







 介绍一种基于STN的空间变换网络与编码器结构相结合的端到端可微网络,用于学习图像的一般转换分布,以进行数据增强。此方法在图像分类任务中,通过对抗性方式训练,能生成更复杂且对分类器有益的样本,实验显示其在多个数据集上的性能超越传统数据增强方法。
介绍一种基于STN的空间变换网络与编码器结构相结合的端到端可微网络,用于学习图像的一般转换分布,以进行数据增强。此方法在图像分类任务中,通过对抗性方式训练,能生成更复杂且对分类器有益的样本,实验显示其在多个数据集上的性能超越传统数据增强方法。
引言
我们知道STN(Spatial Trandfoemer Networks),它最初的目的是来对图像或者特征进行各种空间变形,从而可以实现矫正图像字符或者文本的作用,详情可以参照下面博客:
STN介绍
在最初的使用中,STN的目的是学习转换输入数据,使其对某些转换保持不变。相反,我们的方法使用STN以对抗的方式生成增强样本的分布。
但是STN既然可以来矫正图像,那么当然可以扭曲图像,即将规范的图片进行平移旋转缩放操作改变图像的空间特性,增加任务网络对该图片的处理难度,本篇介绍的论文就是基于STN产生对抗样本来进行数据增广。
Adversarial Learning of General Transformations for Data Augmentation(2019)
摘要
数据增强(DA)是防止大型卷积神经网络过度拟合的基础,特别是在训练样本数量有限的情况下。在图像中,DA通常基于启发式变换,如图像翻转、裁剪、旋转或颜色变换。与使用预定义的转换不同,DA可以直接从数据中学习。现有的方法要么学习如何组合一组预定义的转换,要么训练用于DA的生成模型。我们的工作结合了这两种方法的优点。它学会了在一个端到端完全可微的网络结构中,使用空间变换网络和编码器结构相结合来变换图像。这两部分都是以对抗性的方式训练的,这样转换后的图像仍然属于同一类,但是对于分类器来说是新的、更复杂的样本。实验表明,在训练图像分类器时,我们的方法优于以往的生成数据增强方法。
动机
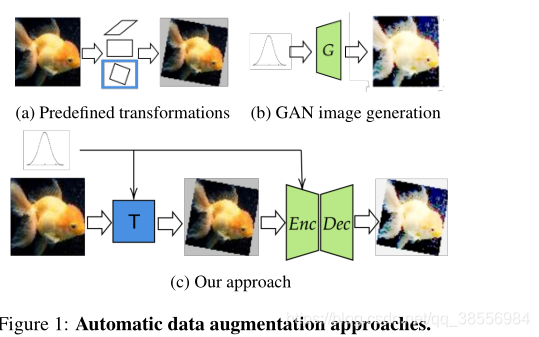
- 为了获得正确的训练和良好的性能,它们需要大的标记数据集。如果训练数据量很小,正则化技术可以帮助模型避免过度拟合。在这些技术中,数据增强似乎是提高网络最终性能的最有效方法。
- 目前一些预定义的变换可以产生一致性的精度改进。选择正确的转换需要先验知识,而选择的转换依赖于数据集。例如,如果水平翻转图像对自然图像来说是有意义的,它会在数字数据集上产生歧义。基于预定义的转换(图1a),这会阻止学习对分类器有用的其他转换(转换类型有限)。
- 基于生成对抗网络(GAN)的模型从数据p(X)的概率分布生成新样本(图1b)。这些方法在训练样本数较少的情况下表现出一定的局限性,因为很难用较少的训练数据集训练出一个好的生成模型,这种方法对MNIST这样的简单数据集是有效的,但似乎不适用于更复杂的数据集。
我们的工作将生成模型和转换学习方法的优势结合在一个单一的端到端网络架构中。首先,我们的模型不是学习生成样本,而是学习生成给定样本的转换(图1c)。在实际应用中,我们发现仿射变换学习全局变换,而编码器结构学习更多关于局部图像失真和颜色变化的局部变换。因此,两者的结合导致变换的一般分布,可以应用于任何基于图像的训练数据,而不是特定于给定的域或应用。
贡献
本文的主要贡献有:i)提出了一种完全可微、端到端可训练的数据增强网络,能够显著提高基于图像的分类器的性能;ii)我们以对抗的方式使用STN,与编码器编码器架构一起,能够学习用于扩充训练数据的一般转换的分布;iii)我们实验表明,对于数据扩充,学习图像转换比从头生成图像要好,联合学习数据增强和分类比两个独立任务更有效。
模型算法
该体系结构包括四个模块:一个用于转换输入图像的生成器
G
G
G,两个用于对生成的样本施加约束的鉴别器
D
c
{D^c}
Dc和
D
d
{D^d}
Dd,以及一个用于执行最终分类任务的分类器
C
C
C。
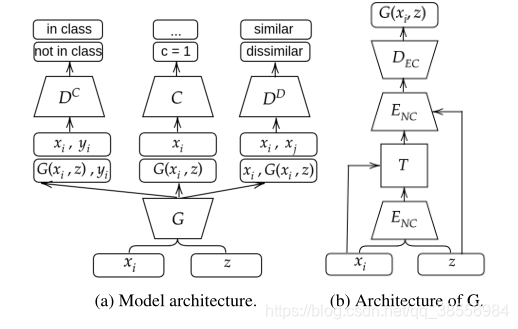
生成器由两个部分组成:学习全局仿射变换的空间变换网络(STN)和原则上可以学习任何其他变换的U-Net变体。在原始的论文中,空间变换模块用于去除输入数据的不变性,而该模型在本篇论文中用于数据增广。生成器可以被定式如下:
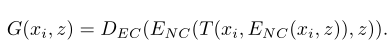
生成器的损失函数可以表示为以下三项的加权和:
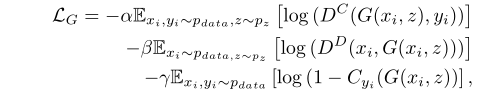
其中
D
c
{D^c}
Dc和
D
d
{D^d}
Dd分别是类和异类判别器。它们的作用是对转换后的图像实施约束。更多细节将在以下段落中给出。
C
y
i
{C_{{y_i}}}
Cyi为i类的分类网络的softmax输出,即给定图像属于yi类的概率。最后,引入α、β和γ作为超参数来平衡三个损失项,稳定模型的训练。
损失函数的第一项增加了变换样本)确实属于原始样本的同一类的概率。第二项增加了变换样本和原始样本不同的概率。最后,第三项降低了变换样本的正确分类F的概率。这种损失促使生成器生成难以分类的图像。
实验
当在数据集太小的情况下学习样本的生成时,生成器会生成对分类器没有帮助的差样本。当样本数增加时,我们的方法比标准数据增加的方法获得了更好的精度。例如,在4000个训练样本中,基线获得66%的精度,预定义的数据增强获得76%的精度,我们的模型达到80.5%的精度,因此与基线相比净增14个点,与数据增强模型相比净增4个点。
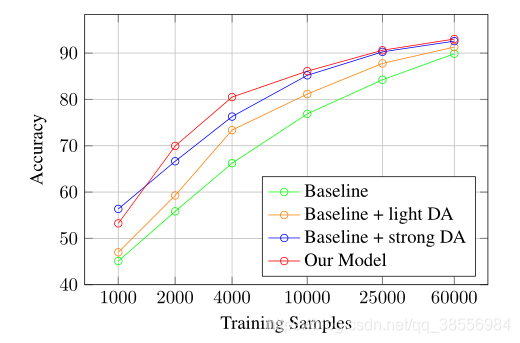
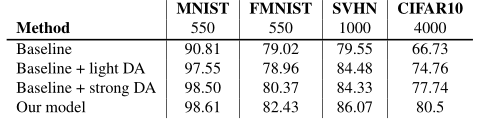
在第二个实验中,我们比较了四个数据集在减少样本数的情况下不同类型的数据增强。如表所示。1、我们最好的机型总是表现得比轻DA和强DA好。这意味着我们的数据扩充模型学习对最终分类器更有用的转换。注意,在FMNIST上,轻DA会降低最终分类器的性能。这表明数据扩充依赖于数据集,在某些域中生成有用的新样本的转换在其他域中可能不可用。
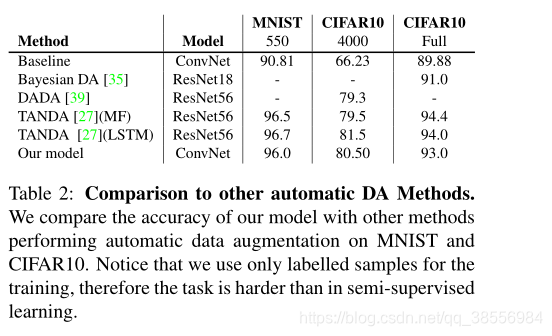
我们将我们的方法与其他自动数据扩充方法进行了比较。与TANDA[27]相比,我们的方法获得的精度略低。

我们的方法学习为每个数据集应用正确的转换。例如,在MNIST和Fashion MNIST上没有翻页或缩放,因为这并不有用,而在SVHN上通常使用缩放,在CIFAR10上,同时应用缩放、翻页和颜色更改。
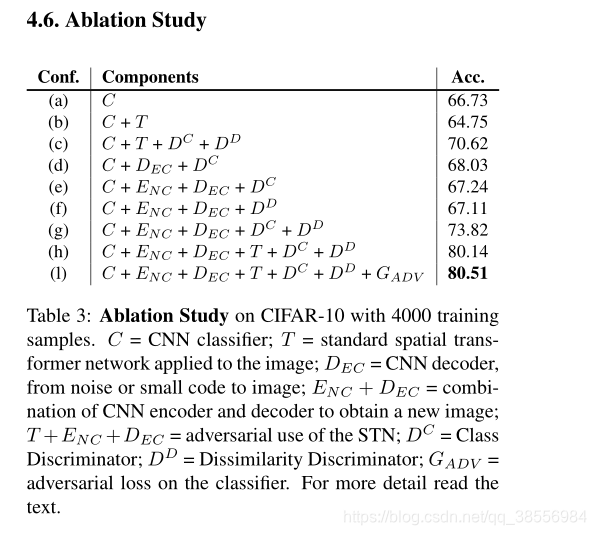
**消融实验。我们看到如果单单使用T效果还下降了,为64.75%,如果使用了T还加入了鉴别器那效果就好一些了70.62,再加入生成编码解码到达80.14%,73.82高于70.62那就是说局部图像失真和颜色变化的局部变换比整体变换好。**但是他这个局部变化是基于生成的,生成的对于序列任务可能不太适合???

















 2892
2892

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









