







人脸检测算法
https://www.cnblogs.com/JYLJX666/p/10613441.html
传统方法:
adaboost
adaboost+Haar-like
ACF
DMP
MTCNN:
http://www.sfinst.com/?p=1683
https://www.jianshu.com/p/2f749b07e09f
https://zhuanlan.zhihu.com/p/63948672
算法整体思路:

stage1:基于图像金字塔的思想,原图经过resize成多个图像后输入P-Net中,由于该网络是全卷积,所以可以适应任何图像大小。经过三层卷积后的特征图输出是脸和背景分类概率,候选框的x,y坐标偏置(我看的版本里面没有面部关键点,不过原理差不多),最后特征图的感受野为12×12,即特征图1个像素代表原图的12个像素,得到的特征图按照这种规律映射到原图生成候选框,经过NMS过滤候选框。

stage2:根据可能的候选框切割图像分别输入R-Net,输出和stage1相同。

stage3:基本原理同stage2,输出多了5个脸部关键点,包含三部分:a.是否人脸的概率的1×1×2向量;b.人脸检测框坐标(左上点和右下点)1×1×4向量;c.人脸关键点坐标1×1×10向量。

损失函数:
1)对于输出a:是否人脸分类,由于是分类问题,其loss 函数使用常见的交叉熵损失:

2)对于输出b:人脸检测框定位,由于是回归问题,所以使用L2 损失函数:

3)对于输出c:人脸关键点定位,由于也是回归问题,所以也使用L2 损失函数:
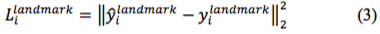
最终将三个损失函数进行加权累加,便得到总损失函数。由上述样本选择可知,当负样本和正样本训练时,由于仅用于分类,所以其仅有分类损失,而不存在人脸检测框和人脸关键点定位损失。即并不是所有的样本都同时存在上述三种损失。通过控制不同权重,使得三个网络的关注点不一样:


难样本挖掘:
不同于传统的难样本挖掘算法,论文中提出使用在线难样本挖掘。首先将前向传递得到的loss值降序排序,然后选择前70%大的样本作为难样本,并在反向传播的过程中只计算难样本的梯度,即将对于训练网络没有增强作用的简单样本忽略不计。
SSH
https://blog.csdn.net/weixin_40671425/article/details/90406061
算法整体思想:全卷积网络,通过在特征图上添加检测模块,对人脸进行早期定位和分类,步长分别为8、16、32,分别表示为M1、M2、M3。检测模块由卷积二分类器和回归器组成,分别对人脸进行检测和定位。采用与RPN类似的策略来形成anchors集合,以密集的重叠滑动窗口方式定义anchors。 在每个滑动窗口位置处,定义K个anchors,其具有与该窗口相同的中心和不同的比例。 但是,与RPN不同,我们只考虑纵横比为 1 的anchor s来减少anchor boxes的数量

SSH检测模块:包括一个简单的上下文模块来增加有效的感受野,上下文模块的输出通道数(即图3和图4中的“X”)设置为128作为检测模块M1,检测模块模块M2和M3的通道数设置为256。最后,两个卷积层进行边界盒回归和分类。在每个卷积位置Mi中,分类器决定过滤器中心对应的每个尺度为的窗口是否包含一个人脸。分类器采用2K个11的卷积层作为分类器。对于回归器分支,还部署了4K个1*1的通道进行回归预测。在卷积过程中的每个位置,回归器预测所需的尺度变化和平移量,以便将每个正anchors与人脸匹配。

**上下文模块:**在两阶段检测器中,通常通过扩大候选proposals周围的窗口来整合上下文。SSH通过简单的卷积层模仿这种策略。由于anchors是以卷积的方式分类和回归的,所以采用更大的过滤器(更大的卷积核尺寸),这类似于在两阶段检测器中增加proposals周围的窗口大小。为此,我们在上下文模块中使用5×5和7×7的过滤器(卷积核)。以这种方式对上下文建模增加了与相应层的步长成比例的感受野,并且因此增加了每个检测模块的目标尺度。为了减少参数的数量,采用一些串联的3×3的卷积核来代替较大的卷积核(注:尽管大卷积核可以获得更大的感受野,但是参数数量更大,而采用一些较小的卷积核层堆叠起来可以达到与大感受野同样的效果,同时减少了参数数量)。对于模块M2和M3,检测模块的输出通道数(即图4中的“X”)分别设置为:M1通道数为128,M2和M3的通道数为256。应该注意的是,与部署在[24]中用于生成提案的模块相比,我们的检测模块及其上下文过滤器使用的参数更少。尽管更有效,但我们通过经验发现上下文模块将WIDER FACE的验证集的平均精度提高了0.5%以上。

损失函数:人脸分类,边框回归

S3FD
https://zhuanlan.zhihu.com/p/44504595
算法整体思想:主要解决人脸检测中检测小脸难的问题

SSD
https://blog.csdn.net/u010712012/article/details/86555814
PyramidBox
介绍:https://baijiahao.baidu.com/s?id=1596461980141300726&wfr=spider&for=pc
详解:https://blog.csdn.net/Doheo/article/details/83933197?utm_source=distribute.pc_relevant.none-task
算法整体思想:

③LFPN:借鉴FPN设计

FPN结构:


④CPM:借鉴inception和renet思想设计网络,并借鉴SSH的思想分为脸,头,身体三个部分
每个部分结构如下:


⑤PL:分为脸,头,身体三个部分:个人理解face、head和body结果均经过一层一层卷积最终分支所来,而一般head和body包含face,这样相当于起到限制的作用,有利于低分辨率、模糊和较多遮挡的人脸的预测。

借https://blog.csdn.net/Doheo/article/details/83933197?utm_source=distribute.pc_relevant.none-task图一用,侵删

DSFD
https://blog.csdn.net/wwwhp/article/details/83757286
**算法整体思想:**DSFD使用拓展的VGG16或Resnet作为backbone,在分类层之前添加辅助结构;使用conv3_3、conv4_3、conv5_3、conv_fc7、conv6_2、conv7_2作为第一个镜头的检测层,生成作为原始特征图的of1,of2,of3,of4,of5,of6,使用FEM将原始特征图转换为六个增强的特征图:ef1,ef2,ef3,ef4,ef5,ef6,以此构建成第二个镜头的检测层;设计上和S3FD以及PyramidBox不同,在FEM中利用了感受野增广以及新的anchor设计策略后,没有必要设计三种尺度的stride、anchor和receptive field去满足等比例间隔原则;原始镜头和增强镜头使用的loss function不同,分别为FSL、SSL

FEM:Feature Enhance Module:FEM中先使用1×1卷积归一化输入的特征图,然后对up layer的输入进行上采样和当前layer输入执行元素乘积,最后将N个FM分成三份分别作为包含不同扩张卷积层数的子网络中,最后concat操作合并子网结果,得到增强特征图。

PAL:Progressive Anchor Loss:训练过程使用FSL和SSL,FSL用于收敛调整网络,测试时只有Second shot输出。

网络的各种参数:原始输入为640×640

SRN
https://zhuanlan.zhihu.com/p/57909644
算法整体思路:
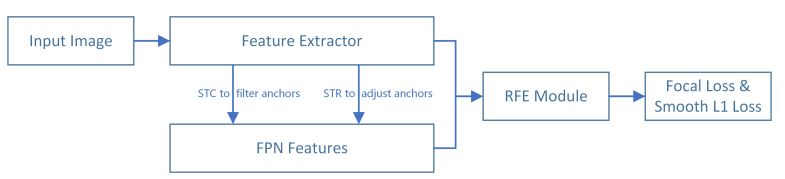
SRN使用ResNet-50做主干网,包含6层特征金字塔结构,其中4个residual block上的feature map表示为:C2、C3、C4、C5,在C5上通过conv 3 x 3、stride = 2,再做两次下采样,生成C6、C7;bottom-up、top-down、lateral connect的特征金字塔生成方式与FPN保持一致;
从网络结构可以发现,P2、P3、P4、P5与C2、C3、C4、C5尺度相同,生成的方式与FPN操作一致,但P6、P7是直接靠conv 3 x 3、stride = 2的下采样操作生成的;STC模块通过C2、C3、C4(1st-step) / P2、P3、P4(2nd-step)完成2-stage的分类;STR模块通过C5、C6、C7(1st-step) / P5、P6、P7(2nd-step)完成2-stage的回归;STC、STR二者融合,就构成了2-stage的分类 + 回归,只不过二者作用于不同的feature map层上;

STC:Selective Two-step Classification
1st-step通过预定义的objectness阈值过滤大部分易分负样本,减少2nd-step分类器所需处理的样本量; 使用这个操作的出发点为:anchor-based检测器为检出小尺度人脸,都会在特征金字塔的浅层feature map上做anchor的密集采样,小尺度人脸是保持高召回率了,却带来了海量false positives,进一步导致了正负样本数量不均衡;从这点上看,STC就是作用于浅层feature map上;
但作者也提到,没必要在所有检测分支上都使用2-step分类操作,因为P5、P6、P7等高层feature map上anchor的占比比较小(占总anchor数量的11.1%),正负样本数量不均衡的问题会比较轻,且这些层上的特征更利于检测大尺度人脸;但P2、P3、P4等浅层feature map不同,anchor数量特别多(占总anchor数量的88.9%),且特征的表达能力本身又比较弱,context信息也不够,语义信息又缺乏,因此在这些浅层feature map上使用2-step的分类操作,就会有很好的效果。
此外,SRN在两阶段中都引入了focal loss操作,可以更全面地利用所有样本,且STC中,两阶段的分类器共享了大部分参数(仅预测的分类分支参数不一样),因为二者任务相同:都是从 bg 中判别出前景的人脸区域;最终实验结果如SRN论文中的table 2,可知STC应用于浅层feature map上的性能优于应用于高层feature map上;
STP: Selective Two-step Regression
1-stage的目标检测算法一般仅对bbox做一次边框调整,作者认为不够,但cascade rcnn里又说了,盲目地迭代做multi-step的bbox reg,并不能进一步提升bbox的定位精准度,SRN论文中的table 4中证实了,在浅层feature map上操作两次bbox reg,精度竟然还下降了,作者认为原因有二:
1 三个浅层featue map本职工作是通过密集采样的anchor检测小尺度人脸,这些feature map上特征本身的表达能力也不够,因此要其进一步完成bbox回归,精准度就显得不够了;
2 训练阶段,若让浅层feature map也参与其不擅长的bbox回归任务中,有点没发挥其特长,导致模型过于关注其产生的reg loss,忽略了其本职工作的cls loss;
基于以上分析,SRN选择仅在高层P5、P6、P7上使用STR操作,出发点很简单:低层feature map专注于分类任务,高层feature map充分利用大尺度人脸的高语义信息,训练出更适于bbox精准定位的分支;这种divide-and-conquer策略让整个模型的效率非常之高;---- 那么整体上,STC、STR就是RefineDet中ARM、ODM的进一步深入探索,非常有利于小尺度人脸的检测,并过滤海量负样本anchors。
RFE:Receptive Field Enhancement
现有人脸检测算法都使用正方形的卷积核尺度,如conv 3 x 3、1 x 1等,因而也会生成正方形的感受野区域,如果目标尺度长宽比并不是接近1:1,那么此类正方形感受野可能并不会带来最佳检测性能;
SRN中提出了RFE,为模型引入多样化的感受野信息,有助于SRN检出极端尺度、姿态下的人脸,RFE结构如图2,包含了Inception、ResNet思路,共4个分支 + 1个shotcut。

Improved SRN
https://zhuanlan.zhihu.com/p/56700948
数据增强:
使用SRN的原始数据增强策略,包括光照扭曲、通过零填充操作进行随机扩展、从图像中随机裁剪块,并调整块的大小到1024×1024。另外,在概率为0.5的情况下,利用PyramidBox中的data-anchor-sampling,随机选择图像中的一个人脸,并基于子图像进行定位。这些数据增强方法对于防止过度拟合和构造鲁棒模型至关重要。
特征提取:

训练策略:
由于RESNET-50-FPN主干网已经被修改,所以不能使用ImageNet预训练模型。一种解决方案是DRN,它在ImageNet数据集上训练修改后的主干,然后在更宽的面上进行细化。
然而,有人证明了ImageNet的预训练是不必要的。因此,将训练epoch翻了一番,达到260次,并从零开始用改进的骨干网络训练模型。从零开始训练的关键因素之一是标准化,由于输入量大(1024×1024),一个24G GPU只能输入5幅图像,导致批量归一化从零开始训练时效果不佳。为此,利用group=16的组规范化(Group Normalization )从零开始训练这个改进的ResNet-50骨干网。
此外,最近的FA-RPN证明,人脸检测模型若先在MS COCO上训练一波,再在Wider Face上进一步训练,性能会更好,Improved SRN也使用了该方案
Retinaface
https://blog.csdn.net/warrentdrew/article/details/98742948
算法整体思路:
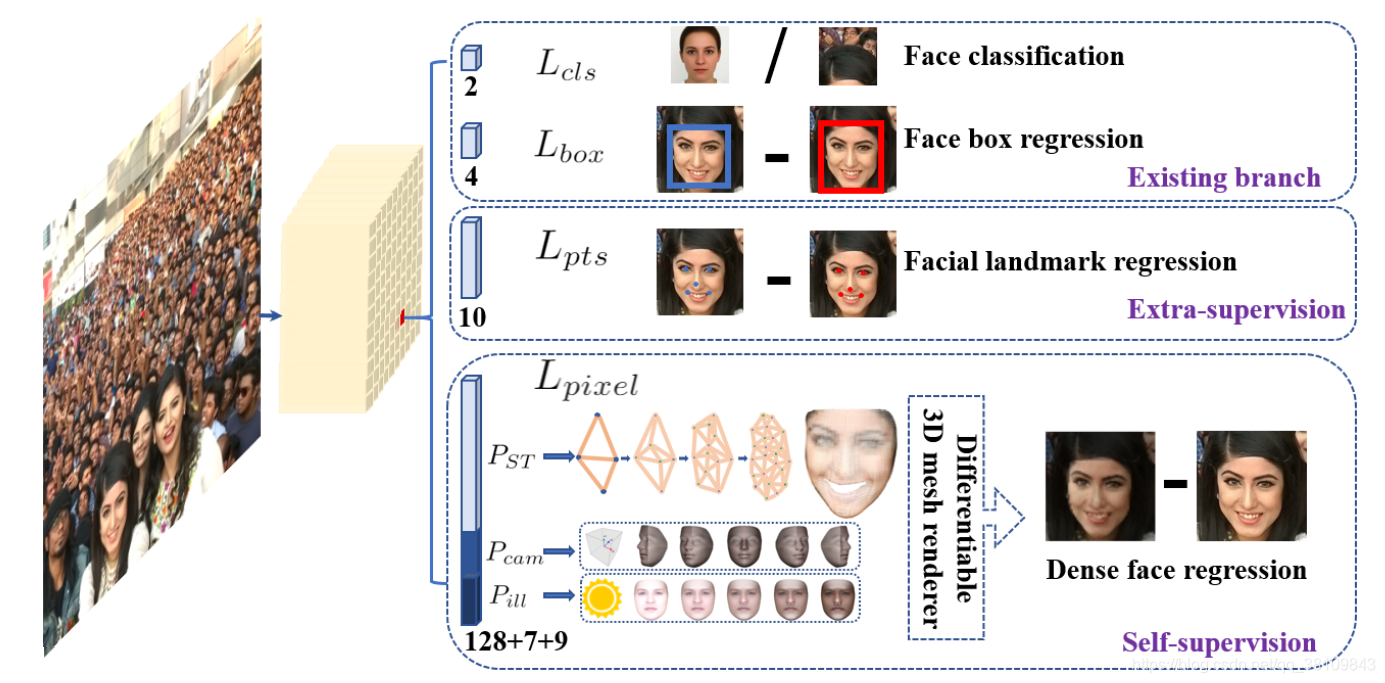


人脸识别算法
facenet:
https://blog.csdn.net/chenriwei2/article/details/45031677
https://blog.csdn.net/gubenpeiyuan/article/details/80470811

图中的数字表示这图像特征之间的欧式距离,可以看到,图像的类内距离明显的小于类间距离,阈值大约为1.1左右。
Triplet Loss:

有三张图片输入的Loss(之前的都是Double Loss或者 是 SingleLoss),文章这里,直接学习特征间的可分性:相同身份之间的特征距离要尽可能的小,而不同身份之间的特征距离要尽可能的大。

如何选择训练数据:
举个例子:在一个1000个人,每人有20张图片的情况下,其T=10002020*999
也就是O(T)=N2 ,所以,穷举是不大现实的。那么,我们只能从这所有的N2个中选择部分来进行训练。答案是选择最难区分的图像对。
给定一张人脸图片,我们要挑选其中的一张hard positive:即另外19张图像中,跟它最不相似的图片。同时选择一张hard negative:即在20*999图像中,跟它最为相似的图片。挑选hard positive 和hard negative有两种方法,offline和online方法,具体的差别只是在训练上。
实际采用:采用在线的方式,在mini-batch中挑选所有的anchor positive 图像对,同时,依然选择最为困难的anchor negative图像对。
新的问题:选择最为困难的负样本,在实际当中,容易导致在训练中很快地陷入局部最优。为了避免这个问题,在选择negative的时候,使其满足上式(3):左边:Positive pair的欧式距离右边:negative pair的欧式距离。
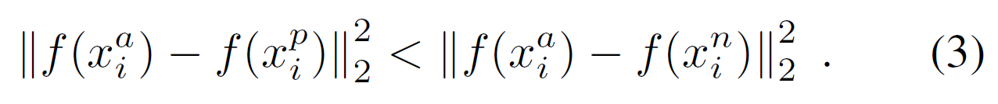
insightface/arcface:
https://blog.csdn.net/Wuzebiao2016/article/details/81839452
损失函数:https://www.cnblogs.com/k7k8k91/p/9777148.html
https://blog.csdn.net/u014380165/article/details/80645489
https://blog.csdn.net/qq_34914551/article/details/86515184
人脸识别分为四个过程:人脸检测、人脸对齐、特征提取、特征匹配。其中,特征提取作为人脸识别最关键的步骤,提取到的特征更偏向于该人脸“独有”的特征,对于特征匹配起到举足轻重的作用。但在Resnet网络表现力十分优秀的情况下,要提高人脸识别模型的性能,除了优化网络结构,修改损失函数是另一种选择,优化损失函数可以使模型从现有数据中学习到更多有价值的信息。
而在我们以往接触的分类问题有很大一部分使用了Softmax loss来作为网络的损失层,实验表明Softmax loss考虑到样本是否能正确分类,而在扩大异类样本间的类间距离和缩小同类样本间的类内距离的问题上有很大的优化空间,因而作者在Arcface文章中讨论了Softmax到Arcface的变化过程,同时作者还指出了数据清洗的重要性,改善了Resnet网络结构使其“更适合”学习人脸的特征。
Softmax Loss


Center Loss:Center Loss的整体思想是希望一个batch中的每个样本的feature离feature 的中心的距离的平方和要越小越好,也就是类内距离要越小越好。



A-Softmax Loss(SphereFace)
在Softmax Loss中,

特征向量相乘包含由角度信息,即Softmax使得学习到的特征具有角度上的分布特性,为了让特征学习到更可分的角度特性,作者对Softmax Loss进行了一些改进。




Cosine Margin Loss

Angular Margin Loss

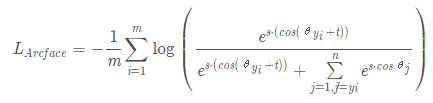
网络结构
大多数的卷积神经网络为完成Image-Net的分类任务而设计的,所以网络会采用224x224的输入,然而作者所用的人脸大小为112x112,如果直接将112x112的数据作为预训练模型的输入会使得原本最后提取到的特征维度是7x7变成3x3,因此作者将预训练模型的第一个7x7的卷积层(stride=2)替换成3x3的卷积层(stride=1),这样第一个卷积层就不会将输入的维度缩减,因此最后还是能得到7x7的输入,如下图所示,实验中将修改后的网络在命名上加了字母“L”,比如SE-LResNet50D


作者改善了Resnet网络的残差块使其更适合人脸识别模型的训练,采用 BN-Conv-BN-PReLu-Conv-BN 结构作为残差块,并在残差块中将第一个卷积层的步长从2调整到1,激活函数采用PReLu替代了原来的ReLu。采用修改过的残差块的模型作者在后面添加了“IR”以作为标识。


综上所述,最终在Resnet网络上做出了3项改进,第一是将第一个7x7的卷积层(stride=2)替换成3x3的卷积层(stride=1),第二是采用了Option-E输出,第三是使用了改善后的残差块。
人脸识别中的活体检测
https://zhuanlan.zhihu.com/p/25401788















 100
100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









