







四、图像分类之后发展
这里只做简介,并给出引用,因为别人已经写得很好了,概念类东西不是本系列的重点,我主要写的是在之后章给出的一些自己的tip
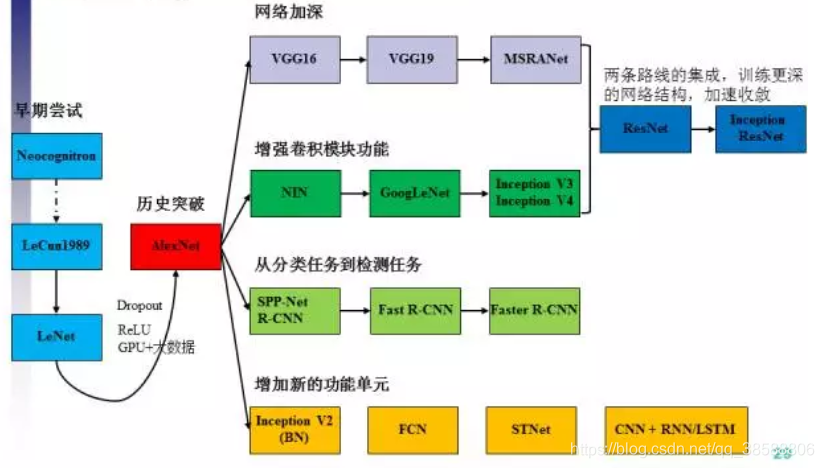
图像分类模型叙述步骤如下:CNN之前模型->leNet->AlexNet->VGG系列->GoogLeNet->Inception系列->ResNet系列->Inception-Resnet系列->SENet。现在讲AlexNet
4.1 AlexNet
论文中alexnet如下定义

这算是跨时代的模型了,提出了dropout思想,Relu,LRN,最大池化。
1.dropout就是训练过程随机忽略一些神经元(输出设置为0),防止过拟合
2.Relu激活函数,解决梯度弥散,效果远超sigmoid
3.LRN就是局部正则化,对局部神经元的活动创建竞争机制,使得响应较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。引自论文:(目的是增强泛化能力)
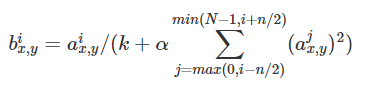
通过第i个核输出的点(x,y)由相邻核的输出进行正则化运算得到b,n是相邻区间,n/2就是下区间。k, n, α和β是超参数。
4.数据增强,225255截取224224,减轻过拟合,提升了泛化能力
5.最大值池化:之前是平均池化,并不能很好的滤掉噪点,如用最大值池化,去噪效果可以得到极大的提升,因此增强了泛化能力。
详见:AlexNet详细解读及AlexNet实现。这里别人已经说的很详细了。
4.2 VGG系列
图像分类模型叙述步骤如下:CNN之前模型->leNet->AlexNet->VGG系列->GoogLeNet->Inception系列->ResNet系列->Inception-Resnet系列->SENet。现在讲VGG
VGG16一般结构如图(引自论文)

不过VGG论文对比了四种配置,其中D就是VGG16,E就是VGG19,同样,前两个FC可以用dropout。

其改变如下:
1.卷积核统一用3X3的核。
2.池化核统一用2X2。
3.也有比如C级用到了1X1的卷积核
4.指出AlexNet常用的LRN用处不大
5.使用预训练好的参数初始化可以加速训练。
之前我们就说过卷积核的大小决定了是不是更多地考虑相邻像素之间的关系,但卷积核太大泛化能力就会下降,且特征图容易产生噪点,这里只采用了3*3的核,实际上,拟合能力可以用深度得到弥补,而1X1的核只是为了对图像进行一个线性变换,主要是1. 实现跨通道的交互和信息整合;2. 进行卷积核通道数的降维和升维。
值得注意的是这里用了连续卷积,这是为了提取更加丰富的特征,但连续卷积到一定程度必将造成质量下降,这里还是用maxpool,这是实验后得出的构造。实现见VGG实现。
4.3 GoogLeNet及inception系列
图像分类模型叙述步骤如下:CNN之前模型->leNet->AlexNet->VGG系列->GoogLeNet->Inception系列->ResNet系列->Inception-Resnet系列->SENet。现在讲GoogLeNet。其结构如下,最后结果是3个softmax加权。

LRN这些AlexNet的东西都没变,关键是多了inception结构如下。

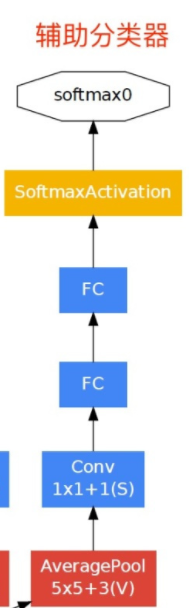
以及多出去的辅助分类器,3个softmax会进行加权判定。
GoogleNet参数比VGG小36倍,但性能却比VGG好,而inception结构经历了V1,V2,V3,V4四个版本。
Inception结构如图:

充分利用了1X1,3X3,5X5核的特性,所以既能增加神经网络表现,又能保证计算资源的使用效率。即多尺度的提取,不过问题仍然是如何权衡各个尺度的关系。然后为了减小参数,我们可以用一个1X1的核进行降维,减少参数量,这个原理就如我之前举的canny算子粒子,既然都是提取梯度,RGB在边缘处都有突变,不就可以直接低维嵌入?(激活函数仍然是ReLu)
修改后的InceptionV1如图:

当然,这肯定还不够,为了进一步减少计算量,GoogleNet又提出卷积分解概念,5X5的卷积可以由两个3X3的卷积替代,实际上大家可以仔细想一下,把图像矩阵先收缩再进行3X3卷积,完全可以替代5X5卷积。
进而有inceptionV2:

普遍意义来说,任意nxn的卷积都可以通过1xn卷积后接nx1卷积来替代,进而有InceptionV3:

InceptionV4是与resnet结合的网络,我们之后说
4.4 ResNet
ResNet算是深度学习的革命,网络的深度提升不能通过层与层的简单堆叠来实现。由于臭名昭著的梯度消失问题,深层网络很难训练。因为梯度反向传播到前面的层,重复相乘可能使梯度无穷小。结果就是,随着网络的层数更深,其性能趋于饱和,甚至开始迅速下降。于是resnet用了跳跃连接的方法,先上图:

这里要注意:resnet学习的是残差函数F(x) = H(x) - x,是让残差与目标函数尽可能拟合,而非函数,这样在计算反向传播的时候就缓解了梯度消失的情况。其18层到152层的配置如下:

代码实现见ResNet实现,原理见ResNet原理。
4.5 Inception-resnet系列
说白了就是resnet的残差与inception结构结合罢了。论文中结构如下:

具体见INCEPTION-RESNET介绍及代码实现。
4.6 SENet
即压缩激活网络,除了SE模块其他与之前讲的相同。其表述如下:

考虑了特征通道之间的相互依赖关系,所谓压缩可以理解为一个pooling只不过是有全局感受野的,而激活即通过参数 w 来为每个特征通道生成权重,其中参数 w 被学习用来显式地建模特征通道间的相关性。最后是一个 Reweight 的操作,将 Excitation 的输出的权重看做是进过特征选择后的每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定。与inception ,resnet结合后结构如下:

其效果如下,可以看出通过加入SEmodule让分类结果得到了有效的提升。

4.7 其他网络
4.7.1 DenseNet

建立的是前面所有层与后面层的密集连接,另一大特色是通过特征在channel上的连接来实现特征重用,相比于减少了参数数量且性能更好,配置如下:(引用自论文)
 具体见DenseNet原理。
具体见DenseNet原理。
4.7.2 Residual Attention Networks
就是引用了注意力机制,花书上面已经讲得太多了。结构如下:

配置表如下:

也可见注意力残差网络论文笔记。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









