






摘要:
参考该博主文章转化BIO命名实体识别(NER)数据格式,增加了实体类型统计的功能,在MSRA数据集上测试,与数据集描述中的各实体类型数量匹配。
功能:
将BIO格式的NER数据集保存为json文件,并输出各类型实体的数量。
BIO格式数据如图:

转换之后的json如图:
![]()
MSRA数据集描述:

实体数量统计:
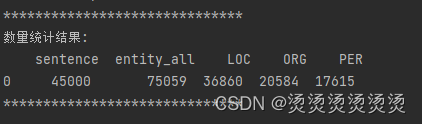
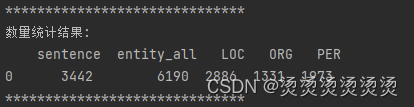
代码:
import json
import pandas as pd
def get_data(input_file):
"""
将BIO格式数据转换为json格式
Args:
input_file: BIO格式数据存储位置
Returns:result,字典列表形式的BIO数据
"""
result = []
with open(input_file, 'r', encoding='utf-8') as f:
texts = f.read().rstrip()
data = texts.split('\n\n')
for i in range(len(data)):
line = data[i].split('\n')
start, end = -1, 0
offsets = [] # 存储每个实体的起始下标位置和结束下标位置
texts = []
labels = []
for idx, item in enumerate(line):
item_split = item.split('\t') # 实体和标签之间的分隔符
if len(item_split) == 2:
word, label = item_split
else:
print(item_split)
texts.append(word)
labels.append(label)
# 处理空标签情况,当作O标签处理
if not len(label) or label.isspace():
print("空标签:", item_split)
label = 'O'
# 处理B标签
if label[0] == 'B':
# 处理“BIIBI”,“BBI”类型
if len(labels) >= 2:
if labels[-2][0] == "I" or labels[-2][0] == "B":
end = idx
offsets.append((start, end))
start, end = idx, 0
continue
# 处理I标签
if label[0] == 'I':
# 一定得是B在I前面,否则数据错误
if start >= 0:
end = idx
else:
print("错误:I在B前:", labels, label)
continue
# 处理O标签
if label == 'O':
if start >= 0:
end = idx
offsets.append((start, end))
# 找到就恢复初始值,寻找下一个B标签
start, end = -1, 0
continue
texts = ''.join(texts)
ents = [
(texts[start:end], labels[start][2:])
for start, end in offsets
]
# 处理以“BI"结尾的情况,前面用texts[start:end]取不到最后一个字符,因为是前闭后开区间
if start >= 0 and end:
# offsets.append((start, end))
ents.append((texts[start:], labels[start][2:]))
line_dict = {
"text": texts,
"entity": [
{'entity': entity, 'entity_type': entity_type}
for entity, entity_type in ents
]
}
result.append(line_dict)
return result
def check_data(data):
"""
获取句子数,实体总数目,各实体类型数量
Args:
data: 字典列表格式标注数据
Returns:nums_dict,一个存储句子数,实体总数目,各实体类型数量的dict
"""
nums_dict = {"sentence": len(data), "entity_all": 0, "LOC": 0, "ORG": 0, "PER": 0}
for each_dict in data:
if len(each_dict["entity"]):
nums_dict["entity_all"] += len(each_dict["entity"])
for each in each_dict["entity"]:
if each["entity_type"] == "LOC":
nums_dict["LOC"] += 1
if each["entity_type"] == "ORG":
nums_dict["ORG"] += 1
if each["entity_type"] == "PER":
nums_dict["PER"] += 1
return nums_dict
if __name__ == "__main__":
# input_file = "data/Sighan2006NER/test.txt"
# output_file = "data/Sighan2006NER/test.json"
# input_file = "data/CLUE Fine-Grain NER/train.json"
# output_file = "data/CLUE Fine-Grain NER/train.json"
# input_file = "data/MSRA/msra_test_bio.txt"
# output_file = "data/MSRA/msra_test_bio.json"
input_file = "data/MSRA/msra_train_bio.txt"
output_file = "data/MSRA/msra_train_bio.json"
# 将BIO格式数据转换为json格式
result = get_data(input_file)
# 检查数据
nums_dict = check_data(result)
nums_df = pd.DataFrame(nums_dict, index=[0])
print("*" * 30)
print("数量统计结果:\n", nums_df)
print("*" * 30)
# 存储数据
with open(output_file, 'w', encoding='utf-8') as f:
for item in result:
f.write(json.dumps(item, ensure_ascii=False) + '\n')















 1554
1554











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









