






背景
目的:
- 鉴于多分支模型训练性能好,推理相对较慢,单分支扁平化模型训练性能差,推理性能好的情况,将二者综合,试图构建一种网络模型,在模型训练阶段使用多分支训练获得更好的训练性能,在模型推理阶段将训练好的多分支模型恒等转换为单分支的扁平化模型。这其中的核心问题就是如何把多分支的模型转换为一个单分支的模型?RepVGG论文中把这个过程叫做结构重参数化技术。 重参数其实就是在测试的时候对训练的网络结构进行压缩。比如三个并联的卷积(kernel size相同)结果的和,其实就等于用求和之后的卷积核进行一次卷积的结果。所以,在训练的时候可以用三个卷积来提高模型的学习能力,但是在测试部署的时候,可以无损压缩为一次卷积,从而减少参数量和计算量。
重参数技术的优势:
多分支的网络有利于网络的收敛和学习更多的信息;针对超分任务可以设计针对性的分支来学习纹理和边缘信息;推理时仅采用单分支推理,减少推理时显存占用和计算复杂度;
重参数技术的劣势:
由于是多分支训练,单分支推理,需要将多分支的模型的参数通过重参数合并原理,将多个分支的权重参数合并到一个卷积核上,这可能导致模型量化时,量化比较困难;
原理
卷积操作可以描述为:
o
u
t
f
m
a
p
=
I
n
p
u
t
∗
k
e
r
n
e
l
+
R
E
P
(
b
i
a
s
)
outfmap=Input*kernel+REP(bias)
outfmap=Input∗kernel+REP(bias)
其中,*为卷积操作,
I
n
p
u
t
∈
R
C
×
H
×
W
Input\in R^{C\times H\times W}
Input∈RC×H×W为输入特征,
k
e
r
n
e
l
∈
R
D
×
C
×
K
×
K
kernel\in R^{D\times C \times K \times K }
kernel∈RD×C×K×K为卷积核,
b
i
a
s
∈
R
D
为偏置项,
R
e
p
(
b
i
a
s
)
∈
R
D
×
H
×
W
表示广播后的偏置项
bias\in R^{D} 为偏置项,Rep(bias)\in R^{D\times H \times W}表示广播后的偏置项
bias∈RD为偏置项,Rep(bias)∈RD×H×W表示广播后的偏置项。
卷积具有如下两个性质:
- 可加性:
I
n
p
u
t
∗
k
e
r
n
e
l
1
+
I
n
p
u
t
∗
k
e
r
n
e
l
2
=
I
n
p
u
t
∗
(
k
e
r
n
e
l
1
+
k
e
r
n
e
l
2
)
Input*kernel_1+Input*kernel_2=Input*(kernel_1+kernel_2)
Input∗kernel1+Input∗kernel2=Input∗(kernel1+kernel2)
上述公式解释起来就是,针对输入都是同一个特征图,并行分支的两个卷积核,可以先将二者的卷积核相加,然后再进行一次卷积操作,从而减少计算量和和访存。
- 同质性:
I n p u t ∗ ( p × k e r n e l ) = p × ( I n p u t ∗ k e r n e l ) Input*(p\times kernel)=p\times(Input * kernel) Input∗(p×kernel)=p×(Input∗kernel)
网络结构重参数论文
RepVGG(RepVGG: Making VGG-style ConvNets Great Again)
论文作者知乎:RepVGG:极简架构,SOTA性能,让VGG式模型再次伟大(CVPR-2021) - 知乎
官方开源代码:https://github.com/DingXiaoH/RepVGG
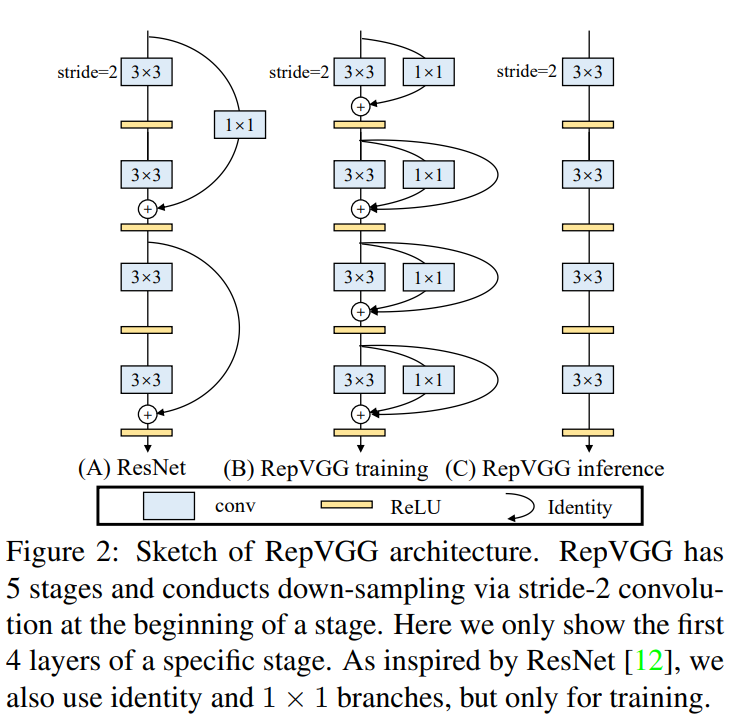
模型运行性能
在学术论文中通常采用模型的参数量和浮点运算量FLOPs来衡量模型的运行性能,但实际在工程落地时参数量和FLOPs并不能真正反映出部署在实际的设备上的运行速度。另外两个影响推理速度的因素有:模型内存访问次数和模型的并行化程度。
- 模型访问内存的次数Memory Access Cost(MAC),Multi-Branch模型每个分支都要访问内存,都要保存特征图,虽然有的分支参数量和计算量并不高(比如1x1卷积分支,Identity分支,分组卷积等),但是访问内存的次数以及占用的内存大小都增加了。
- 模型的并行化程度,Multi-Branch模型不同branch的速度不同,但是在某个算子节点处输入是所有分支的结果汇合在一起作为输入,需那么这时可能就需要等待其他分支,导致算力资源的浪费,并行度不高。
VGG类的单分支网络的优点:
1.没有任何分支,访问内存次数少,占用显存少;
2.直筒型网络,不需要等待其他分支的结果,并行度高;
多分支网络的优点:
- 不同的分支学习到了不同的特征,不同的分支的特征融合后,表征能力更强;
- 从特征和梯度复用的层面理解,比如ResNeXt和DenseNet,多个分支之间可以进行特征和梯度的复用;
- 从集成学习的角度出发,resnet中的每个short-cut连接,就给模型提供了另一种可能;这样模型从头到尾就一共有2的N次方的可能,就像是将2的N次方的结果进行综合集成;
重参数化原理
如何将训练时的多分支网络转换为单分支网络结构?
在RepVGG论文中,主要是将:并联的带BN的3x3卷积核,1x1卷积核和残差结构转换为一个3x3的卷积核,这也是该论文的核心点。下图就是介绍了如何进行转换的思想。
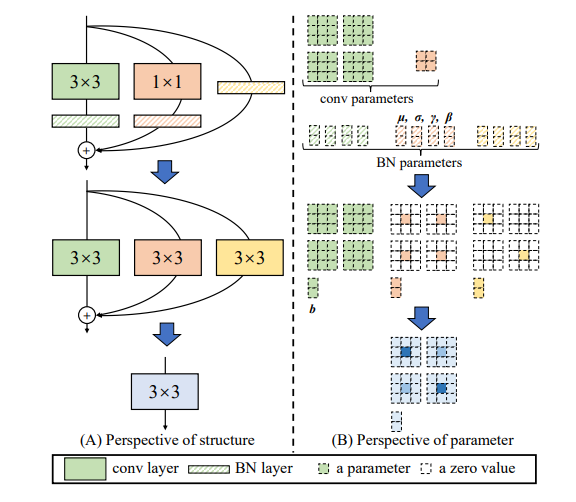
并行的3x3卷积和1x1的卷积如何转换为一个3x3卷积
情况一:
不考虑BN层的情况下:那么根据1.4节中卷积的可加性原理,虽然3x3和1x1的卷积核大小不一样,但是可以将1x1卷积用0 padding到3x3大小,然后就可以与另外一个分支的3x3卷积核进行相加了;
1.先将1x1的卷积核进行补0padding
2.并行的两个卷积核大小的卷积合并代码如下:
def transII_conv_branch(conv1, conv2):
weight=conv1.weight.data+conv2.weight.data
bias=conv1.bias.data+conv2.bias.data
return weight,bias
情况二:
如果卷积核后面都跟了BN层:1.首先将BN层融合到卷积层;2.然后在进行3x3卷积和1x1卷积的合并;
- 卷积层和BN层合并原理:
卷积操作:
o
u
t
f
m
a
p
=
I
n
p
u
t
∗
k
e
r
n
e
l
+
R
E
P
(
b
i
a
s
)
outfmap=Input*kernel+REP(bias)
outfmap=Input∗kernel+REP(bias)
BatchNorm操作:
B
N
(
x
)
=
γ
×
(
x
−
m
e
a
n
)
v
a
r
+
β
BN(x)=\gamma\times\frac{(x-mean)}{\sqrt{var}}+\beta
BN(x)=γ×var(x−mean)+β
将卷积代入BatchNorm:
B
N
(
C
o
n
v
(
x
))
=
γ
×
(
I
n
p
u
t
∗
k
e
r
n
e
l
+
R
E
P
(
b
i
a
s
)
−
m
e
a
n
)
v
a
r
+
β
=
I
n
p
u
t
∗
(
γ
∗
k
e
r
n
e
l
v
a
r
)
+
γ
v
a
r
×
(
R
E
P
(
b
i
a
s
)
−
m
e
a
n
)
+
β
BN(Conv(x))=\gamma \times \frac{(Input*kernel+REP(bias)-mean)}{\sqrt{var}}+\beta \\=Input*(\frac{\gamma * kernel}{\sqrt{var}})+\frac{\gamma}{\sqrt{var}}\times(REP(bias)-mean)+\beta
BN(Conv(x))=γ×var(Input∗kernel+REP(bias)−mean)+β=Input∗(varγ∗kernel)+varγ×(REP(bias)−mean)+β
即:
将BN融合到卷积层后,新的卷积核和偏置为:
k
e
r
n
e
l
n
e
w
=
γ
∗
k
e
r
n
e
l
v
a
r
;
b
i
a
s
n
e
w
=
γ
v
a
r
×
(
R
E
P
(
b
i
a
s
)
−
m
e
a
n
)
+
β
kernel_{new}=\frac{\gamma * kernel}{\sqrt{var}};\\ bias_{new}=\frac{\gamma}{\sqrt{var}}\times(REP(bias)-mean)+\beta
kernelnew=varγ∗kernel;biasnew=varγ×(REP(bias)−mean)+β
- 多分支合并:将BN层的参数融合到卷积核之后,原来带BN层的结构就变成了不带BN层的结构,我们将新卷积核相加之后,就得到了融合的卷积核。
Conv+bn->Conv代码实现:
def transI_conv_bn(conv, bn):
std = (bn.running_var + bn.eps).sqrt()
gamma=bn.weight
weight=conv.weight*((gamma/std).reshape(-1, 1, 1, 1))
if(conv.bias is not None):
bias=gamma/std*conv.bias-gamma/std*bn.running_mean+bn.bias
else:
bias=bn.bias-gamma/std*bn.running_mean
return weight,bias
代码测试:
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+bn
conv1=nn.Conv2d(64,64,3,padding=1)
bn1=nn.BatchNorm2d(64)
bn1.eval()
out1=bn1(conv1(input))
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transI_conv_bn(conv1,bn1)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
残差结构(恒等映射)如何转换为一个3x3卷积,进而和并行的3x3卷积、1x1卷积合并
残差的实际操作就是前面层的特征图与后层的特征图Elementwise相加,每个通道中每个元素对应相加。那么如何将identity分支用一个卷积层表示,这样才有可能融合。identity前后值不变,那么会想到是用权重等于1的卷积核,并分开通道进行卷积,即1x1的卷积核且权重固定为1的Depthwise卷积。这样相当于单独对每个通道的每个元素乘1,然后再输出来,这就是想要的identity操作!下面是一个示意图:
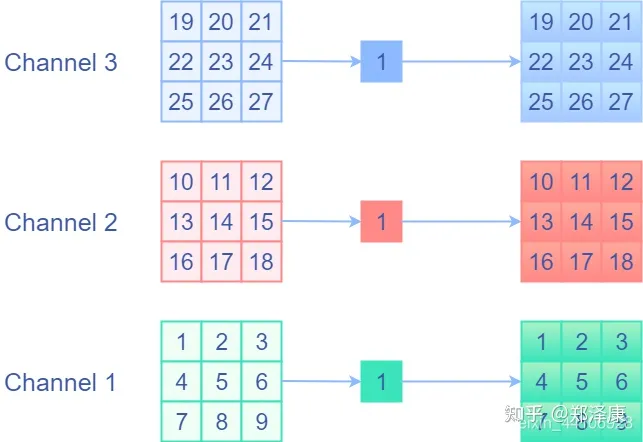
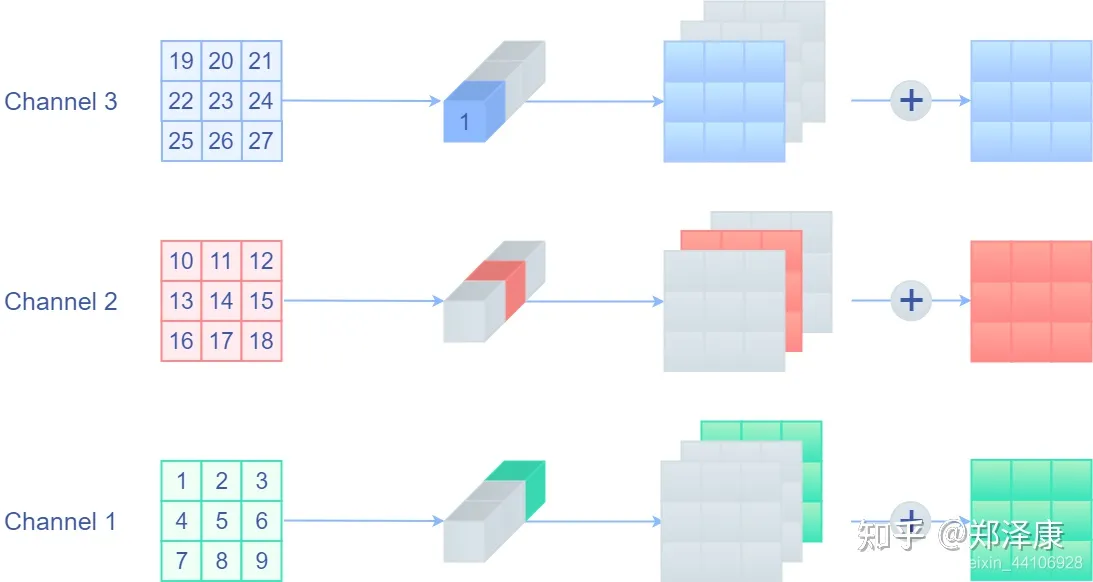
上图确实将残差连接用卷积来表达了:初步达到目的,但是新的问题产生了,之前的3x3和1x1分支都不是Depthwise卷积,是不能融合的,那如何要把Depthwise卷积以普通卷积的形式表达出来?
因为普通卷积输出是将各个通道结果相加,那么只要将当前通道对应的卷积权重设置为1,而其他通道权重设置为0,不就等价Depthwise卷积了! 下面是一个示意图:
CVPR2021-Diverse Branch Block
串联的1x1Conv+K x K Conv卷积->K x K Conv
串联的1x1的卷积和KxK卷积合并成单个K x K卷积,1x1的卷积核和kxk的卷积核分别为:
F
(
1
)
∈
R
D
×
C
×
1
×
1
,
b
(
1
)
∈
R
D
F
(
2
)
∈
R
E
×
D
×
K
×
K
,
b
(
2
)
∈
R
E
F^{(1)}\in R^{D\times C\times 1 \times\ 1},b^{(1)}\in R^{D}\\ F^{(2)}\in R^{E\times D\times K \times\ K},b^{(2)}\in R^{E}
F(1)∈RD×C×1× 1,b(1)∈RDF(2)∈RE×D×K× K,b(2)∈RE
则串联的两个卷积输出为:
O
′
=
(
I
∗
F
(
1
)
+
R
E
P
(
b
(
1
)
)
)
∗
F
(
2
)
+
R
E
P
(
b
(
2
)
)
O^{'}=(I*F^{(1)}+REP(b^{(1)}))*F^{(2)}+REP(b^{(2)})
O′=(I∗F(1)+REP(b(1)))∗F(2)+REP(b(2))
希望将两个卷积融合成一个卷积,即希望用单独的一个卷积核F’和偏置来表达输出O’:
O
′
=
I
∗
F
′
+
R
E
P
(
b
′
)
O'=I*F'+REP(b')
O′=I∗F′+REP(b′)
O
′
=
I
∗
F
(
1
)
∗
F
(
2
)
+
R
E
P
(
b
(
1
)
)
∗
F
(
2
)
+
R
E
P
(
b
(
2
)
)
O'=I*F^{(1)}*F^{(2)}+REP(b^{(1)})*F^{(2)}+REP(b^{(2)})
O′=I∗F(1)∗F(2)+REP(b(1))∗F(2)+REP(b(2))
因为
I
∗
F
(
1
)
I*F^{(1)}
I∗F(1)是1x1卷积只进行了通道间的线性组合,并不涉及空间位置上的卷积计算,可以线性重组3x3的卷积核参数来将1x1的卷积核融合到3x3卷积中:
F
′
=
F
(
2
)
∗
T
R
A
N
S
(
F
(
1
)
)
F'=F^{(2)}*TRANS(F^{(1)})
F′=F(2)∗TRANS(F(1))
实验验证如下:
卷积核参数融合代码:
def transIII_conv_sequential(conv1, conv2):
weight=F.conv2d(conv2.weight.data,conv1.weight.data.permute(1,0,2,3))
return weight
测试代码:
def conv1x1Conv3x3ToConv3x3(data):
# 1x1卷积
conv1 = nn.Conv2d(in_channels=1, out_channels=4, kernel_size=1, padding=0, bias=False, stride=1)
# 3x3卷积
conv2 = nn.Conv2d(in_channels=4, out_channels=4, kernel_size=3, padding=0, bias=False, stride=1)
# 先1x1,在3x3
model = nn.Sequential(
conv1,
conv2
)
#原始两层卷积结果
out1 = model(data)
print("两层卷积:",out1.view(1,-1)[:10])
#一层3x3卷积的结果
conv3x3 = nn.Conv2d(in_channels=1, out_channels=4, kernel_size=3, padding=0, bias=False, stride=1)
out2 = conv3x3(data)
print("一层3x3卷积:",out2.view(1,-1)[:10])
# 1x1卷积和3x3卷积核的参数进行融合
weights = F.conv2d(conv2.weight, conv1.weight.permute(1, 0, 2, 3))
conv3x3.weight.data = weights
#融合后一层3x3卷积结果
out3 = conv3x3(data)
print("重参数融合后一层3x3卷积:",out3.view(1,-1)[:10])
print("两层卷积和一层3x3卷积差异:",(out1 - out2).sum())
print("两层卷积和重参数后的一层3x3卷积差异:",(out1 - out3).sum())
if __name__ == '__main__':
input = torch.rand(1,1,256,256)
conv1x1Conv3x3ToConv3x3(input)















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









