







引言
数据增广最简单的就是对图像进行平移、旋转以及缩放等等,但是如何将这些操作进行组合以及如何可以对增广策略进行迁移,主要介绍一篇2018年的论文次采用了强化学习进行策略搜索来解决这个问题,我们可以来看一下。此外还简单介绍两篇2020年最新的数据增广论文。
AutoAugment: Learning Augmentation Policies from Data
摘要
在本文中,我们将更深入地研究图像的数据增强,并描述一个称为AutoAugment的简单过程来搜索改进的数据增强策略。我们的关键见解是创建数据扩充策略的搜索空间,直接在感兴趣的数据集上评估特定策略的质量。在我们的实现中,我们设计了一个搜索空间,其中一个策略由许多子策略组成,其中一个子策略是为每个小批量中的每个图像随机选择的。子策略由两个操作组成,每个操作是图像处理函数,例如平移、旋转或剪切,以及应用这些函数的概率和幅度。我们使用搜索算法来寻找最佳策略,这样神经网络在目标数据集上产生最高的验证精度。最后,可以将从一个数据集中学习到的策略传输到其他类似的数据集中。例如,在ImageNet上学习的策略允许我们在细粒度视觉分类数据集Stanford Cars上获得最新的精度,而无需在额外数据上预先训练微调权重。
动机
- 机器学习和计算机视觉社区的一大焦点是设计更好的网络架构。在寻找更好的包含更多不变性的数据增强方法方面,人们的关注较少。
- 当增强方法对特定数据集改进时,很难同样适应于其他数据集。训练过程中的图像水平翻转是CIFAR-10上的一种有效的数据增强方法,而MNIST上则没有这种方法,因为这些数据集中存在不同的对称性。近年来,对自动学习数据扩充的需求作为一个尚未解决的重要问题而被提出。
贡献
1.在我们的实现中,每个策略表示可能的增强操作的几个选择和顺序,其中每个操作是图像处理功能(例如平移、旋转或颜色标准化)、应用该功能的概率以及应用它们的幅度.我们使用搜索算法来寻找这些操作的最佳选择和顺序,这样训练神经网络就可以获得最佳的验证精度。在我们的实验中,我们使用强化学习作为搜索算法。
2. 我们的方法在诸如CIFAR-10、reduced CIFAR-10、CIFAR-100、SVHN、reduced SVHN和ImageNet(无需额外数据)的数据集上实现了最新的精度。
3. 我们展示了在一个任务上发现的策略可以很好地在不同的模型和数据集上推广,这一结果表明,迁移数据增强策略为迁移学习提供了一种可供选择的方法。
模型
我们将寻找最佳扩充策略的问题描述为离散搜索问题。在我们的搜索空间中,一个策略由5个子策略组成,每个子策略由两个图像操作按顺序应用组成,每个操作还与两个超参数关联:
1)应用该操作的概率
2)操作的大小。
下图显示了一个在我们的搜索空间中包含5个子策略的策略示例。

**搜索空间。**我们搜索的操作是ShearX/Y、TranslateX/Y、Rotate、AutoContrast、Invert、Equalize、Solarize、Posterize、Contrast、Color、Brightness、Sharpness、Cutout、Sample Pairing。我们的搜索空间总共有16个操作。每个操作还带有一个默认的震级范围,这将在第4节中进行更详细的描述。我们将震级范围离散为10个值(均匀间距),以便使用离散搜索算法查找它们。类似地,我们还将该操作应用于11个值(均匀间距)的概率离散化。在
(
16
×
10
×
11
)
2
{\left( {16 \times {\rm{10}} \times {\rm{11}}} \right)^{\rm{2}}}
(16×10×11)2的可能性空间中,找到每个子策略成为一个搜索问题。然而,我们的目标是同时找到5个这样的子政策,以增加多样性。有5个子策略的搜索空间大约有
(
16
×
10
×
11
)
10
{\left( {16 \times {\rm{10}} \times {\rm{11}}} \right)^{{\rm{10}}}}
(16×10×11)10≈2.9×1032个可能性。

**搜索算法细节。**我们在实验中使用的搜索算法使用强化学习。搜索算法由两部分组成:控制器(递归神经网络)和训练算法(最近策略优化算法)。在每个步骤中,控制器预测由softmax产生的决策;然后将该预测作为嵌入输入下一步。为了预测5个子策略,控制器总共有30个softmax预测,每个子策略有2个操作,每个操作需要操作类型、大小和概率。
对于小批量中的每个示例,随机选择5个子策略中的一个子策略来增强图像。然后在验证集上对子模型进行评估以测量其准确性,并将其作为奖励信号来训练递归网络控制器。
实验
在本节中,我们实验研究了我们的方法在CIFAR-10、CIFAR-100、SVHN和ImageNet数据集上的性能。我们描述了我们用来寻找扩充策略的实验。






Image Augmentation Is All You Need: Regularizing Deep Reinforcement Learning from Pixels
提出了一种简单的数据增强技术,可以应用于标准的model-free强化学习算法,使得直接从像素点进行鲁棒学习,而不需要辅助损失或预训练。该方法利用计算机视觉任务中常用的输入扰动对值函数进行正则化。现有的model-free方法,如Soft Actor-Critic(SAC),无法从图像像素有效地训练深层网络。然而,我们的增强方法的加入极大地提高了SAC的性能,使其能够在DeepMind控制套件上达到最先进的性能。
作者的实验效果:

DATA AUGMENTATION IMBALANCE FOR IMBALANCED ATTRIBUTE CLASSIFICATION
行人属性识别是一个重要的多标签分类问题。尽管卷积神经网络在从图像中学习区分特征方面表现突出,但在细粒度任务的多标签设置中,数据不平衡仍是一个有待解决的问题。本文提出了一种新的重采样算法:数据增广不平衡(DAI),通过增加标签占小部分的比例,显式地提高了识别较少属性的能力。从根本上讲,在多标签数据集上同时采用过采样和欠采样的方法,抢富济贫的思想对DAI的发展做出了重要贡献。大量的经验证据表明,我们的DAI算法在行人属性数据集(即标准PA-100K和PETA数据集)上取得了最新的结果。
动机
- 许多人身数据的属性识别在其类分布上自然表现出不平衡性。例如,lowerBodyCasual属性的比例达到0.86,accessorNothing属性的比例达到0.74,而60岁以上的样本在PETA数据集上只占0.06。具有高比例的属性是高度倾斜的,因为在现实生活中他们比具有较少样本的属性更容易获得样本。
- 对于多标签环境下采样方法的不平衡问题,目前还没有新的见解。
- 为了解决多标签场景中的重采样问题,DAI将重点放在多标签设置中的不平衡数据上。然后利用DAI构造子平衡数据集,依次训练子平衡数据集和整个训练集。
贡献
- DAI通过增加标签占很小比例的正比例,明显增强了较少属性的区分能力。
- DAI可以在多标签设置中工作。它能尽可能平衡每个标签。
- 在接下来的广泛评估中,我们在两个主流数据集(PA-100K,PETA)中取得了最新的结果,与其他基线相比,我们的方法取得了显著和一致的改进.
算法
这里我们定义A为m×n的标签矩阵,m等于训练样本数,n等于每个图像具有的属性数。r是长度等于m的重加权向量,它表示在整个训练数据集上应用DAI后,子平衡数据集中存在的样本数。经过权重分配后,每个标签中样本所占的比例可以表示为:
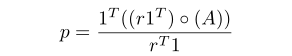
我们希望少数样本的标签通过重新采样更加平衡。在这里我们给出了最小化的目标作为公式。
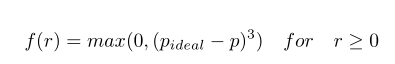
为了将上式最小化,我们将其转换为无限制的形式,这样我们可以通过梯度下降来最小化它。
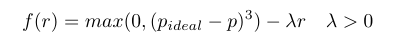
实验

为了更好地证明我们设计的模型的有效性和优越性,我们应用了成分消融研究来明确说明每个模块对不同数据集的贡献。















 1125
1125











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









