




 本文深入解析强化学习核心概念,对比Q-learning与SARSA算法,探讨DQN、DPG及DDPG等深度强化学习方法,并引入AC算法及TRPO、PPO等策略梯度优化技巧,配以清晰图解,助你快速掌握强化学习精髓。
本文深入解析强化学习核心概念,对比Q-learning与SARSA算法,探讨DQN、DPG及DDPG等深度强化学习方法,并引入AC算法及TRPO、PPO等策略梯度优化技巧,配以清晰图解,助你快速掌握强化学习精髓。
强化学习总结
注:本文图片均来自莫烦python或深入浅出强化学习原理入门,但我觉得小哥哥不是很理解,或者说讲的不是让人很懂,这里我做一个比较细致的论述
一、强化学习概述
强化学习是机器学习的一种,为什么这样说,从Qlearning就可以看出来,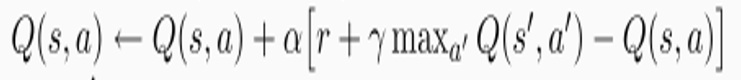
你看,什么时候Q(s,a)稳定啊,是不是当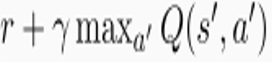 等于
等于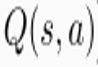 啊。所以这东西更新过程就是不断地迭代Q(s,a)让两项接近,第一项我们称Q现实,第二项称Q估计,梯度下降如下定义:
啊。所以这东西更新过程就是不断地迭代Q(s,a)让两项接近,第一项我们称Q现实,第二项称Q估计,梯度下降如下定义: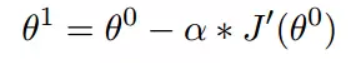
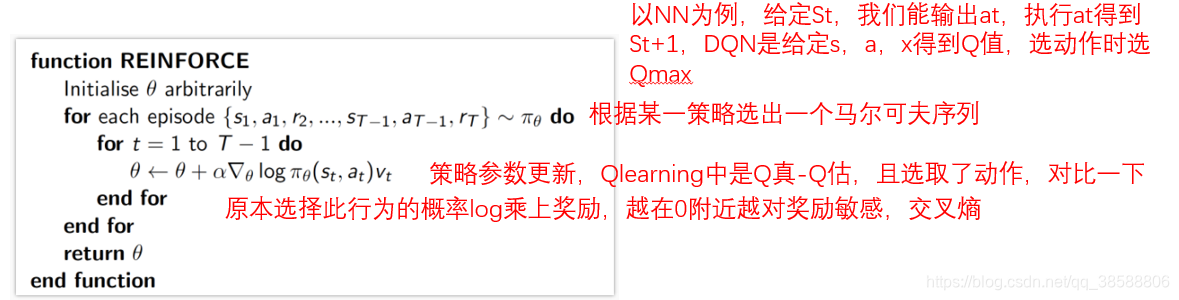
α就是学习率,是不是一样,只不过损失函数变J了,那既然这样,强化学习直接叫梯度学习算了,为什么还那么高大上呢,说白了,就一区别:强化学习的y标签是在探索过程中一个个给的(单步更新),或一小批次给的(回合更新),上一步的y和这一步的y有因果性,而普通的机器学习训练的时候总是直接拿一个batch去训练,没有因果性。假如你是一只狗,那么强化学习就是一口口喂你吃的,普通的机器学习是直接让你吃满汉全席。是不是简单死了。那既然这样,我们是不是可以用CNN来计算y估计与y真实,其差值的平方就是一个损失函数,那你是不是可以变一下,用高斯损失,MSL,交叉熵啊。值得一提的是R是环境给的,一般就是仿真的物理环境。
那强化学习还有个东西,即选择用于更新的数据的策略,分为同策略和异策略,比如Qlearning的步骤是在状态s选择一个动作a,到达一个状态s’,然后去更新上一个状态s,这时选择是e-greedy 除去随机,就是选Qmax,即选择在s状态下Q最大的,而在更新的时候用的是s下做a到s’的奖励加上下一个状态不管什么动作Q最大的那个减去原来的Q乘上y。(这里又体现了时序差分,即选择的是s下的Q(s,a),更新是用的下一步的Q(s’,a’),就是时间不同嘛)。 那关键是我们更新用的是下一状态s’不管什么动作Q最大的那个Q(s’,a’),但我在s’选择动作时,我不一定选择的就是我之前用于更新的那个Q(s’,a’)啊,这就是异策略,大家可以理解下。而sarsa是同策略,选什么就更新什么,但仍然是时序差分。如下。
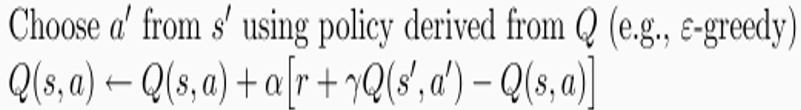
Qlearning选了一次,sarsa选了两次,大家可以在下面的代码看到:(注:原文没有备注,而我帮大家备注了下)
1.1 Qlearning框图如下,不难理解

1.2 sarsa框图如下,也不难理解

两者最大的区别就是sarsa比较保守,而QLeaning比较激进,即假设终点附近有很多奖励为负的点时,Qlearning会德玛西亚冲冲冲,表现为损失(真实-估计)上窜下跳幅度大,最后能收敛到一个较小值,而sarsa容易一直在观望徘徊到不了终点,表现为损失上蹿下跳幅度小,但一直在高位。
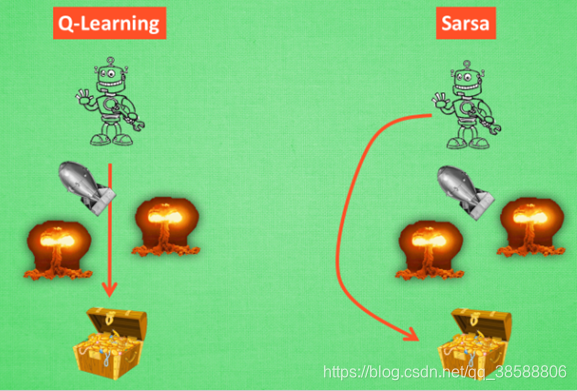
这样我们就知道强化学习的基本概念了。这两哥们可是经典算法,你可以用它来走迷宫。
1.3 sarsa(λ)
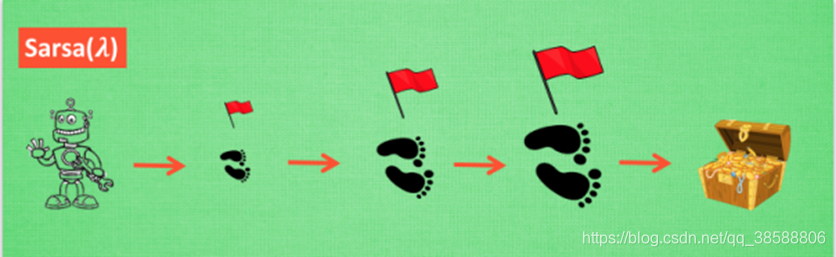
这属于TD(λ)系列,为什么要这孩子,我们先说如何更新吧,假设你走在第10步走到了栅格迷宫的终点得到了奖励+10,那么我可以给第10步的格子一个Q(s,a)加成+10,第9步的格子Q(s,a)加成+9,第5步的格子Q(s,a)加成+5,第5步的格子Q(s,a)加成+5。。。是不是超简单,什么反向模型,什么巴拉巴拉,就这么个简单道理,但是不同的是,奖励不是按我这样叙述的下降的,但是思路是这样的。其伪代码如图:

δ就是TD error,所谓Q真-Q估,这个大家要记住了,也就是机器学习的loss,只不过给每步的loss加了E(S,A)这个权值,这个意思很简单,就是你得到了奖励的话,在马尔可夫序列中离得越远影响越小,马尔可夫序列就是你执行过的动作及相应状态的序列如(S1,A1)->(S2,A2)->(S3,A3)。如下图第二张,但我不希望这个权重过大,因为多个衰减都叠加到一个Q上,这样Q如果是必经之路,Q值爆炸,容易陷入局部最小值,(虽然有e-greedy)为此,我们限制E(S,A)的大小,不让他太大,以有更多机会考虑其他情况。这里我提到了e-greedy可以避免局部最小,为什么,因为它有e的几率选择一个随机动作而不是根据Qmax,那还有啥呢,遗传算法和模拟退火。
二、向深度进发
2.1 DQN
有人说DQN难?世界上还有比这更简单的吗?强化学习不就是机器学习,机器学习怎么用CNN,强化学习一样。其框图如下,我做了备注:双网络下:

多了个记忆池用于回放,而不是直接单步训练,CNN的作用是把动作,映射的状态放进去能得到一个奖励值,我们选择奖励值最大的。那机器就有改进:如下:
1.我不对记忆池随机采样了,因为比如走迷宫,有正奖励的就到终点那一下,是不是正负样本不均衡,我希望我能采样到更多正样本,于是有了DQN with prioritized replay算法,如下:

2.Q其实很容易过估计,说白了,TD(入)我们就说过这个问题,那咋办,改TD(入)吧,不另一个double DQN,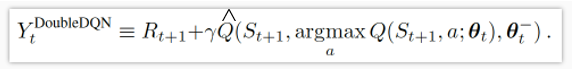
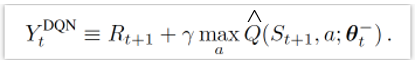
对比后发现了啥,是不是根据原来的选择的是最新的更新,现在先用老的网络选个动作再用此用新网络算Q更新。
3.比方说我让机器人给我做脑科手术,我希望它把刀伸进我脑子的时候更保守些,那是不是就需要优势函数,那dueling DQN就应运而生。
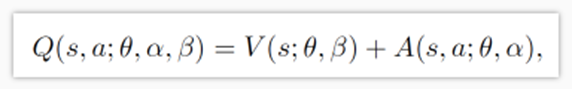
这里优势函数是我们给的,无人驾驶中是目标检测后给的。
三、PG族
3.1 policy gradient
DQN是一个黑箱子,给他s和a他给你一个奖励值,我们在选择时选奖励最大的那个,PG如果深度化就是给他S,他给你机器人要执行各个动作的概率,当然,哪个动作潜在奖励更大,他概率就越高,但机器还是有可能选择概率小的那个。
这个是回合更新要先走一次的,达到终止条件才更新,比方说下棋,棋局结束才更新的。θ更新用交叉熵,说白了,越不可能给我大奖励的事情给了我大的奖励,θ就有大的更新,越有可能给我大奖励的事情给了我大奖励,我却熟视无睹,这就是为什么我们总对陌生人的态度好过自己的亲人。
说到这个,我们顺便提及蒙特卡罗强化学习,说白了也是一样,随便乱走,达到终止条件才更新,不过奖励是一个整个过程的平均罢了,需要加一些其他的策略,不然这方法就是一傻子方法。

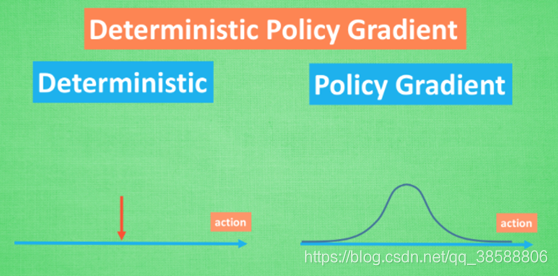
3.2 DPG
D指的是确定性,本来我们输出机器人执行各个动作的概率,现在我们选择概率最大的那个作为我们的动作。细看见DDPG介绍。这没啥难的
3.3 DDPG
这个D才是深度。这一共有4个网络如下,这里用到了Actor-Critic思想。
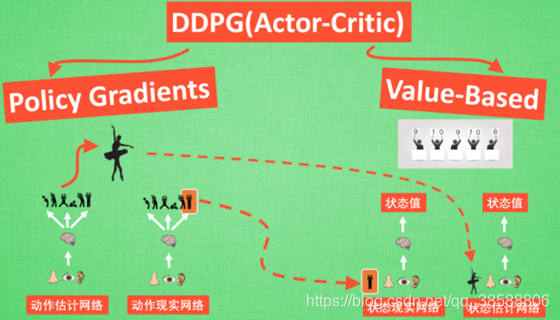
现在我们介绍Actor-Critic
说白了,PG是回合更新,我们需要的是单步更新,而Qlearning不能解决动作值连续的情况,(PG可以输出概率值的概率分布啊),Q要给出每个动作的Q,然后选Qmax,对于连续值只能离散采样,一个个算,浪费时间。那我们结合这两个,得到AC算法
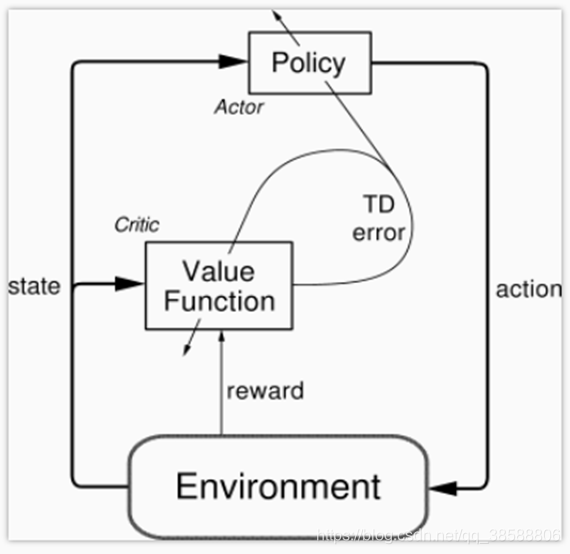
这个难吗,不难,就两个网络,一个是PG网络,一个是Qlearning的网络,不就是刚开始你在S状态,你用PG选一个动作去执行,然后观察环境给你的奖励然后得到(Q真-Q估)这不就是TDerror,我们是不是一直都是用TDerror更新Q的网络参数的,那我也用这个TDerror去更新PG的网络参数,不就可以了。那最后是怎样,Critic收敛,actor收敛,但一般情况达不到,所以我们加个类似TD(入)的东西,如下:

仔细看,不过是多了个权罢了。
然而还不够:
于是我们有了DDPG,再次贴图:
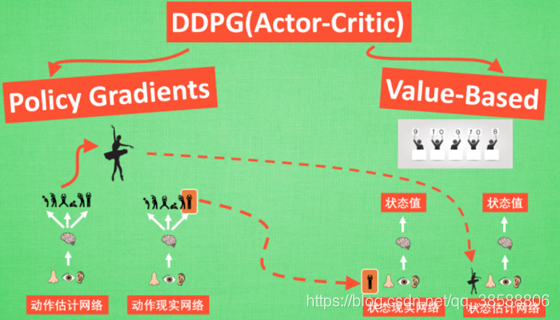
4个网络,用动作估计网络去产生了估计动作,然后得到的奖励去算TDerror更新状态估计网络,用动作现实网络去产生了现实动作,然后得到的奖励去算TDerror更新状态现实网络。而右边都产生了状态值,这个状态值是给动作网络的输入,就是这样的形式,这样训练后网络易于收敛。知道AC这个不难理解。具体见DDPG算法,要你手写怕是也不难,值得一提的是DDPG仍然有记忆池,这个可以从算法去理解,要不然咋能搞四个网络呢。
3.4 TRPO
说白了解决PG算法的步长问题,PG的交叉熵在小概率时间发生大奖励的时候容易爆炸,这并不是我们想要的,于是,我希望能有个合理的步长,详细见TRPO算法。
那么还有种办法叫PPO,仍然见PPO类算法。

建议看论文去,不要看CSDN的公式,别人讲过的我就不讲了。
四、面向分布式
多个CPU同时提高训练效率,代表有:
1.DPPO(分布式PPO)见DPPO视频
2.A3C,多个actor。

这个别人已经写得很好了从AC到A3C教程。
最后我可能会不定期更新,希望大家多多关注,谢谢哈。

















 1048
1048

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









