







Preface阅读总结:
- 传统优化算法在一次运行中最多只能找到一个解,效率低不好;进化算法因为population-approach一次能找到好多解,很棒。
- MOEA分是否 保留精英或者emphasize currently elite. 第五章讲non-elitist,第六章讲elitist
- 第七章讲 有Constraint的优化问题(不是应该对取值点都有限制吗,是不是对目标函数多了限制,到第七章再看看)
- 第八章谈MOEA的问题,有很大的空间可以提升;第九章讲MOEA在现实生活中的应用。
- 感谢了好多人。
Prologue阅读总结:
1.单目标优化有基于梯度(梯度下降算法?)和基于启发式的(好像就是字面意思,从别的的东西得到启发,神经网络就是一种),用随机搜索更可靠(随机梯度下降算法吗?),还有模仿自然和物理的 进化算法(之前看论文好像看到就是一代一代的种群不断变强) 和 模拟退火(https://www.cnblogs.com/hdu-2010/p/4322841.html)
(感觉就有点像随机梯度下降算法,防止进入local minimum卡在那里不动,带有一定的随机性)
1.1大多研究都注重把多目标优化转化为单目标优化,比较谁的转换方式更好,但是这和我们一开始直观的感受,单目标优化是多目标优化的一个退化是相反的。多目标优化不是单目标优化的一个简单的扩展,有一个fundamental difference在二者之间。
1.1.1这个区别就是单目标优化的解一般是唯一的,而多目标优化有许多trade-off的解。
1.2在找出一堆多目标优化的 trade-off解后,利用higher-level information来选择一个我们喜欢的解,所以解决多目标优化问题的一种方法是,利用对一个特定问题相关偏好,给每个目标函数设定一个权重值,多目标优化就变成了单目标优化。但是第一这种偏好其实很主观的,而且如果你没有domain knowledge是很难得到一个reliable和accurate的vector;第二我们不一定每次都能得到hopefully的解
两种方法 1)preference-based approach得到一个解;2)从很多trade-off解中利用问题信息找出一个解
1.3大家以前都认为在一次模拟运行中只有一个解能被找到,所以理所当然的,把目光都放在了多目标——>单目标上。后来有人提出了这种进化算法,每次迭代处理很多个解,所以最后得到的解也是很多个(如果存在多个trade-off解)
1.4主要讲了MOEA的一个发展过程吧,第一个提出来的EA算法是VEGA,但是他有一个缺点在很多很多次迭代后,所有的解会汇聚到一个点。后来的NSGA NPGA等等。。
1.5 介绍全书的分布
3.25
2 Multi-Objective Optimization
Multi-modal optimization 是啥?(好像4.6节会讲)
In applied mathematics, multimodal optimization deals with optimization tasks that involve finding all or most of the multiple (at least locally optimal) solutions of a problem, as opposed to a single best solution. Evolutionary multimodal optimization is a branch of evolutionary computation, which is closely related to machine learning. Wong provides a short survey,[1] wherein the chapter of Shir[2] and the book of Preuss[3] cover the topic in more detail.
还是没太明白,就说了有多个解,具体是怎么样的问题呢
2.1 moop
variable bounds构成了决策空间,而variable bounds+constraints构成search space。因为有二元性,最大化乘个-1就变最小化
2.1.1 liner and nonlinear moop
如果目标函数和限制函数都是线性的,我们叫MOLP 即 linear moop,就像
Linear Programming一样

反之就是Nonlinear MOOP,现在还没有收敛性证明,不太好。
2.1.2 convex and nonconvex MOOP
凸函数
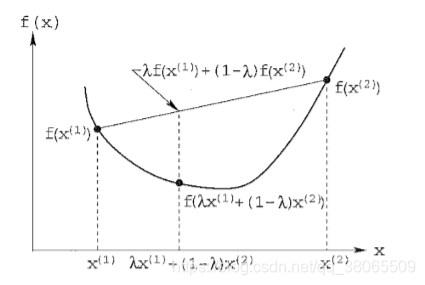
反过来就是非凸函数了
海森矩阵就是一堆二阶偏导,凸函数的hessian矩阵是正定的。

怎么理解二阶偏导与凸函数的Hessian矩阵是半正定的?
https://www.zhihu.com/question/40181086很好的证明,忘记了就再看看。
Convex MOOP的定义就是,所有目标函数是凸的,可行域也是凸的(所有不等式的限制是非凸函数,等式限制是线性的),因为所有非凸函数g(x)>=0的解集是凸集(?)
目标函数空间,决策空间,search space,要区分清楚。
2.2 principles of multi-objective optimization
举了一个flight的例子,cost和convenience的权衡。
2.2.1 Illustrating Pareto-Optimal Solutions
用了一个小例子说明Pareto解和Pareto前沿,如果所有的目标函数都是最小化的话,前沿会在左下角。
2.2.2 objectives in moo
1)找尽可能接近Pareto前沿的解
2)解的分散要尽量diverse(才能更好的表现出Pareto前沿),保证欧式距离尽可能大,一般来说在决策空间保证diverse,目标空间也会diverse,但有些特殊情况可不一定。
3.26
2.2.3 Non-Conflicting Objectives
如果目标函数之前不存在冲突的话,就是不用损人才能利己,那我们的解只有一个,但是一般情况下不是很好判断目标函数是否冲突。
2.3 Difference with Single-Objective Optimization

2.3.1 Two Goals Instead of One
就是1)找尽可能接近Pareto前沿的解
2)解的分散要尽量diverse
因为这两个目标不相关,所以要在一个算法中达到这两个目标比单目标优化难的多。
2.3.2 Dealing with Two Search Spaces
因为有第二个Goal的存在,所以我们在一个空间保持diverse并不意味着一定在另外一个空间也有diverse,这就很困难了,怎么才能保持diverse呢,他的难度一般取决于两个空间之间的mapping。
2.3.3 No Artificial Fix-Ups
以前的方法 weight sum 和ε-constraint都是相当于把多目标转化为单目标,每次都是只得到一个解,效率低,后来population-based的方法,好!
2.4 Dominance and Pareto-Optimality
2.4.1 Special Solutions
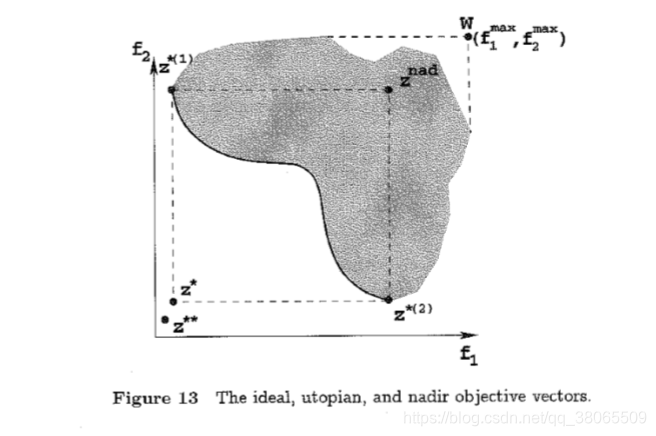
Ideal Objective Vector 就是把每个目标函数都单独去最小化得到的一个向量

它是一个lower bound of all objective functions。
我们还定义了一个Utopian向量,他比ideal vector 还要小,严格小一个ε。
还有一个nadir vector 他是upper bound of the entire pareto-optimal set,注意和那种严格的上界是不一样的,不能混淆
几个点如图所示
我们还定义了一种标准化的方法
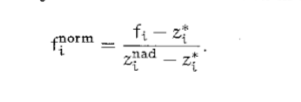
最后会把目标函数的值定在0,1之间
2.4.2 Concept of Domination
直观的来讲支配就是,我所有的都不比你差,而且我还有至少一个肯定比你好。
2.4.3 Properties of Dominance Relation
1)自己不能支配自己 reflexive
2)q支配p推不出p支配q symmetric
3) 反对称性?
4)有传递性,p支配q,q支配r,则p支配r
有序,部分有序,好像是离散数学的内容,不大清楚,有空再好好了解一下。
2.4.4 Pareto-Optimality
不被其他任何解支配的解叫 Non-dominated set
书上配的这个图感觉非常好,复制过来
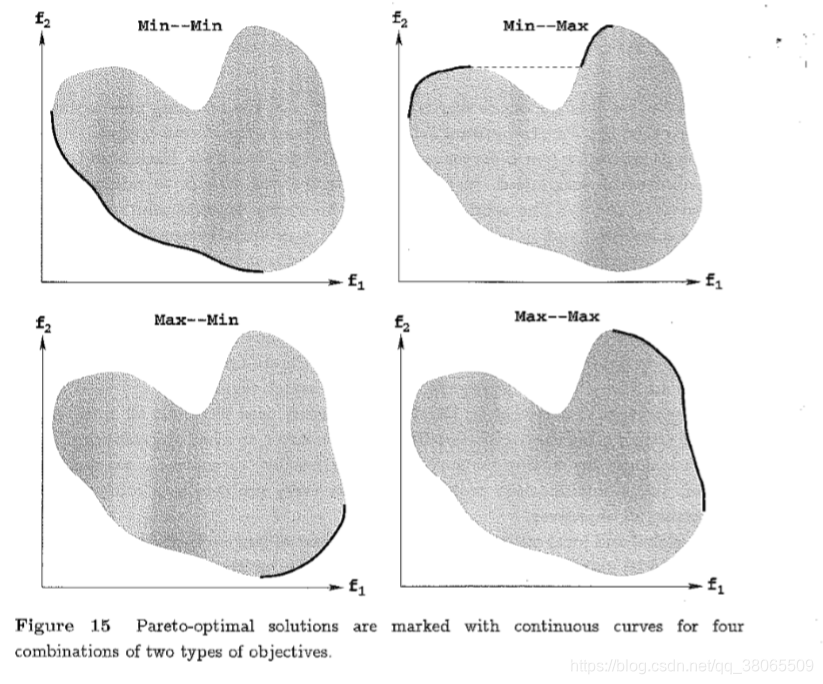
只是我们一般把最大化都搞成最小化,方便统一。
定义了全局Pareto最优解,好像就是Pareto最优解,没啥区别
还有局部Pareto最优解,直接看英文解释,很直接。
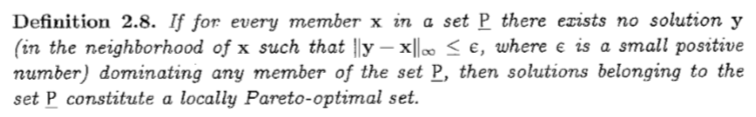
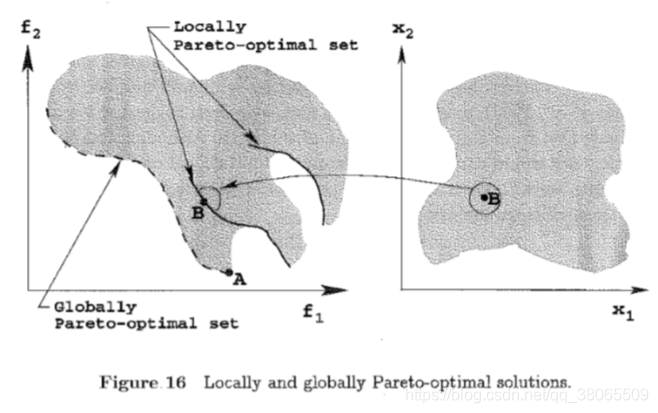
这个图也很好,我们可以看到从决策空间到目标空间的映射是非线性的。
至于在目标空间连续,在决策空间不需要连续的问题,没有具体例子,不是特别明白,8.3章好像会有实例
2.4.5 Strong Dominance and Weak Pareto-Optimality
强支配就是我所有的都比你好,我就强支配你
弱不被支配的集

因为要让这个解集的个数减少的要求更严格(要强支配),所以它的个数大于或等于之前那个Non-dominated set;
Pareto最优解一定是Non-dominated set,但是Non-dominated set可能包含Pareto和非Pareto(因为我们给的population不太好?),首先解决如何找Non-dominated set.
2.4.6 Procedures for Finding a Non-Dominated Set
Approach 1:Naïve and Slow
每次将一个解与集合P里面的所有其它解做比较,如果没有被支配,就把它丢入Non-dominated set里面,反之就看下一个解,直到所有解都看过了。
这种算法的复杂度较高,最差的话是O(MN²),M是目标函数的个数,N是种群个数。
经过实验发现,平均的复杂度大概在O(N²)。
我们并不关心复杂度关于M怎么变化,我们更多的关心关于N怎么变化,因为对于一个给定的问题,变的是N,不变的是M
3.29
Approach 2:Continuously Updated
大致思路就是,设置一个集合P’,初始化的时候将solution1丢进去,然后从solution2开始,与P’里面的比较,如果2决定1就删除1,如果1决定2,2就舍去,看solution3,记得要与P’的每一个solution都要比较,如果他们当前解不被P’里的支配,就把它并进去。(直接讲不是很好说,可以看英文步骤说明)

这种方法最多![]() *M次比较,比前面一次少很多,可以从Figure17上看出来,尽管他们的斜率是一样的,但是仍然可以看到非常不一样的地方。
*M次比较,比前面一次少很多,可以从Figure17上看出来,尽管他们的斜率是一样的,但是仍然可以看到非常不一样的地方。
Approach 3:Kung et al.‘s Efficient Method
核心思想是利用了递归,一层一层的返回再比较,返回再比较,最后得出Non-dominated set,如果由具体代码应该能更清楚,不过文中举了一个例子已经非常具体了。
显而易见的,我们从实验得出,这种方法效率最高。
2.4.7 Non-Donimated Sorting of a Population
我记得NSGA那个算法好像就是基于非支配排序的,记不清了
就是先从P种找最厉害的Non-dominated set,从P种剔除这些,再找第二厉害的Non-dominated set,依次进行下去。
讲道理这个做法的计算复杂度应该是每次 找支配解的计算复杂度之和,但是每一次计算之后他的复杂度会飞速下降,所以往往只用第一次的计算复杂度来代表它的整体复杂度,我们会在8.8章证明它。
还有一种很棒的方法,定义了ni:支配i的解的个数,Si:i支配解的集合,最多只有O(MN²),具体看步骤P43.
2.5 Optimality Conditions
给了一些 Pareto最优解的必要条件,和特殊要求下的充分条件,但是并没有给证明
大概是这么个意思?没有找到很好的解释,好像在凸优化那本书里面有详细讲
2.5 Summary
大体总结了一下本章,多目标优化的困难啊,没有合适的方法啊,以前只是转成单目标啊,很受制于主观因素,更多的由于目标之间的冲突,所以我们有一组最优解啊,然后介绍了一些支配,non-dominated set,Pareto解啦等等概念,教了3种找Non-dominated的方法啦,等等,还介绍了找分等级的Non-dominated 的方法,最后给了一些最优化的条件,具体证明要在别的论文里面看好像。

















 1733
1733

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









