
Sigmoid 函数的一个主要特性是,当 x 趋近于正无穷时,σ(x) 趋近于 1;而当 x 趋近于负无穷时,σ(x) 趋近于 0。这种特性使得 sigmoid 函数非常适合用于将任意实数值压缩到 0 到 1 的范围内,从而可以解释为一个概率值。
softmax
在神经网络中,Softmax函数是一种常用的激活函数,特别是在处理多分类问题时。以下是关于Softmax函数的详细介绍:
- 定义
Softmax函数将输入值(通常是模型的原始输出分数或对数几率)转换为概率分布,使得所有类别的概率之和为1。这使得Softmax函数非常适合用于多分类问题的输出层。
- 公式
对于输入向量x的第i个元素x_i,Softmax函数的输出y_i可以表示为:
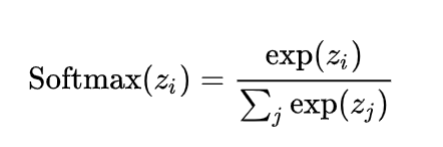
其中,exp是自然对数的底数(约等于2.71828),n是输入向量的长度(即类别的数量)。
- 特点
- 概率分布:Softmax函数的输出是一个概率分布,即所有输出值的范围在[0, 1]之间,且它们的和为1。这使得Softmax函数的输出可以直接解释为属于各个类别的概率。
- 单调性:由于Softmax函数是基于指数函数的,因此它保持了输入值的相对大小关系。即,如果x_i > x_j,那么y_i也将大于y_j。
- 敏感性:Softmax函数对输入值的敏感度取决于输入值的相对大小。当输入值的差异较大时,Softmax函数会给出更加确定的概率分布;而当输入值的差异较小时,Softmax函数会给出更加均匀的概率分布。
- 应用
在神经网络中,Softmax函数通常用于分类问题的输出层。神经网络的最后一层(即输出层)通常包含与类别数量相等的神经元。这些神经元的原始输出分数经过Softmax函数处理后,转换为属于各个类别的概率。然后,可以选择概率最大的类别作为预测结果。

- 与Sigmoid函数的区别
Sigmoid函数也是一种常用的激活函数,但它主要用于二分类问题。与Softmax函数不同,Sigmoid函数将输入值映射到[0, 1]之间的单个输出值,表示属于某个类别的概率。而Softmax函数则将输入值映射到多个输出值(即概率分布),表示属于不同类别的概率。因此,在处理多分类问题时,Softmax函数是更合适的选择。
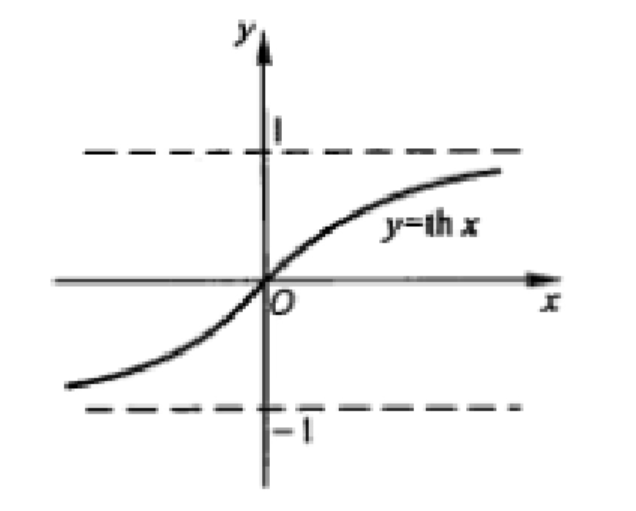
tanh
- 公式:y = tanh(x) = (ex - e-x) / (ex + e-x),其中e是自然对数的底数。

- tanh函数是Sigmoid函数的一种变种,它将输入值映射到范围在-1到1之间的连续值。
- 使用场景:
- tanh函数在神经网络中有许多应用场景,主要是作为隐藏层的激活函数。
- 在深度神经网络中,tanh函数通常被用作隐藏层的激活函数。由于其输出范围在-1到1之间,且具有零中心性质,有助于减少梯度消失问题。
- 在某些图像处理任务中,tanh函数可以作为一种激活函数来帮助提取图像的特征和进行图像分类。
- 优点:tanh函数是一个可导的、平滑的函数,输出在[-1,1]之间,可以被解释为概率。其输出以0为中心,这有利于梯度下降,并且与Sigmoid函数相比,tanh函数的均值接近0,有助于加速模型的训练。
- 缺点:在极端输入值时,tanh函数的梯度仍然会变得非常小,导致梯度消失的问题。
其他
损失函数(Loss Function)
在神经网络中,损失函数(Loss Function)是一个用于衡量模型预测结果与真实值之间差异的函数。它是神经网络优化和训练的关键部分,通过最小化损失函数来更新网络参数(W,b),提高模型的预测性能。以下是关于神经网络中常见的损失函数的详细解释:
均方误差(Mean Squared Error, MSE)
- 计算公式:MSE = ∑(y - y’)² / n
- 其中,y 是真实值,y’ 是预测值,n 是样本数。
- MSE 是回归问题中最常用的损失函数之一,它计算预测值与真实值之间的平方差的均值。适用于连续值的预测问题。
- MSE 的值越小,说明预测结果与真实值越接近。
平均绝对误差(Mean Absolute Error, MAE)
- 计算公式:MAE=n_1_i=1∑_n_∣_yi_−_y_^_i_∣
- n 是样本的数量。
- yi 是第 i 个样本的真实值。
- y^i 是第 i 个样本的预测值。
- ∣_yi_−_y_^_i_∣ 表示真实值与预测值之间的绝对差异。
- MSE 的值越小,说明预测结果与真实值越接近。
交叉熵损失(Cross-Entropy Loss)
- 计算公式:CE = -∑ y log(y’)
- 其中,y 是真实值的概率分布,y’ 是预测值的概率分布。
- 交叉熵损失函数常用于分类问题,特别是多类别分类。它通过计算预测概率分布与真实标签之间的交叉熵来衡量模型的错误程度。
- 交叉熵的值越小,说明预测结果与真实值越接近。
KL散度(Kullback-Leibler Divergence)
- 计算公式:KL = ∑ y log(y / y’)
- 其中,y 是真实值的概率分布,y’ 是预测值的概率分布,使用了激活函数softmax输出的结果。
- KL散度是一种用来度量两个概率分布之间差异的函数。在神经网络中,它通常用来度量网络输出与真实分布之间的差异。
- KL散度的值越小,说明预测结果与真实值越接近。
Hinge Loss
- 计算公式:HL = max(0, 1 - y * y’)
- 其中,y 是真实值,y’ 是预测值。
- Hinge Loss 主要用于支持向量机(SVM)等模型的分类问题中。
- 当 y * y’ >= 1 时,HL 的值为 0;否则,HL 的值随着 y * y’ 的增大而逐渐增大。
层(Layer)
在神经网络中,线性变换或基于激活函数的变换称为层。
Linear
实现线性变化的层。
Sigmoid
实现非线性变换的(sigmoid激活函数)的层。
ReLU
实现非线性变换的(ReLU激活函数)的层。
Conv
实现卷积操作的层。
Pool
实现池化操作的层。
Embedding
用于将离散的输入(如单词、字符、类别等)转换为固定大小的连续向量,即嵌入向量(embedding vectors)。
Affine
进行的矩阵的乘积运算的层,矩阵的乘积运算在几何学领域被称为“仿射变换”。
Softmax with Loss
Softmax与交叉熵损失通常一起使用,构成Softmax with Loss的组合。这种组合在神经网络的最后一层(通常是全连接层)之后应用Softmax函数将输出转换为概率分布,然后使用交叉熵损失函数计算损失。
Attention
实现注意力的层。
超参数(Hyperparameters)
- **定义: **由人决定的参数。
- 分类:
- 网格参数:涉及网络结构,如网络宽度(层宽)、深度(层数)、链接方式、卷积核数量、卷积核尺寸、激活函数等。
- 优化参数:与学习过程相关,包括学习率、批样本数量、优化器(如动量优化器的动量参数β)以及损失函数。
- 正则化参数:用于防止过拟合,如权重衰减系数、丢弃比率等。
- 具体超参数举例:
- 学习率(Learning Rate):控制模型在训练过程中参数更新的步长。通常是一个较小的正数,如0.01、0.001等。
- 迭代次数(Iterations):模型在训练数据上进行前向和反向传播的次数。这个数字直接影响训练时间和模型的拟合能力。
- **轮(epoch):**一个Epoch意味着训练数据集中的每个样本都有机会更新内部模型参数。简而言之,一个Epoch代表了一次完整的训练周期,即模型已经“看到”了训练数据集中的所有数据一次。
- 隐藏层数目(Hidden Layers):神经网络中的层数,决定了模型的复杂度和学习能力。
- 隐藏层单元数目:每层中的神经元数量,影响模型的表示能力和计算成本。
- 激活函数(Activation Function):用于在神经网络中添加非线性因素,常见的激活函数包括ReLU、Sigmoid和Tanh等。
- 损失函数(Loss Function):用于衡量模型预测值与实际值之间的差距,常见的损失函数有均方误差、交叉熵损失等。
参数更新(Parameter Update)
随机梯度下降(Stochastic Gradient Descent, SGD)
- 原理:SGD根据一个随机选择的样本来计算损失函数的梯度,并据此更新网络参数。
- 优点:计算速度快,因为每次迭代只需要考虑一个样本。
- 缺点:由于每次只考虑一个样本,更新可能具有较大的随机性,导致震荡和可能陷入局部最小值。
- 数学公式: W = W - η * (dL/dW)^(i)
- W:模型参数
- η:学习率
- (dL/dW)^(i):损失函数L关于参数W对于单个样本i的梯度
class SGD(Optimizer):
def __init__(self, lr=0.01) #lr是学习率
super().__init__()
self.lr = lr
def update_one(self, param):
param.data -= self.lr * param.grad.data
批量梯度下降(Batch Gradient Descent, BGD)
- 原理:BGD在每个更新步骤中考虑整个训练集,从而消除SGD中的随机性。
- 优点:由于考虑了整个训练集,更新更加稳定。
- 缺点:计算速度慢,因为它需要一次处理整个训练集。此外,对于大规模数据集,内存占用可能是一个问题。
- 数学公式:W = W - η * (dL/dW)
- W:模型参数
- η:学习率
- (dL/dW):损失函数L关于参数W的梯度,这里考虑的是整个训练集
自适应梯度下降(Adaptive Gradient Descent, AGD)
- 原理:AGD通过动态调整学习率来加速参数更新。在每一步,AGD都会根据之前步骤的梯度大小来调整学习率。
- 优点:在处理复杂和非线性问题时表现良好,因为学习率可以根据梯度进行自适应调整。
- 缺点:如果学习率调整不当,可能导致训练不稳定或收敛速度过慢。
Momentum update
- 原理:Momentum update受到物理中动量概念的启发,通过引入“速度”的概念来加速SGD在相关方向上的更新,并抑制震荡。
- 优点:在深度网络中收敛更好,能够加速训练过程。
- 缺点:引入了一个新的超参数(动量系数),需要进行调整。
- 数学公式:
v = β * v - η * (dL/dW) ①
W = W + v ②- W:模型参数
- η:学习率
- β:动量系数,通常接近1(如0.9)
- v:速度,初始化为0,用于加速SGD在相关方向上的更新并抑制震荡
class MomentumSGD(Optimizer):
def __init__(self, lr=0.01, momentum=0.9):
super().__init__()
self.lr = lr
self.momentum = momentum
self.vs = {} #速度
def update_one(self, param):
v_key = id(param)
if v_key not in self.vs:
self.vs[v_key] = np.zeros_like(param.data)
v = self.vs[v_key]
v *= self.momentum
v -= self.lr * param.grad.data
param.data += v
RMSprop 和 Adam
-
原理:RMSprop和Adam都是自适应学习率的方法。RMSprop使用梯度平方的移动平均值来调整学习率,而Adam结合了RMSprop和Momentum的思想,进一步提高了训练速度和稳定性。
-
优点:两者都能根据梯度自动调整学习率,对超参数的选择相对鲁棒,适用于大多数深度学习问题。
-
缺点:引入了一些新的超参数(如学习率衰减率、beta值等),需要进行调整。
-
Adam
数学公式(简化版):
m_t = β1 * m_{t-1} + (1 - β1) * (dL/dW)t ①
v_t = β2 * v{t-1} + (1 - β2) * ((dL/dW)_t)^2 ②
m_hat_t = m_t / (1 - β1^t) ③
v_hat_t = v_t / (1 - β2^t) ④
W = W - η * m_hat_t / (sqrt(v_hat_t) + ϵ) ⑤
- W:模型参数
- η:学习率
- β1, β2:超参数,控制指数衰减率(通常β1接近1,如0.9;β2接近1但小于β1,如0.999)
- m_t, v_t:梯度的一阶矩估计和二阶矩估计
- m_hat_t, v_hat_t:修正后的矩估计
- (dL/dW)_t:当前时刻的梯度
- ϵ:一个小的常数,用于防止除以零或接近于零的数
数据集的预处理(Preprocessing of Dataset)
在向机器学习的模型输入数据之前,通常要对数据进行一定的处理。
一些常见的数据集预处理步骤:
- 数据清洗:
- 缺失值处理:对于缺失的数据,可以使用均值、中位数、众数或特定的预测模型进行填充,或者简单地删除包含缺失值的行或列。
- 异常值处理:识别并处理数据中的异常值,如使用IQR(四分位距)规则或Z-score方法等。
- 重复值处理:删除或合并重复的数据行。
- 数据过滤:根据业务需求,筛选出符合特定条件的数据。
- 数据转换:
- 类别编码:对于分类数据,使用标签编码(Label Encoding)、独热编码(One-Hot Encoding)或自定义编码进行转换。
- 文本处理:对于文本数据,进行分词、去除停用词、词干提取、词形还原、TF-IDF转换等操作。
- 日期和时间处理:提取日期和时间数据中的有用特征,如年份、月份、星期几等。
- 对数转换:对于偏态分布的数据,可以使用对数转换使其更接近正态分布。
- 归一化/标准化:将数据按比例缩放,以消除不同特征之间的尺度差异,使模型更容易学习和收敛。常见的归一化方法有最小-最大归一化,而标准化则使用均值和标准差。
- 特征选择:
- 特征降维:使用PCA(主成分分析)、LDA(线性判别分析)等方法减少特征数量,同时尽可能保留数据中的信息。
- 特征重要性评估:使用树模型(如随机森林、决策树)或模型内置的特征重要性评估方法来确定哪些特征对模型性能贡献最大。
- 去除冗余特征:删除与其他特征高度相关的特征,以减少计算成本和提高模型泛化能力。
- 数据分割:
- 训练集、验证集和测试集分割:将数据集分为三个部分,分别用于模型训练、超参数调整和模型评估。通常,训练集占大部分(如70%),验证集和测试集各占一小部分(如15%)。
- 数据增强(主要针对图像和音频数据):
- 对于图像数据,可以通过旋转、平移、缩放、裁剪、翻转等操作增加数据集的多样性。
- 对于音频数据,可以使用噪声添加、时间拉伸、音调变换等方法进行数据增强。
- 数据平衡:
- 如果数据集中不同类别的样本数量差异很大,可能会导致模型偏向于数量较多的类别。这时可以使用过采样(如SMOTE算法)或欠采样方法来平衡各类别样本的数量。
- 数据验证:
- 在进行模型训练之前,确保数据已经经过适当的预处理,并且没有引入任何错误或偏差。可以使用统计方法或可视化工具来验证数据的质量和分布。
过拟合(Overfitting)
- **定义:**模型过度拟合了特定训练数据的状态。无法预测未知数据的状态,或者说不能泛化的状态就是过拟合。
- 原因:
- 训练的数据少。
- 解决办法:
- 数据增强(data augmentation)。
- 解决办法:
- 模型的表现力太强。
- 解决办法:
- 权重衰减(weight decay):一种在深度学习中通过向模型的损失函数中添加一个正则项来限制模型复杂度的方法。这种正则项通常基于模型参数的L2范数(即参数的平方和)。
- Dropout:是一种随机删除(禁用)神经元进行训练的方法,模型在训练时随机选择隐藏层的神经元,并删除选中的神经元。
- 原因:集成学习(ensemble learning)是单独训练多个模型,在推理时对多个模型的输出取平均值的方法。经过实验发现,这种做法可以使神经网络的识别精度提高几个百分点。集成学习和Dropout相似,之所以这么说,是因为Dropout在训练时会随机删除神经元,这可以解释为每次都在训练不同的模型。
- Direct Dropout:Direct Dropout是在训练过程中,以一定的概率随机地将神经网络中的某些神经元“关闭”或“丢弃”,这些被丢弃的神经元在前向传播和反向传播中都不起作用。
- Inverted Dropout:Inverted Dropout,也称为反向随机失活,与Direct Dropout类似,也是在训练过程中随机丢弃一部分神经元。但其不同之处在于,Inverted Dropout在训练时会对神经元的输出进行缩放,以确保在测试时不需要进行额外的调整。
- 批量正则化(batch normalization):批量正则化是一种在神经网络训练过程中,对每个小批量(mini-batch)的数据进行归一化的技术。它通过调整神经网络的激活函数输入,使其具有适当的尺度,从而加速训练过程并提高模型的性能。
- 解决办法:
目标
神经网络训练的目标是调整网络中的参数(如权重和偏置),以最小化一个预定义的损失函数(loss function),该损失函数衡量了模型预测与真实标签之间的差异。训练神经网络通常涉及以下几个关键步骤:
- 定义网络结构:选择一个适合问题的神经网络架构,如多层感知机(MLP)、卷积神经网络(CNN)、循环神经网络(RNN)等,并确定网络的层数、每层的神经元数量、激活函数等。
- 初始化参数:在训练开始前,网络中的权重和偏置需要被初始化为一些随机值或特定的初始值。初始化的方式会影响网络的训练速度和性能。
- 前向传播:对于给定的输入数据,通过神经网络进行前向传播,计算每一层的输出,直到得到最终的预测值。
- 计算损失:将网络的预测值与真实标签进行比较,使用损失函数计算预测值与真实值之间的差异。常见的损失函数包括均方误差(MSE)、交叉熵损失(cross-entropy loss)等。
- 反向传播:根据损失函数计算出的梯度信息,通过反向传播算法更新网络中的参数。反向传播算法利用链式法则计算损失函数关于每个参数的梯度,并使用优化算法(如梯度下降、Adam等)更新参数。
- 迭代优化:重复执行前向传播、计算损失和反向传播的过程,不断更新网络参数,以减小损失函数的值。这个过程通常通过迭代多次训练数据集(称为一个epoch)来完成。
- 验证和测试:在训练过程中,使用验证集来评估模型的性能,以便在过拟合和欠拟合之间进行权衡。训练完成后,使用测试集来评估模型的泛化能力。
- 调整超参数:在训练过程中,可能需要调整一些超参数(如学习率、批处理大小、迭代次数等)以获得更好的性能。这些超参数的选择通常基于经验、实验或自动调参技术。
- 部署和应用:一旦模型训练完成并达到满意的性能,就可以将其部署到实际应用中,用于处理新的输入数据并生成预测结果。
总之,神经网络训练的目标是通过调整网络参数来最小化损失函数,从而提高模型的预测性能。
解决问题
回归(线性回归/非线性回归)问题
在深度学习中,回归任务通常使用回归损失函数来评估模型的性能,如均方误差(Mean Squared Error, MSE)或平均绝对误差(Mean Absolute Error, MAE)。这些损失函数计算预测值与实际值之间的差异,并用于指导模型的训练过程。
多分类问题
在多分类问题中,通常有以下特点:
- 多个类别:存在多个不同的类别标签,每个输入样本需要被分配到这些类别中的一个。
- 输出层:在神经网络中,输出层通常包含与类别数量相等的神经元。每个神经元的输出表示输入样本属于对应类别的概率。
- 激活函数:输出层的激活函数通常是softmax函数,它可以将神经元的输出转换为概率分布,使得所有类别的概率之和为1。
- 损失函数:在多分类问题中,常用的损失函数是交叉熵损失(Cross-Entropy Loss),它衡量了模型预测的概率分布与真实概率分布之间的差异。
- 评估指标:评估多分类模型性能的指标包括准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1分数(F1 Score)等。这些指标可以帮助我们全面了解模型在不同类别上的表现。
聚类问题
聚类问题是无监督学习的问题,算法的思想就是“物以类聚,人以群分”。聚类算法感知样本间的相似度,进行类别归纳,对新的输入进行输出预测,输出变量取有限个离散值。
- 可以作为一个单独过程,用于寻找数据内在的分布结构
- 可以作为分类、稀疏表示等其他学习任务的前驱过程
实现
神经网络,以“线性变换→激活函数→线性变换→激活函数→线性变换→……”的形式进行一系列的变换。
训练
在神经网络训练过程中:会将损失函数加在推理处理后面,然后找到使该损失函数的输出最小的参数。
预测
神经网络,以“线性变换→激活函数→线性变换→激活函数→线性变换→……”的形式进行一系列的变换。
例如,一个2层的神经网络可以用如下伪代码实现:
W1, b1 = Variable(...), Variable(...)
W2, b2 = Variable(...), Variable(...)
# 预测
def predict(x):
y = F.linear(x, W1, b1) #线性变换
y = F.sigmoid(y) #激活函数
y = F.linear(y, W2, b2) #线性变换
return y
神经网络架构
MLP(Multi-Layer Perceptron)全连接层神经网络
在机器学习中,MLP的全称是多层感知器(Multi-Layer Perceptron),也被称为多层感知机。MLP是全连接层神经网络的别名。它是一种基于前馈神经网络(Feedforward Neural Network)的机器学习模型,通常由多个全连接层组成。每个全连接层都包含多个神经元,每个神经元都与前一层的所有神经元相连,并通过激活函数对输入进行非线性变换。

应用领域
- 图像识别:
- MLP在图像识别领域有着广泛的应用,包括图像分类、物体检测等任务。例如,通过输入图像的像素值,MLP可以学习到图像的特征信息,进而实现对不同类别图像的识别。
- 在图像识别任务中,MLP可以与其他深度学习模型(如卷积神经网络CNN)结合使用,以提高识别的准确性和效率。
- 自然语言处理:
- MLP在自然语言处理领域也有着广泛的应用,包括文本分类、情感分析等任务。通过训练大量的文本数据,MLP可以学习到文本的语义信息,实现高效的分类和情感分析。
- 例如,在文本分类任务中,MLP可以根据文本的内容和上下文信息,将输入的文本数据分为不同的类别。在情感分析任务中,MLP可以判断文本中的情感倾向,如积极、消极或中性等。
- 金融预测:
- MLP在金融领域也有着重要的应用,如股票价格预测、汇率预测等。通过对历史金融数据的学习和分析,MLP可以预测未来的金融市场趋势和风险。
- 在金融预测任务中,MLP可以学习到金融数据的内在规律和趋势,从而实现对未来金融市场的准确预测。这有助于金融机构和企业做出更明智的投资和决策。
- 医学影像分析:
- 在医学影像领域,MLP被应用于医学图像识别、疾病预测等任务。通过输入医学图像的像素值,MLP可以学习到图像中的病变特征和结构信息,进而实现对疾病的诊断和预测。
- 例如,在乳腺癌诊断中,Mayo Clinic使用MLP模型帮助医生识别乳腺X光片中的异常区域,提高诊断的准确性和效率。
- 其他领域:
- 除了以上几个领域外,MLP还在声音识别、推荐系统、情感分析等领域有着广泛的应用。例如,在声音识别任务中,MLP可以学习到语音的特征信息,实现对不同语音的识别;在推荐系统中,MLP可以根据用户的历史行为数据推荐感兴趣的商品或服务;在情感分析任务中,MLP可以判断文本中的情感倾向等。
伪代码实现
class MLP(Model):
#下面的fc是full connect(全连接)的缩写
#activation指定激活函数
def __init__(self, fc_output_sizes, activation=F.sigmoid):
super().__init__()
self.activation = activation
self.layers = []
for i, out_size in enumerate(fc_output_sizes):
layer = L.Linear(out_size) #创建Linear层(实现线性变化的层)
setattr(self, 'l' + str(i), layer)
self.layers.append(layer)
def forward(self, x):
for l in self.layers[:-1]:
x = self.activation(l(x)) #将Linear层的结果 输出给 激活函数
return self.layers[-1](x)
有了MLP类,我们可以轻松实现下面的N层网络
model = MLP((10, 1)) #2层
model = MLP((10,20,30,40,1)) #5层
CNN(Convolutional Neural Network)卷积神经网络
CNN和我们之前见的MLP相同,也是由各层(Layer)组合而成的。不过在CNN中,出现了新的层——**卷积层(convolution layer)**和 池化层(pooling layer)。

应用领域
CNN(卷积神经网络)擅长的领域主要集中在图像和视频处理方面,以及与之相关的任务。以下是CNN擅长的领域的详细归纳:
- 图像识别:
- CNN在图像识别领域取得了显著的成功,尤其是在大规模图像分类问题上。它可以通过学习图像中的特征表示,有效地识别出图像中的物体、场景等。
- 例如,在ImageNet等大规模图像分类数据集上,CNN模型如AlexNet、VGGNet、ResNet等取得了令人瞩目的性能。
- 物体检测:
- CNN不仅可以识别图像中的物体,还可以对物体进行定位。它可以通过在图像中滑动窗口或使用区域建议网络(RPN)等方法来检测物体,并给出物体的边界框。
- 流行的物体检测算法如Faster R-CNN、YOLO(You Only Look Once)和SSD(Single Shot MultiBox Detector)等都基于CNN。
- 图像分割:
- CNN在图像分割任务中也有着广泛的应用。它可以将图像划分为多个区域,每个区域具有相同的属性或特征。
- 例如,在医学图像分析中,CNN可以用于分割病变区域、血管等;在自动驾驶中,CNN可以用于分割道路、车辆、行人等。
- 图像生成:
- CNN不仅可以处理和分析图像,还可以生成图像。通过训练CNN模型,可以生成具有特定特征或风格的图像。
- 例如,GAN(生成对抗网络)就是基于CNN的一种生成模型,它可以生成逼真的图像、视频等。
- 视频处理:
- CNN也可以应用于视频处理任务,如视频分类、视频目标检测、视频分割等。
- 通过将视频帧视为连续的图像序列,CNN可以捕捉视频中的时空信息,从而实现对视频内容的分析和理解。
- 其他领域:
- 除了上述领域外,CNN还在语音识别、自然语言处理等领域有所应用。尽管这些领域通常与RNN或Transformer等模型更相关,但CNN的局部感知和权值共享的特性也使其在这些领域具有一定的优势。
总结来说,CNN在图像和视频处理领域具有广泛的应用和出色的性能。通过学习图像中的特征表示和捕捉时空信息,CNN可以实现对图像和视频内容的深入理解和分析。
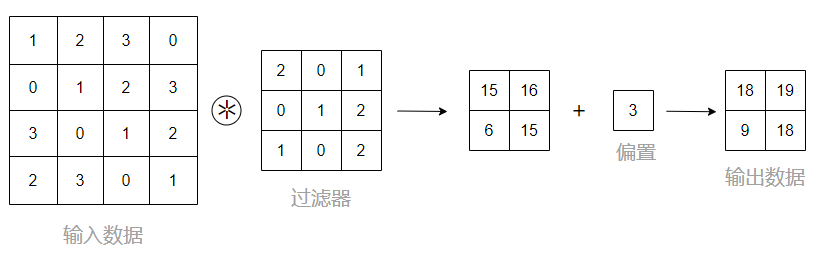
卷积运算(Conv)
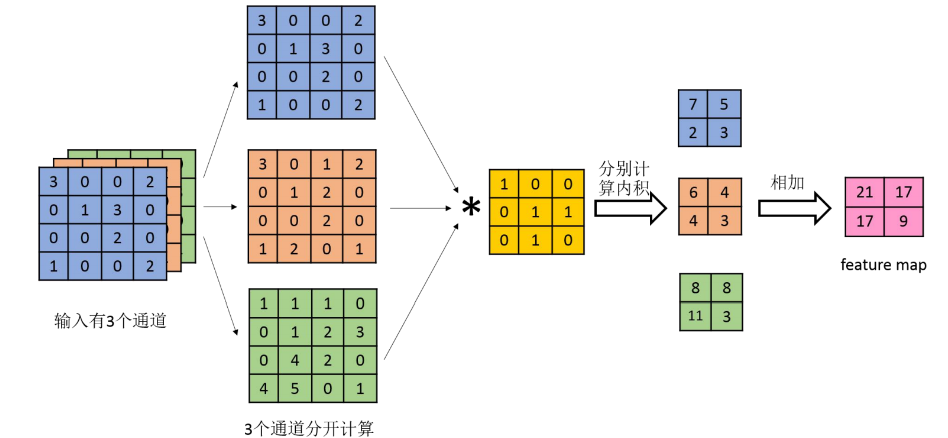
单通道,二维,带偏置的卷积示例
多通道卷积计算:
填充(padding)
在使用卷积层主要处理前,有时候需要在输入数据额度周围填充固定的数据(例如0),这个处理就叫做填充。
使用填充的主要目的是调整输出的大小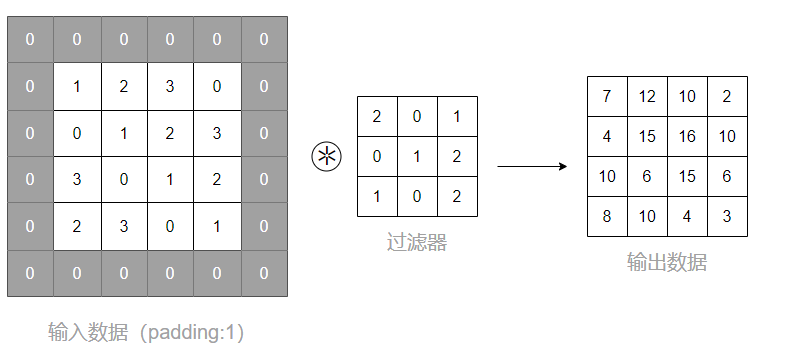
步幅(stride)

池化层(Pool)
池化窗口(pooling region)和 步幅(stride)
一般来说,池化窗口的大小和步幅应设置为相同的值,例如3×3池化的步幅为3,4×4池化的步幅为4,以此类推。
池化处理(pooling operation)
-
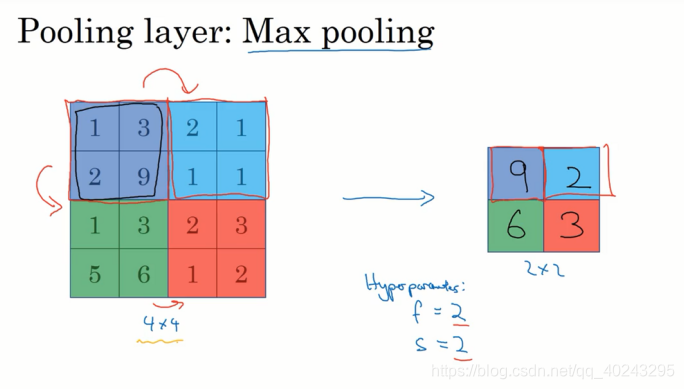
**最大池化(Max Pooling):**从对象区域中取出最大值的计算。
-
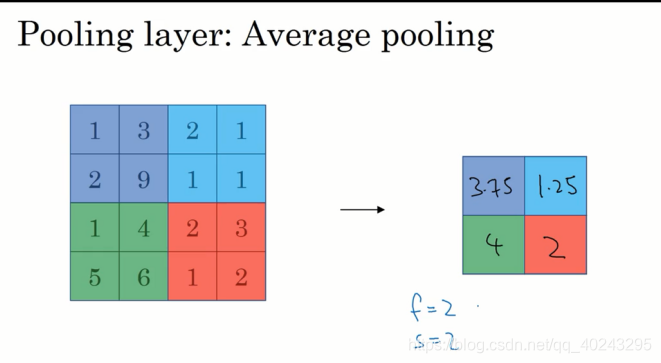
**平均池化(Average Pooling):**计算对象区域的平均值。
-
最大池化(Max Pooling)
-
平均池化(Average Pooling):
特点
- **没有学习参数:**与卷积层不同,池化层没有任何学习参数。这是因为池化只取对象区域中的最大值(或平均值)。
- **通道数量不发生改变:**池化计算不改变输入数据和输出数据的通道数量。计算是按通道独立进行的。
- **对微小的位置变化具有鲁棒性:**对于输入数据中的微小差异,池化的结果是相同的。
具有代表性的CNN
VGG16
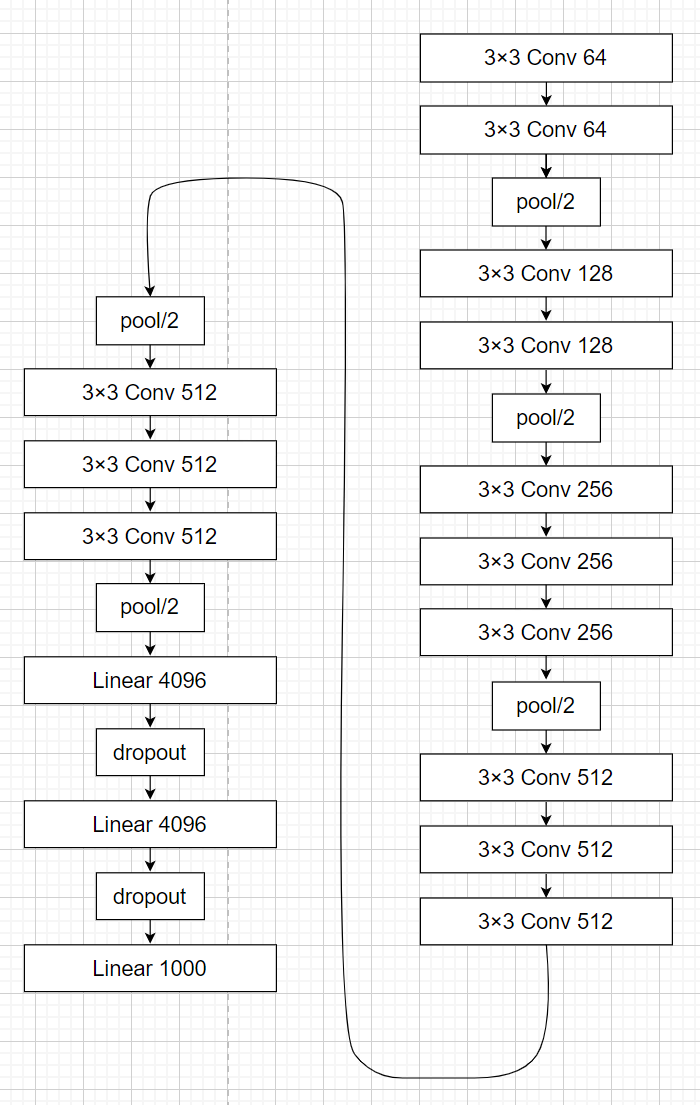
- “3×3 conv 64”表示卷积核大小为3×3,输出通道数为64。
- “pool/2”表示2×2的池化。
- “linear 4096”表示输出大小为4096的全连接层。
介绍:
VGG是2014年ILSVRC比赛中获得亚军的模型,作者通过改变模型中使用的层数等方式提出几种变体。
VGG16是在大型数据集ImageNet上训练的,训练后的权重数据已开放下载。
RNN(Recurrent Neural Network)循环神经网络
介绍
RNN(循环神经网络)具有如下所示的循环结构的网络。
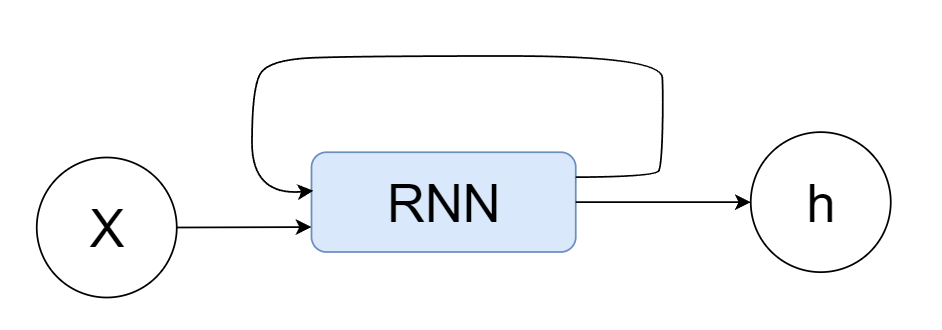
如上所示的循环结构使RNN的输出前馈到自身,因此,RNN网络拥有“状态”。
应用领域
- 自然语言处理(NLP):
- 文本分类:例如,情感分析、垃圾邮件检测等。
- 机器翻译:RNN(尤其是LSTM和GRU等变体)在翻译任务中取得了巨大的成功,如谷歌神经机器翻译系统。
- 文本生成:包括对话生成、诗歌生成、摘要生成等。
- 语音识别:将音频序列转换为文本序列。
- 时间序列预测:
- 股票价格预测。
- 天气预测。
- 传感器数据预测(如医疗设备的读数)。
- 音乐生成和识别:
- RNN可以学习音乐的旋律和节奏模式,用于音乐生成或识别。
- 推荐系统:
- 通过分析用户的浏览或购买历史,RNN可以帮助预测用户未来的兴趣,并据此提供推荐。
- 视频分析:
- 分析视频帧的序列,以识别动作、事件或对象。
- 视频字幕生成(从视频内容生成描述性文本)。
- 运动轨迹预测:
- 预测移动物体的未来轨迹,这在自动驾驶和机器人技术中尤为重要。
- 手写识别:
- 从连续的笔画序列中识别字符或单词。
- 生物信息学:
- 分析DNA或RNA序列以识别基因或预测蛋白质结构。
RNN的循环结构允许它们捕捉序列中的长期依赖关系,这是它们在这些领域取得成功的一个关键因素。然而,传统的RNN在处理非常长的序列时可能会遇到梯度消失或梯度爆炸的问题,这限制了它们捕捉长期依赖的能力。因此,更复杂的RNN变体,如LSTM(长短期记忆网络)和GRU(门控循环单元),被开发出来以解决这些问题,并在许多应用中取得了更好的性能。
公式
以下是RNN的基本公式描述,主要涉及到三个部分:输入、状态和输出。
- 循环单元的状态更新:
假设当前时间步为 t,ht 表示RNN在 t 时刻的隐藏状态(内部记忆),xt 是 t 时刻的输入,_ht_−1 是 _t_−1 时刻的隐藏状态。RNN通过以下方式更新其隐藏状态: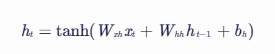
其中:
- tanh 是双曲正切激活函数。
- _Wxh_ 是输入到隐藏状态的权重矩阵。
- _Whh_ 是隐藏状态到隐藏状态的权重矩阵(循环权重)。
- _bh_ 是隐藏层的偏置向量。
- _xt_ 是 _t_ 时刻的输入。
- _ht_−1 是 _t_−1 时刻的隐藏状态。
- 输出:
RNN的输出 yt 通常基于当前时刻的隐藏状态 ht。具体地,
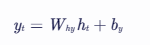
其中:
- Why 是隐藏状态到输出的权重矩阵。
- by 是输出层的偏置向量。
注意:在实际应用中,输出 yt 可能还会经过一个激活函数(如softmax),特别是当处理分类问题时。
- 训练RNN:
为了训练RNN,我们需要定义一个损失函数 L,它衡量了模型预测 yt 和真实值之间的差异。RNN通过反向传播算法(称为反向传播通过时间,Backpropagation Through Time, BPTT)来更新权重矩阵 Wxh、Whh、Why 和偏置向量 bh、by。在BPTT中,损失 L 对这些权重和偏置的梯度是沿着序列展开的,这导致了RNN的训练可能非常耗时,并且容易遇到梯度消失或梯度爆炸的问题。
具有代表性的RNN
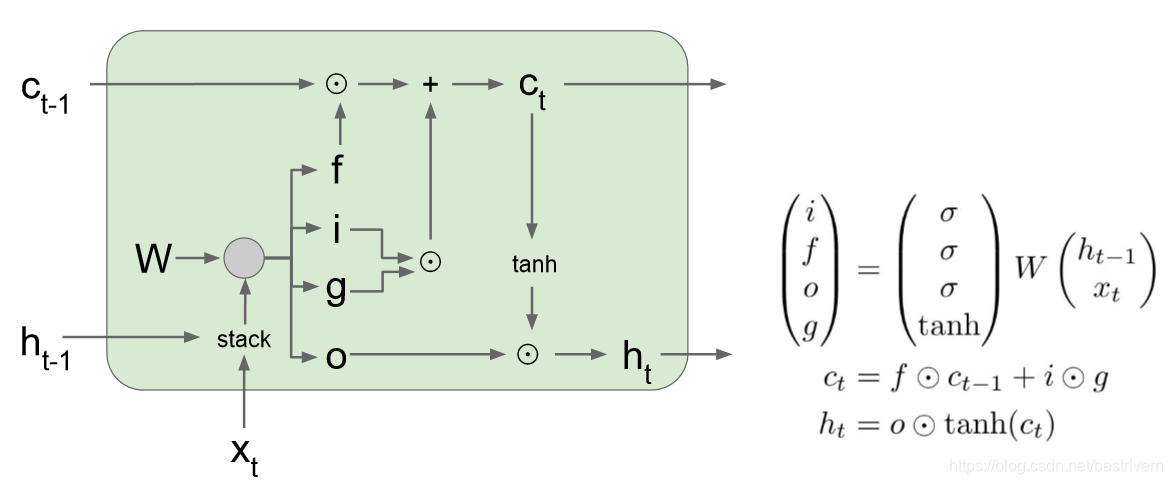
LSTM(Long Short-Term Memory)
由于RNN模型如果需要实现长期记忆的话需要将当前的隐含态的计算与前n次的计算挂钩,即: st=f(U∗xt+W1∗st−1+W2∗st−2+…Wn∗st−n)
那样的话计算量会呈指数式增长,导致模型训练的时间大幅增加,因此RNN模型一般不直接用来进行长期记忆计算。另外,传统RNN处理不了长期依赖问题,这是个致命伤。但LSTM解决了这个问题。
Long Short Term网络—— 一般就叫做 LSTM ——是一种 RNN 特殊的类型,可以学习长期依赖信息。LSTM 由 Hochreiter & Schmidhuber (1997) 提出,并在近期被 Alex Graves 进行了改良和推广。对于很多问题,LSTM 都取得相当巨大的成功,并得到了广泛的使用。
LSTM 通过刻意的设计来避免长期依赖问题。记住长期的信息在实践中是 LSTM 的默认行为,而非需要付出很大代价才能获得的能力!
所有 RNN 都具有一种重复神经网络模块的链式的形式。在标准的RNN中,这个重复的模块只有一个非常简单的结构,例如一个 tanh层。
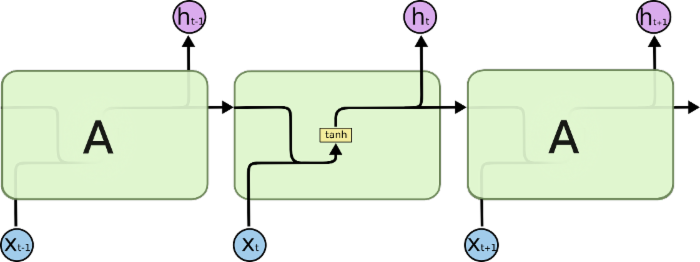
标准 RNN 中的重复模块包含单一的层。
LSTM 同样是这样的结构,但是重复的模块拥有一个不同的结构。不同于 单一神经网络层,这里是有四个,以一种非常特殊的方式进行交互。

LSTM 中的重复模块包含四个交互的层。

在上面的图例中,每一条黑线传输着一整个向量,从一个节点的输出到其他节点的输入。粉色的圈代表 pointwise 的操作,诸如向量的和,而黄色的矩阵就是学习到的神经网络层。合在一起的线表示向量的连接,分开的线表示内容被复制,然后分发到不同的位置。
LSTM 的关键就是细胞状态(cell),水平线在图上方贯穿运行。细胞状态类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。
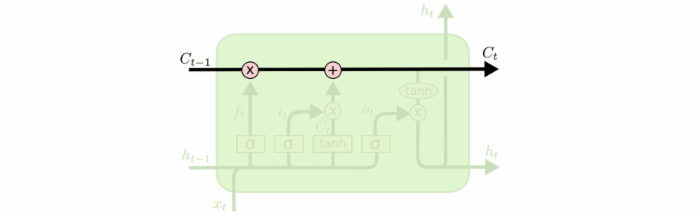
LSTM 有通过精心设计的称作为“门”的结构来去除或者增加信息到细胞状态的能力。门是一种让信息选择式通过的方法。他们包含一个 sigmoid 神经网络层和一个 pointwise 乘法操作。
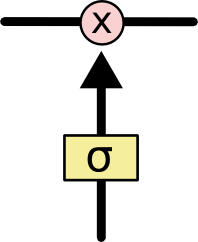
Sigmoid 层输出 0 到 1 之间的数值,描述每个部分有多少量可以通过。0 代表“不许任何量通过”,1 就指“允许任意量通过”!
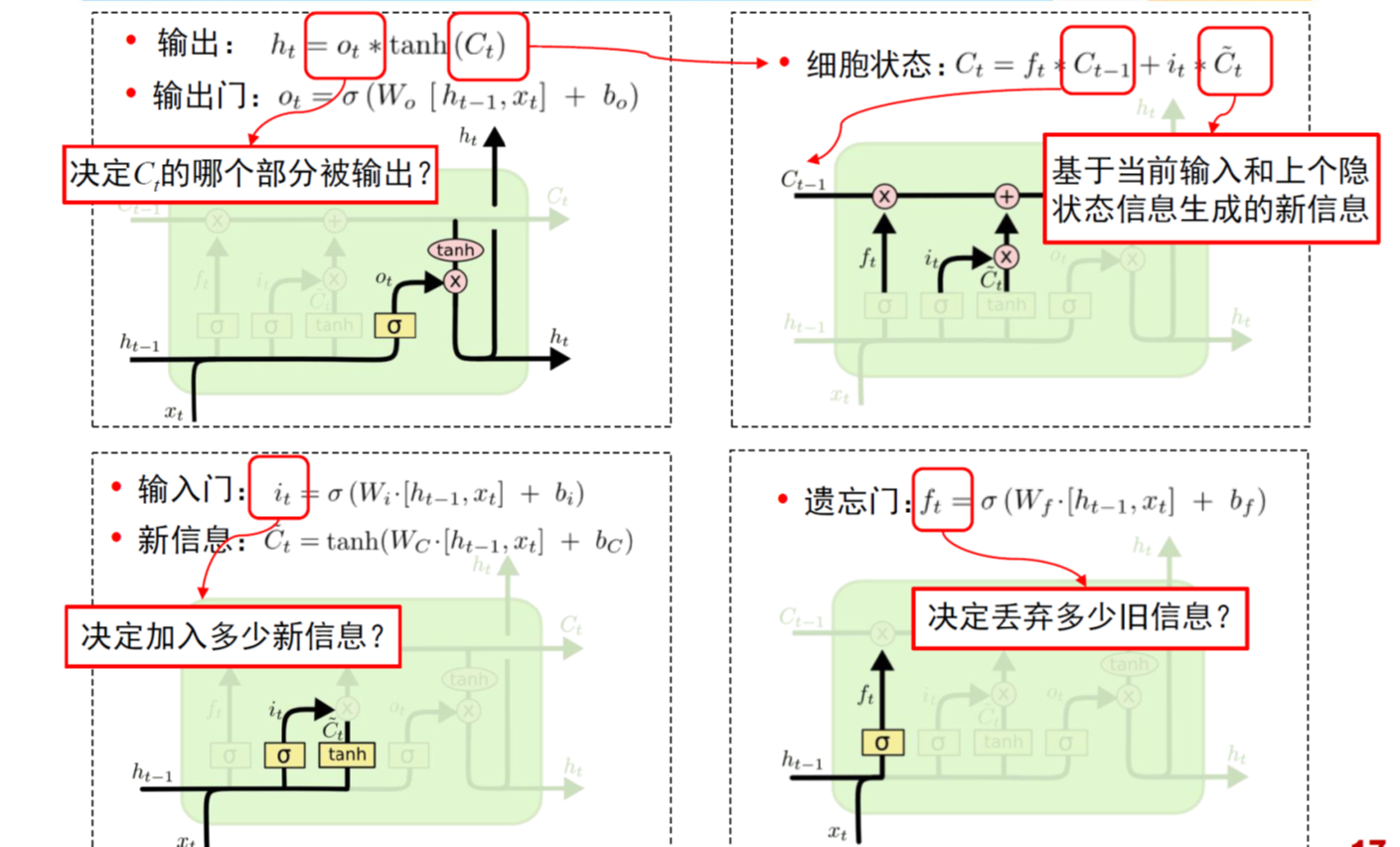
LSTM中有3个控制门:输入门,输出门,记忆门。三个门的元素的值在[0,1]之间。
(1)forget gate:选择忘记过去某些信息:
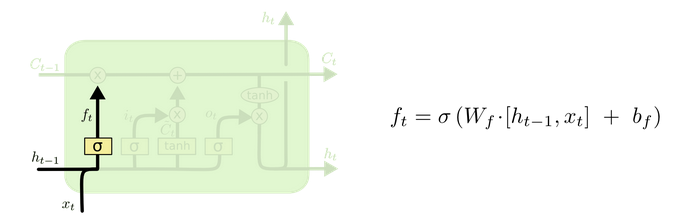
- 遗忘门决定我们要从细胞状态中丢弃什么信息。
- 它查看ht-1(前一个隐藏状态)和xt(当前输入),并为状态Ct-1(上一个状态)中的每个数字输出0和1之间的数字。
- 1代表完全保留,而0代表彻底删除。
(2)input gate:记忆现在的某些信息:
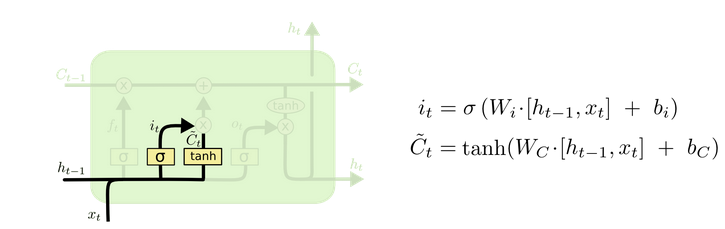
- 首先,输入门的Sigmoid层决定了我们将更新哪些值。
- 然后,一个tanh层创建候选向量C ̃_t,该向量将会被加到细胞的状态中。
- 最后,结合这两个向量来创建更新值。
(3)update memory:将过去与现在的记忆进行合并:
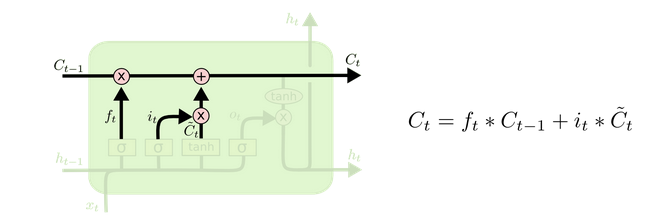
- 现在是时候去更新上一个状态值Ct−1了,将其更新为Ct。
- 将上一个状态值C_(t-1)乘以f_t,以此表达期待忘记的部分。之后将得到的值加上 i_t∗C ̃_t。这个得到的是新的状态值。
(4)output gate:输出
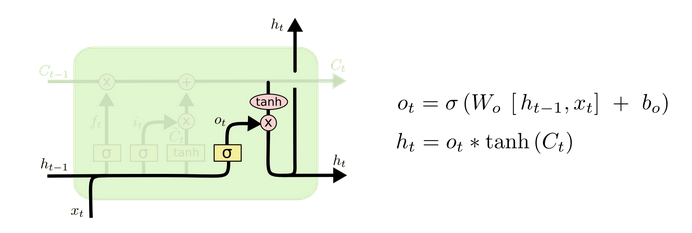
- 输出门决定我们要输出什么, 此输出将基于当前的细胞状态。
- 首先,通过一个sigmoid层,决定了我们要输出细胞状态的哪些部分。
- 然后,将细胞状态通过tanh(将值规范化到-1和1之间),并将其乘以Sigmoid门的输出,至此完成了输出门决定的那些部分信息的输出。
公式总结:
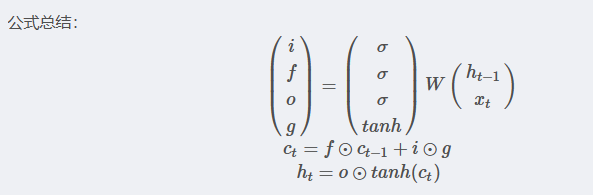
其中,h是隐藏状态,c是记忆单元。
- i是输入门。
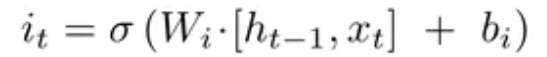
- f是遗忘门。

- o是输出门。
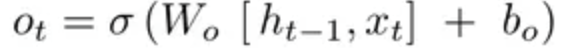
- g是新增信息。这里
 公式中 i 的作用是输入门i 判断新增信息g的各个元素的价值有多大。输入门i 不回不经过考虑就添加新信息,而是会对要添加的信息进行取舍。换句话说,输入门会添加加权后的新信息。
公式中 i 的作用是输入门i 判断新增信息g的各个元素的价值有多大。输入门i 不回不经过考虑就添加新信息,而是会对要添加的信息进行取舍。换句话说,输入门会添加加权后的新信息。
GRU(Gated Recurrent Unit,门控循环单元)
- LSTM和GRU的比较:
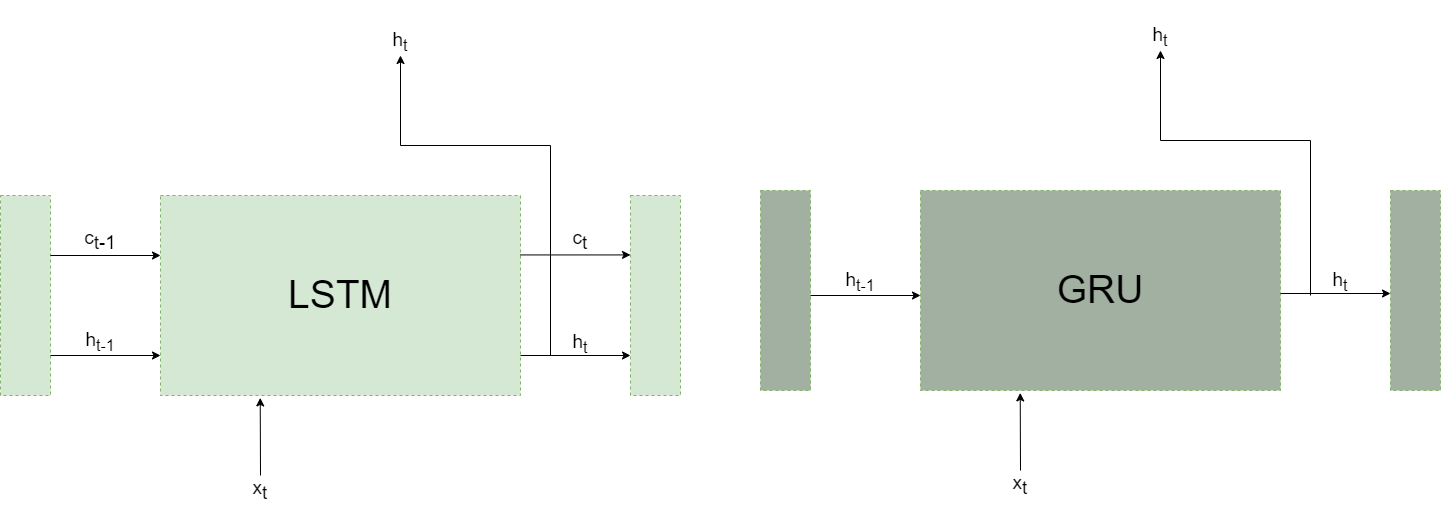
LSTM的记忆单元是私有存储,对其他层不可见。LSTM将必要的信息记录在记忆单元中,并基于记忆单元的信息计算隐藏状态。
GRU中不需要记忆单元这样的额外存储。
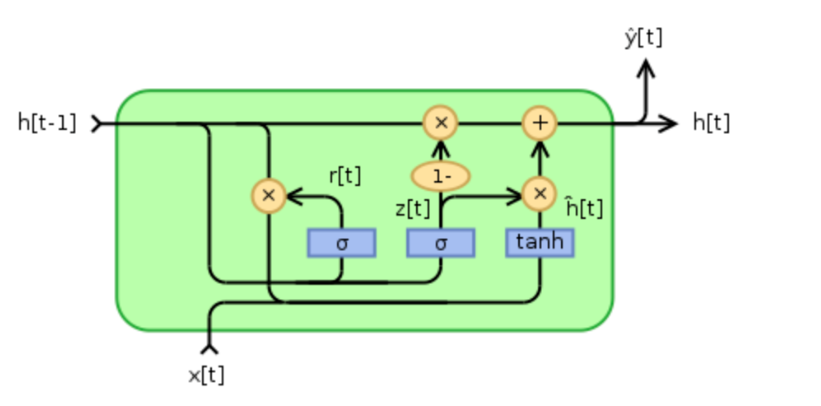
- GRU的计算图图下:
- 公式:
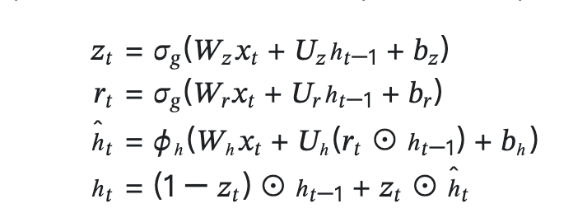
- 其中:
GRU没有记忆单元,只有一个隐藏状态h在时间上传播。这里使用rt 和zt 共两个门(LSTM使用3个门)。
- rt 是reset门:决定在多大程度上“忽略”过去的隐藏状态。根据上面公式3,如果rt 是0,则新的隐藏状态
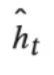 仅取决于输入xt。也就是说过去的隐藏状态将完全被忽略。
仅取决于输入xt。也就是说过去的隐藏状态将完全被忽略。 - zt 是update门:它扮演了LSTM门的forget门和input门的两个角色。上面公式4的
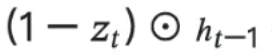 部分充当forget门的功能。根据这个计算,从过去的隐藏状态中删除应该被遗忘的信息。
部分充当forget门的功能。根据这个计算,从过去的隐藏状态中删除应该被遗忘的信息。 部分充当input门的功能,对新增的信息进行加权。
部分充当input门的功能,对新增的信息进行加权。 - 综上,GRU是简化了LSTM的架构,与LSTM相比,可以减少计算成本和参数。
应用:基于RNN生成文本
使用语言模型生成文本

生成下一个单词:
- 选择概率最高的单词。
- 根据概率分布选择,概率高的单词容易被选到,概率低的单词难以被选择。
seq2seq
时序数据:文本数据、音频数据、视频数据等。
seq2seq:将一种时序数据转化为另一种时序数据。
seq2seq模型也成为Encoder-Decoder模型。
- Encoder(编码):基于某种既定规则的信息转换。
- Decoder(解码):将被编码的信息还原到它的原始状态。
编码器
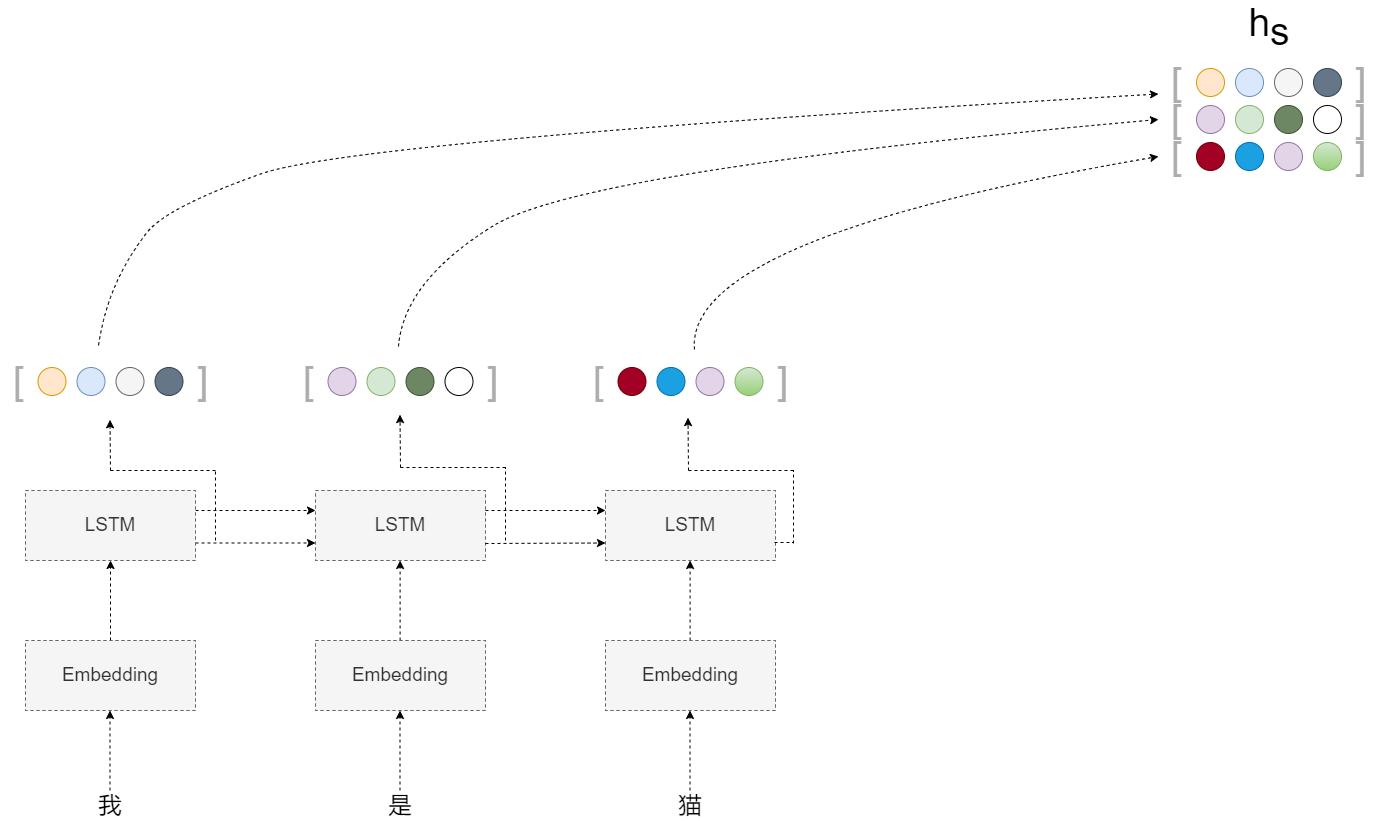
注意,编码器的LSTM是从左到右阅读句子的。因此上图中单词“猫”对应向量编码了“我”,“是”,这两个单词的信息。如果考虑向量能够更均衡地包含单词“猫”周围的信息。
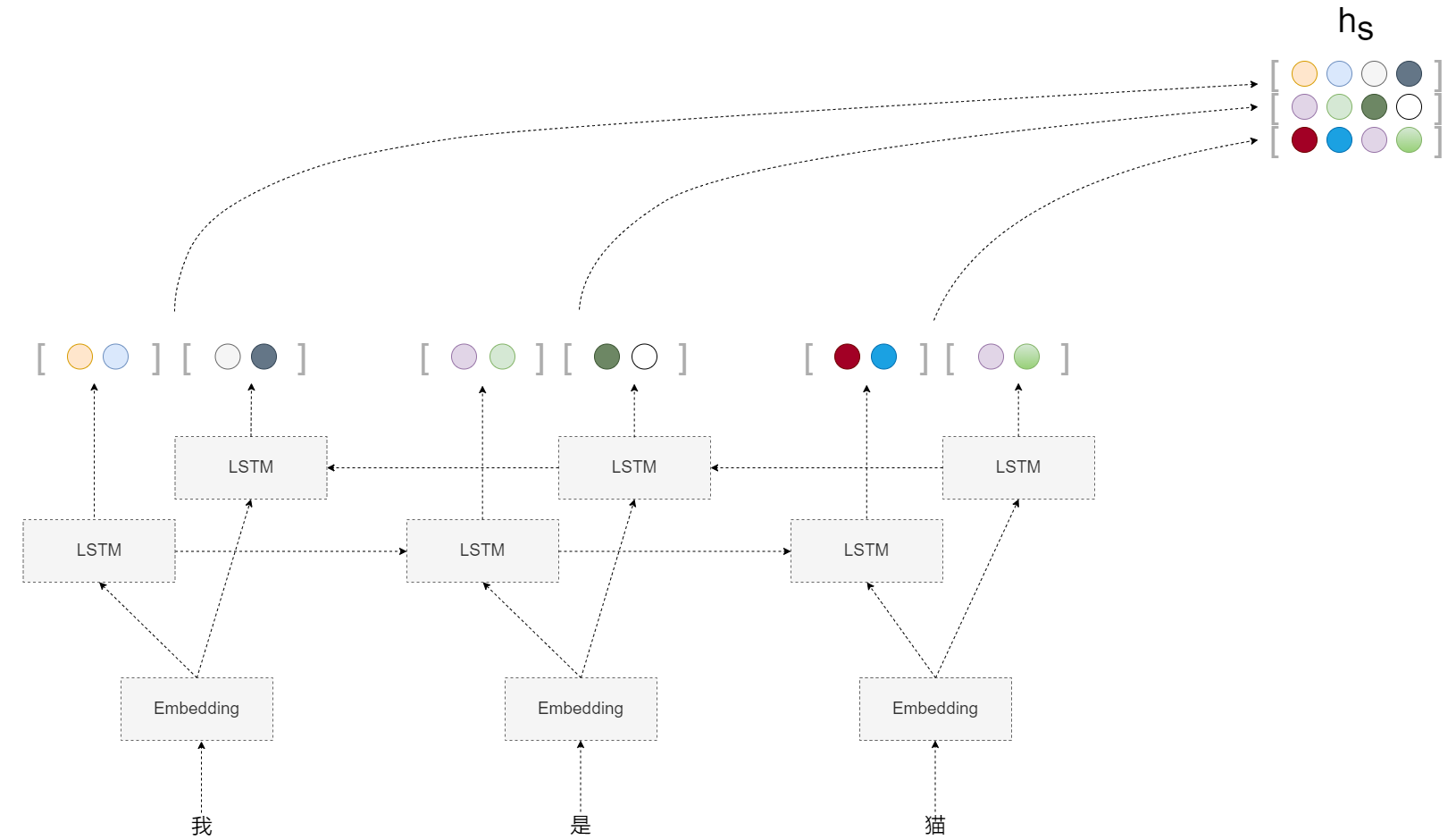
为此,可以让LSTM从两个方向进行处理,这就是名为双向LSTM的技术,如下:
解码器
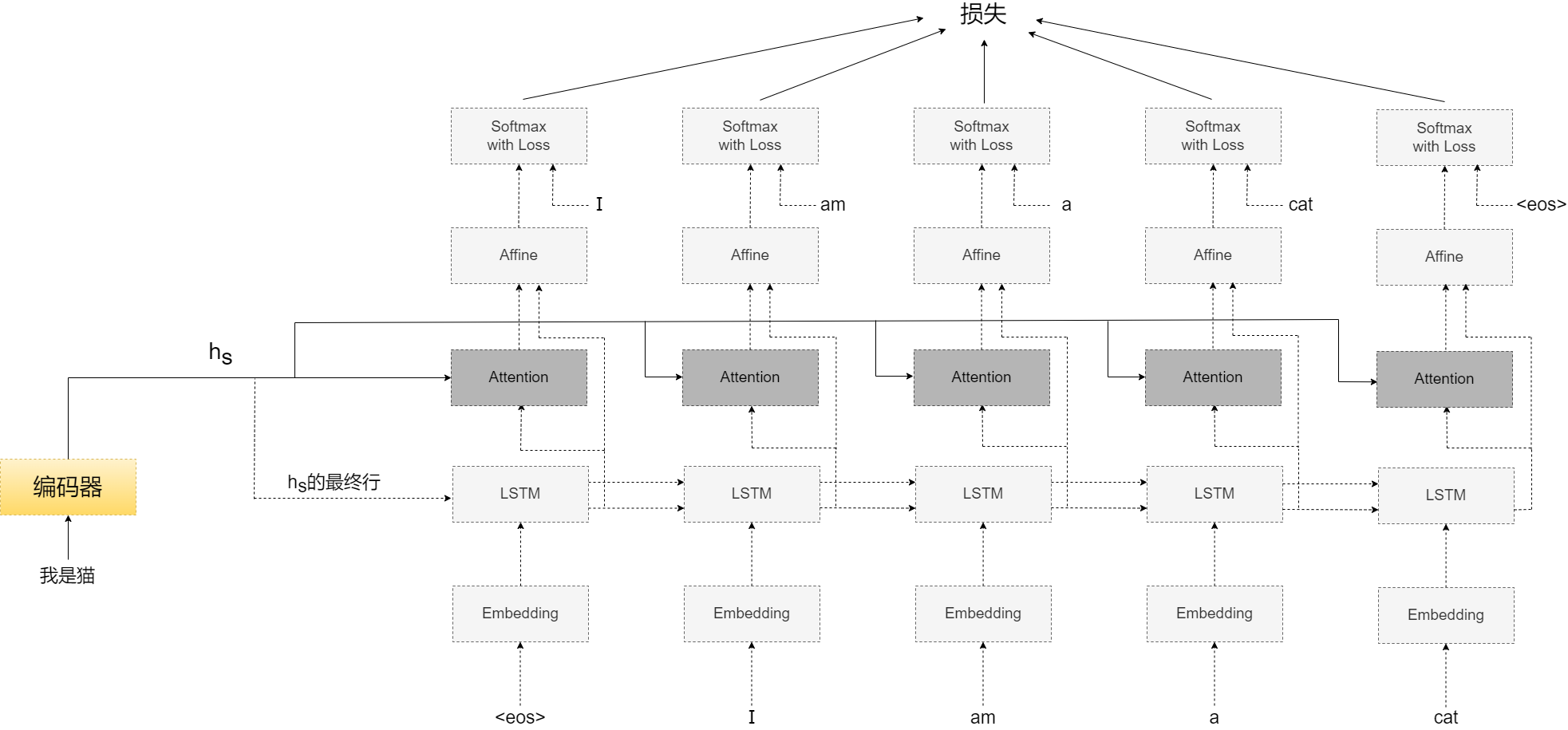
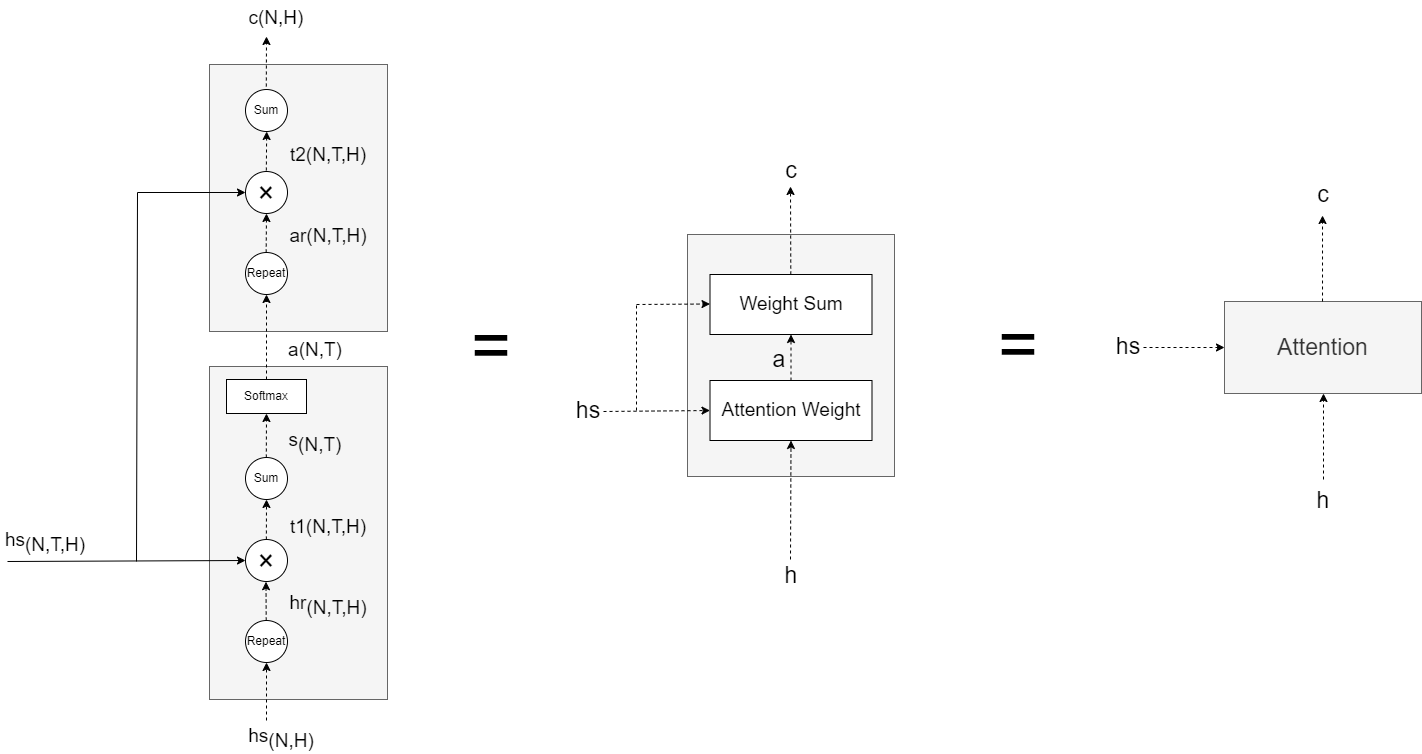
如上所示,编译器的输出hs 被输出到各个时刻的Attention层。
Attention:
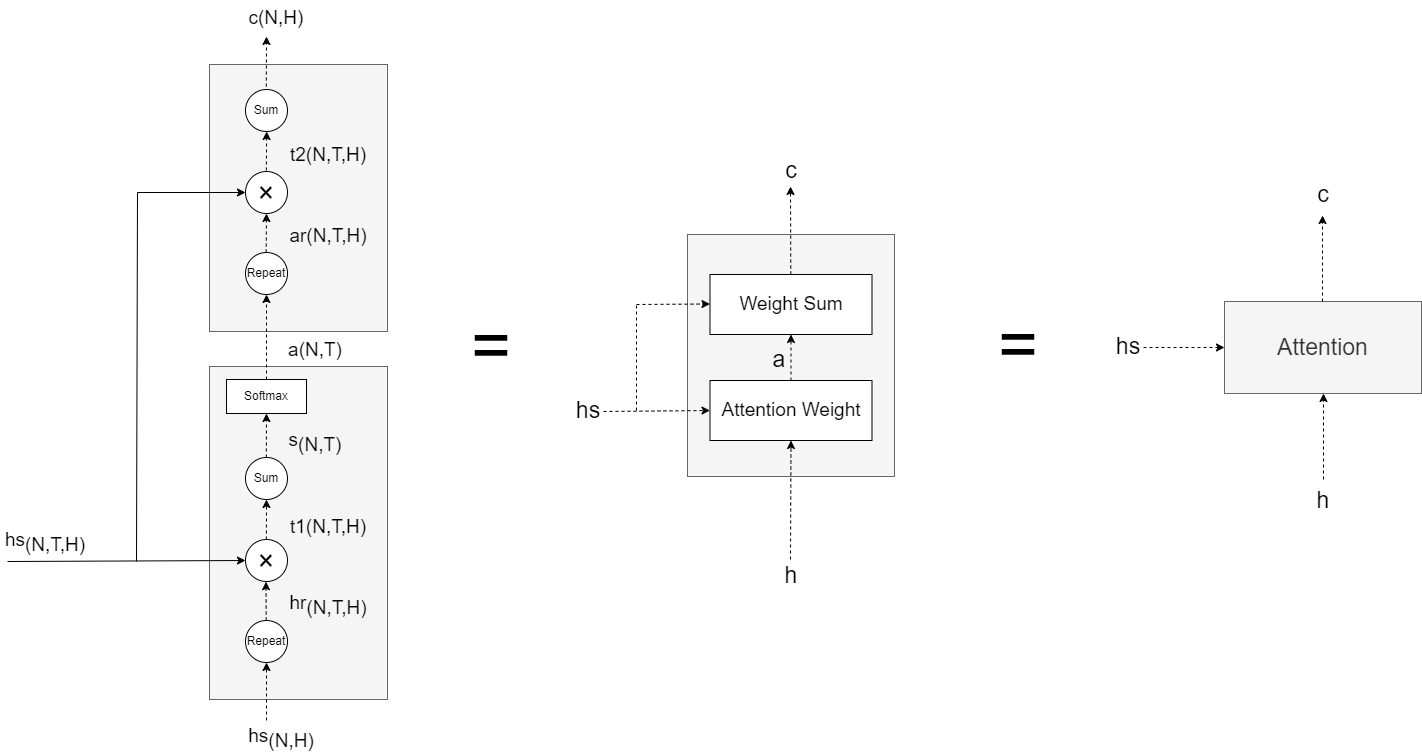
将时序方向(即横向方向)上扩展的多个Attention层整体实现为Time Attention层,如下:

解码器的实现:
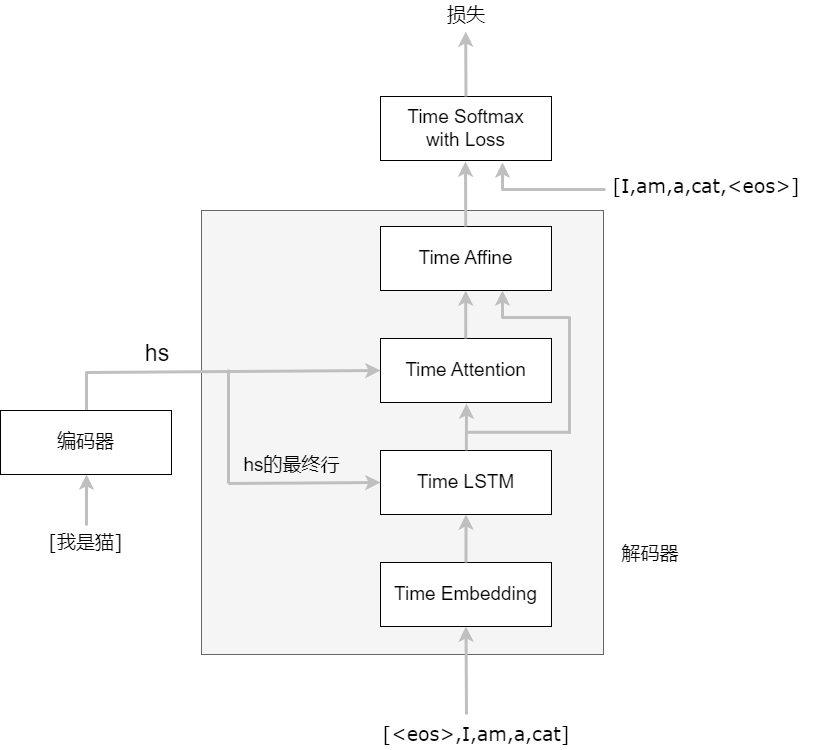
解码器各层解释:
- Softmax with Loss:
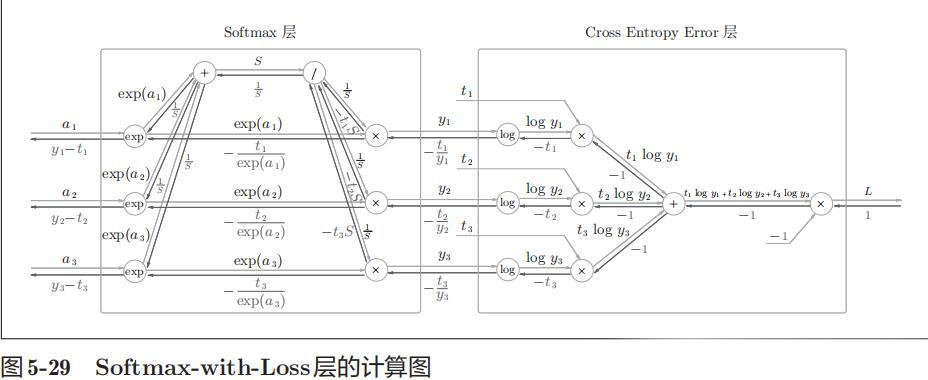
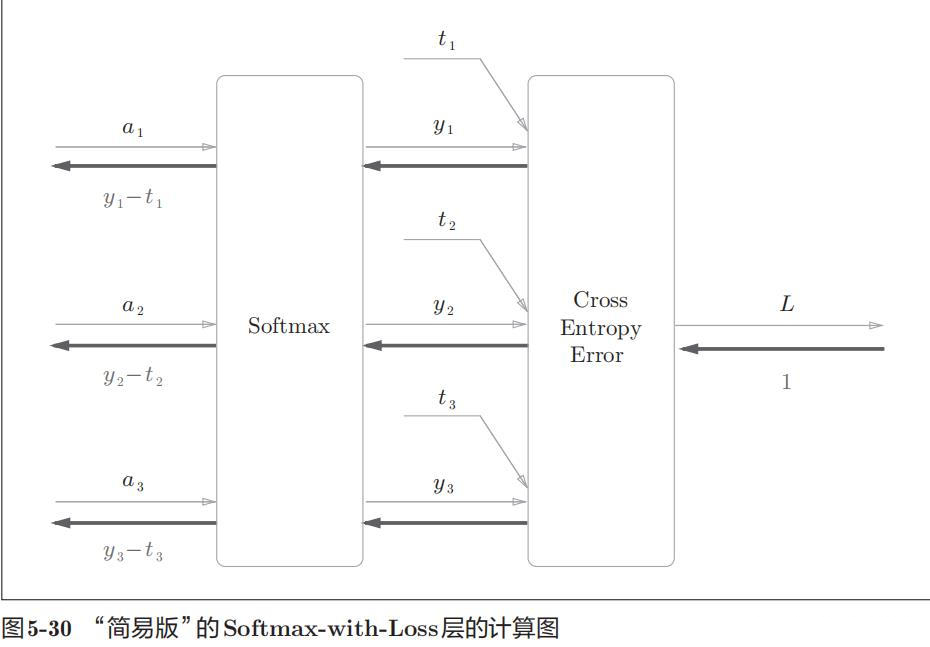
- Affine:
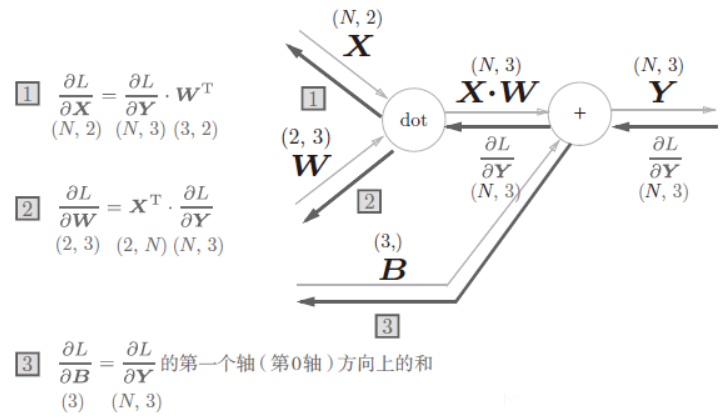
- **Attention:**注意力层。
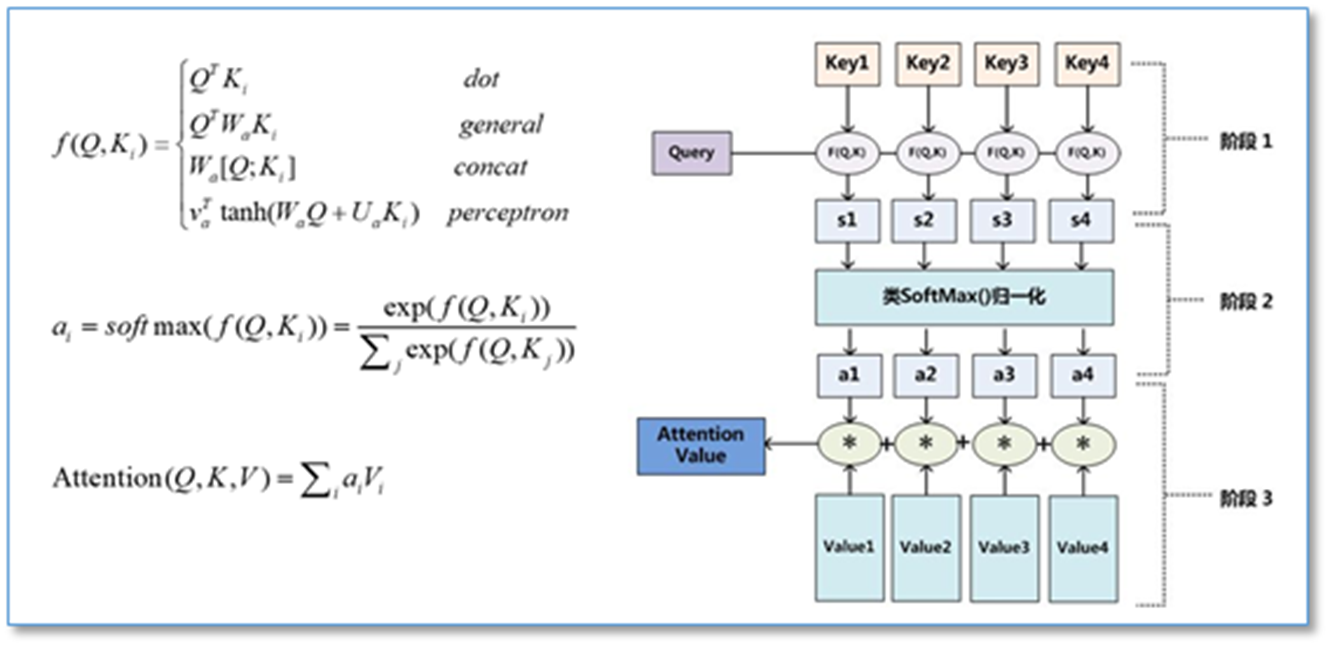
- 相似度计算:计算query(查询)与每个key(键)的相似度。常用的相似度函数包括点积、拼接、感知机等。
- 权重归一化:使用softmax函数对相似度得分进行归一化,得到每个key对应的权重。
- 加权求和:将权重与相应的value(值)进行加权求和,得到最终的Attention输出。
在计算attention时主要分为三步:第一步是将query和每个key进行相似度计算得到权重,常用的相似度函数有点积,拼接,感知机等;第二步一般是使用一个softmax函数对这些权重进行归一化;最后将权重和相应的键值value进行加权求和得到最后的attention。当Q=K=V时就是自注意力。
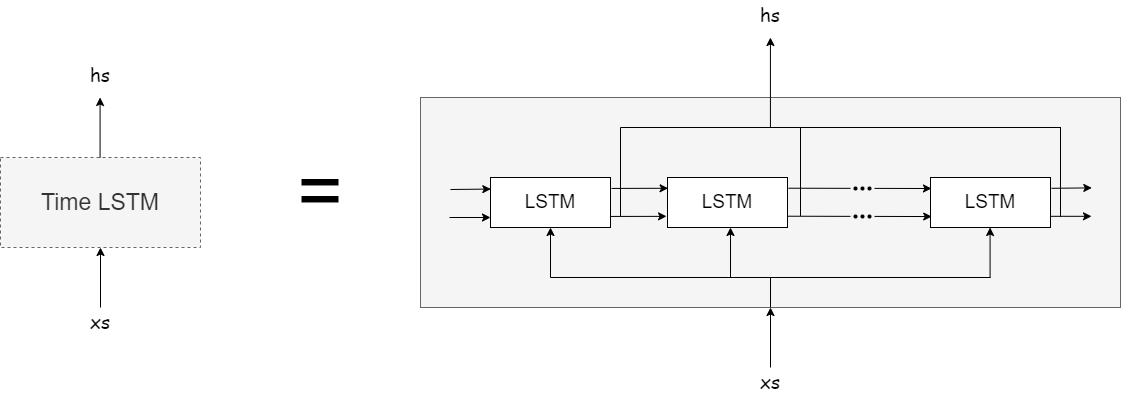
- LSTM:
- **Embedding:**从权重参数中抽取“单词ID对应行(向量)”的层。用于将离散的输入(如单词、字符、类别等)转换为固定大小的连续向量,即嵌入向量(embedding vectors)。
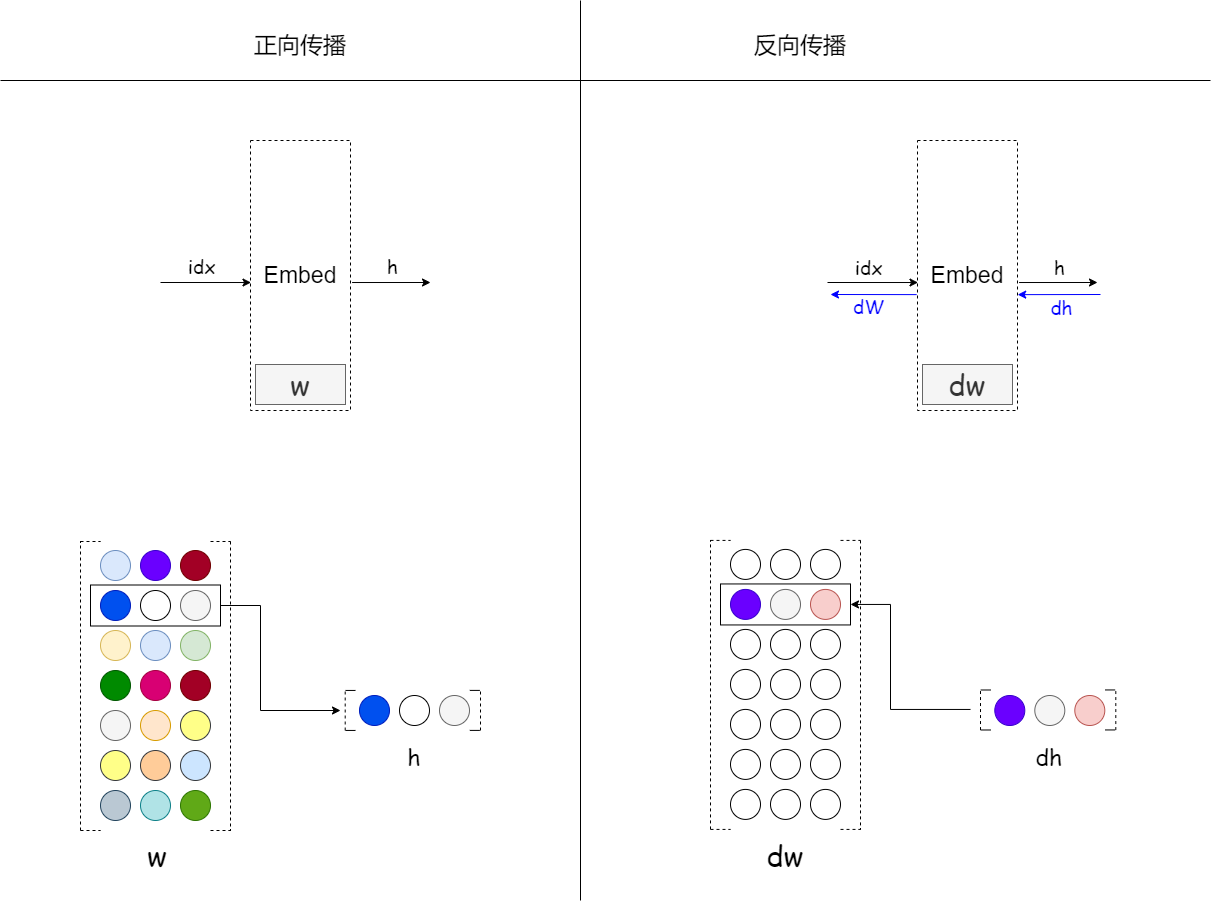
在加深层的时候(非时序方向层),有一个重要的技巧是残差连接(skip connection,也称为residual connection 或 shortcut),如下:
所谓残差连接,就是指“跨层连接”。在残差连接的连接处,有两个输出被相加。加法在反向传播时“按原样”传播梯度,所以残差连接中的梯度可以不受任何影响地传播到前一个层。这样一来,即便加深了层,梯度也能被正常传播,而不会发生梯度消失(或者梯度爆炸)。
- 在时间方向上,RNN层的反向传播的梯度消失或者梯度爆炸问题,可以通过LSTM、GRU等Gated RNN应对,梯度爆炸可以通过梯度剪裁应对。
- 在深度方向上,RNN的梯度消失或者梯度爆炸问题,用残差连接很有效。
Tranformer
Transformer结构举例
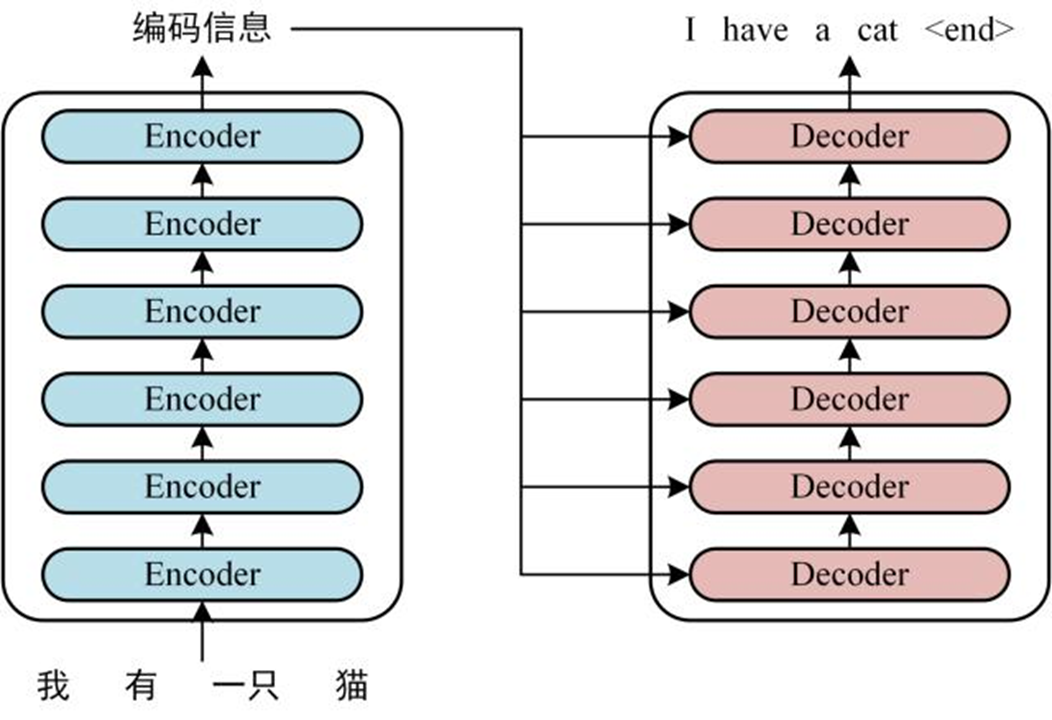
下图是 Transformer 用于中英文翻译的整体结构。可以看到 Transformer 由 Encoder 和 Decoder 两个部分组成,Encoder 和 Decoder 都包含 6 个 block。
第一步:
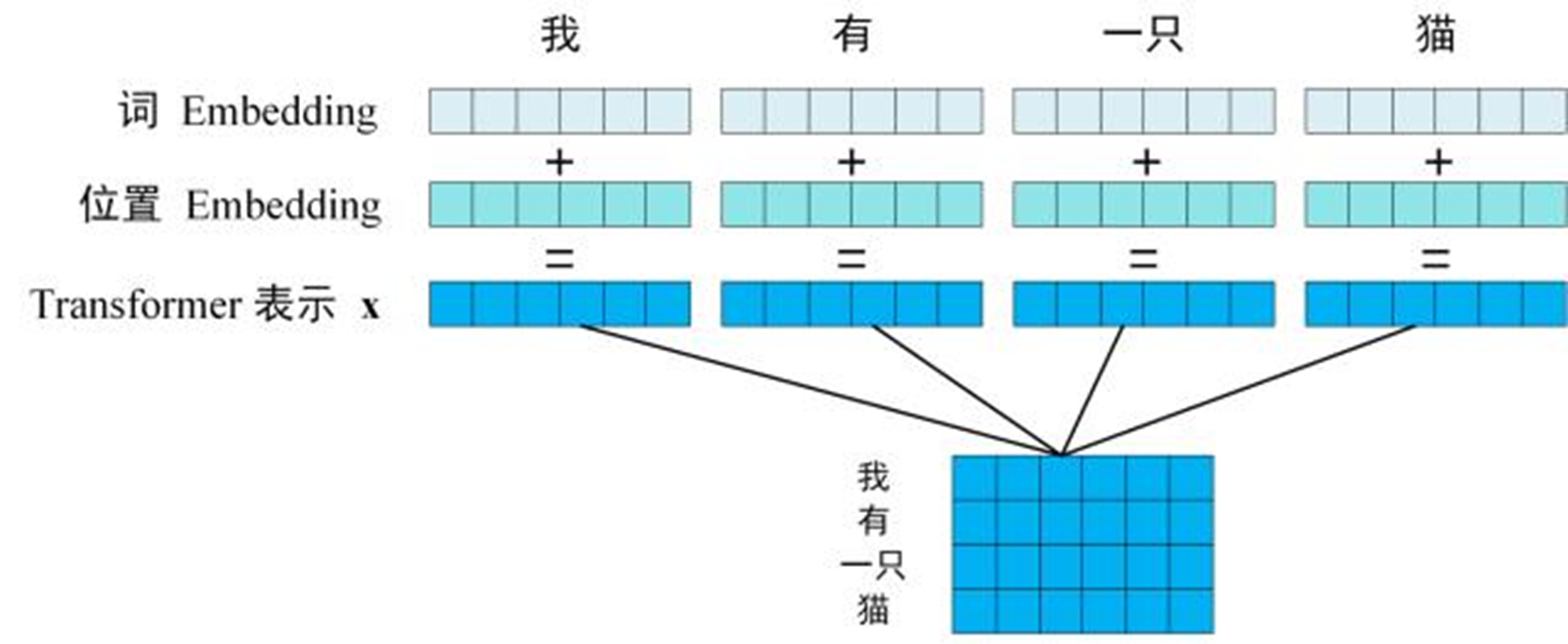
获取输入句子的每一个单词的表示向量 X,X由单词的 Embedding 和单词位置的 Embedding 相加得到。
第二步:
将得到的单词表示向量矩阵 (每一行是一个单词的表示 x) 传入 Encoder 中,经过 6 个 Encoder block 后可以得到句子所有单词的编码信息矩阵 C。单词向量矩阵用 X(n×d)表示, n 是句子中单词个数,d 是表示向量的维度 (论文中 d=512)。每一个 Encoder block 输出的矩阵维度与输入完全一致。
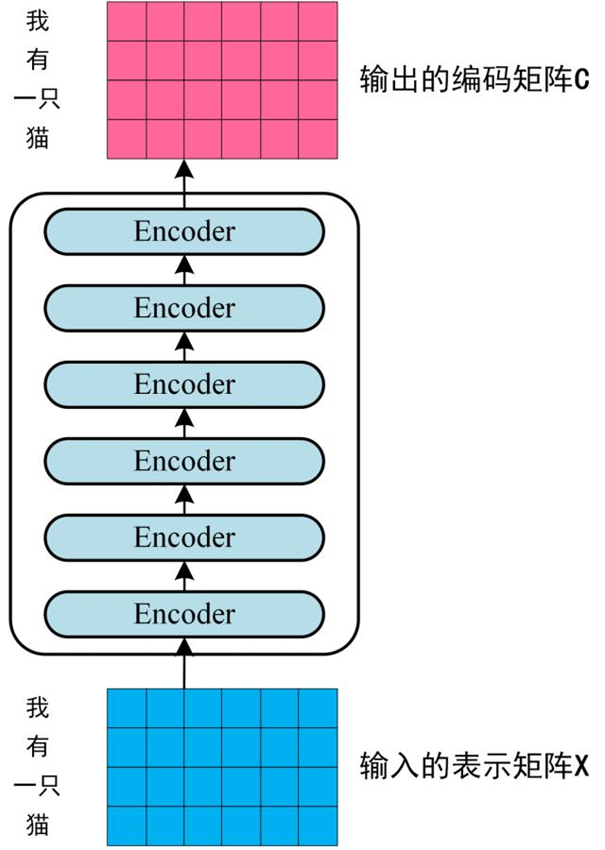
第三步:
将 Encoder 输出的编码信息矩阵 C传递到 Decoder 中,Decoder 依次会根据当前翻译过的单词 1~ i翻译下一个单词 i+1,如下图所示。在使用的过程中,翻译到单词 i+1 的时候需要通过 Mask (掩盖) 操作遮盖住 i+1 之后的单词。
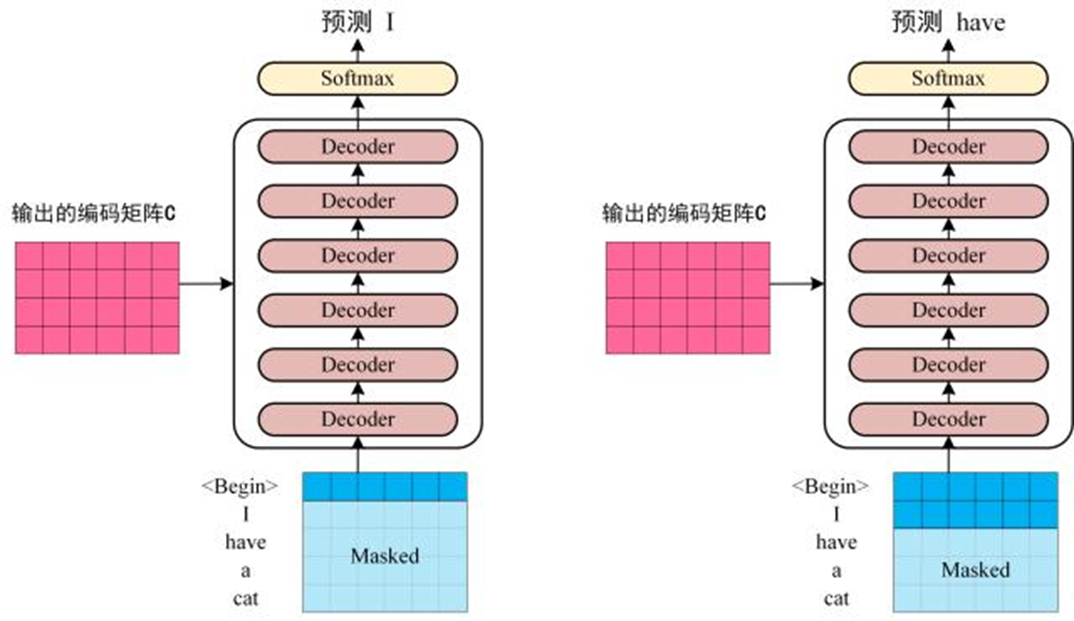
Decoder 接收了 Encoder 的编码矩阵 C,然后首先输入一个翻译开始符 “”,预测第一个单词 “I”;然后输入翻译开始符 “” 和单词 “I”,预测单词 “have”,以此类推。
RNN(LSTM/GRU)缺点
RNN需要基于上一时刻的计算结果逐步进行计算,因此(基本)不可能在时间方向上并行计算RNN。在使用了GPU的并行计算环境下进行深度学习时,这一点会成为很大的瓶颈。
Transformer不用RNN,而用Attention进行处理。其中使用了Self-Attention技巧。
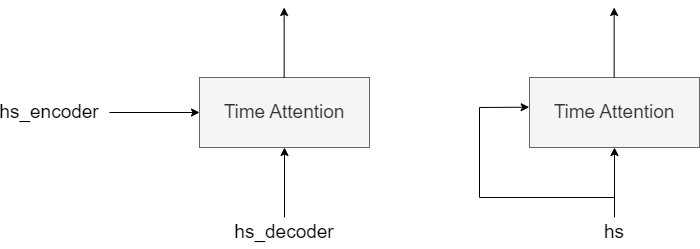
如上左图,Time Attention层的两个输入中输入的是不同的时序数据。
如上右图,Self-Attention的两个输入中输入的是同一个时序数据。
Transformer的层结构
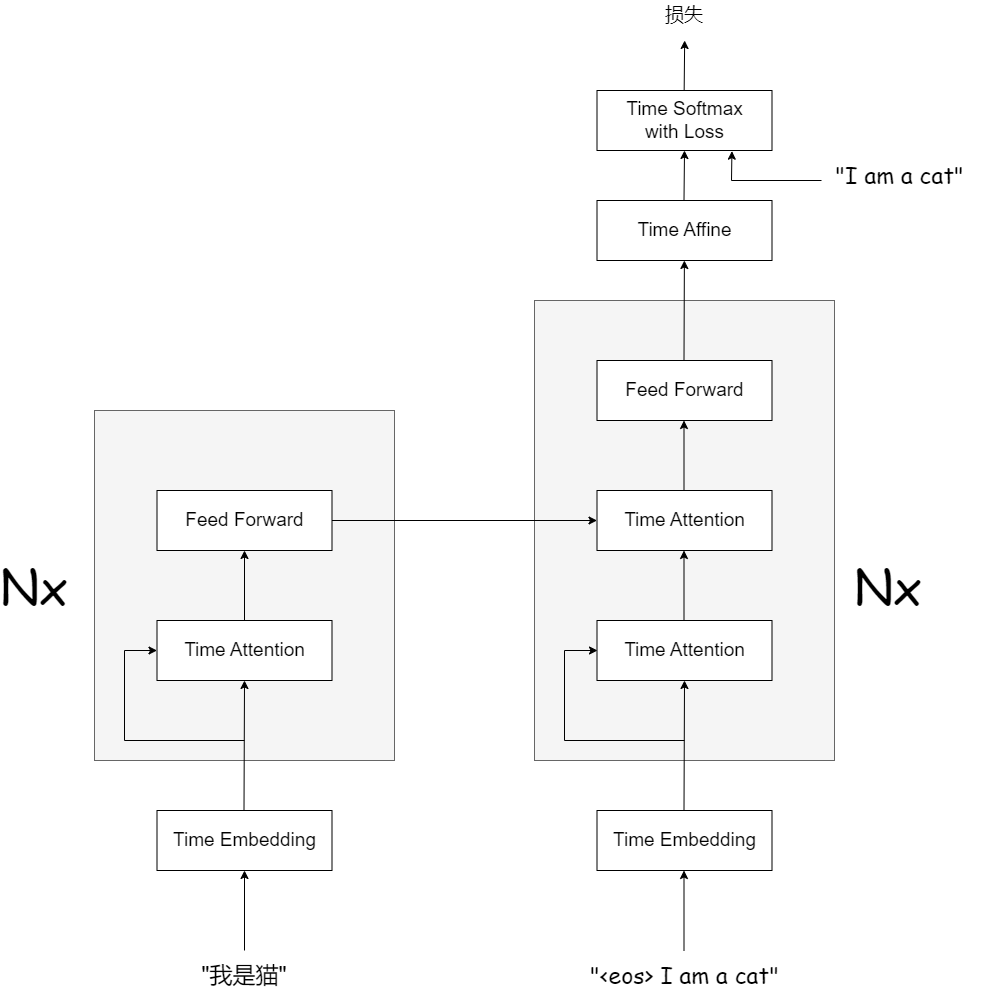
由上图可知,编码器和解码器两者都使用了Self-Attention。
Feed Forward层表示前馈神经网络。
途中Nx表示灰色背景包围的元素被堆叠了N次。
使用Transformer可以控制计算量,充分利用GPU并行计算带来的好处。与GNMT相比,Transformer的学习时间大幅减少,在精度方面也有提高。
理解Attention
【注意力机制】,顾名思义,主要作用是让神经网络把“注意力”放在一部分输入上,即:区分输入的不同部分对输出的影响。
我们知道,一个字/词在一篇文本中表达的意思通常与它的上下文有关。比如:光看“鹄”字,可能会觉得很陌生,而看到它的上下文“鸿鹄之志”后,就对它立马熟悉了起来。因此,字/词的上下文信息有助于增强其语义表示。
同时,上下文中的不同字/词对增强语义表示所起的作用往往不同。比如在上面这个例子中,“鸿”字对理解“鹄”字的作用最大,而“之”字的作用则相对较小。为了有区分地利用上下文字信息增强目标字的语义表示,就可以用到Attention机制。
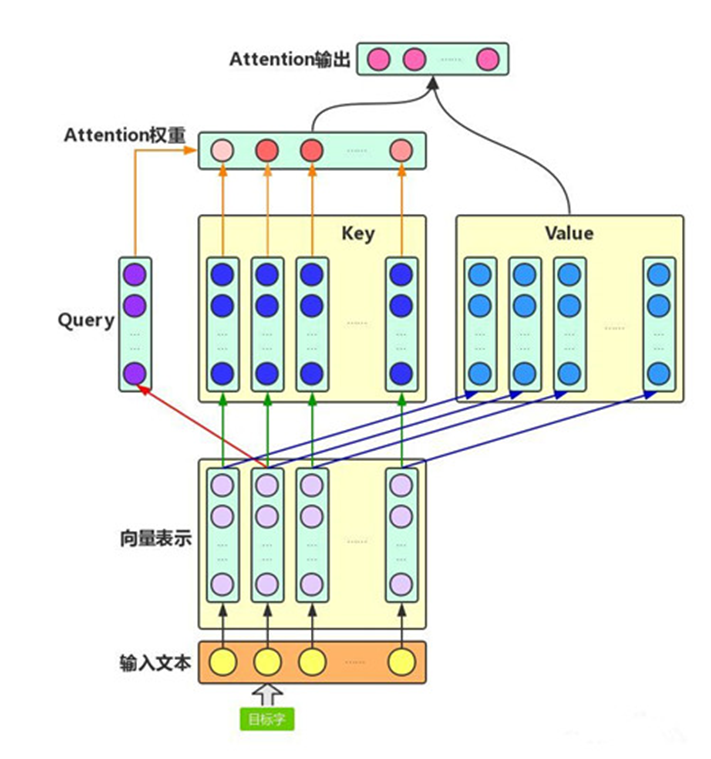
Attention机制主要涉及到三个概念:Query、Key和Value。在上面增强字的语义表示这个应用场景中,目标字及其上下文的字都有各自的原始Value,Attention机制将目标字作为Query、其上下文的各个字作为Key,并将Query与各个Key的相似性作为权重,把上下文各个字的Value融入目标字的原始Value中。
如下图所示,Attention机制将目标字和上下文各个字的语义向量表示作为输入,首先通过线性变换获得目标字的Query向量表示、上下文各个字的Key向量表示以及目标字与上下文各个字的原始Value表示,然后计算Query向量与各个Key向量的相似度作为权重(权重和为1),最后加权融合目标字的Value向量和各个上下文字的Value向量作为Attention的输出,即:目标字的增强语义向量表示。
BERT(Bidirectional Encoder Representations from Transformers)
被提出之后,作为一个Word2Vec的替代者,其在NLP领域的11个方向大幅刷新了精度,是近年来最有突破的技术之一。
BERT
BERT主要特点
• 使用了Transformer 作为算法的主要框架,Transformer能更彻底的捕捉语句中的双向关系;
• 使用了Mask Language Model(MLM) 和 Next Sentence Prediction(NSP) 的多任务训练目标;
• 使用更强大的机器训练更大规模的数据,使BERT的结果达到了全新的高度,并且Google开源了BERT模型,用户可以直接使用BERT作为Word2Vec的转换矩阵并高效的将其应用到自己的任务中。
• BERT本质上是通过在海量的语料的基础上运行自监督学习方法为单词学习一个好的特征表示,所谓自监督学习是指在没有人工标注的数据上运行的监督学习。
• 在以后特定的NLP任务中,我们可以直接使用BERT的特征表示作为该任务的词嵌入特征。
• 所以BERT提供的是一个供其它任务迁移学习的模型,该模型可以根据任务微调或者固定参数进行特征提取。
BERT系列模型的改进
•**引入常识:**ERNIE1.0/ERNIE(THU)/ERNIE2.0(简称为“ERNIE系列”)
•**引入多任务学习:**MTDNN/ERNIE2.0
•**基于生成任务的改进:**MASS/UNILM
•**不同的mask策略:**WWM/ERNIE系列/SpanBERT
•**精细调参:**RoBERTa
BERT整体框架
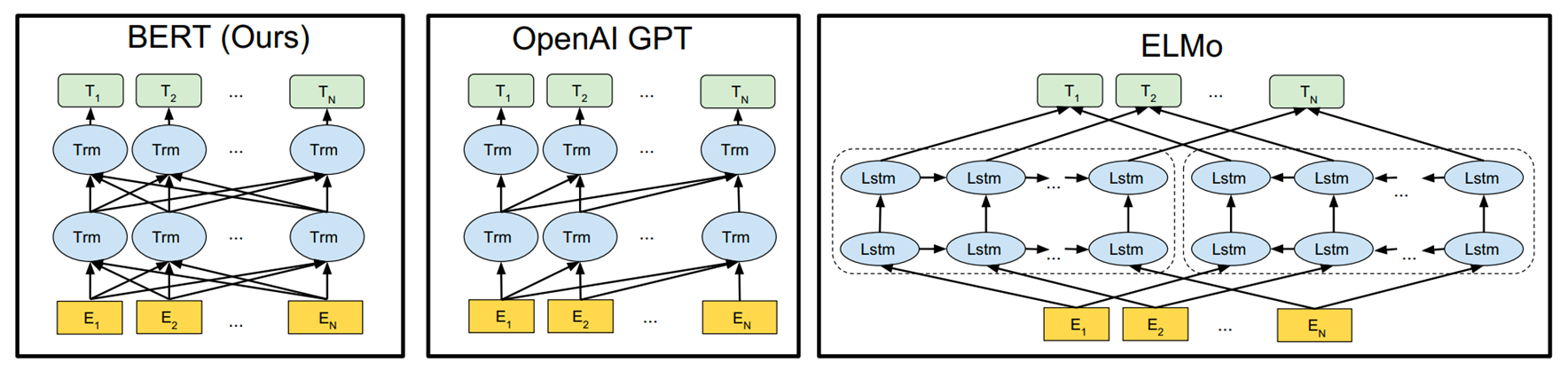
BERT 的特征抽取结构为双向的 Transformer,简单来说,就直接采用了 Attention is all you need 中的 Transformer Encoder Block 结构,是一种自编码的预训练方式(GPT采用单向的Transformer,是一种自回归的预训练方式)。BERT提出了两种预训练任务来对其模型进行预训练。
BERT的两个版本
BERT提供了简单和复杂两个模型,对应的超参数分别如下:
BERT-base: L=12,H=768,A=12,参数总量110M;
BERT-large: L=24,H=1024,A=16,参数总量340M;
在上面的超参数中,L表示网络的层数(即Transformer blocks的数量),A表示Multi-Head Attention中self-Attention的数量。
BERT-base为了和OpenAI GPT进行对比,所以模型大小与OpenAI GPT设置一致,不同的在于OpenAI GPT使用left-to-right的self-attention,而BERT使用双向self-attention。
BERT的预训练Task1:MLM
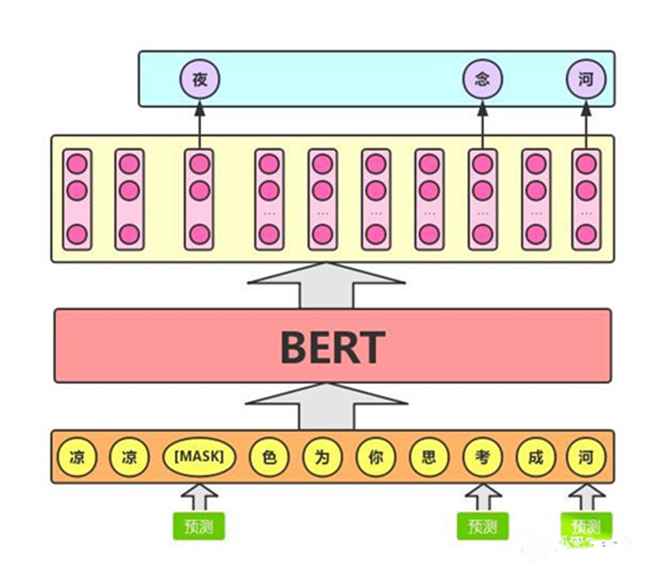
由于BERT需要通过上下文信息,来预测中心词的信息,同时又不希望模型提前看见中心词的信息,因此提出了一种 **Masked Language Model **的预训练方式,即随机从输入语料上 mask 掉一些单词,然后通过的上下文预测该单词,类似于一个完形填空任务。
在预训练任务中,15%的单词会被mask,这15%的单词中,80%的时候会直接替换为 [Mask] ,10%的时候将其替换为其它任意单词,10%的时候会保留原始token。

BERT的预训练Task2:NSP
因为涉及到QA和NLI之类的任务,增加了第二个预训练任务Next Sentence Prediction,目的是让模型理解两个句子之间的联系。
训练的输入是句子A和B,B有一半的几率是A的下一句,输入这两个句子,模型预测B是不是A的下一句。预训练的时候可以达到97-98%的准确度。
BERT的输入
bert的输入可以是单一的一个句子或者是句子对,实际的输入值包括了三个部分,分别是token embedding,segment embedding和position embedding,这三个部分相加形成了最终的bert输入向量。
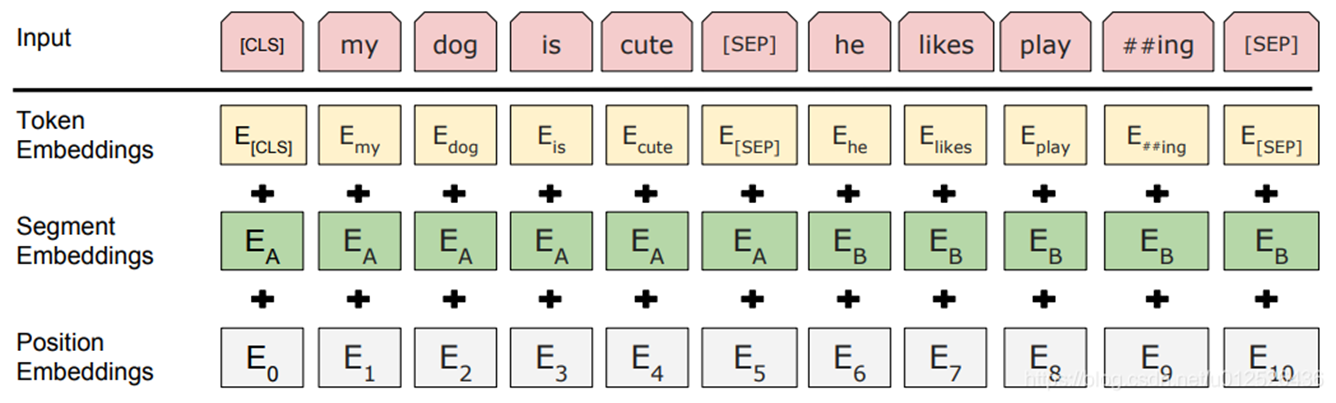
**Token Embeddings:**是词向量,第一个单词是CLS标志,可用于分类任务,对于非分类问题则忽略。
**Segment Embeddings:**用来区别两种句子,因为预训练不光做LM还要做以两个句子为输入的分类任务。
**Position Embeddings:**和之前Transformer的位置向量不一样,不是三角函数而是学习出来的,支持最长序列长度为512个tokens。
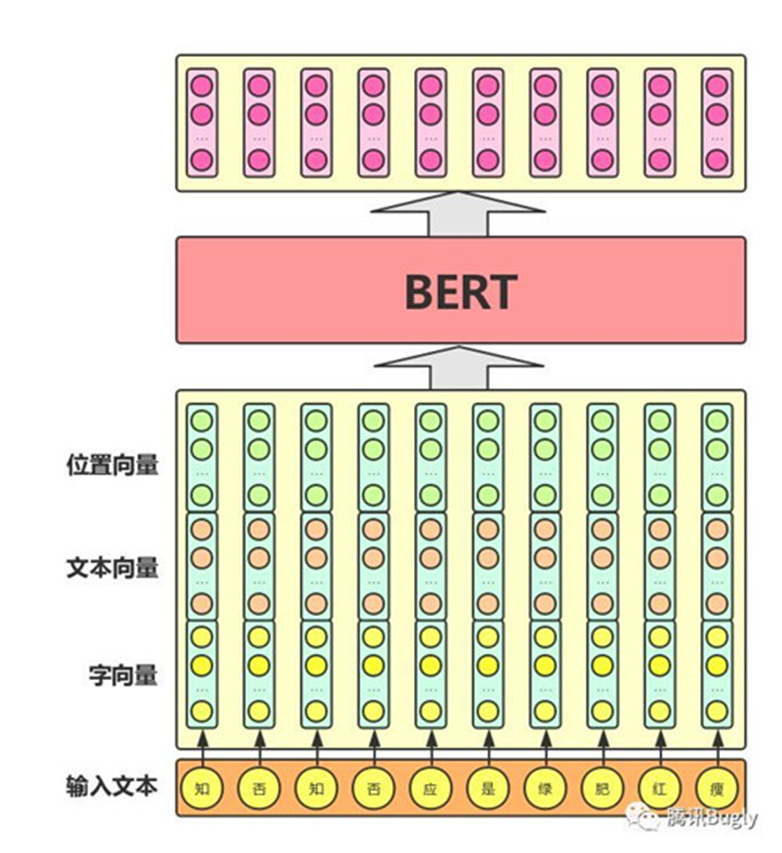
BERT的整体的输入/输出
BERT模型预训练文本语义表示的过程就好比我们在本科阶段学习高数、线性代数、概率论与数理统计等各门基础学科,夯实基础知识。
而模型在特定NLP任务中的参数微调就相当于我们在研究生期间基于已有基础知识、针对所选专业作进一步强化,从而获得能够应用于实际场景的专业技能。
从右图可以看出,BERT模型将字向量、文本向量(该向量的取值在模型训练过程中自动学习,用于刻画文本的全局语义信息,并与单字/词的语义信息相融合)和位置向量的加和作为模型输入;模型输出则是输入各字对应的融合全文语义信息后的向量表示。
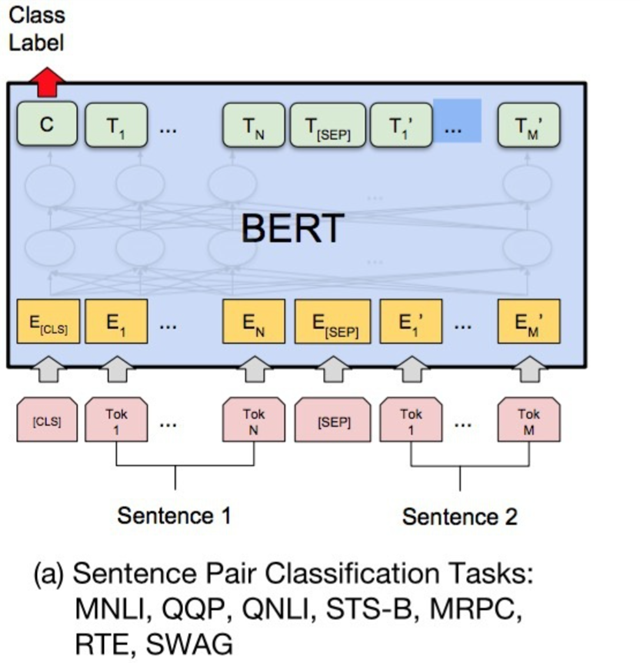
微调整(Fine-tuning)
在海量无标签语料上训练完BERT之后,便可以将其应用到NLP的各个任务中了。
微调任务主要包括以下四类:
(a)基于句子对的分类任务
- **MNLI:**给定一个前提 (Premise) ,去推断假设 (Hypothesis) 与前提的关系。该任务的关系分为三种,蕴含关系(Entailment)、矛盾关系(Contradiction) 以及中立关系 (Neutral)。所以这个问题本质上是一个分类问题。
- **QQP:**判断两个问题句是否表示的是一样的意思。
- QNLI:用于判断文本是否包含问题的答案,类似于我们做阅读理解定位问题所在的段落。
- STS-B:预测两个句子的相似性,包括5个级别。
- **MRPC:**也是判断两个句子是否是等价的。
- **SWAG:**从四个句子中选择最有可能为前句下文的那个。
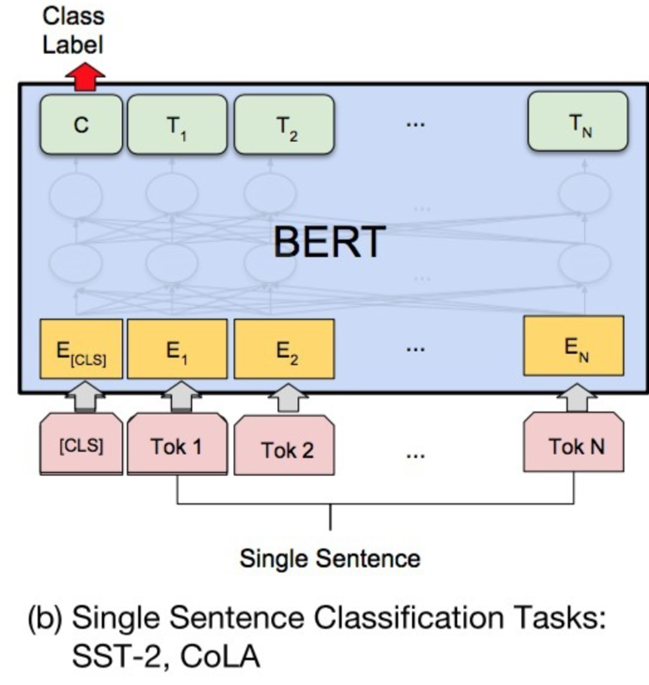
(b)基于单个句子的分类任务
- **SST-2:**电影评价的情感分析
- **CoLA:**对一个给定句子,判定其是否语法正确
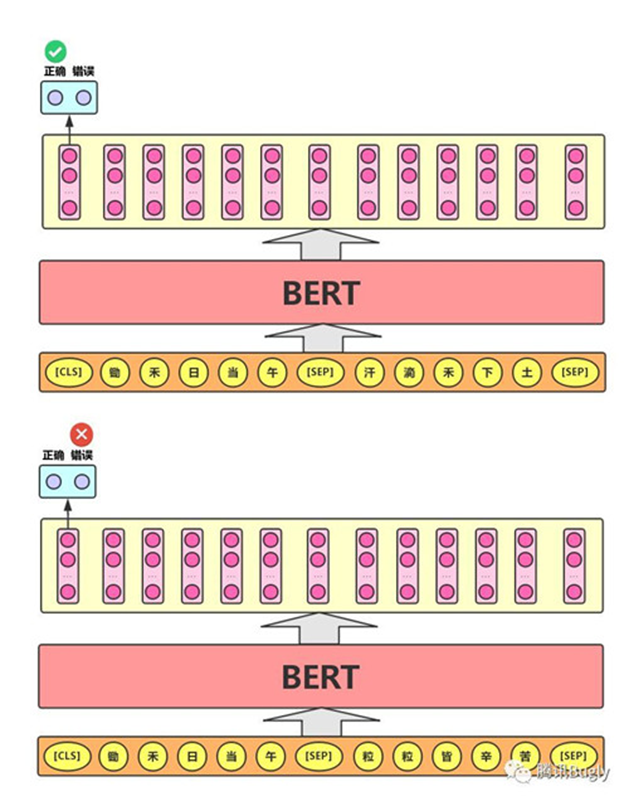
- 对于GLUE数据集的分类任务(MNLI,QQP,QNLI,SST-B,MRPC,RTE,SST-2,CoLA),BERT的微调方法是根据[CLS]标志生成一组特征向量,并通过一层全连接进行微调。损失函数根据任务类型自行设计,例如多分类的softmax或者二分类的sigmoid。
(c)问答任务
- SQuADv1.1:给定一个句子(通常是一个问题)和一段描述文本,输出这个问题的答案,类似于做阅读理解的简答题。
- 如右图,SQuAD的输入是问题和描述文本的句子对。输出是特征向量,通过在描述文本上接一层激活函数为softmax的全连接来获得输出文本的条件概率。
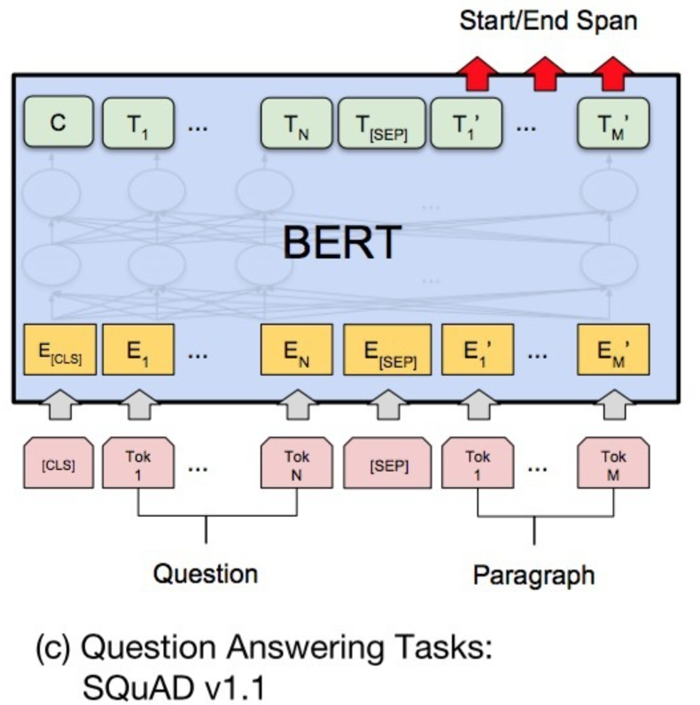
(d)命名实体识别
- CoNLL-2003NER:判断一个句子中的单词是不是Person,Organization,Location,Miscellaneous或者other(无命名实体)。
- 微调CoNLL-2003NER时将整个句子作为输入,在每个时间片输出一个概率,并通过softmax得到这个Token的实体类别标签。

BERT模型压缩方法
1、剪枝——即训练后从网络中去掉不必要的部分
•包括权重大小剪枝、注意力头剪枝、网络层以及其他部分的剪枝等。
2、权重因子分解——通过将参数矩阵分解成两个较小矩阵的乘积来逼近原始参数矩阵
•权重因子分解既可以应用于输入嵌入层(这节省了大量磁盘内存),也可以应用于前馈/自注意力层的参数(为了提高速度)
3、知识蒸馏——又名「Student Teacher」
•知识蒸馏的本质是让超大线下 teacher model来协助线上student model的training,而不是从头学习一个小模型。 一些方法还将BERT 蒸馏成如LSTMS 等其他各种推理速度更快的架构。另外还有一些其他方法不仅在输出上,还在权重矩阵和隐藏的激活层上对 Teacher 知识进行更深入的挖掘。
**4、权重共享——模型中的一些权重与模型中的其他参数共享相同的值 **
•例如,ALBERT 对 BERT 中的每个自注意力层使用相同的权重矩阵。
5、量化——截断浮点数,使其仅使用几个比特(这会导致舍入误差)
•模型可以在训练期间,也可以在训练之后学习量化值
预训练和下游任务
•一些方法仅仅在涉及到特定的下游任务时才压缩 BERT,也有一些方法以任务无关的方式来压缩 BERT。
ALBERT
研究动机
自BERT的成功以来,预训练模型都采用了很大的参数量以取得更好的模型表现。但是模型参数量越来越大也带来了很多问题,比如对算力要求越来越高、模型需要更长的时间去训练、甚至有些情况下参数量更大的模型表现却更差。有研究者做了一个实验,将BERT-large的参数量、隐层大小翻倍得到BERT-xlarge模型,并将BERT-large与BERT-xlarge的结构进行对比如下:
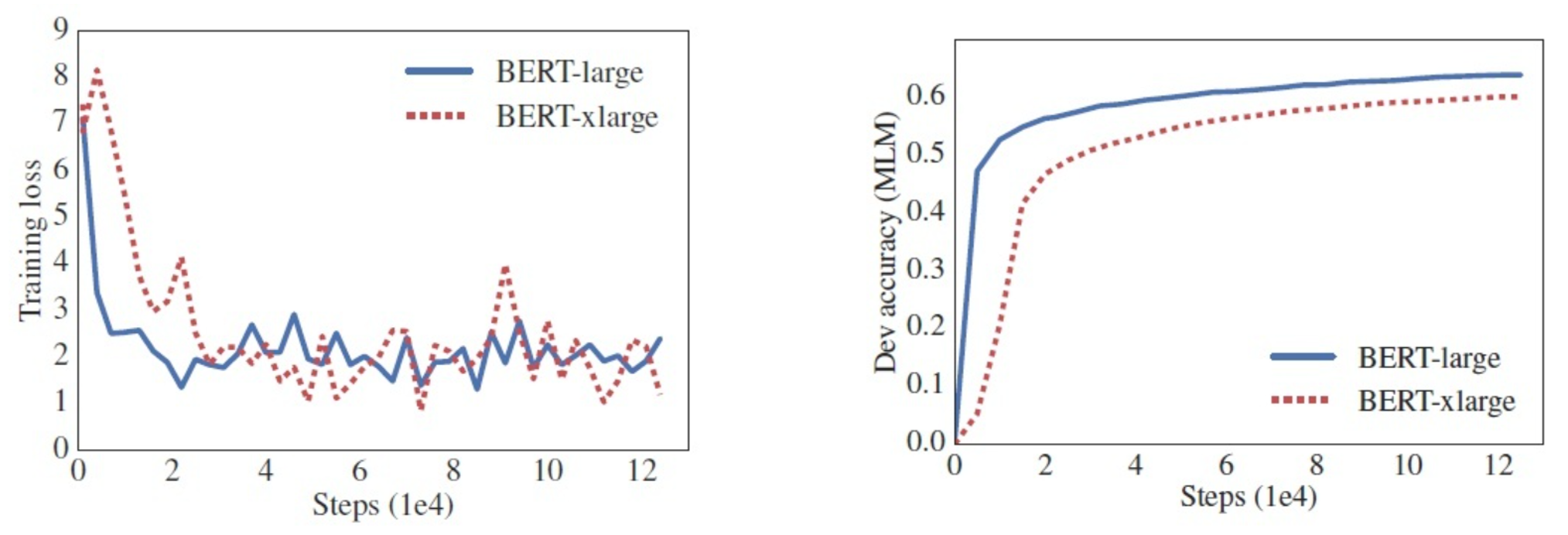
可以看出,BERT-xlarge虽然有更多的参数量,但在训练时其loss波动更大。Marsked LM任务的表现比BERT-large稍差。
为了解决预训练模型参数量过大的问题,ALBERT提出了两种能够大幅减少预训练模型参数量的方法,此外还提出用Sentence-order prediction(SOP)任务代替BERT中的Next-sentence prediction(NSP)任务。
1、对Embedding参数因式分解(Factorized embedding parameterization)
在BERT中,输入词的embedding与encoder输出的embedding维度是一样的都是768。但ALBERT认为,词级别的embedding是没有上下文依赖的,而隐藏层的输出值不仅包括了词本身的意思还包括一些上下文信息,理论上来说隐藏层的表述包含的信息应该更多一些,因此应该让H>>E,所以ALBERT的词向量的维度是小于encoder输出值维度的。
ALBERT具体做法是将词嵌入参数矩阵分解为两个大小分别为VE和EH矩阵,也就是说先将单词投影到一个低维的embedding空间E,再将其投影到高维的隐藏空间H。这使得词嵌入参数的维度从O(VH)减小到 O(VE+E*H)。当H>>E时,参数量减少非常明显。
2、跨层的参数共享(Cross-layer parameter sharing)
ALBERT还提出了一种参数共享的方法,Transformer中共享参数有多种方案,比如只共享全连接层,只共享attention层,ALBERT结合了上述两种方案,全连接层与attention层都进行参数共享,也就是说共享encoder内的所有参数。同样量级下的Transformer采用该方案后实际上效果是有下降的,但是参数量减少了很多。
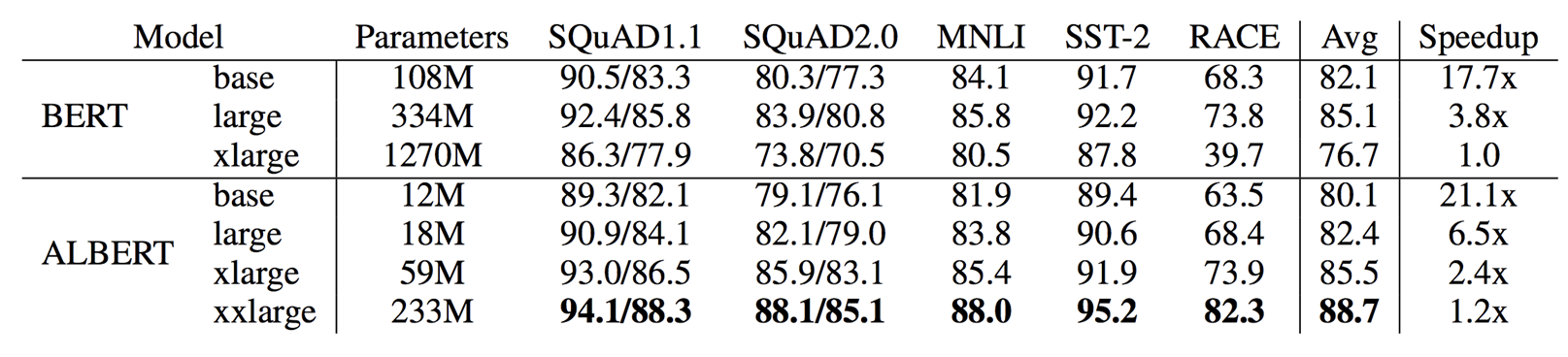
下图是BERT与ALBERT的一个对比,以base为例,BERT的参数是108M,而ALBERT仅有12M,但是效果的确相比BERT降低了两个点。
3、句间连贯(Inter-sentence coherence loss)
BERT的NSP任务实际上是一个二分类,训练数据的正样本是通过采样同一个文档中的两个连续的句子,而负样本是通过采用两个不同的文档的句子。该任务主要是希望能提高下游任务的效果,例如NLI自然语言推理任务。但是后续的研究发现该任务效果并不好,主要原因是因为其任务过于简单。
在ALBERT中,提出了一个新的任务 sentence-order prediction(SOP),SOP的正样本和NSP的获取方式是一样的,负样本把正样本的顺序反转即可。SOP能解决NSP的任务,但是NSP并不能解决SOP的任务,该任务的添加给最终的结果提升了一个点。

小结:
- ALBERT解决的是训练阶段的速度提升,实际上是通过参数共享的方式降低了内存,预测阶段还是需要和BERT一样的时间。
- 在相同的Inference时间下,ALBERT base和large的效果都是没有BERT好的,而且差了2-3个点,作者在最后也提到了会继续寻找提高速度的方法(比如sparse attention)。
- 鱼与熊掌不可兼得,尤其是对于工程落地而言,需要在速度与效果之间寻找一个trade-off。
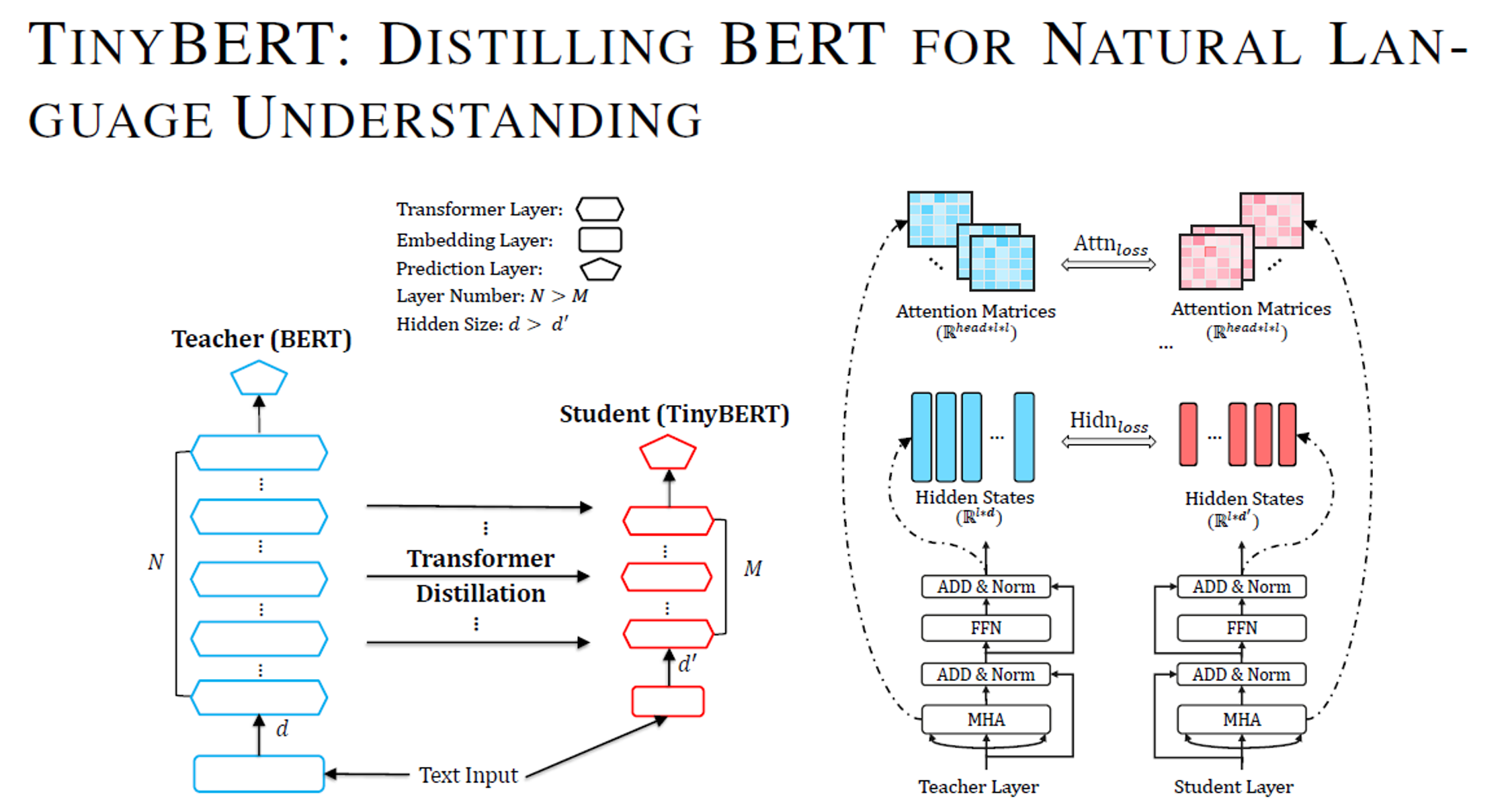
TinyBERT
- TinyBERT 是一种为基于 transformer 结构的模型设计的知识蒸馏方法,模型大小不到 BERT 的 1/7,但速度提高了 9 倍,而且性能没有出现明显下降。
- 目前主流的几种蒸馏方法大概分成基于transformer 结构的蒸馏、基于其它简单结构(比如 BiLSTM )的蒸馏。由于 BiLSTM 等结构简单,且一般是用 BERT 最后一层的输出结果进行蒸馏,不能学到 transformer 中间层的信息,所以对于复杂的语义匹配任务,效果有点不尽人意。
- 基于 transformer 结构的蒸馏方法目前比较出名的有微软的 BERT-PKD (Patient Knowledge Distillation for BERT),huggingface 的 DistilBERT,以及TinyBERT。他们的基本思路都是减少 transformer encoding 的层数和 hidden size 大小,实现细节上各有不同,主要差异体现在 loss 的设计上。
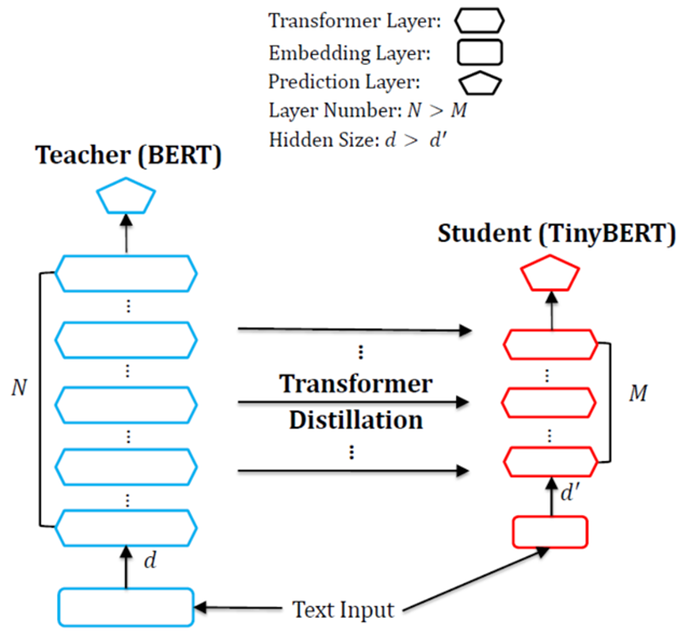
模型蒸馏 Distillation 是一种常用的模型压缩方法,首先训练一个大的 teacher 模型,然后使用 teacher 模型输出的预测值训练小的 student 模型。student 模型学习 teacher 模型的预测结果 (概率值) 从而学习到 teacher 模型的泛化能力。下图展示了 TinyBERT (studet) 和 BERT (teacher) 的结构,可以看到 TinyBERT 减少了 BERT 的层数,并且减小了 BERT 隐藏层的维度。
TinyBERT 蒸馏过程中的损失函数主要包含以下四个:
•Embedding 层损失函数
•Transformer 层 attention 损失函数
•Transformer 层 hidden state 损失函数
•**预测层损失函数 **
TinyBERT蒸馏的映射方法
假设 TinyBERT 有 M 个 Transformer 层,而 BERT 有 N 个 Transformer 层。TinyBERT 蒸馏主要涉及的层有 :embedding 层 (编号为0)、Transformer 层 (编号为1到M) 和输出层 (编号 M+1)。
我们需要将TinyBERT 每一层和 BERT 中要学习的层对应起来,然后再蒸馏。对应的函数为 g(m) = n,m 是 TinyBERT 层的编号,n 是 BERT 层的编号。
•对于embedding层,TinyBERT蒸馏的时候embedding层 (0) 对应了BERT的embedding 层 (0),即 g(0) = 0。
• 对于输出层,TinyBERT的输出层 (M+1) 对应了 BERT 的输出层 (N+1),即 g(M+1) = N+1。
• 对于中间的Transformer层,TinyBERT采用间隔k层蒸馏的方法。例如 TinyBERT有 4 层Transformer,BERT有12层Transformer,则TinyBERT第 1 层 Transformer 学习的是BERT的第 3 层;而TinyBERT第 2 层学习BERT的第 6 层。
TinyBERT 在 Transformer 层损失函数有两个,第一个是 attention loss,第二个损失函数是 hidden loss。
- Transformer 层 attention 子层损失函数
attention loss如下图红框所示,attention loss主要是希望 TinyBERT Multi-Head Attention输出的attention score矩阵能够接近BERT的 attention score矩阵。

因为有研究发现 BERT学习到的attention score 矩阵能够包含语义知识,例如语法和相互关系等。TinyBERT 通过下面的损失函数学习 BERT attention 的功能,h 表示 Multi-Head Attention 中 head 的个数。
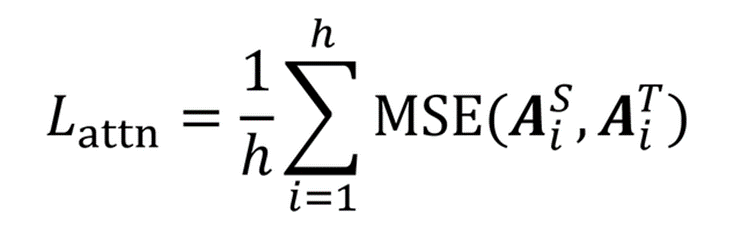
- Transformer 层 hidden 子层损失函数
hiddenstates loss如下图红框所示,hidden state loss 和 embedding loss 类似,计算公式如下,也需要经过一个映射矩阵:

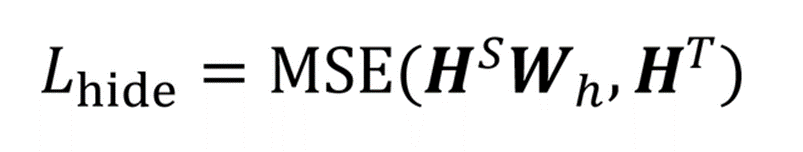
- 预测层损失函数
预测层的损失函数采用了交叉熵,计算公式如下:
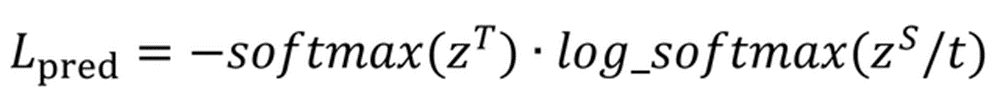
其中 t 是模型蒸馏的 temperature value,zT是 BERT 的预测概率,而zS 是 TinyBERT的预测概率。
温度值的作用:在我们正常的训练过程中,只会关注概率最高结果与正确结果的差别。如果只是构建所有类的传统损失函数的话,小概率结果对损失函数的贡献微乎其微。解决的方法是:加入温度系数,在计算损失函数时放大其他类的概率值所对应的损失值。这种方式使得不同类的输出结果被同等的考量了,促进了小网络的训练效果。
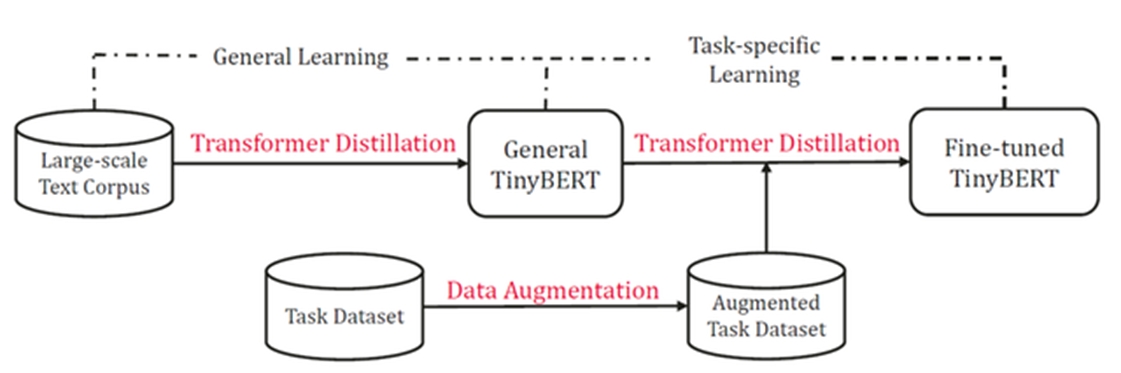
TinyBERT的两阶段训练法
BERT 有两个训练阶段,第一个训练阶段是训练一个预训练模型 (预训练 BERT),第二个训练阶段是针对具体下游任务微调 (微调后的 BERT)。
TinyBERT的蒸馏过程也分为两个阶段:
第一个阶段,TinyBERT在大规模的general数据集上,利用预训练BERT蒸馏出一个GeneralTinyBERT。
第二个阶段,TinyBERT采用数据增强,利用GeneralTinyBERT训练一个微调后的task specific 模型。
RoBERTa
RoBERTa在模型层面没有改变Google的Bert,改变的只是预训练的方法。
1. 静态Masking vs 动态Masking
• 原来Bert对每一个序列随机选择15%的Tokens替换成[MASK],为了消除与下游任务的不匹配,对这15%的Tokens进行(1)80%的情况替换成[MASK];(2)10%的情况保持不变;(3)10%的情况替换成其他词。但整个训练过程,这15%的Tokens一旦被选择就不再改变,也就是说从一开始随机选择了这15%的Tokens,之后的N个epoch里都不再改变了。这就叫做静态Masking。
• 而RoBERTa一开始把预训练的数据复制10份,每一份都随机选择15%的Tokens进行Masking,也就是说,同样的一句话有10种不同的mask方式。这就相当于在这N个epoch的训练中,每个序列的被mask的tokens是会变化的。这就叫做动态Masking。
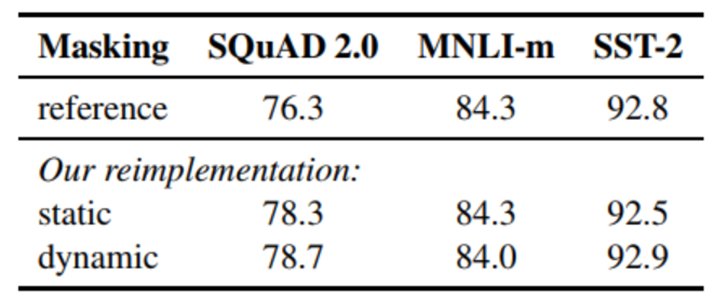
2. with NSP vs without NSP
• 原本的Bert为了捕捉句子之间的关系,使用了NSP任务进行预训练,就是输入一对句子A和B,判断这两个句子是否是连续的。在训练的数据中,50%的B是A的下一个句子,50%的B是随机抽取的。
• RoBERTa去除了NSP,而是每次输入连续的多个句子,直到最大长度512(可以跨文章)。这种训练方式叫做(FULL - SENTENCES),而原来的Bert每次只输入两个句子。实验表明在推断句子关系的任务上RoBERTa也能有更好的性能。
• SENTENCE-PAIR + NSP:两个sentence组成句子对,并且引入NSP任务,总长可能会比512小很多
• FULL-SENTENCES:有多个完整的句子组成,对于跨文档的部分,用一个标识符分开,但是总长不超过512,无NSP任务

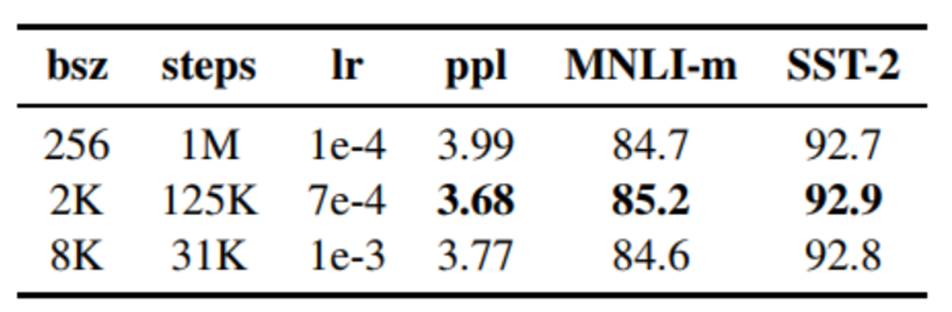
3. 更大的mini-batch
原本的BERT-base的batch size是256,训练1M个steps。RoBERTa的batch size为8k。为什么要用更大的batch size呢?(前提是有足够的算力)作者借鉴了在机器翻译中,用更大的batch size配合更大学习率能提升模型优化速率和模型性能的现象,并且也用实验证明了确实Bert还能用更大的batch size。
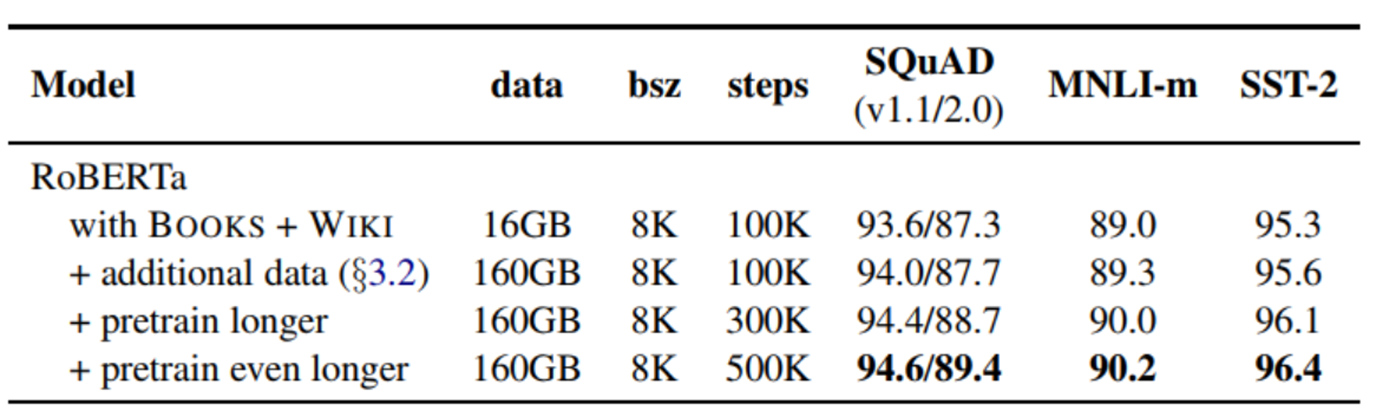
4. 更多的数据,更长时间的训练
借鉴XLNet用了比Bert多10倍的数据,RoBERTa也用了更多的数据。性能确实再次提升。当然,也需要配合更长时间的训练。
GANs(Generative Adversarial Networks )
生成对抗网络的概述
通过对抗的方式去学习数据分布的生成式模型:
•Generative 学习一个生成式模型
•Adversarial 使用对抗的方法训练
•Networks 使用神经网络
GAN的核心思想:
通过生成网络G (Generator)和判别网络D (Discriminator)不断博弈,来达到生成类真数据的目的。
作者:
2014年,IanGoodfellow 和蒙特利尔大学的其他研究者(包括YoshuaBengio)提出GANs
应用:
- 无监督对GAN来讲是小菜一碟
- 训练深度学习模型需要大量数据
- 标注数据费时费力
- GAN提供更便捷的方法训练模型
- GAN通过图像风格迁移可以将马变成斑马
- Image-to-Image
- 桔子变苹果、一秒变名画
- 图像风格迁移
- GAN可以输入文本生成图像
- Text-to-Image
- 标题生成图像
- 风格转换
- GAN的1+1>2
- GAN+ Transfer Learning
- 超分辨率图像生成
- Mind2Mind
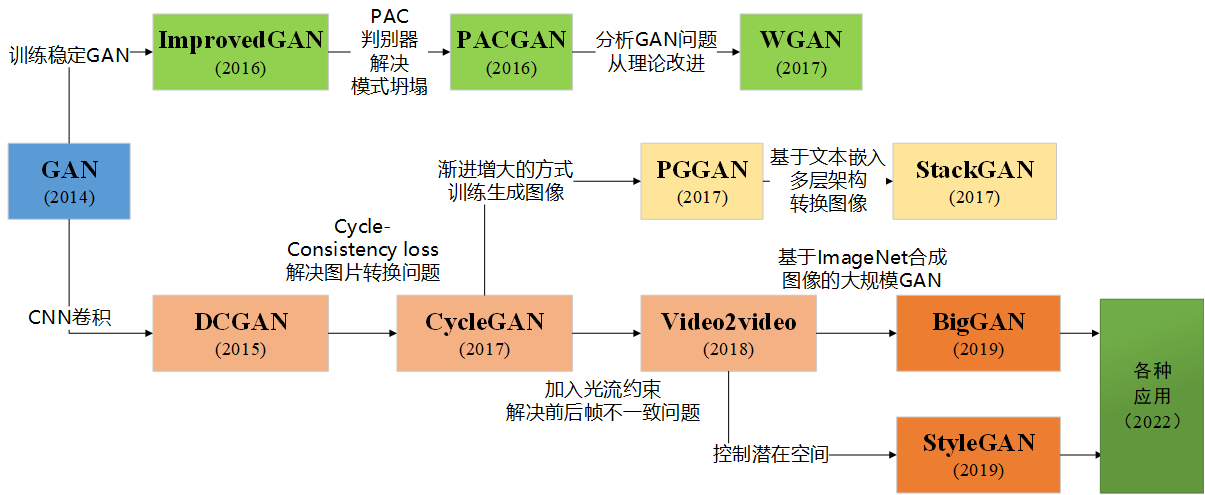
发展脉络:
生成对抗网络的原理

GAN 的思想启发自博弈论中的零和游戏,包含一个生成网络G和一个判别网络D
• G是一个生成式的网络,它接收一个随机的噪声Z,通过Generator生成假数据Xfake。
• D是一个判别网络,判别输入数据的真实性。它的输入是X,输出D(X)代表X为真实数据的概率。
• 训练过程中,生成网络G的目标是尽量生成真实的数据去欺骗判别网络D。而D的目标就是尽量辨别出G生成的假数据和真数据。这个博弈过程最终的平衡点是纳什均衡点。
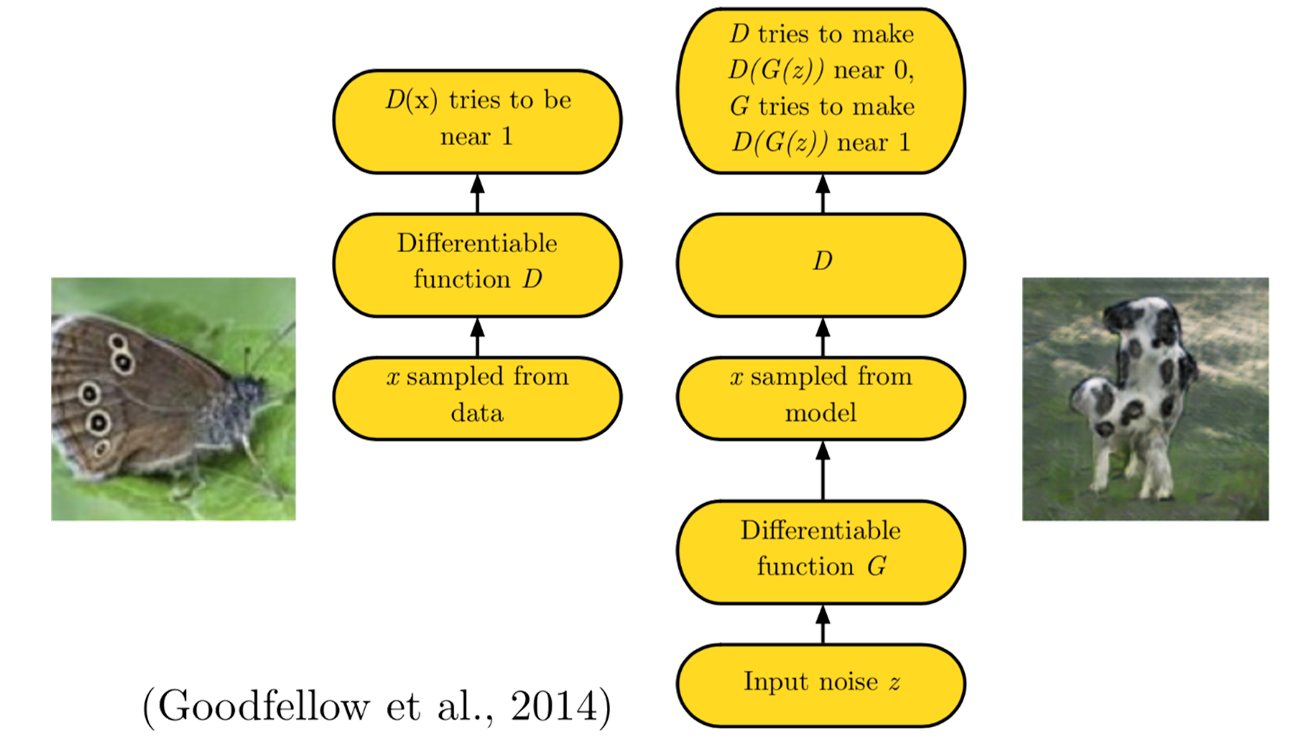
假设我们有两个网络,G和D
G是一个生成图片的网络,它接收一个随机的噪声z,通过这个噪声生成图片,记做G(z)。
D是一个判别网络,判别一张图片是不是“真实的”。它的输入x代表一张图片,输出D(x)代表x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图片。
在训练过程中,生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D。而D的目标就是尽量把G生成的图片和真实的图片分别开来。这样,G和D构成了一个动态的“博弈过程”。
最后博弈的结果是什么?**在最理想的状态下,**G可以生成足以“以假乱真”的图片G(z)。对于D来说,它难以判定G生成的图片究竟是不是真实的,因此D(G(z)) = 0.5。
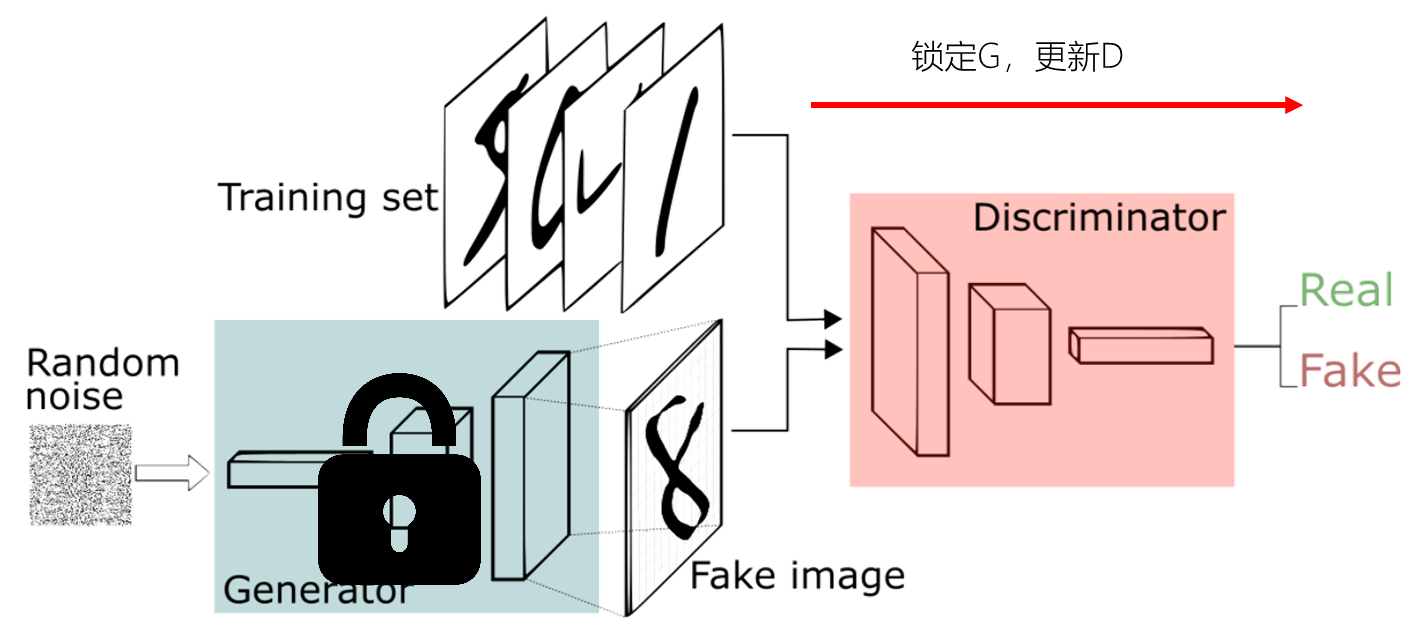
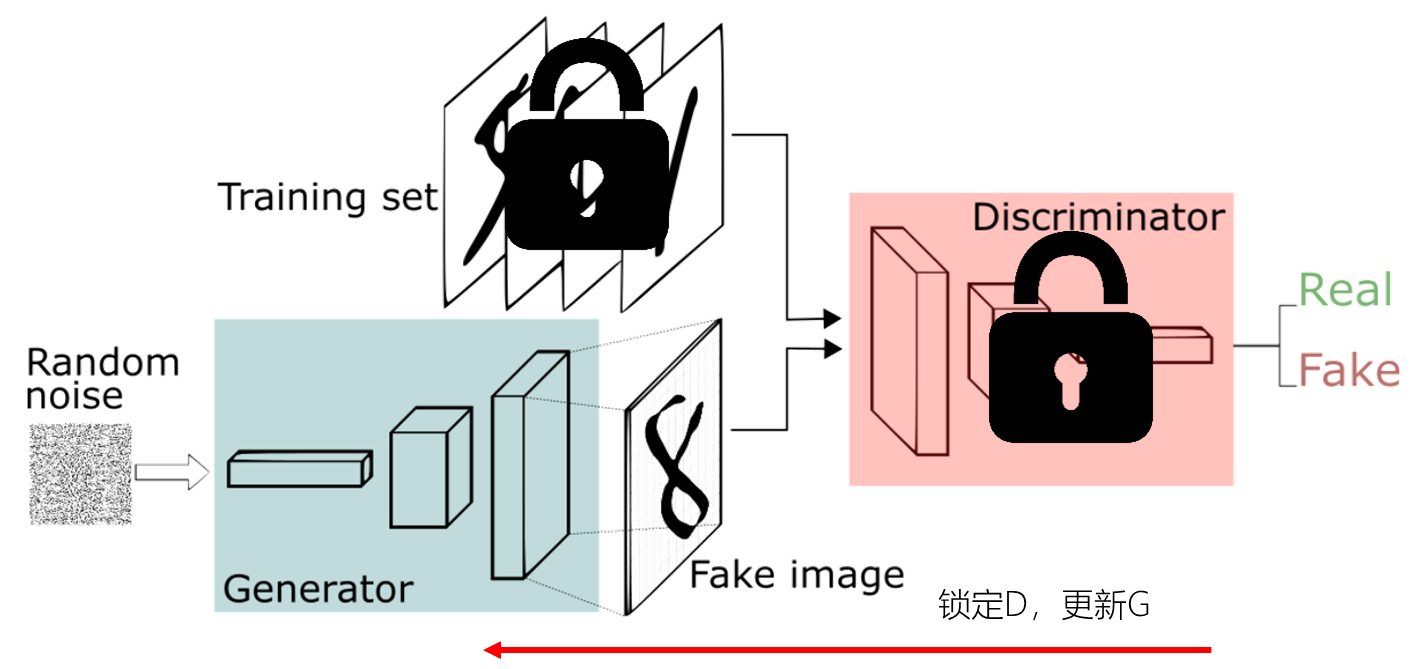
生成对抗网络的训练方法
两个都需要训练,而且彼此依赖,怎么办?
– 锁定一个,训练另一个
训练细节:

优点:
摘自Ian Goodfellow在Quora的问答
• GAN是一种生成式模型,相比较其他生成模型(玻尔兹曼机)只用到了反向传播,而不需要复杂的马尔科夫链
• 相比其他所有模型, GAN可以产生更加清晰,真实的样本
• GAN采用的是一种无监督的学习方式训练,可以被广泛用在无监督学习和半监督学习领域
• 相比于变分自编码器, GANs没有引入任何决定性偏置( deterministic bias),变分方法引入决定性偏置,这看起来导致了VAEs生成的实例比GANs更模糊
• 相比VAE, GANs没有变分下界,如果鉴别器训练良好,那么生成器可以完美的学习到训练样本的分布。换句话说,GANs是渐进一致的,但是VAE是有偏差的
• GAN应用到一些场景上,比如图片风格迁移,超分辨率,图像补全,去噪,避免了损失函数设计的困难,不管三七二十一,只要有一个的基准,直接上判别器,剩下的就交给对抗训练了。
生成对抗网络的存在的问题
- Non-Convergence (不收敛)
训练GAN需要达到纳什均衡,有时候可以用梯度下降法做到,有时候做不到.我们还没有找到很好的达到纳什均衡的方法,所以训练GAN相比VAE是不稳定的。
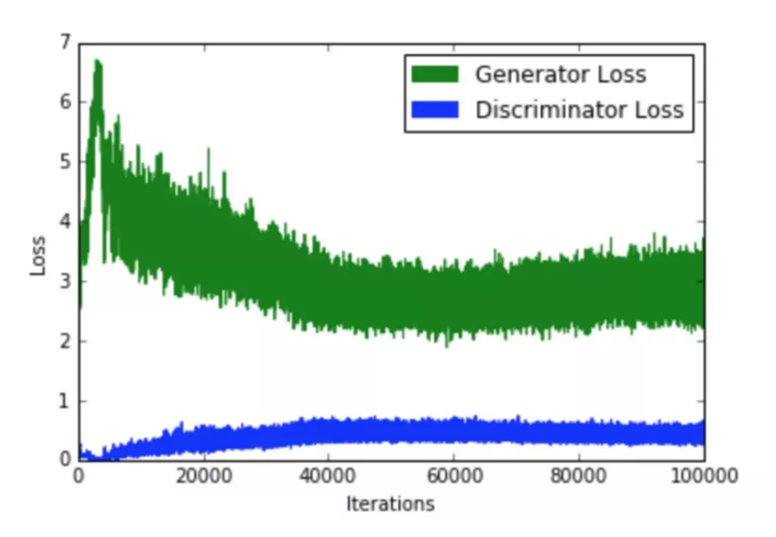
- Mode-Collapse (模式坍塌)可以理解为生成的内容没有多样性
一般出现在GAN训练不稳定的时候,具体表现为生成出来的结果非常差,但是即使加长训练时间后也无法得到很好的改善。
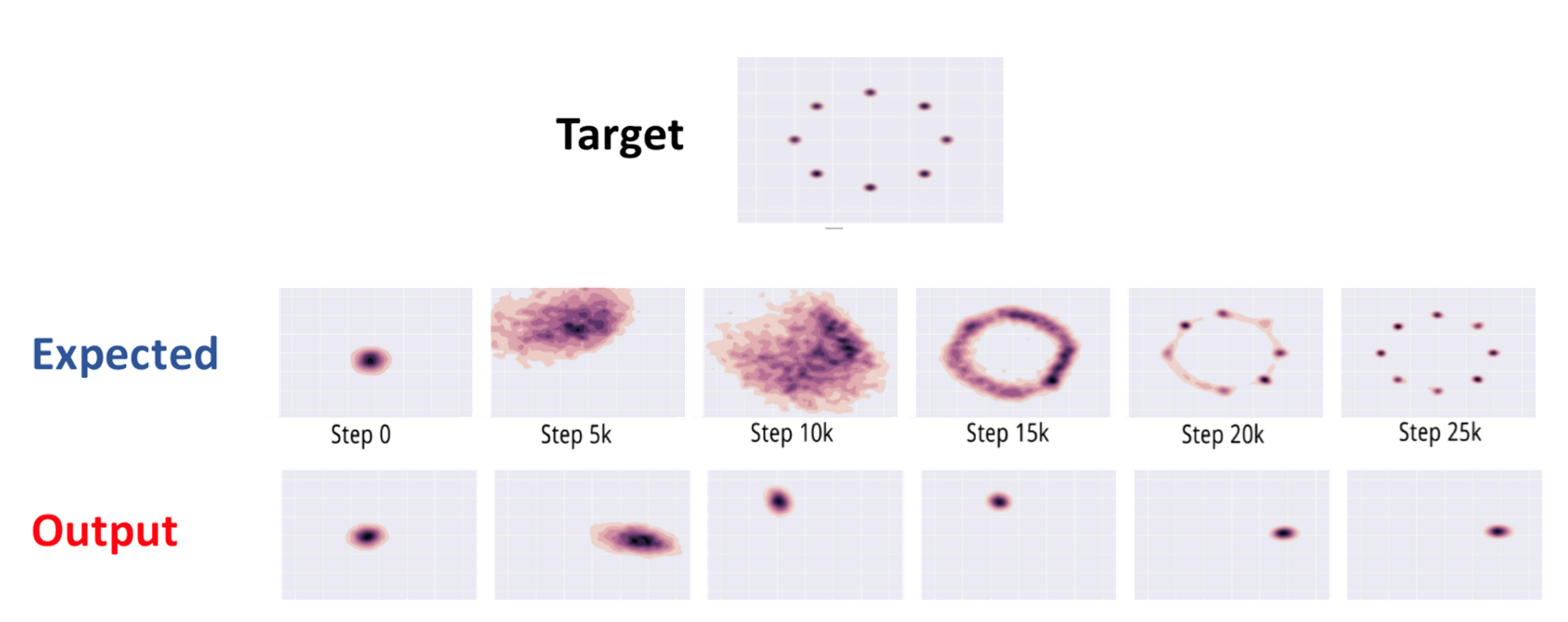
Mode-Collapse (模式坍塌)的原因
• GAN采用的是对抗训练的方式,G的梯度更新来自D,所以G生成的好不好,依赖于D的评价。
• 如果某一次G生成的样本可能并不是很好,但是D给出了很好的评价,或者是G生成的结果中一些特征得到了D的认可,这时候G就会认为我输出的正确的,那么接下来我就这样输出肯定D还会给出比较高的评价(实际上G生成的并不好)。
进入一种“死循环”,最终生成结果缺失一些信息,特征不全。
生成对抗网络的常见结构
Deep Convolutional GAN (DCGAN)
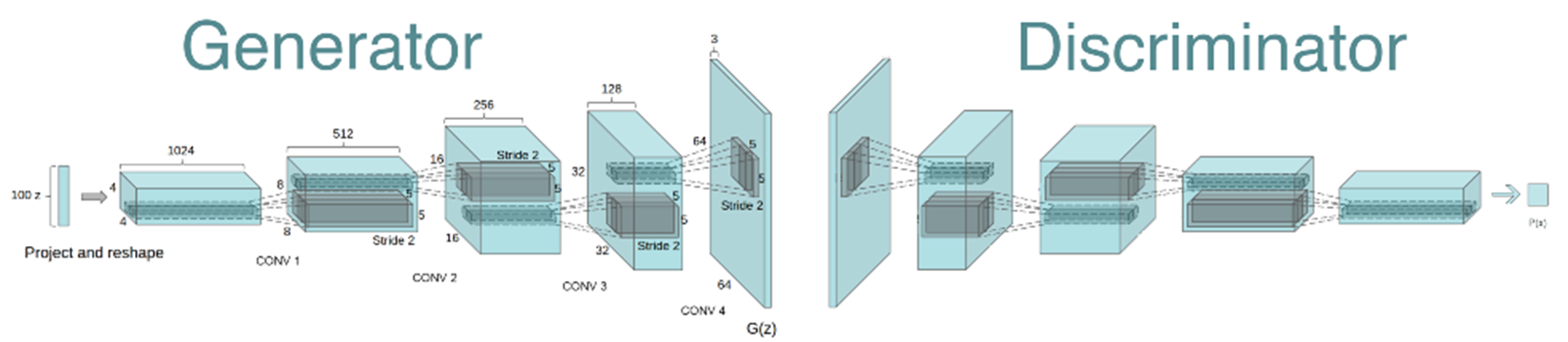
核心思想
1.使用卷积层替换全连接层。
2.在每层后使用BatchNormalization。将特征层的输出归一化到一起,加速了训练,提升了训练的稳定性。(生成器的最后一层和判别器的第一层不加batchnorm)。
3.G的隐藏层使用ReLU;G的输出层使用Tanh;D使用leakrelu激活函数,而不是RELU,防止梯度稀疏。
上面这些 trick 对于稳定 GAN 的训练有许多帮助,自己设计 GAN 网络时也可以酌情使用。
层级GAN

• GAN 对于高分辨率图像生成一直存在许多问题,层级结构的 GAN 通过逐层次,分阶段生成,一步步提生图像的分辨率。
• 典型的使用多对 GAN 的模型有StackGAN,GoGAN。使用单一 GAN,分阶段生成的有 ProgressiveGAN。
生成对抗网络的改进
Mode Collapse的解决方法
- 针对目标函数的改进方法:
- 为了避免前面提到的由于优化 maxmin导致 mode 跳来跳去的问题,UnrolledGAN采用修改生成器 loss 来解决。具体而言,UnrolledGAN在更新生成器时更新 k 次生成器,参考的 Loss 不是某一次的 loss,是判别器后面 k 次迭代的 loss。
- 注意,判别器后面 k 次迭代不更新自己的参数,只计算 loss 用于更新生成器。这种方式使得生成器考虑到了后面 k 次判别器的变化情况,避免在不同 mode 之间切换导致的模式崩溃问题。
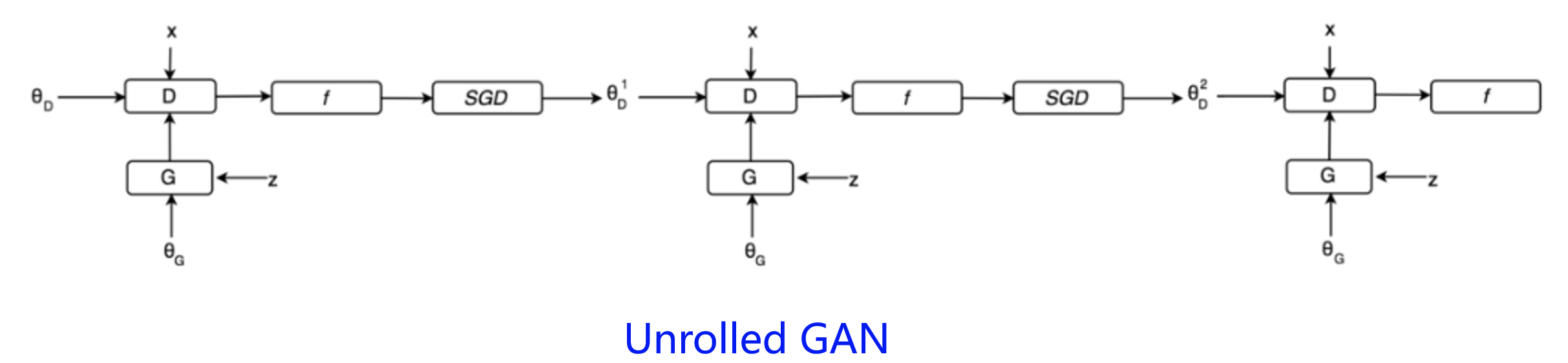
- 针对网络结构的改进方法:
- Multi agent diverse GAN (MAD-GAN) 采用多个生成器,一个判别器以保障样本生成的多样性。
- 相比于普通 GAN,多了几个生成器,且在 loss 设计的时候,加入一个正则项。正则项使用余弦距离惩罚三个生成器生成样本的一致性。
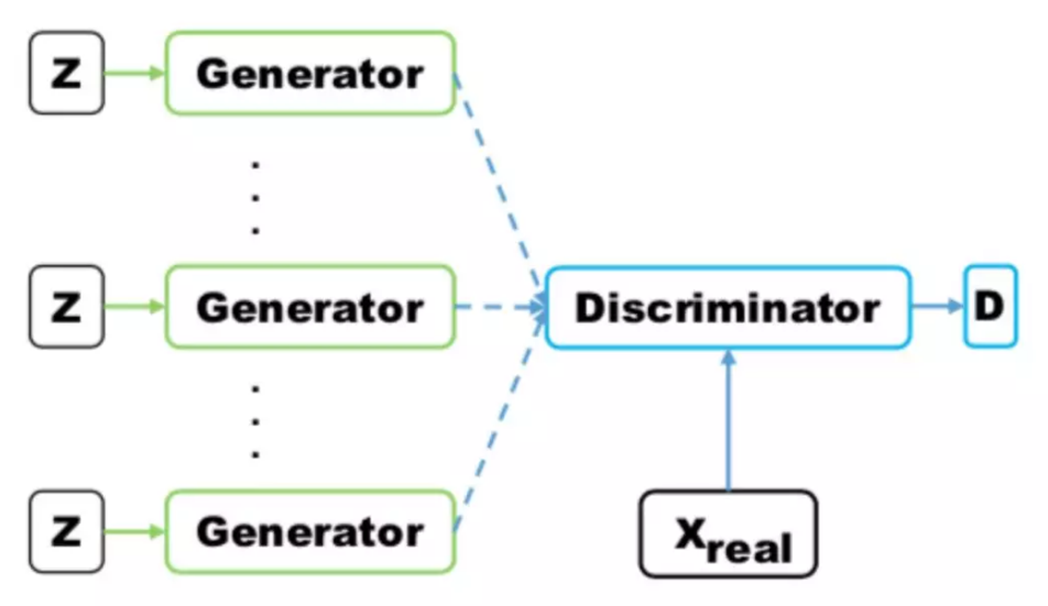
- MRGAN 则添加了一个判别器来惩罚生成样本的 mode collapse 问题。
- 输入样本 x 通过一个 Encoder 编码为隐变量 E(x) ,然后隐变量被 Generator 重构,训练时有三个loss。
- DM和 R (重构误差)用于指导生成 real-like 的样本。而 DD则对 E(x) 和 z 生成的样本进行判别。
- 显然二者生成样本都是 fake samples,所以这个判别器主要用于判断生成的样本是否具有多样性,即是否出现 mode collapse。
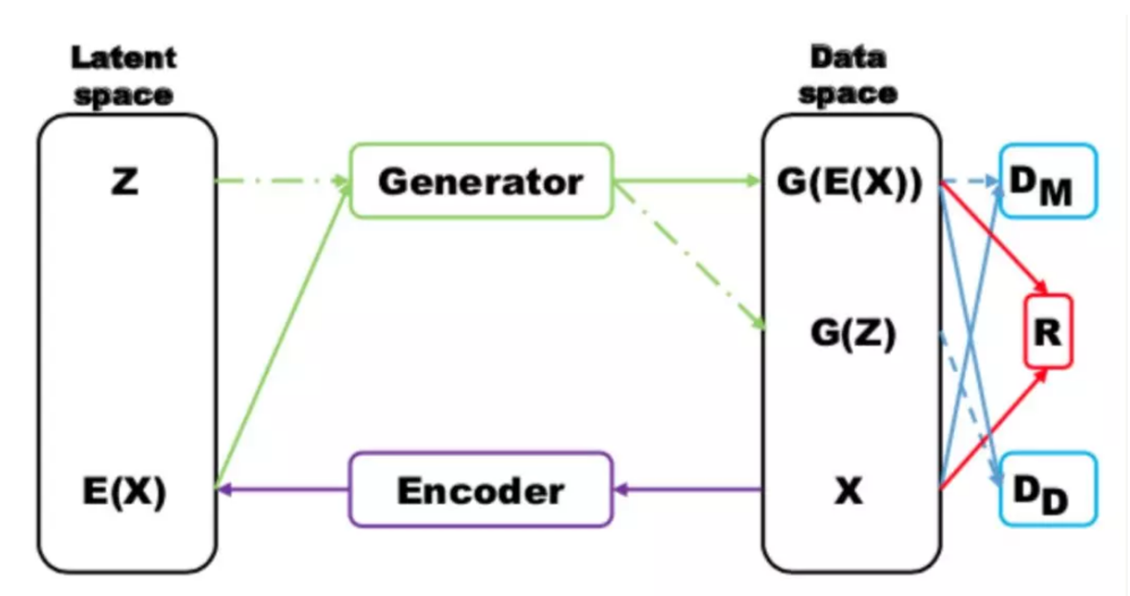
Wasserstein GAN (WGAN)
WGAN的优点:
• WGAN彻底解决GAN训练不稳定的问题,不再需要小心平衡生成器和判别器的训练程度。
• 基本解决了collapse mode的问题,确保了生成样本的多样性。
• 训练过程中终于有一个像交叉熵、准确率这样的数值来指示训练的进程,这个数值越小代表GAN训练得越好,代表生成器产生的图像质量越高。
• 以上一切好处不需要精心设计的网络架构,最简单的多层全连接网络就可以做到。
通过一系列复杂的理论分析,总结以下几点:
• 判别器最后一层去掉sigmoid。
• 生成器和判别器的loss不取log。
• 每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c。
• 不要用基于动量的优化算法。
WGAN解决的问题:
原始GAN的问题:判别器越好,生成器梯度消失越严重。
• 根据原始GAN定义的判别器loss,可以得到最优判别器的形式;而在最优判别器的下,可以把原始GAN定义的生成器loss等价变换为最小化真实分布与生成分布之间的JS散度。
• 我们越训练判别器,它就越接近最优,最小化生成器的loss也就会越近似于最小化真实分布和生成分布之间的JS散度。

问题就出在这个JS散度上
• 如果两个分布之间越接近,它们的JS散度越小,通过优化JS散度就能将它们拉近,最终以假乱真。
• 以上在两个分布有所重叠的时候是成立的,但是如果两个分布完全没有重叠的部分,或者它们重叠的部分可忽略,它们的JS散度是log2。
• 在(近似)最优判别器下,最小化生成器的loss等价于最小化真实分布与生成之间的JS散度,而由于与几乎不可能有不可忽略的重叠,所以无论它们相距多远JS散度都是常数,最终导致生成器的梯度(近似)为0,梯度消失。
Wasserstein距离:
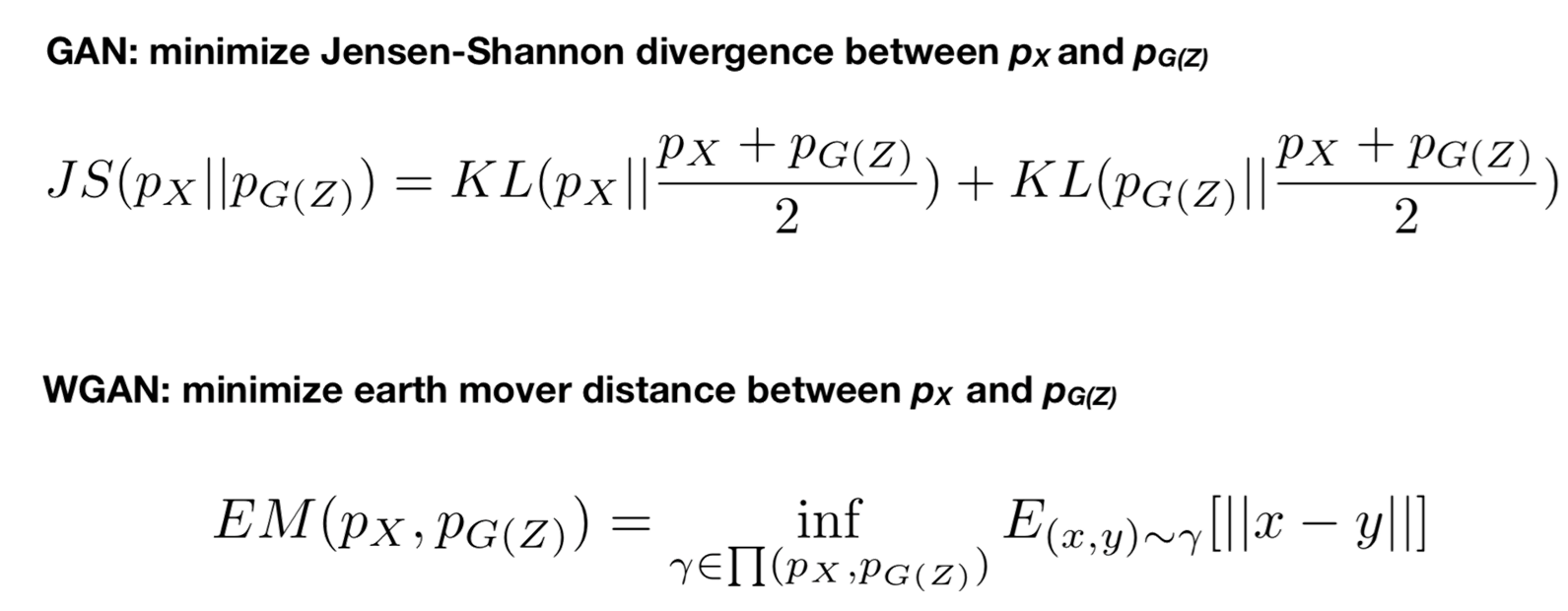
Wasserstein距离又叫Earth-Mover(EM)距离,直观上可以理解为在γ这个“路径规划”下把这堆“沙土”Pr挪到“位置”Pg所需的“消耗”,而W(Pr,Pg)就是“最优路径规划”下的“最小消耗”,所以才叫Earth-Mover(推土机)距离。
Wasserstein距离相比KL散度、JS散度的优越性在于,即便两个分布没有重叠,Wasserstein距离仍然能够反映它们的远近。
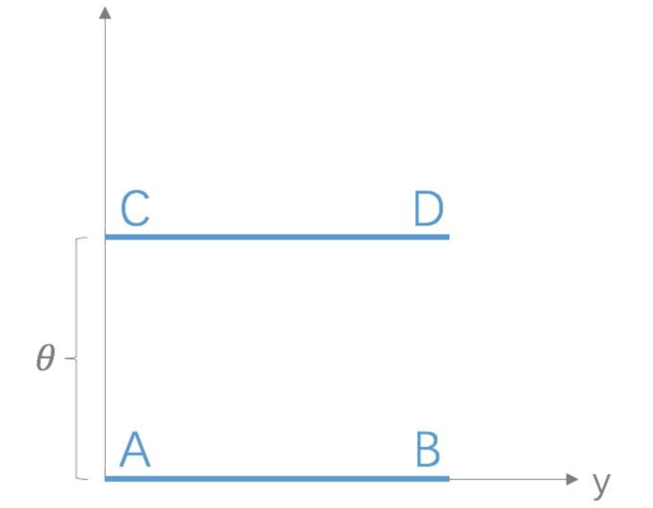
考虑分布P1和P2,P1在线段AB上均匀分布,P2在线段CD上均匀分布,通过参数θ可以控制两个分布的远近.

WGAN和原始GAN的效果比较:
WGAN如果用类似DCGAN架构,生成图片的效果与DCGAN差不多

拿掉Batch Normalization的话,DCGAN不能生成正常图片
 如果WGAN和原始GAN都使用多层全连接网络MLP,不用CNN,WGAN质量会变差些,但是原始GAN不仅质量变得更差,而且还出现了collapse mode,即多样性不足
如果WGAN和原始GAN都使用多层全连接网络MLP,不用CNN,WGAN质量会变差些,但是原始GAN不仅质量变得更差,而且还出现了collapse mode,即多样性不足

生成对抗网络应用
GAN的应用场景:
GAN的潜力巨大,因为它们能去学习模仿任何数据分布,因此,GANs能被教导在任何领域创造类似于我们的世界,比如图像、音乐、演讲、散文。在某种意义上,他们是机器人艺术家,他们的输出令人印象深刻,甚至能够深刻的打动人们。

GAN的应用场景:
- GAN作画

《埃德蒙·贝拉米画像》(Portrait of Edmond Belamy)纽约佳士得拍卖会 43.25万美元 (约300万人民币),成交。
- Image Synthesis 图像合成

- Image-to-Image 风格迁移


- Text-to-Image 图像生成


- Super Resolution 超分辨率图像生成

- Video 视频生成

- 对图像的各种生成变换

图像风格迁移:
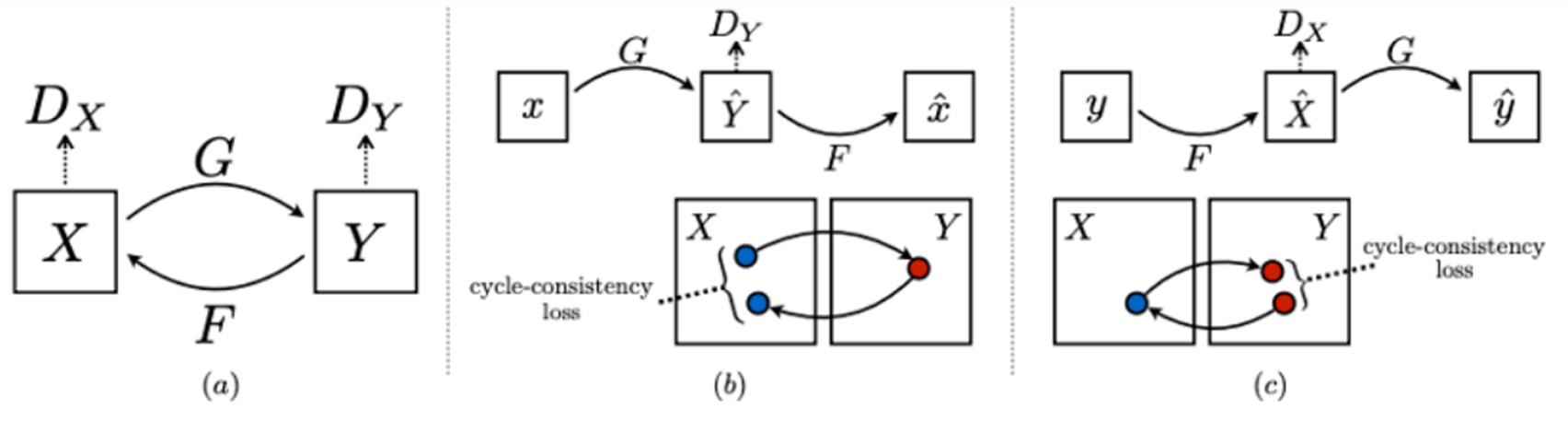
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
CycleGAN可以实现风格迁移功能,通过两个镜像对称的GAN构成一个环形网络。针对无配对数据,在源域和目标域之间不需要建立一对一的映射就可以实现风格迁移。



CycleGAN的两个GAN共享两个生成器G和F,但判别器是独立的两个Dx和Dy,一个单向GAN包含两个loss,CycleGAN包含四个loss。X和Y是两个数据分布,生成器G和F分别是X到Y与Y到X的映射,两个判别器Dx和Dy分别对转换后的图片进行判别,生成器采用ResBlock结构,判别器采用pix2pix的PatchGAN结构,大小为70x70, cycle-consistency loss是用数据集中其他的图来检验生成器,这是防止G和F过拟合。
超分辨率图像生成:
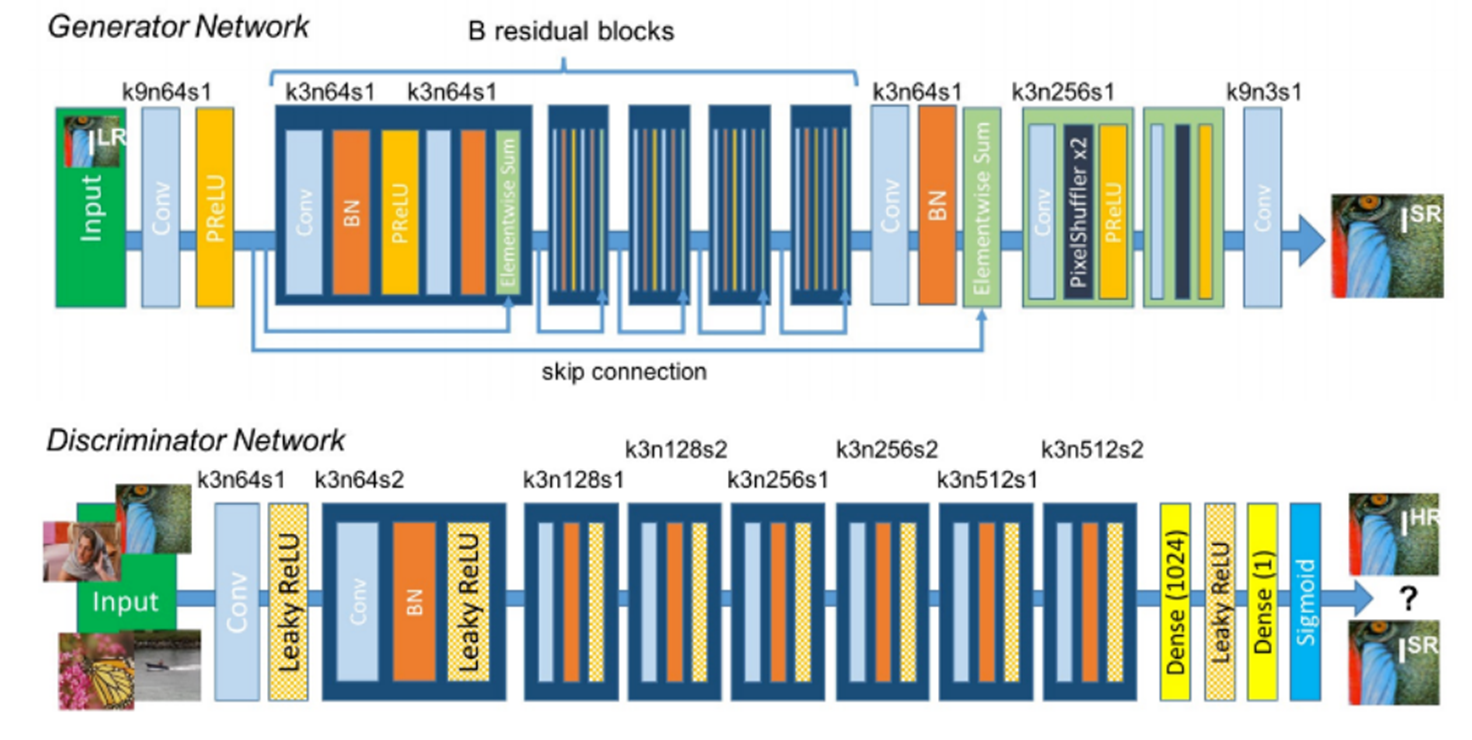
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
SRGAN是将GAN应用到图像超分辨领域,CNN卷积神经网络在传统的超分辨重建上已经取得了非常好的效果,可以取得较高的峰值信噪比PSNR,以MSE为最小化的目标函数。SRGAN是第一个能恢复4倍下采样图像的算法框架,作者提出了感知损失函数,包括对抗损失和内容损失两部分,对抗损失来自判别器,用来分辨真实图像和生成的超分辨图像,内容损失注重于视觉上的相似性。

左侧的Super-resolved image几乎和右侧的原始图像区分不开
SRGAN用sub-pixel网络作为生成网络,由残差结构Residual blocks组成;用VGG作为判别网络。
作者提出感知损失函数,包括内容损失(某层特征图的逐像素损失)和对抗损失构成。
文本风格迁移:
A Dual Reinforcement Learning Framework for Unsupervised Text Style Transfer
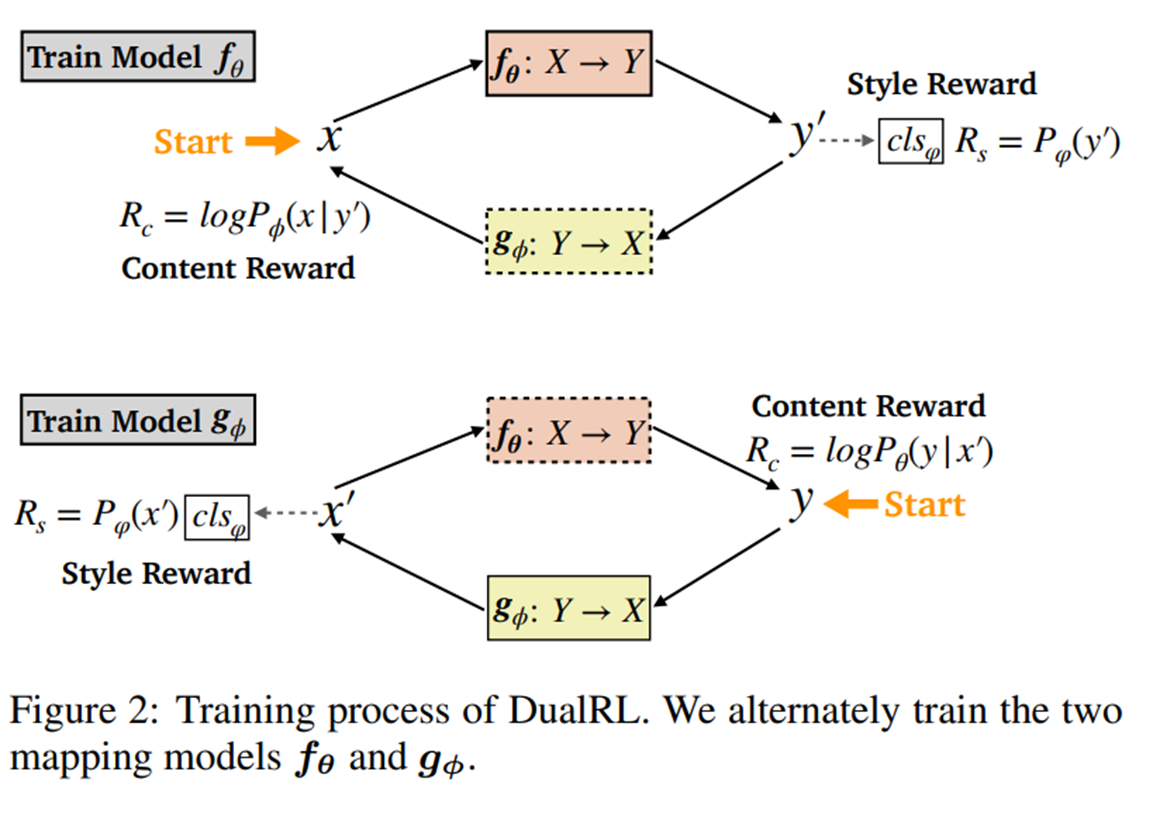
该方法提出了一个双强化学习框架通过单步映射模型来直接进行风格转换,不需要进行文本信息抽离。具体而言,把源文本-目标文本和目标文本-源文本的映射学习看作是一个双向任务,采用两个奖励函数来分别风格准确性和文本内容保留度。通过这种方式,这两个单步映射模型可以通过强化学习来学习,而不需要额外的数据。
深度学习前沿技术
机器阅读
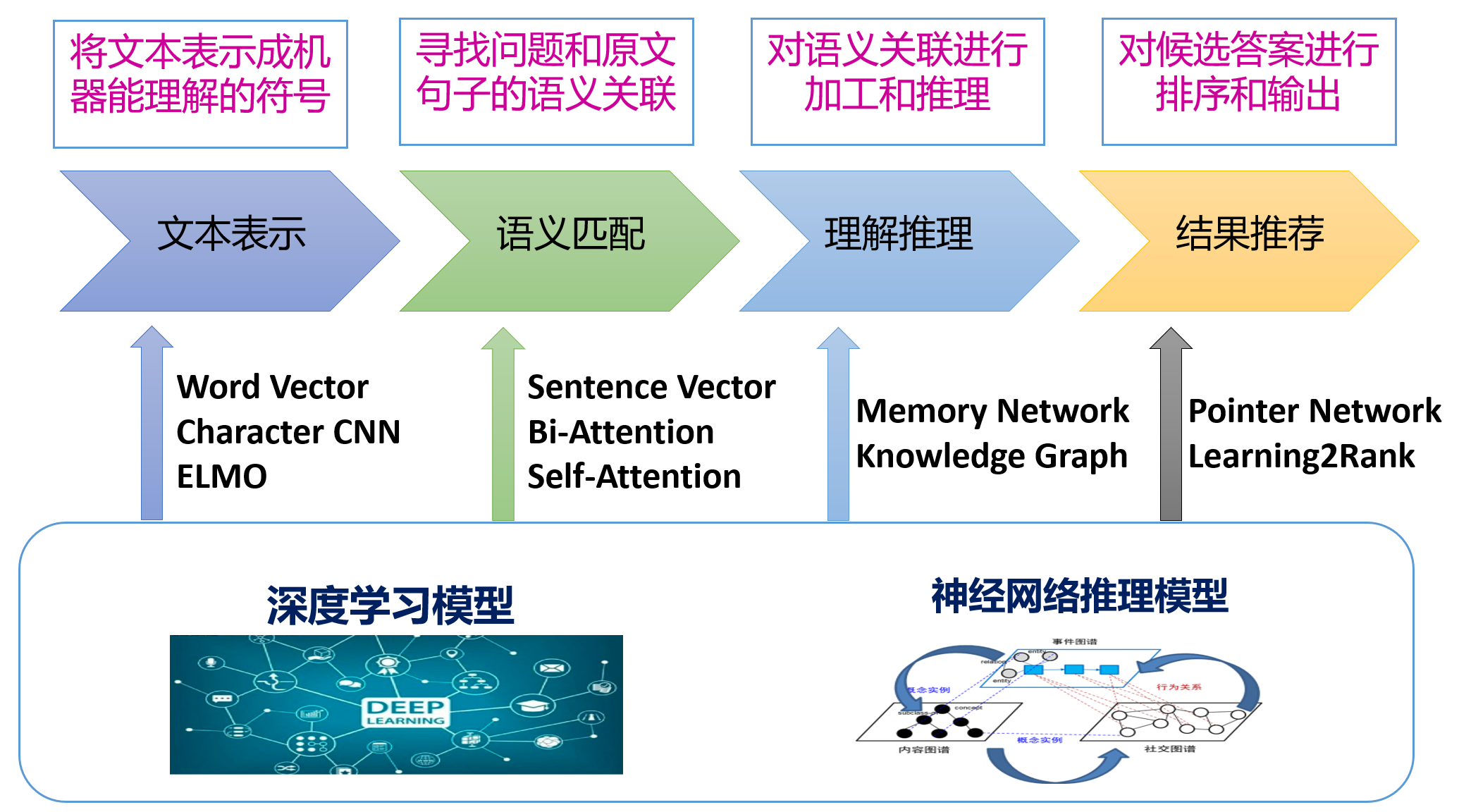
机器阅读旨在让AI代替人类,自动阅读新闻报道等信息并根据问题给出答案,可应用于信息检索和情报挖掘领等多个场景。
机器阅读,涉及到语义理解、知识推理等多项复杂技术,极具挑战性。
主要步骤:
机器阅读数据集:
- MCTest:给定一篇文章、一个问题以及四个选项,预测哪个选项是问题的答案。
- CNN/Daily Mail:给定一篇文章和一个问题,预测问题中被X替换的实体是文章中的哪个实体。
- SQuAD:给定一篇文章、一个问题,预测文章中的一个区间(一个或几个词)作为答案。
- Quasar-T:给定几篇文章、一个问题,预测文章中的一个区间(一个或几个词)作为答案。
- HotPot:给定很多段落、一个问题,答案需要综合多个句子进行多步推理之后才能得到。
- MuTual:MuTual基于中国高考英语听力题改编。要求根据一段双人多轮对话,回答额外提出的问题,并通过能否正确答对问题衡量考生是否理解了对话内容。为了更自然的模拟开放领域对话,该数据集进一步将听力题中额外的问题转化为对话中的回复。
- DuReader:百度发布了开领域的中文阅读理解数据集DuReader,在百度知道和百度搜索中收集了一百多万个文档和二十多万个不同类型的问题,包括YesNo问题,描述性问题等,并且手工整理了答案。
- CommonsenseQA:基于常识知识图谱(背景知识、先验知识),回答给定问题,答案是单项选择题的形式。
机器阅读模型:
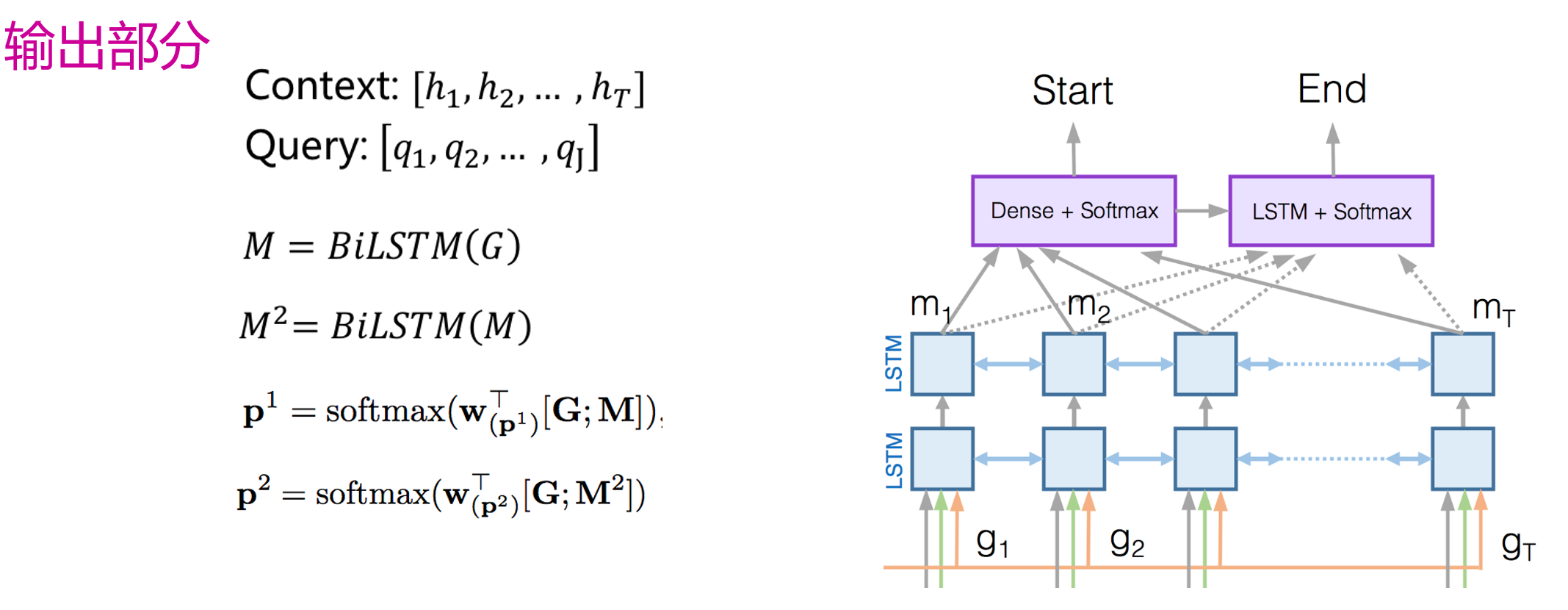
BiDAF:
Bidirectional Attention Flow For Machine Comprehension, ICLR
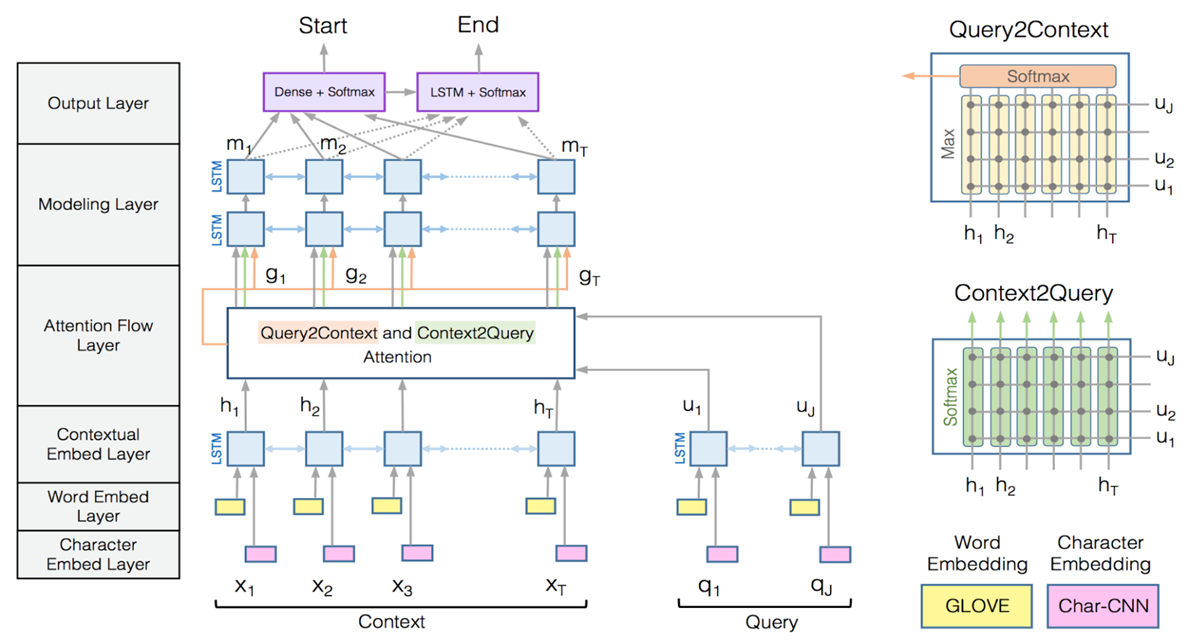
- 输入:一篇文章X和一个问题Y
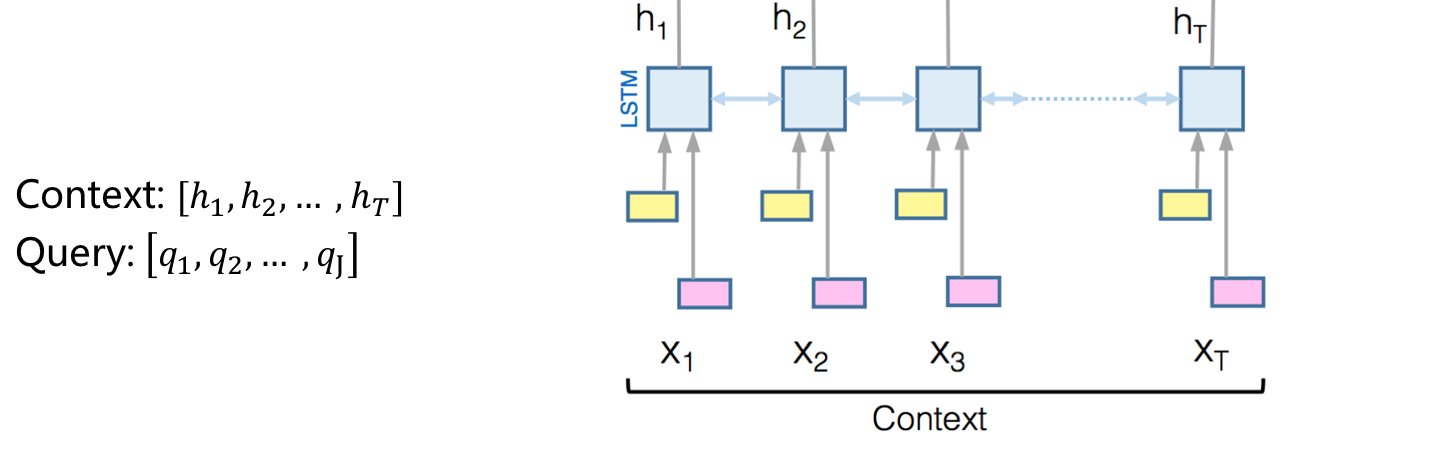
Ø 拼接每一个词对应的GLOVE词向量和Char-CNN词向量
Ø 经过一层BiLSTM层得到Context和Query的向量表示。
双向注意力
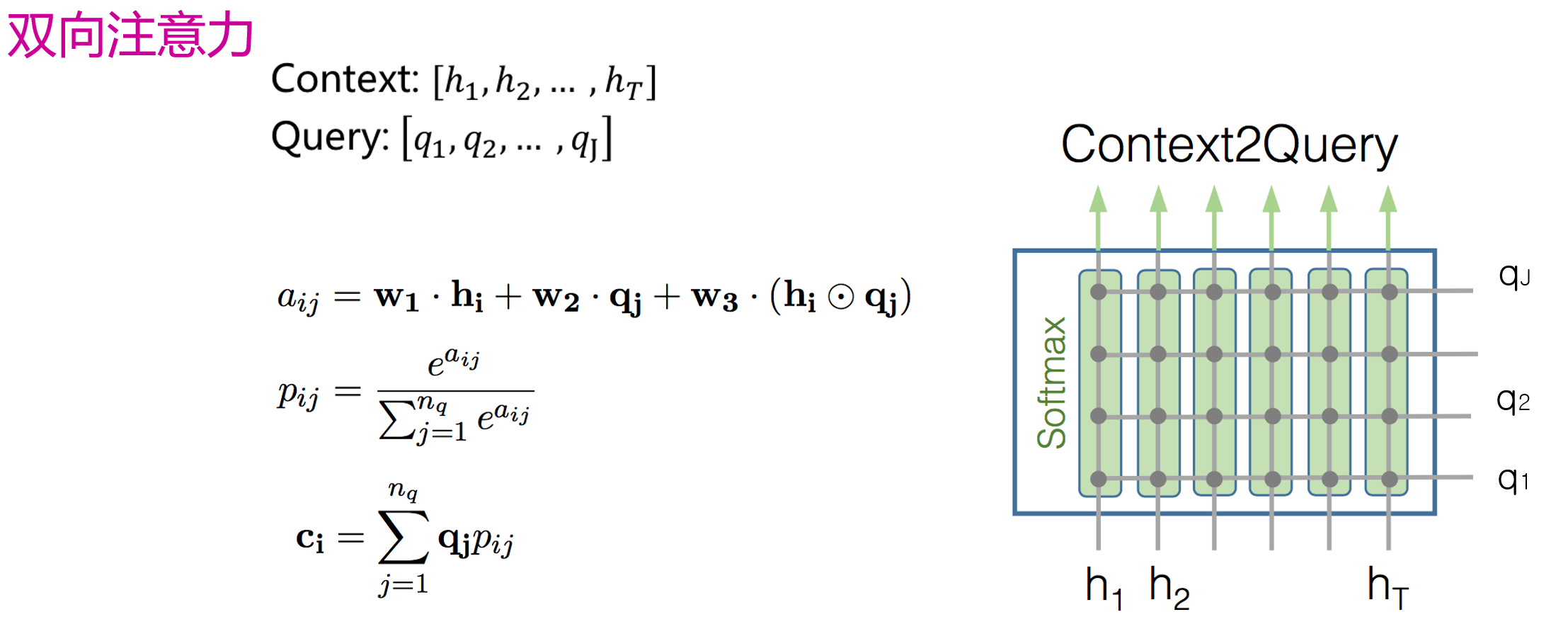
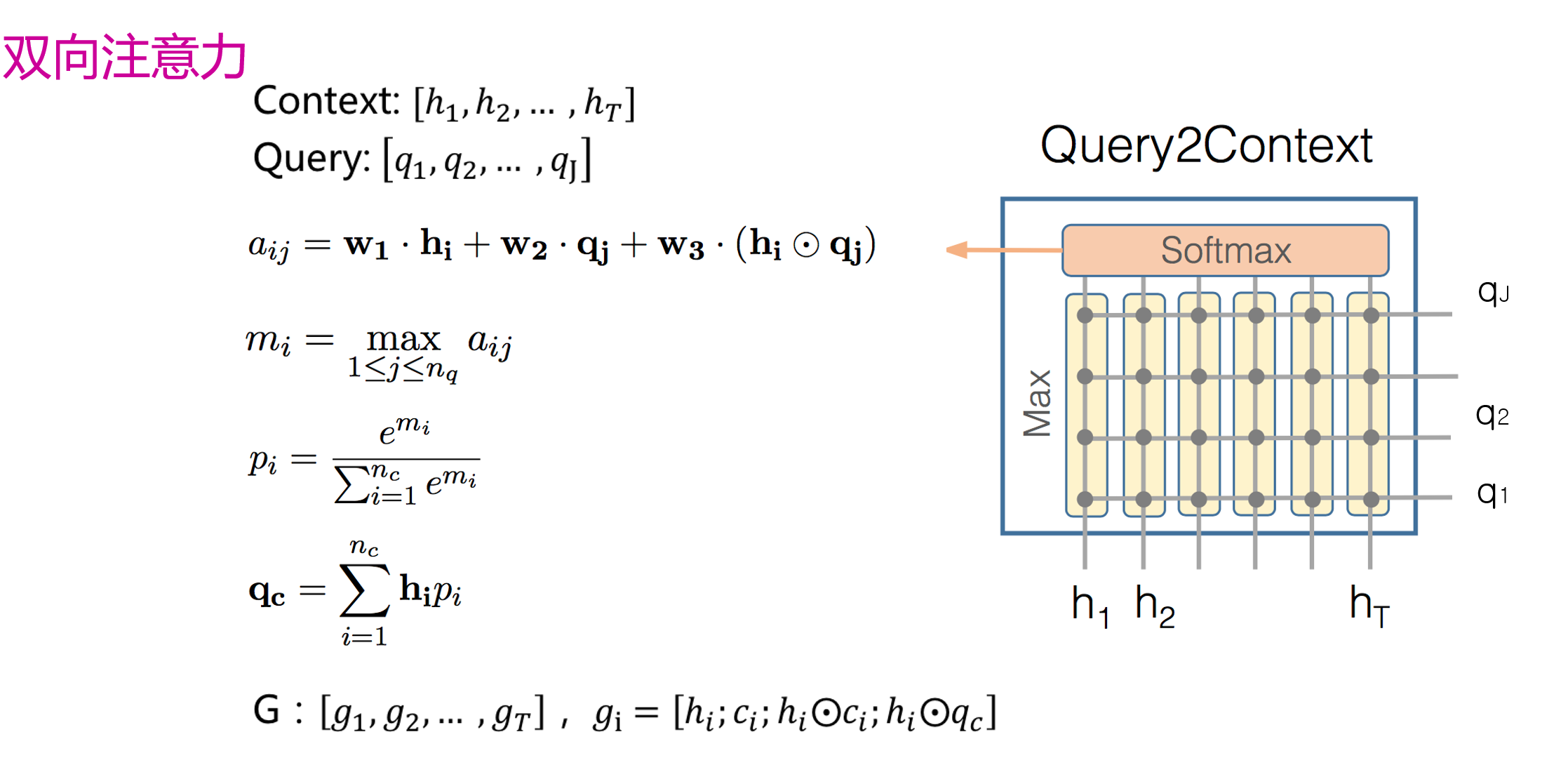
- 输出:文章中每一个词作为答案开始的概率和答案结束的概率
基于策略的机器阅读:
Improving Machine Reading Comprehension with General Reading Strategies,NAACL
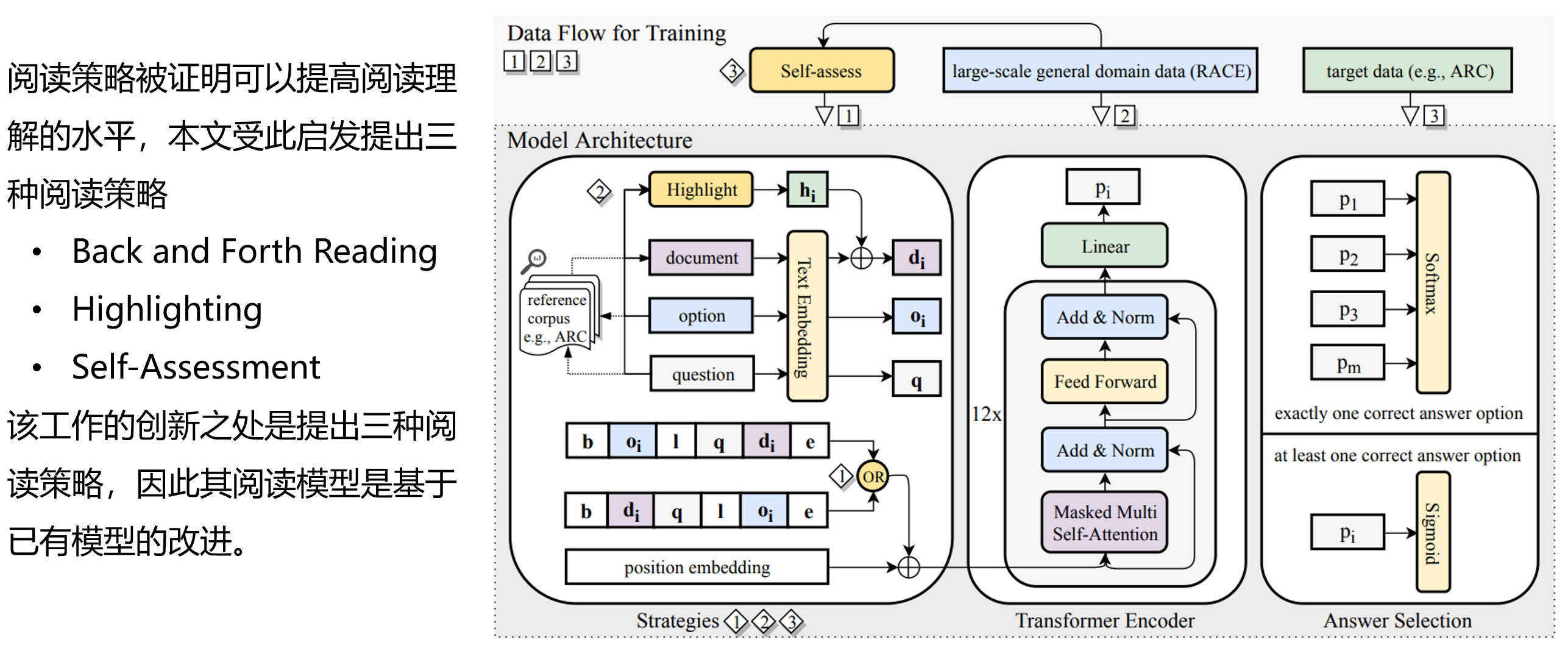
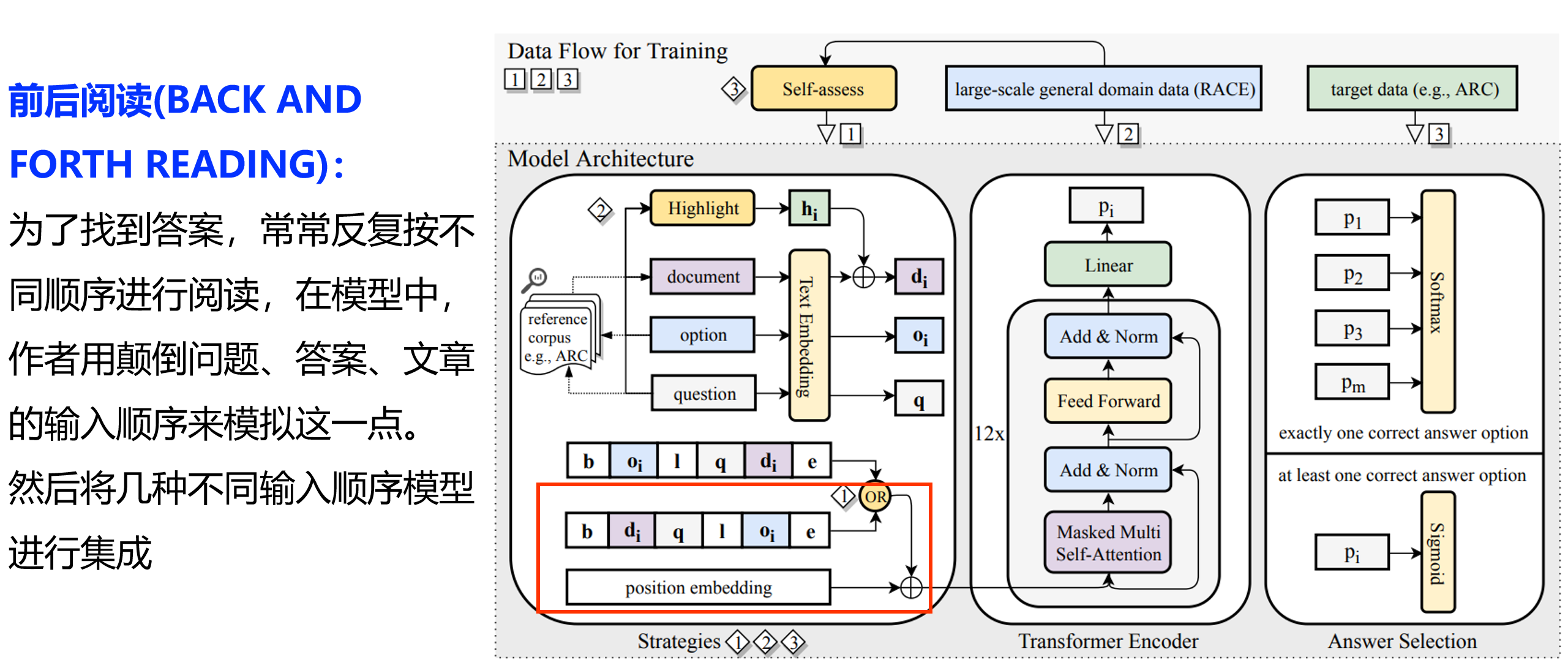
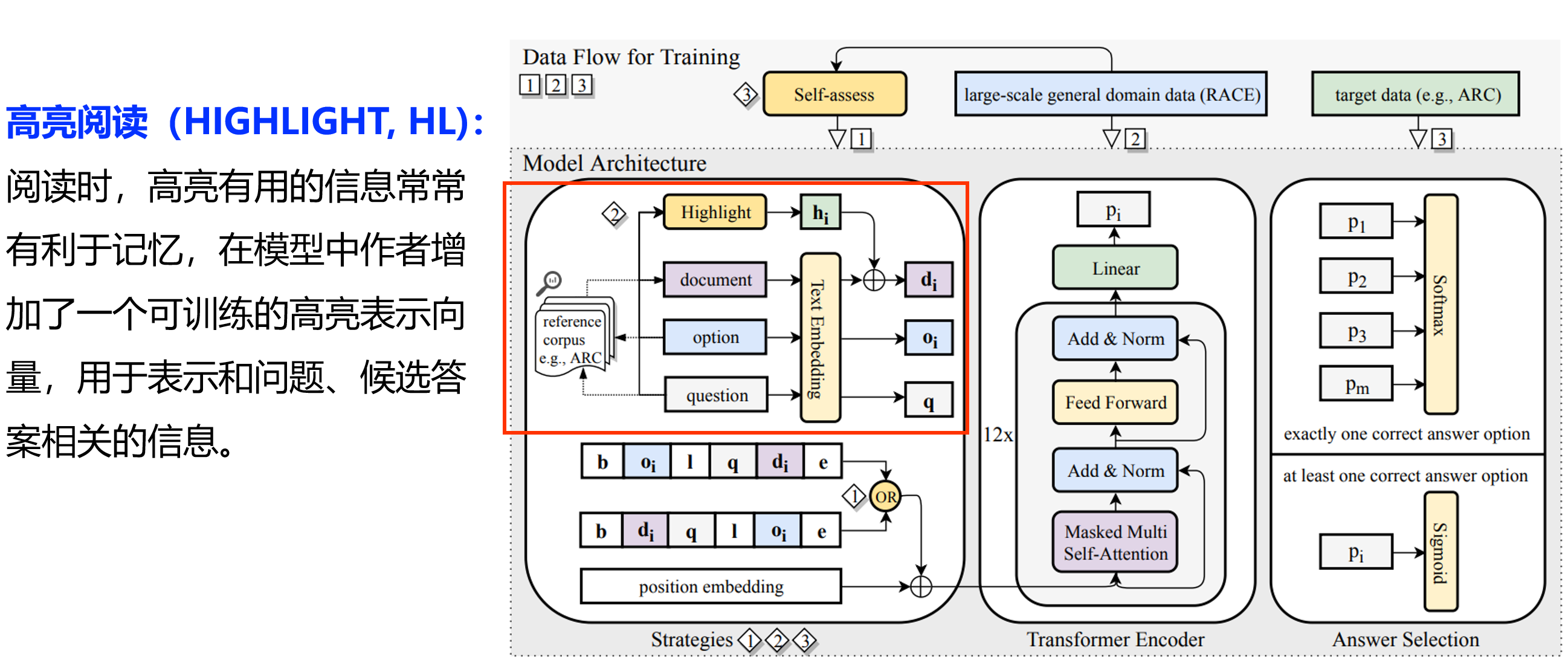
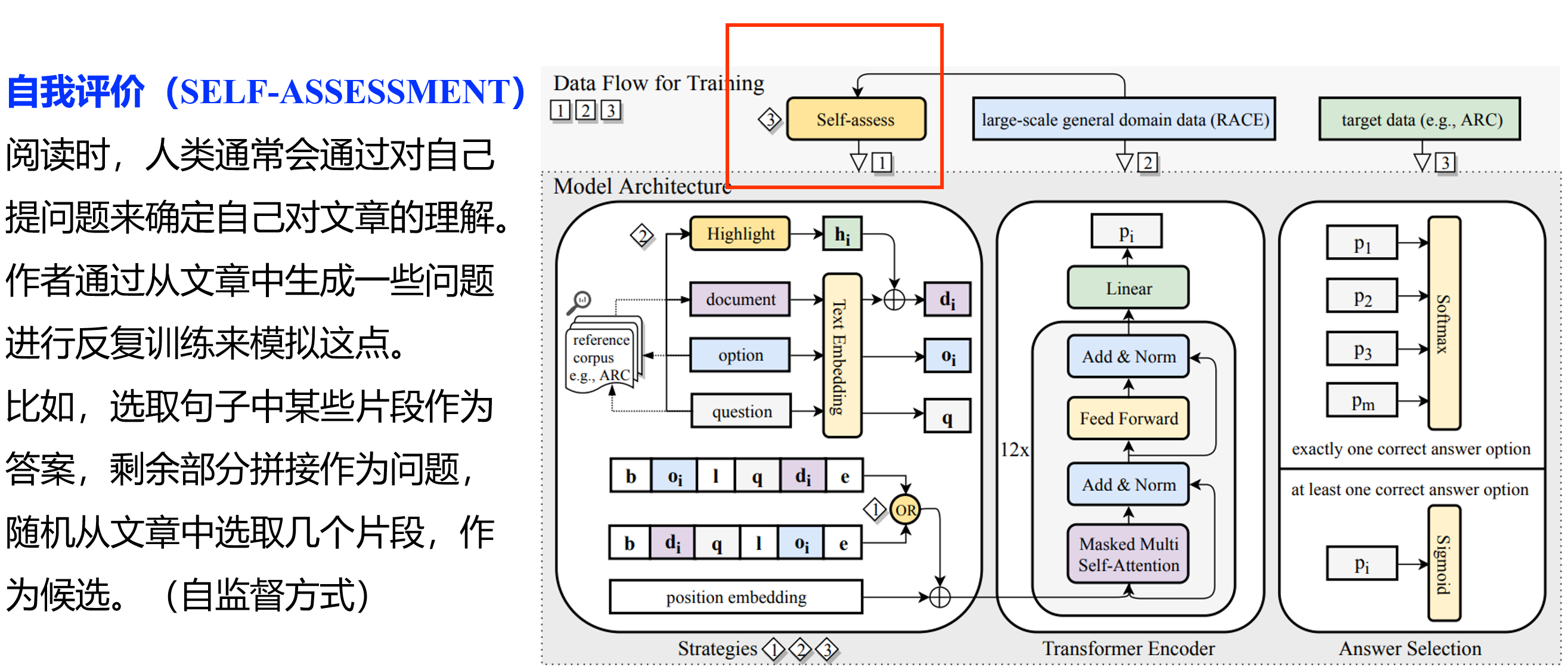
基于蕴含的多模态问答模型(ACL)
Check It Again:Progressive Visual Question Answering via Visual Entailment
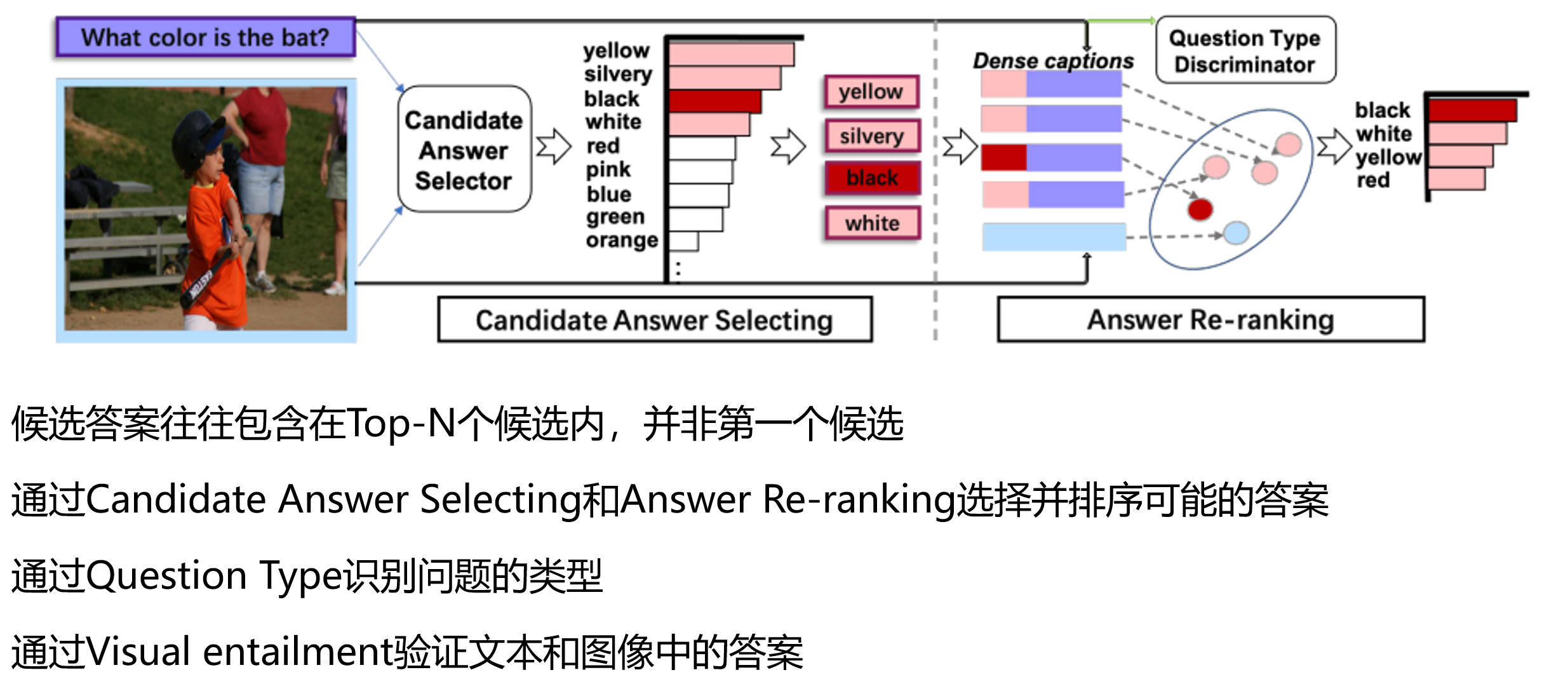
知识蒸馏
什么是知识蒸馏:
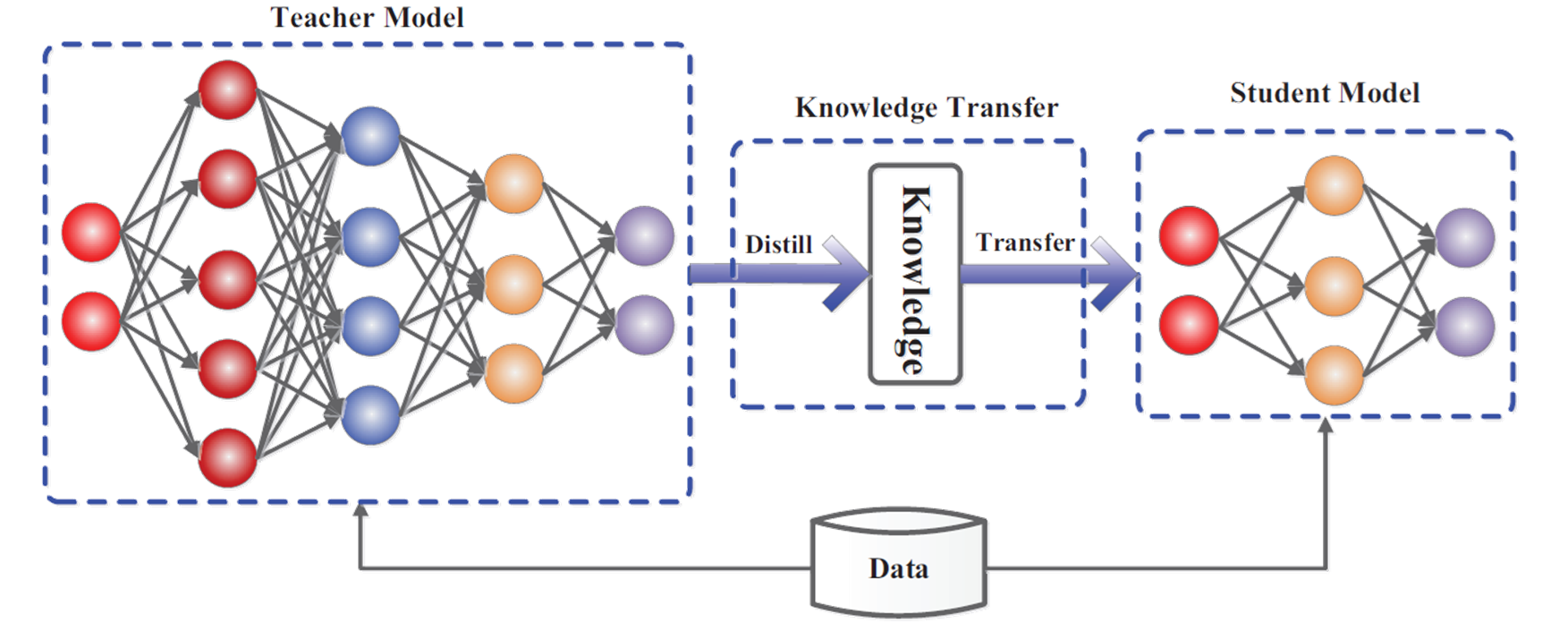
知识蒸馏是一种模型压缩方法,是一种基于“教师-学生网络思想”的训练方法
Knowledge Distillation,顾名思义,就是将已经训练好的模型包含的知识(”Knowledge”),蒸馏(“Distill”)提取到另一个模型里面去。思想来自Hinton2015年的Distilling the Knowledge in a NN
为什么要知识蒸馏:
一般不区分训练和部署的模型,但是训练和部署之间存在着一定的不一致性:
在训练过程中,需要使用复杂的模型,大量的计算资源,以便从非常大、高度冗余的数据集中提取出信息。
在实验中,效果最好的模型往往规模很大,甚至由多个模型集成得到。而大模型不方便部署到服务中去,常见的瓶颈如下:
- 推断速度慢
- 对部署资源要求高(内存、显存等)
在部署时,对延迟以及计算资源有严格限制。
因此,模型压缩,也就是在保证性能的前提下减少模型参数量,是一个非常重要的问题。而知识蒸馏属于模型压缩的一种。
知识蒸馏的基本框架:
知识蒸馏使用的是Teacher—Student模型,其中teacher是“知识”的输出者,student是“知识”的接受者。知识蒸馏的过程分为2个阶段:
- 原始模型训练: 训练"Teacher模型", 简称为Net-T,它的特点是模型相对复杂,也可以由多个分别训练的模型集成而成。对"Teacher模型"不作任何关于模型架构、参数量、是否集成方面的限制,唯一的要求就是,对于输入X, 其都能输出Y,其中Y经过softmax的映射,输出值对应相应类别的概率值。
- 精简模型训练: 训练"Student模型", 简称为Net-S,它是参数量较小、模型结构相对简单的单模型。同样的,对于输入X,其都能输出Y,Y经过softmax映射后同样能输出对应相应类别的概率值。
蒸馏什么知识:
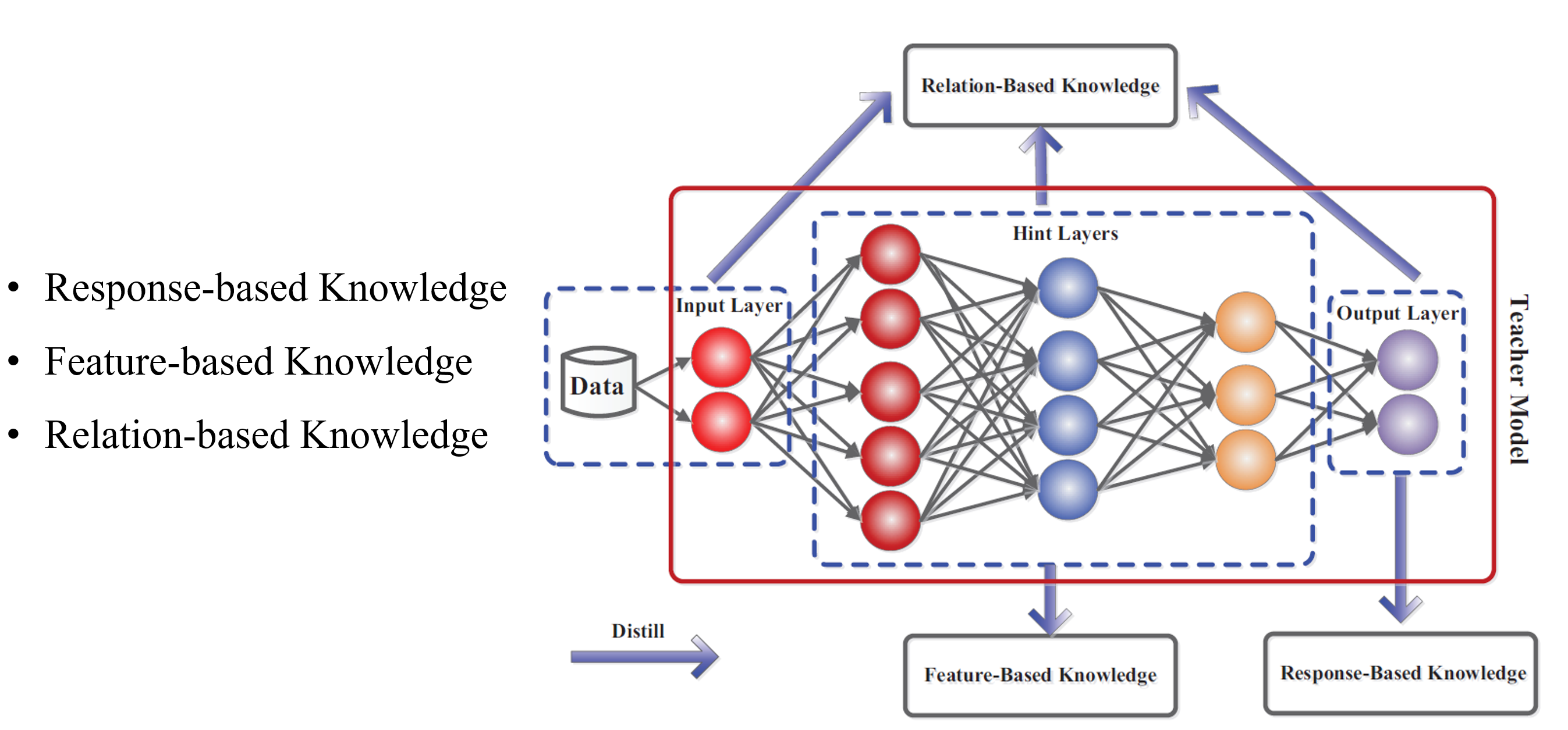
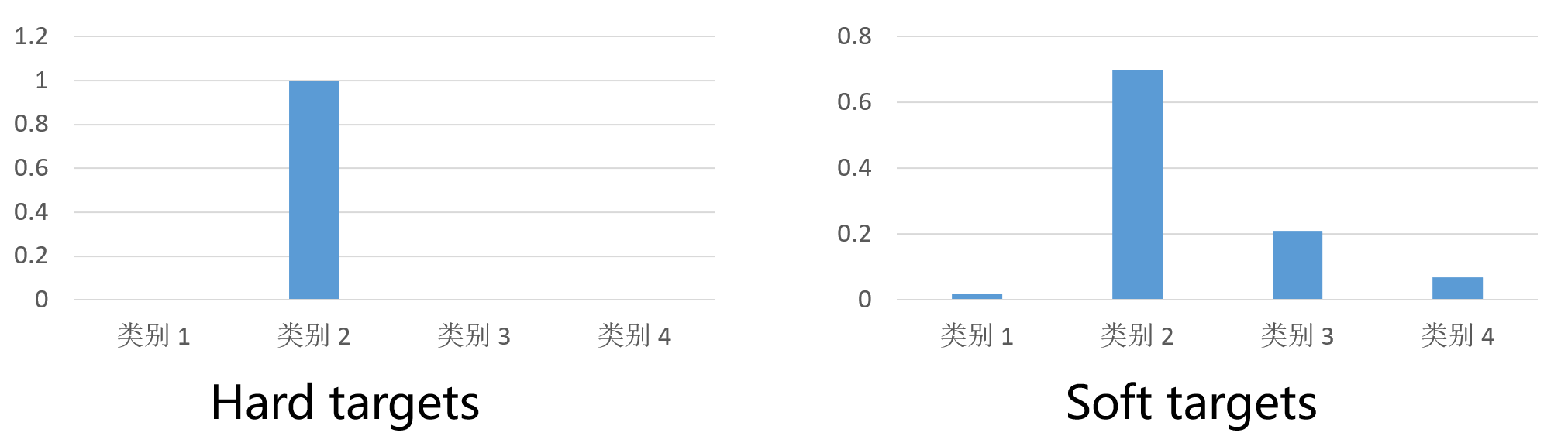
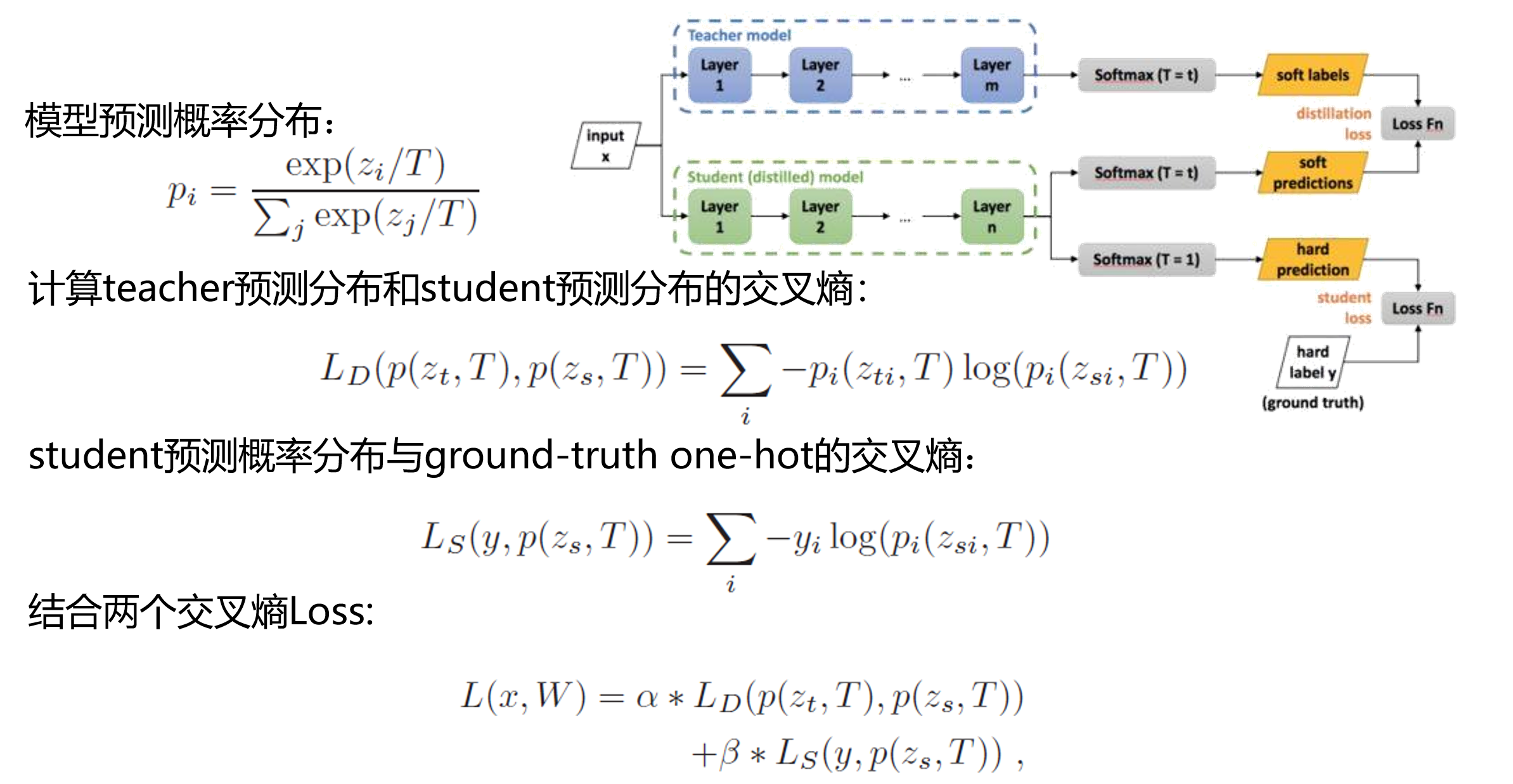
- Response-based Knowledge:
在进行知识蒸馏时,已经有了一个泛化能力比较强的模型Net-T,用它蒸馏训练Net-S,
让Net-S去学习Net-T的泛化能力
方法是使用softmax层输出的类别概率作为“soft target”
传统training过程(hard targets): 对ground truth求极大似然
KD的training过程(soft targets): 用Net-T的类别概率作为soft targets
- Feature-based Knowledge:

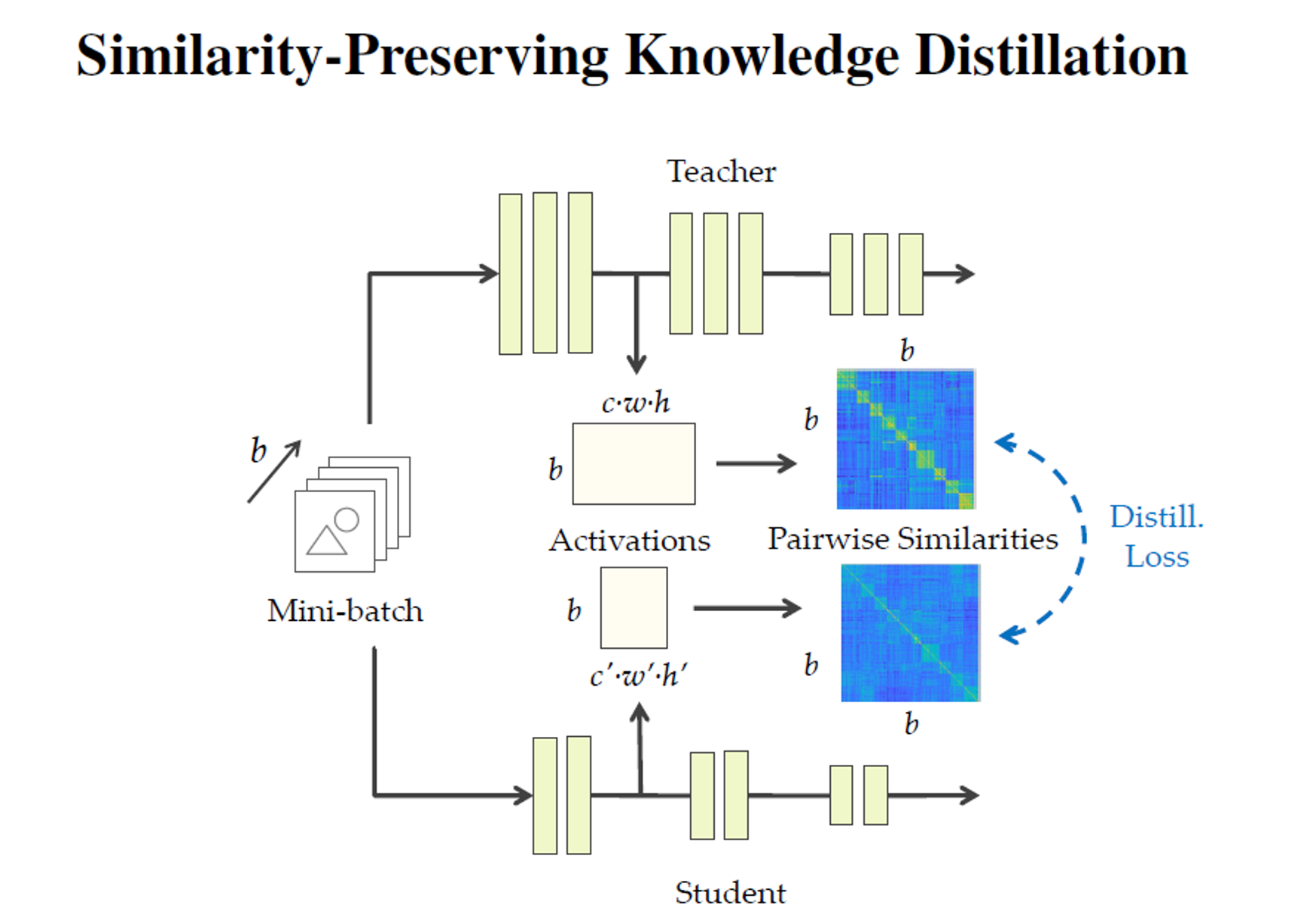
如何蒸馏:
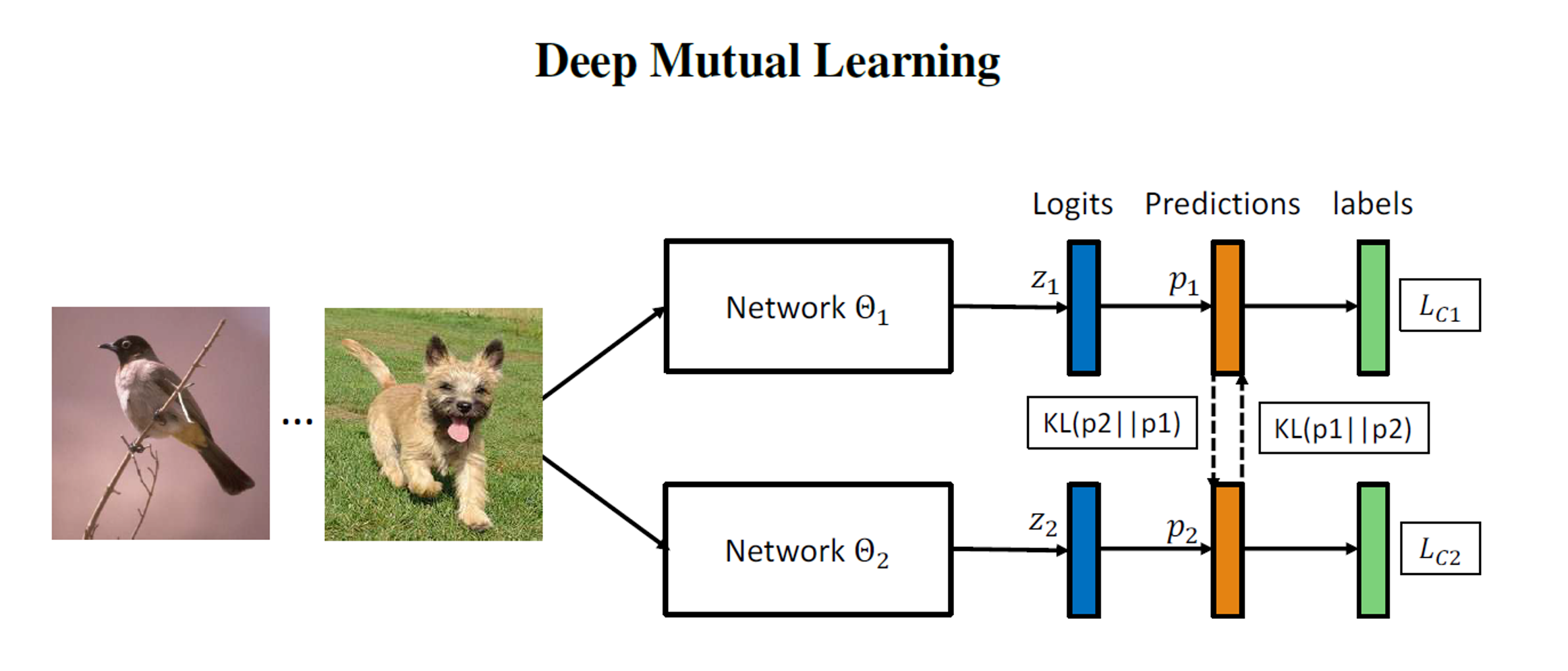

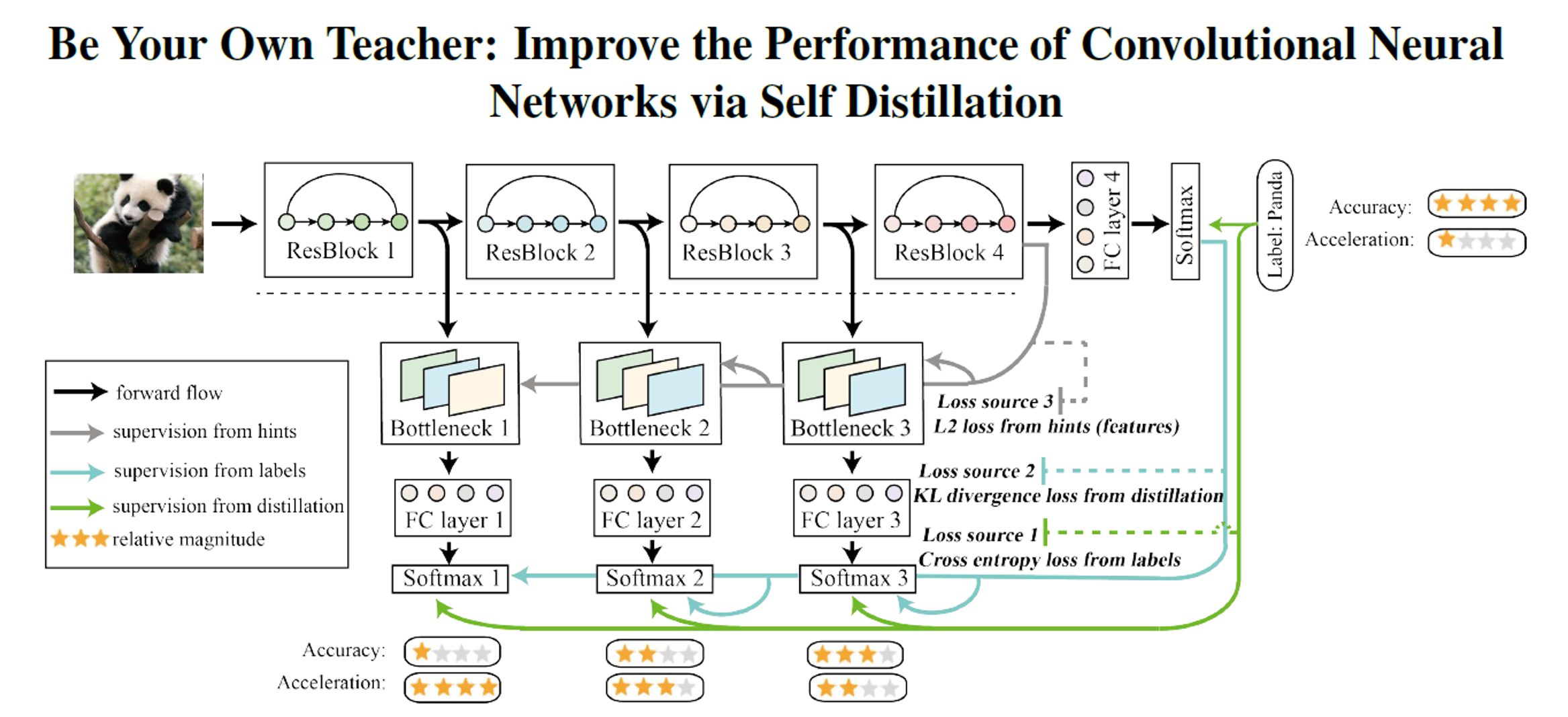
实践部分的模型:
- 微软 EMNLP Patient Knowledge Distillation for BERT Model Compression
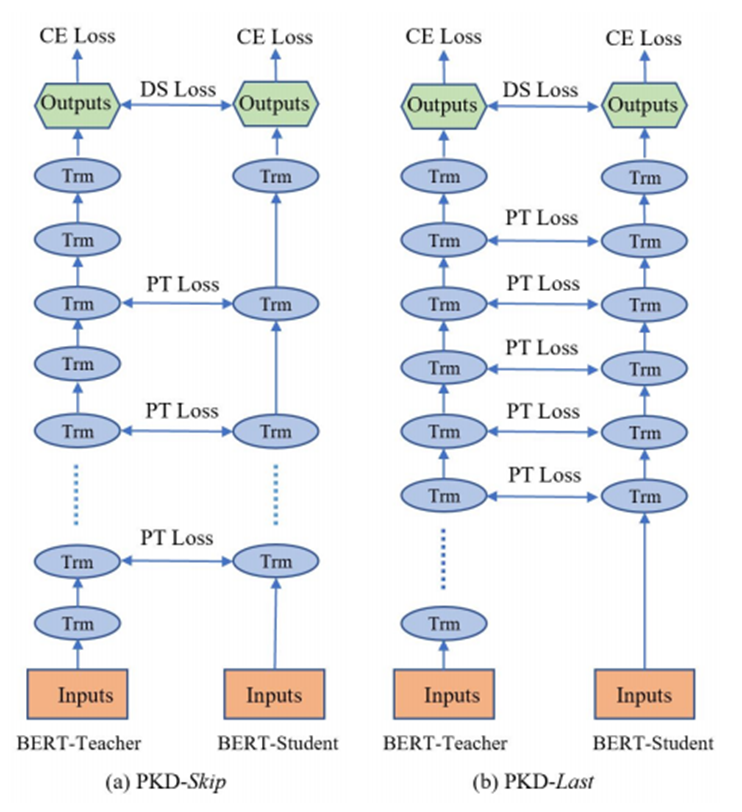
图(a)Student网络每隔2层学习Teacher网络的输出。
图(b)Student网络学习Teacher网络的后6层输出。
老师在教学生的时候,学生只记住了最终的答案,但是对于中间的过程确完全没有学习。
这样在遇到新问题的时候,学生模型犯错误的概率更高。
基于这个假设,文章提出了一种损失函数,使得学生模型的隐藏层表示接近教师模型的隐藏层表示,从而让学生模型的泛化能力更强。文章称这种模型为“耐心的知识蒸馏”模型 (Patient Knowledge Distillation)。
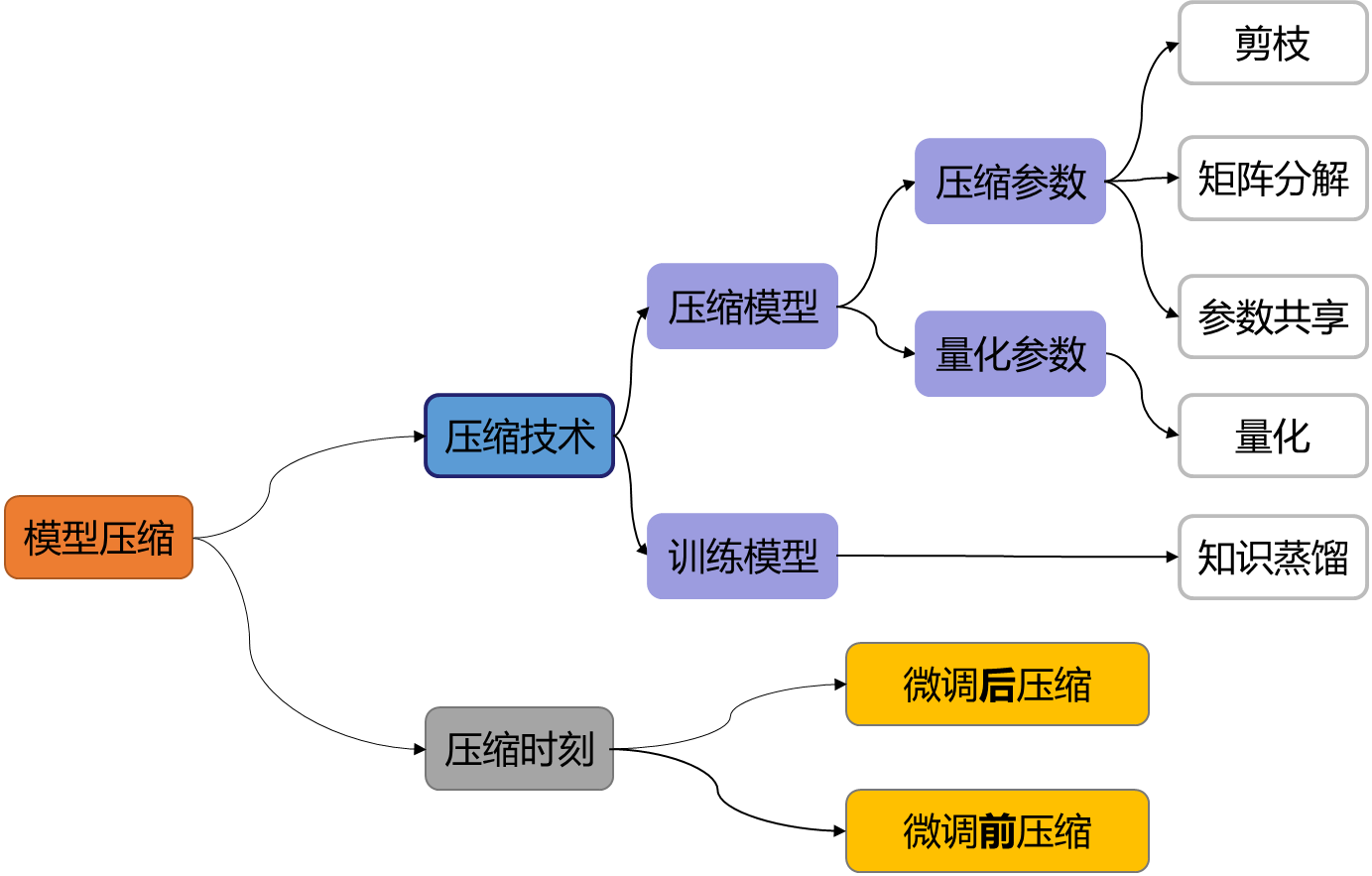
模型压缩:
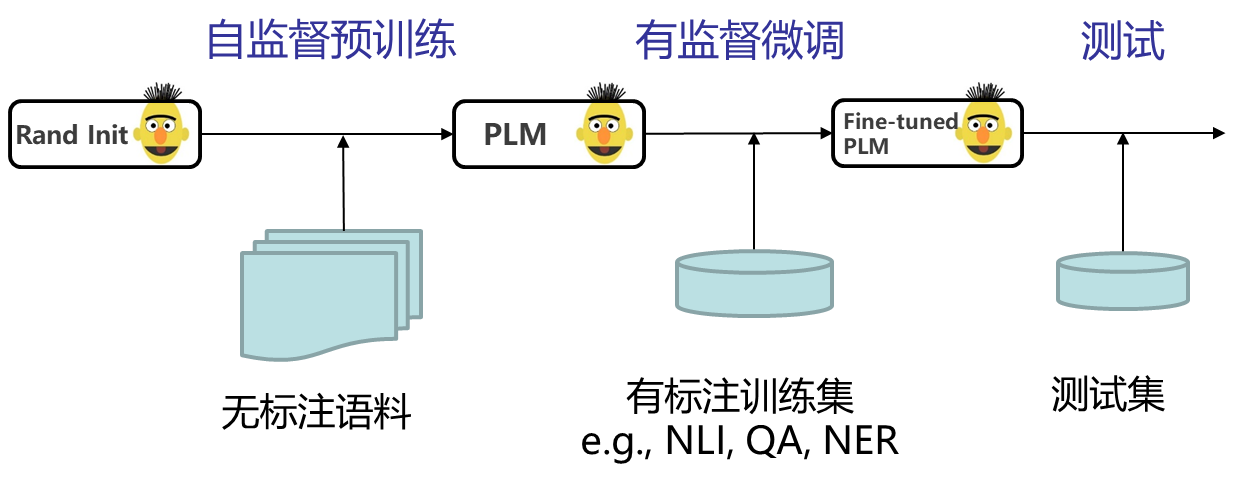
预训练-微调-测试:
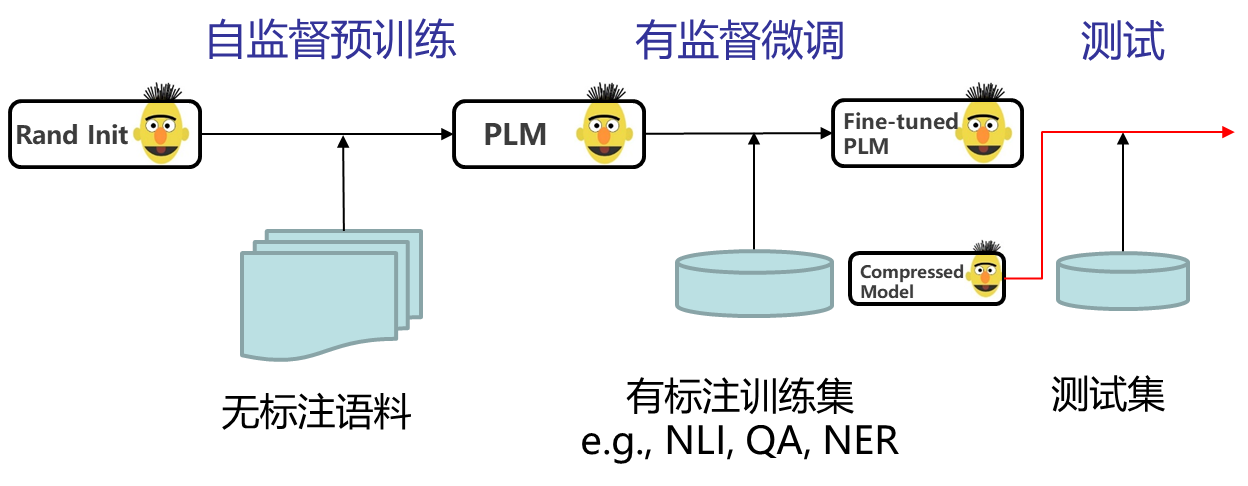
微调后压缩:
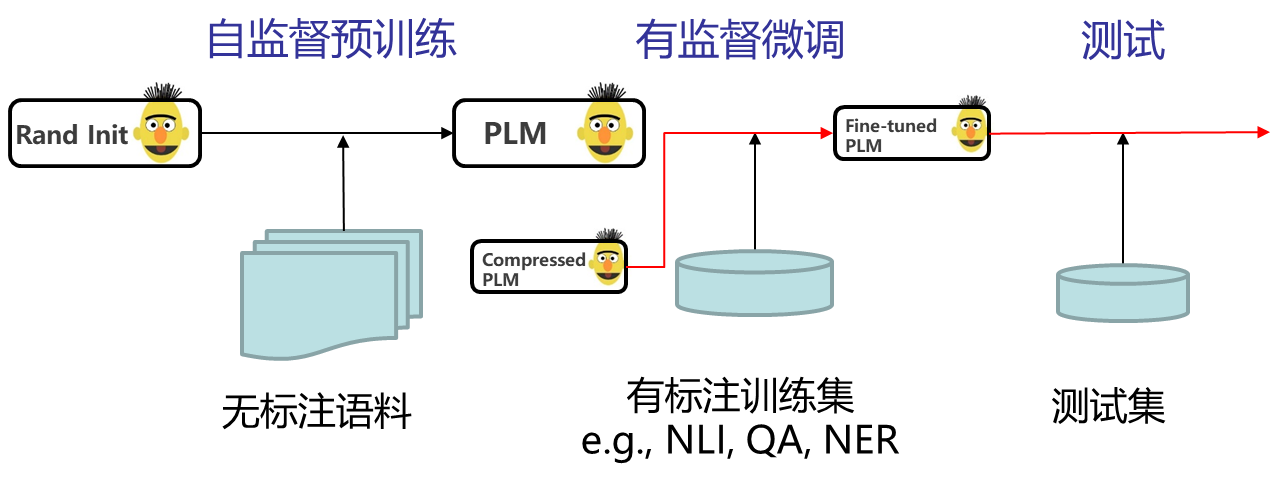
微调前压缩:
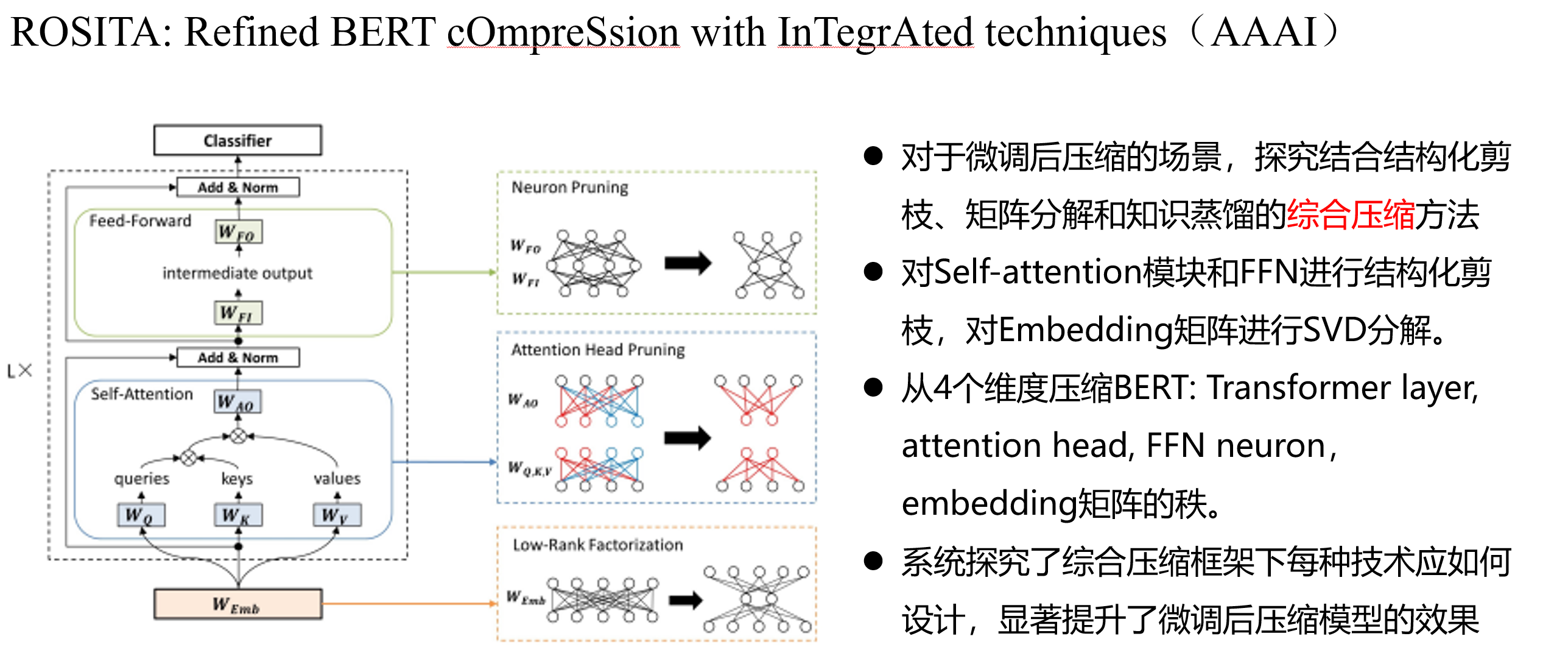
综合多种压缩策略:
知识蒸馏中的知识选择:
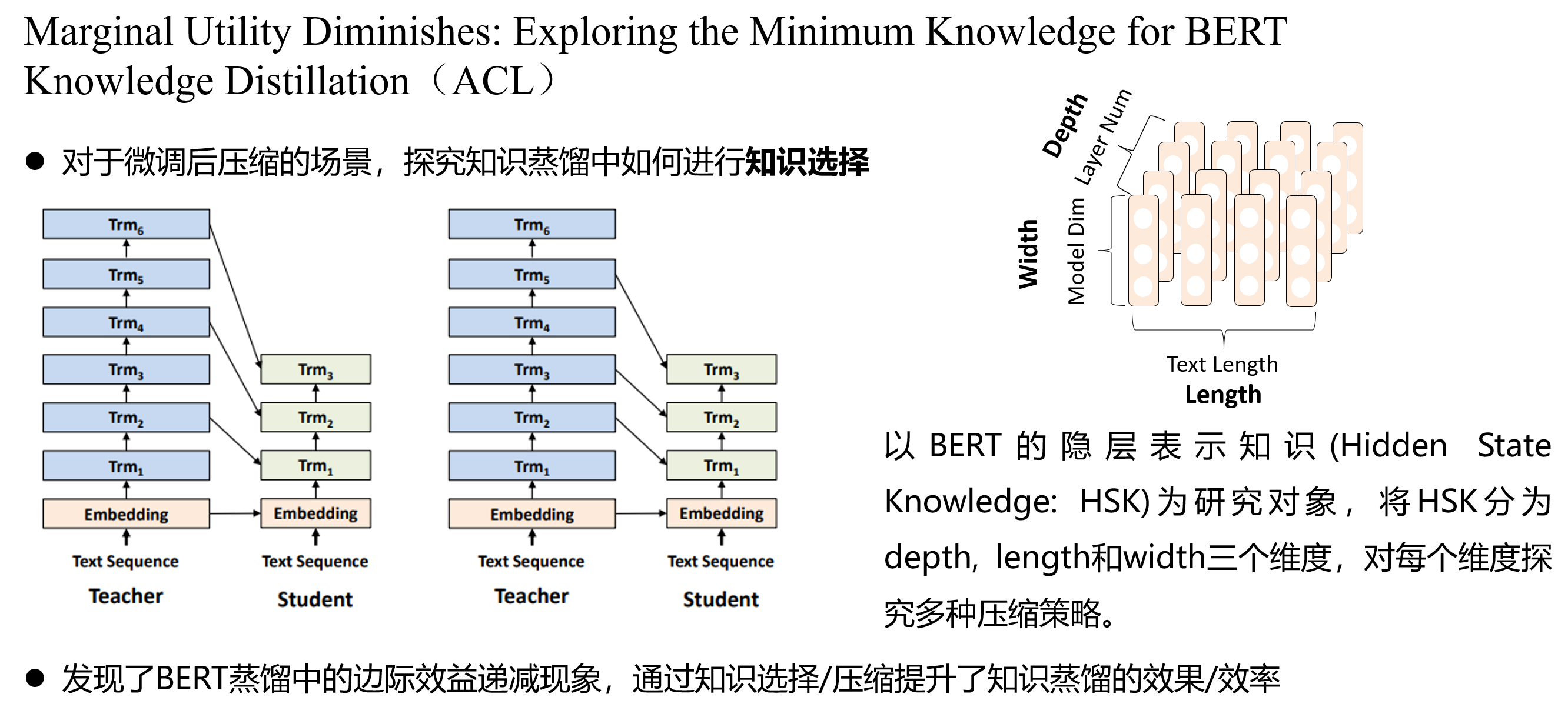
彩票假设(Winning Tickets):
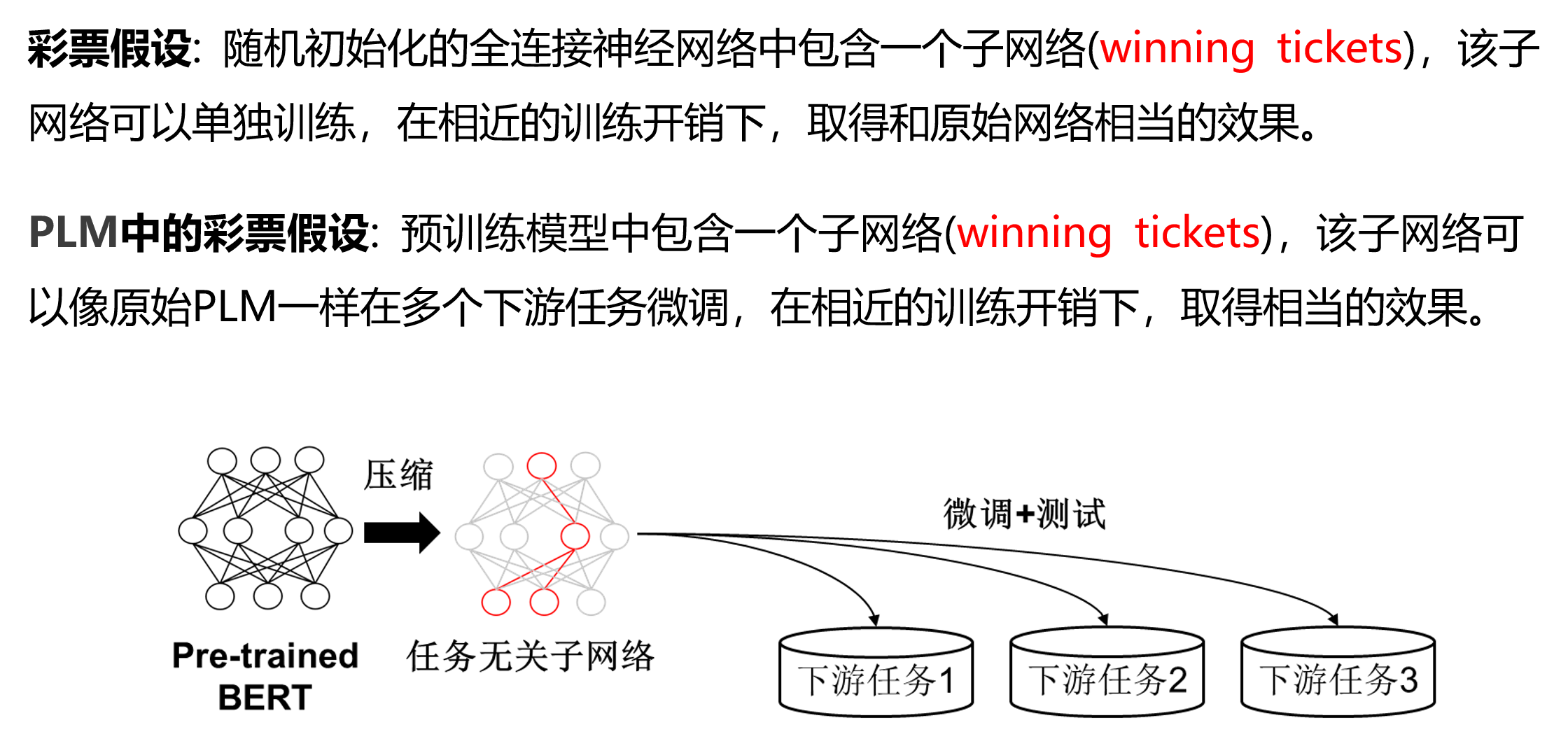
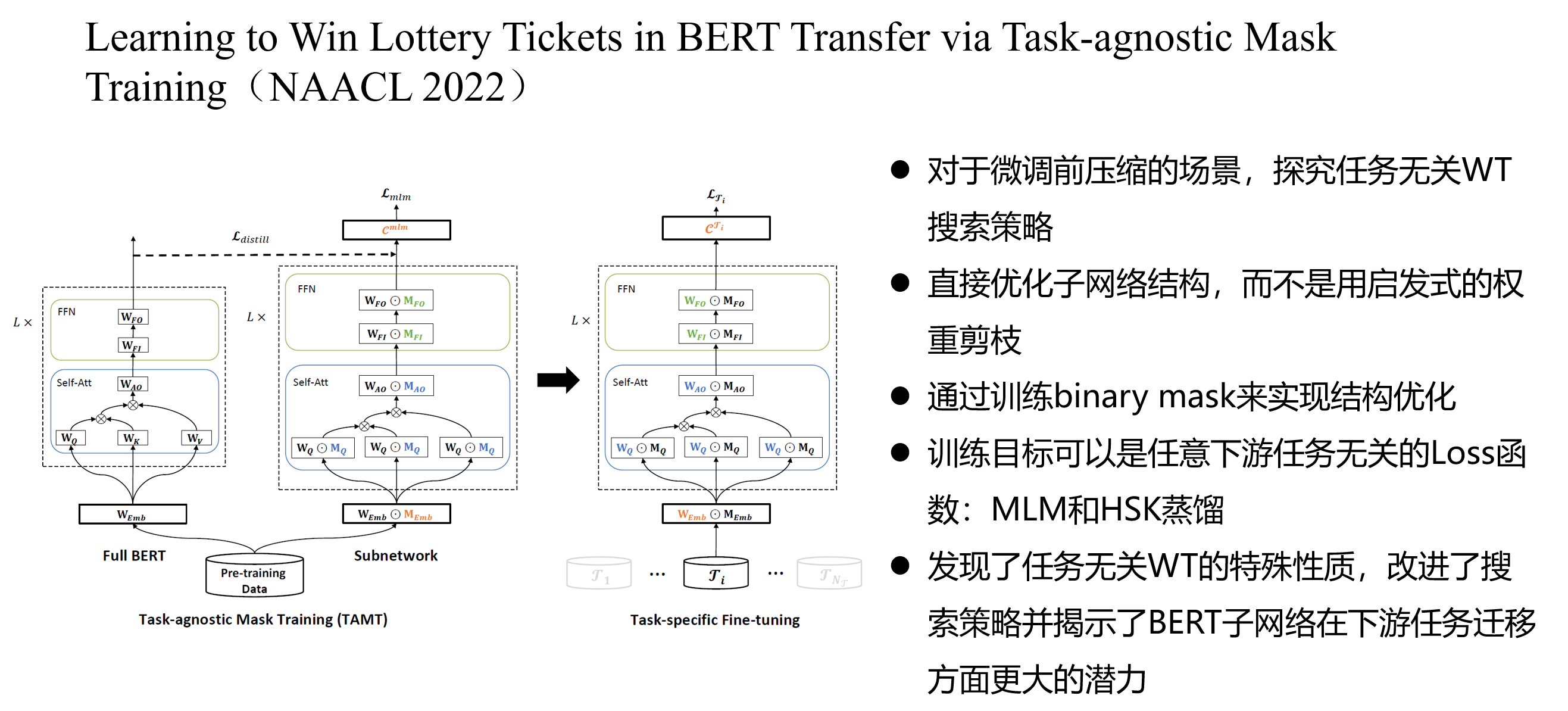
基于彩票假设的任务无关子网络搜索:
对抗与防御
机器阅读挑战—对抗阅读
Adversarial Examples for Evaluating Reading Comprehension Systems,EMNLP

对抗样本和对抗训练

对抗训练

CV中的对抗攻击与防御
NLP中的对抗攻击与防御
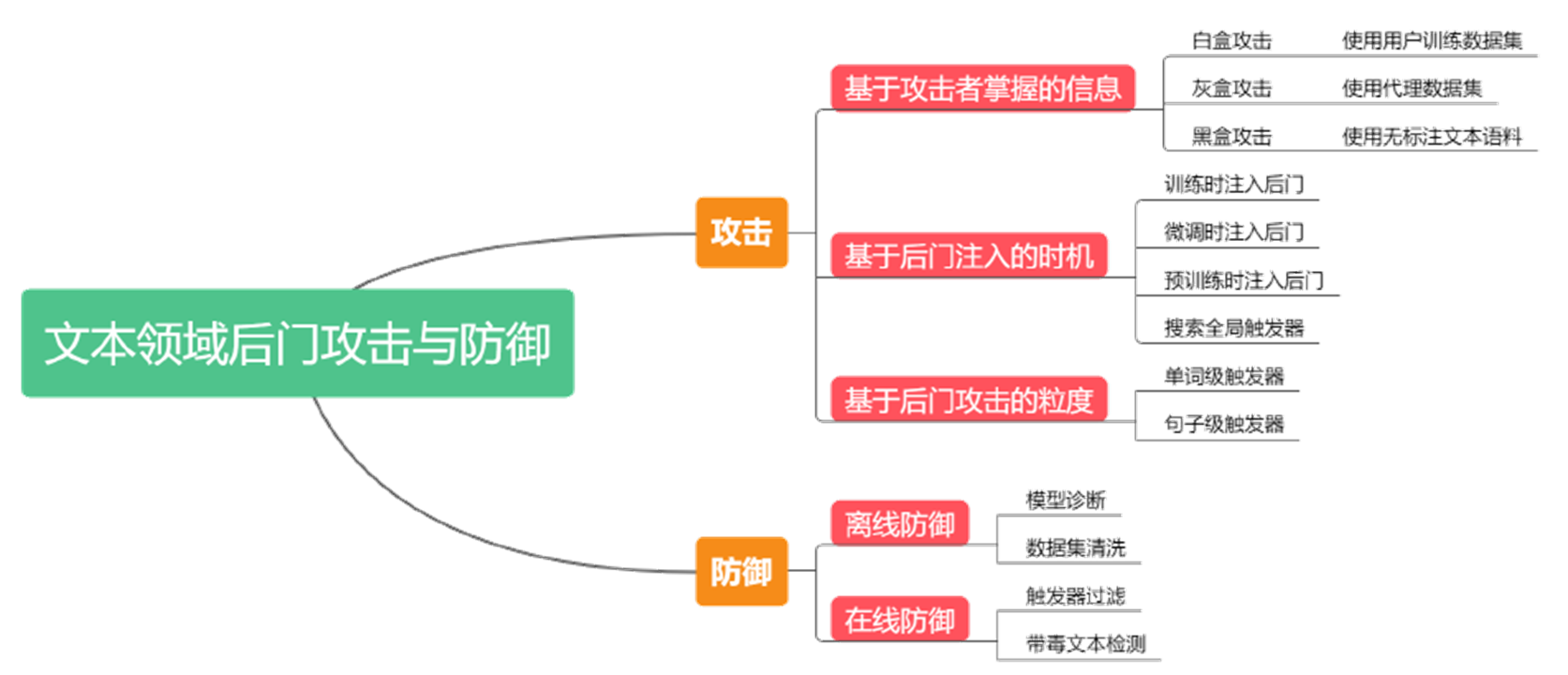
元学习
什么是元学习 Meta learning
- 元学习(Meta-Learning)起源于General AI(普适人工智能),目标是让机器学会学习(Learning-to-Learn),让机器变得更加智能,代替人类完成更多复杂多变的任务。
- 一般将元学习视为深度学习模型的补充,用于提高模型的泛化能力,将模型更好地泛化到差别较大的任务中。
- 通常使用预训练模型结合调参的模式,在保持深度模型精度的同时,额外提高深度学习模型的泛化能力,减弱过拟合,提高深度学习模型在分布外任务的表现。
- 早在1987年,科学家就提出了元学习,指的是机器与环境交互,不断获取信息,进行自我更新,适应不断变化的环境,在没有任何人为干预的场景下,机器能自发地适应环境并且进化,学会如何处理遇到的新任务。
- 元,指的是万物的本质
元学习 Meta learning = learn to learn
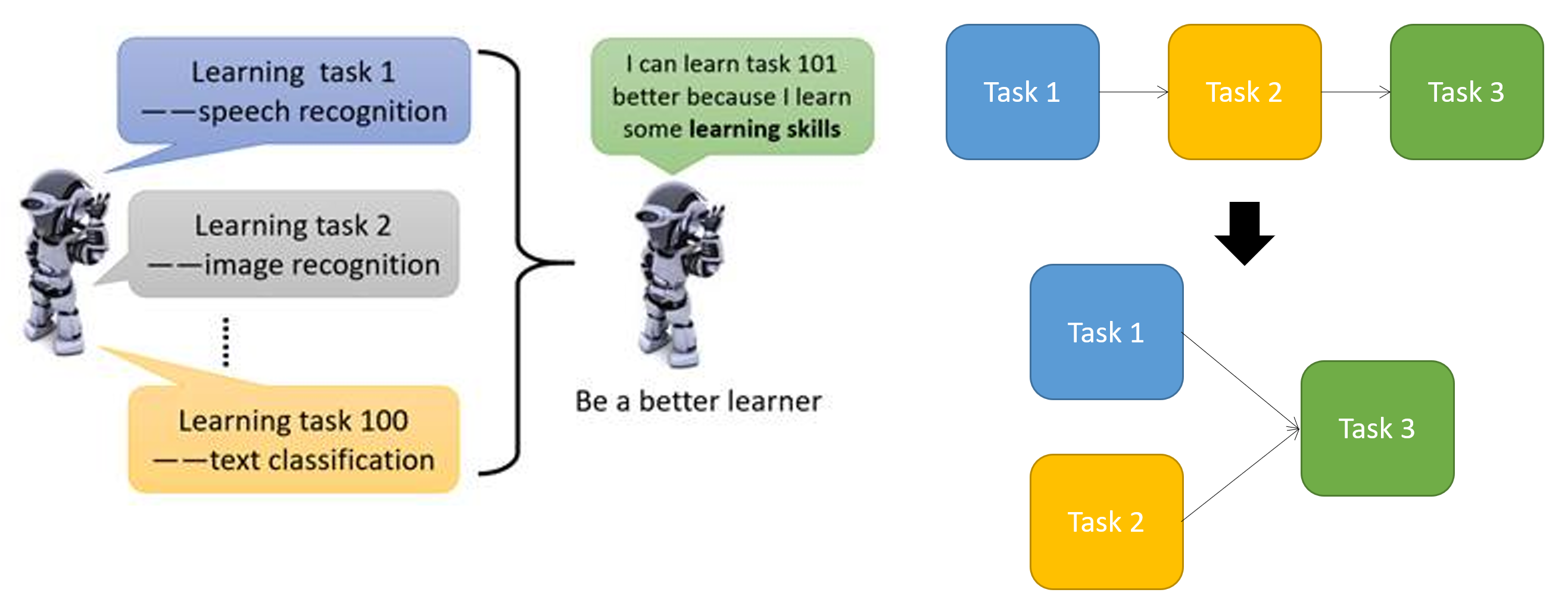
meta learning vs transfer leaning vs multi-task learning vs few-shot learning
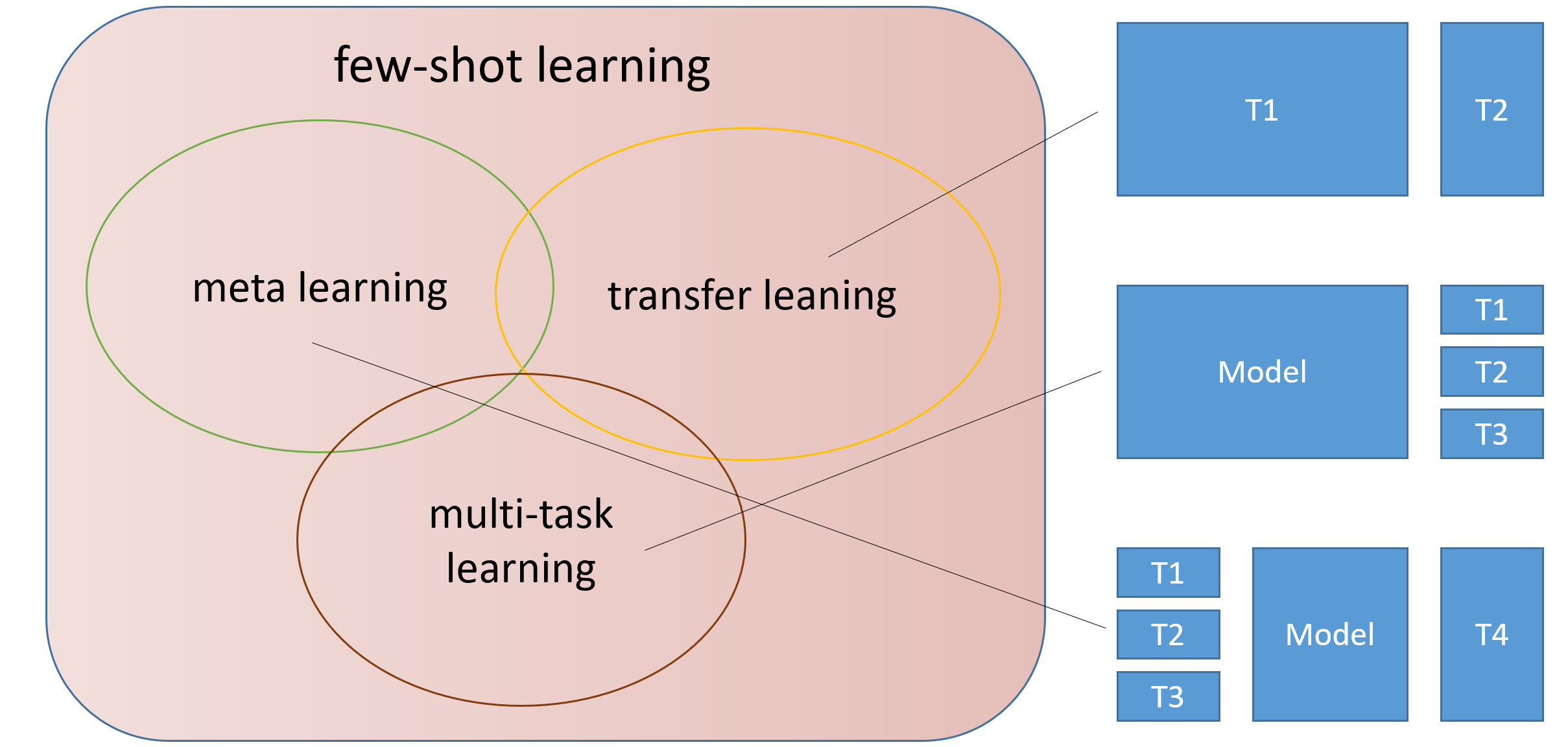
神经网络的学习结构:
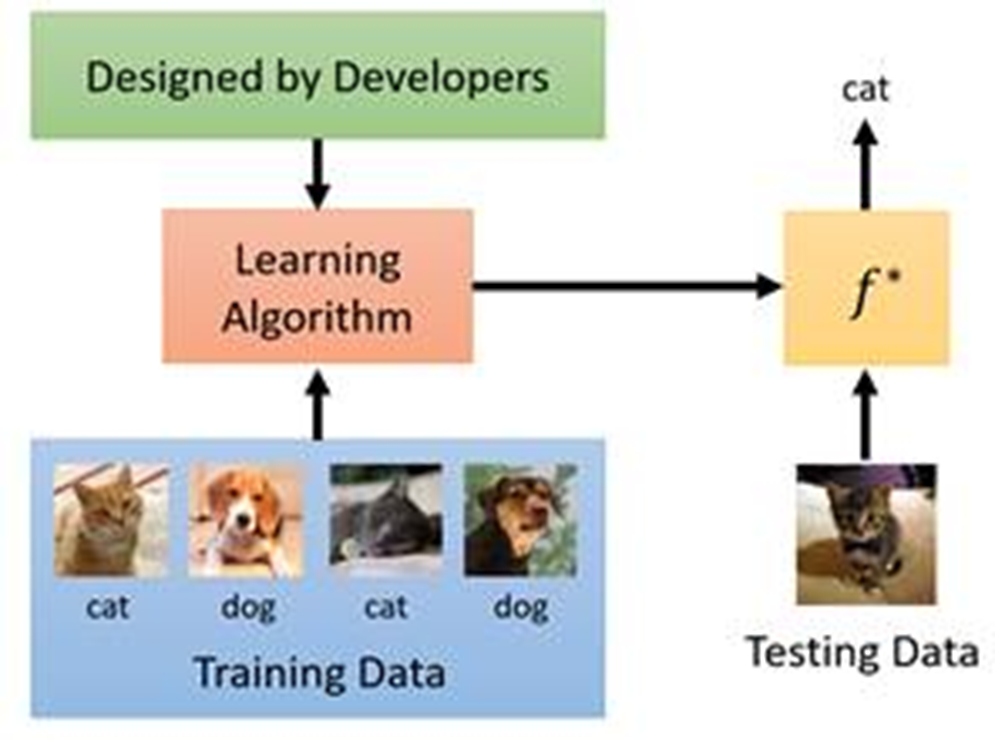
- 输入数据
- 神经网络
- 学习算法
TODO: 通过定义的学习算法使用神经网络去适配训练数据
元学习结构:
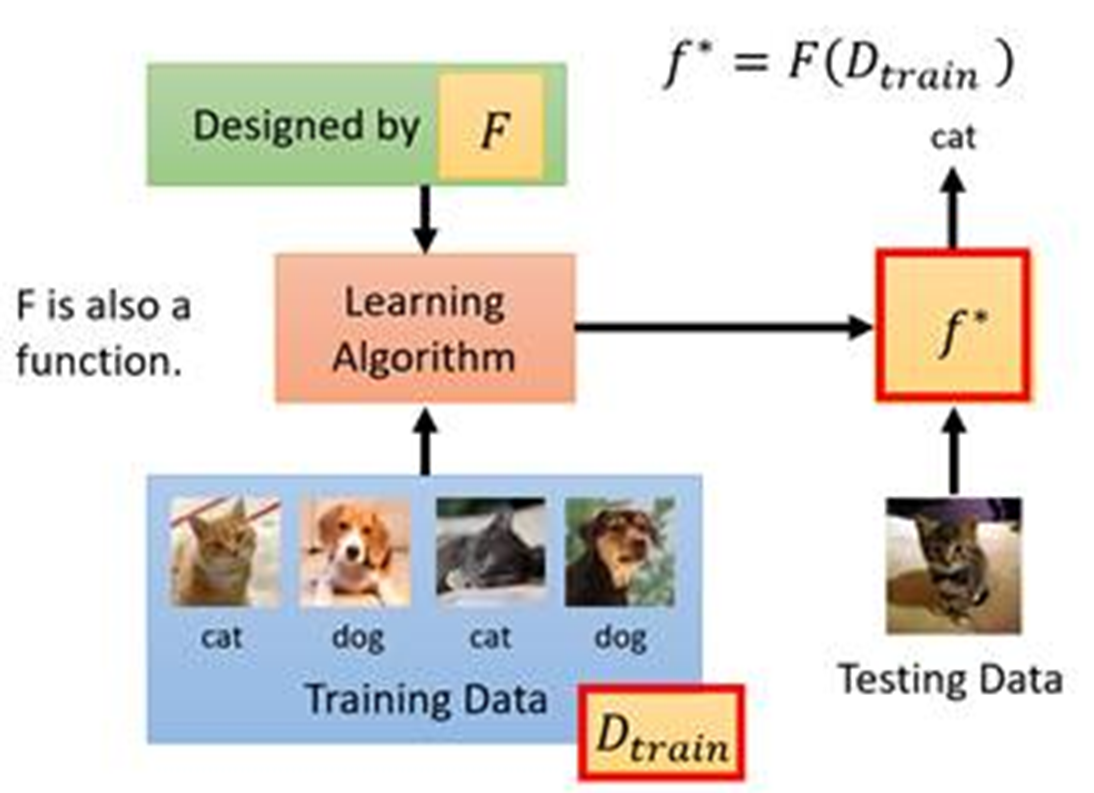
- 训练数据
- 神经网络函数
- 机器定义的学习算法
TODO: 机器学习设计学习算法
- What is f ?*

- What is F ?
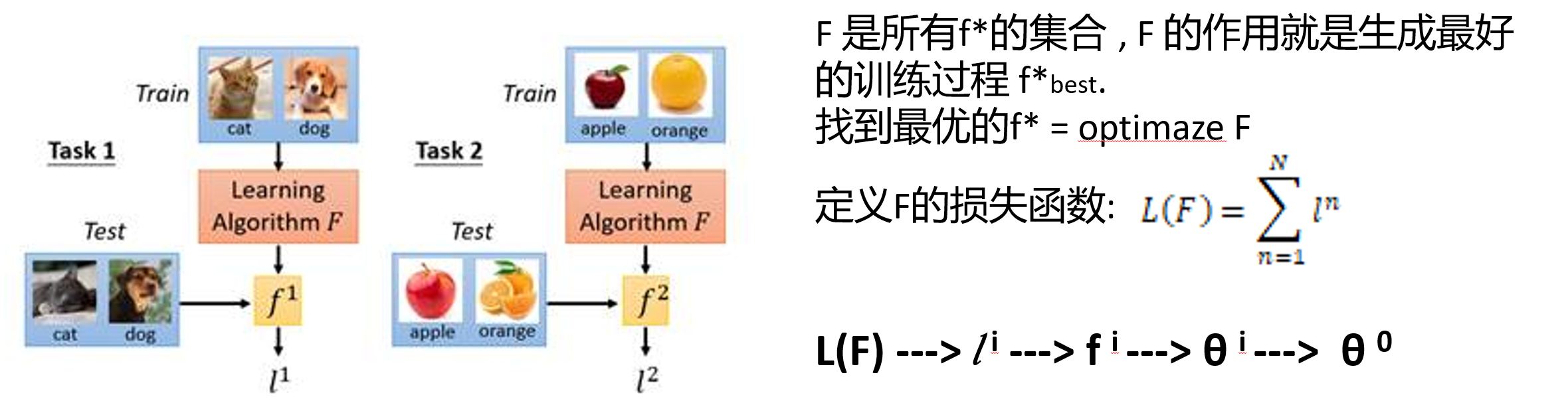
Meta Learning的简单实例:MAML
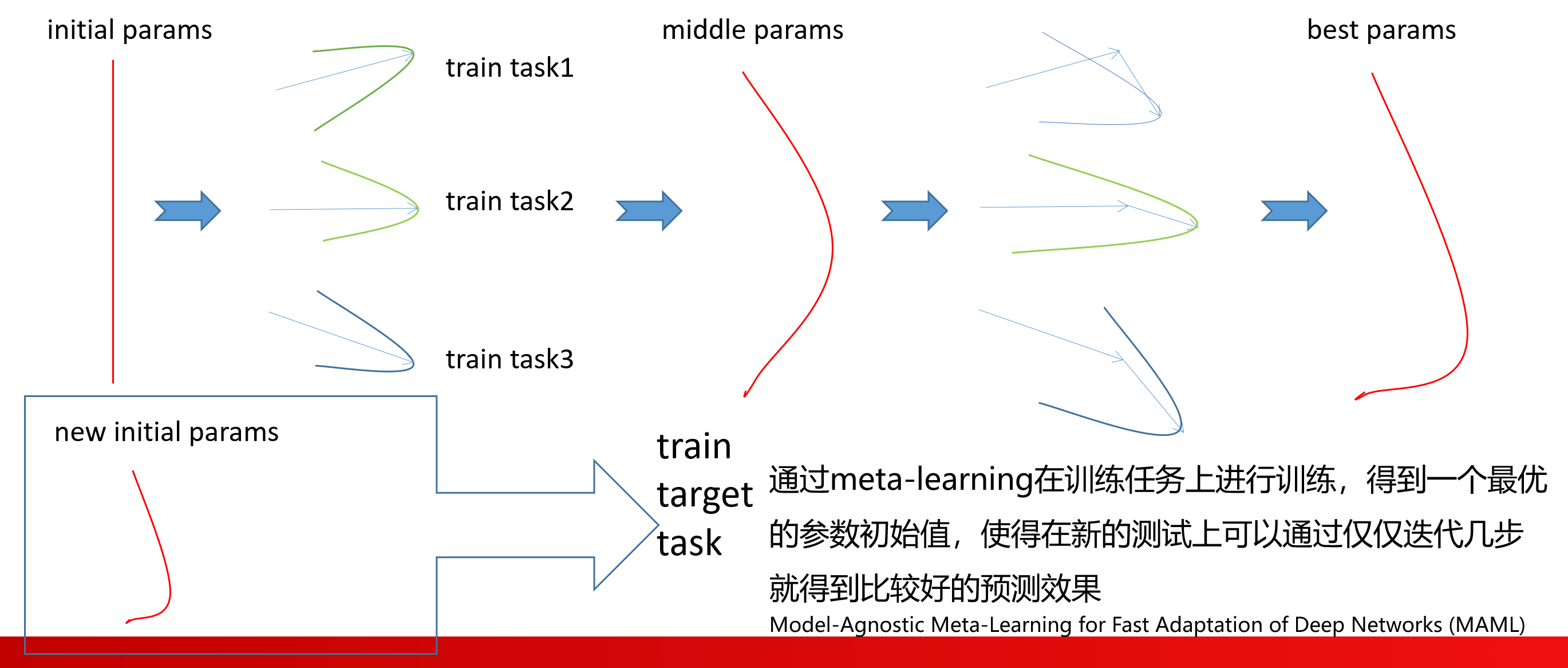
目的:优化网络的初始参数,将F视为每一个模型参数的函数,而每一个模型参数又是同一组初始参数的函数,最终通过优化F优化网络初始参数。
知识增强
知识库问答(KBQA)和基于知识的机器阅读(KBMRC)
知识库问答和基于知识的机器阅读理解是两个不同的任务:
(1)KBQA先要有个知识库,问题答案的来源是结构化数据构成的知识库。关键技术点是对问题中实体的识别和把实体之间对应的关系映射到知识库(理解查询意图)。
(2)KBMRC来源是一些非结构化的语料,结合外部知识(维基百科或者知识图谱)进行推理,通过阅读理解找到答案进行返回,答案一般来自于原文。
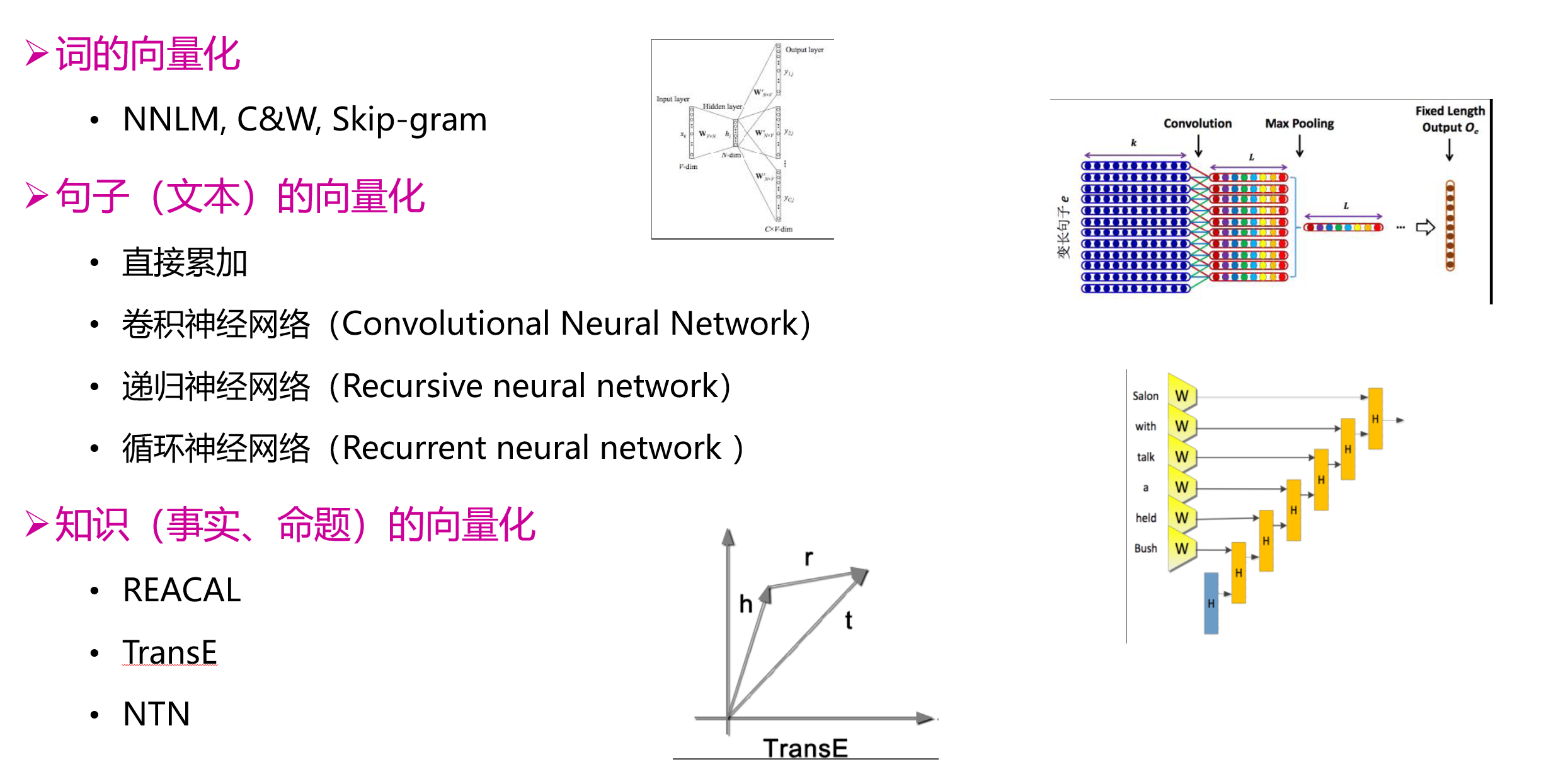
文本、知识的深度表示
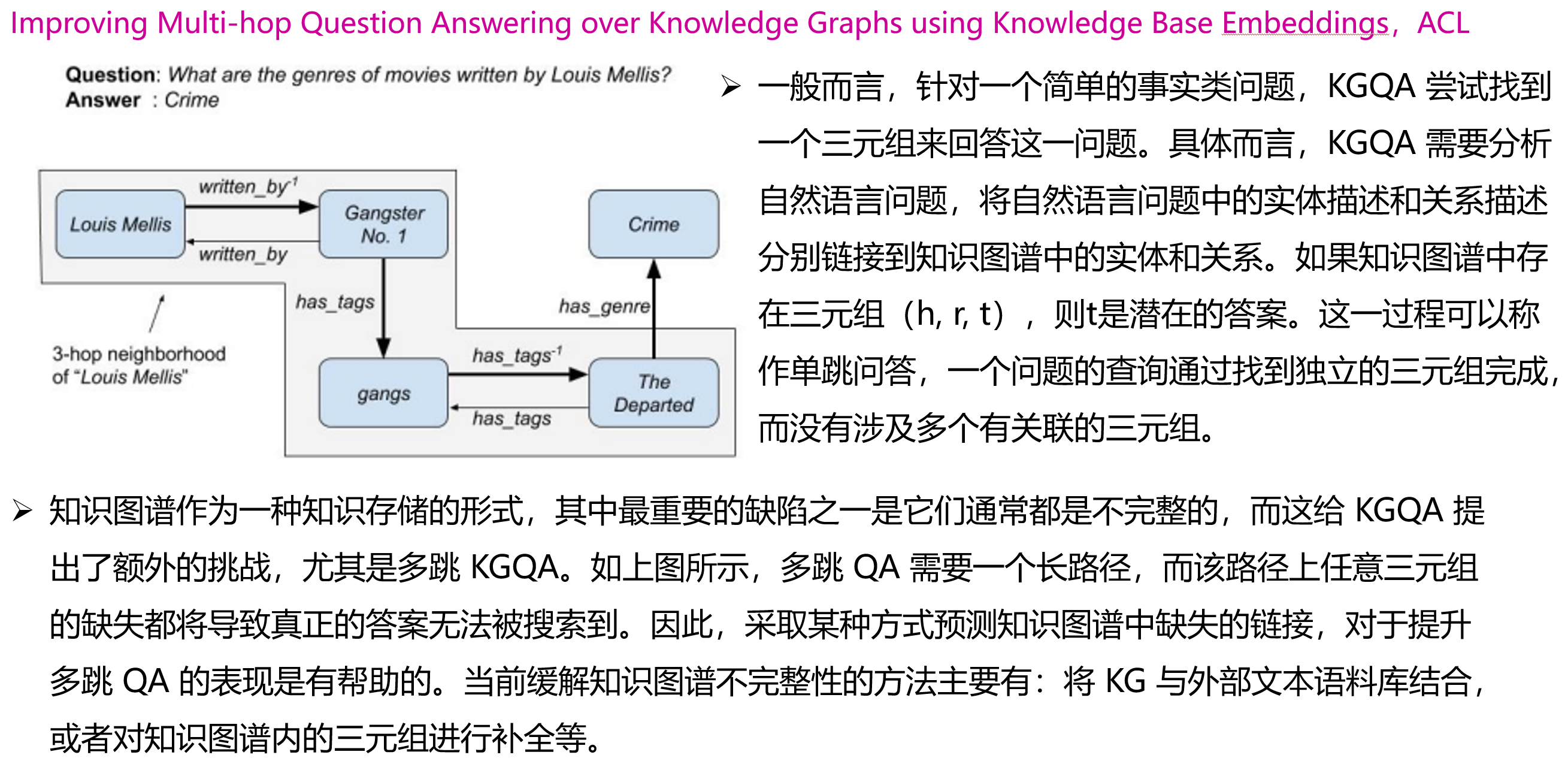
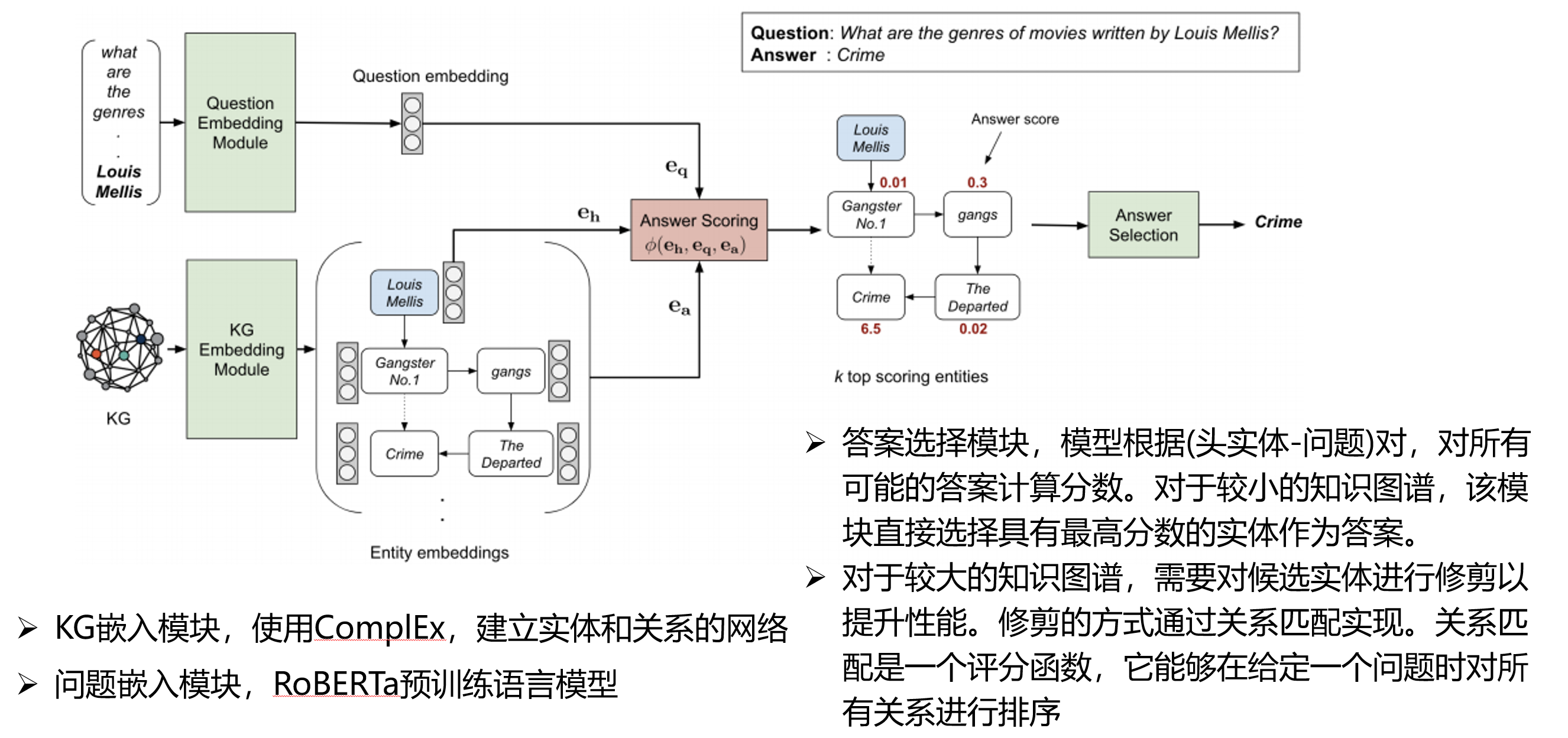
基于知识图谱的多跳问答:

















 2284
2284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









