









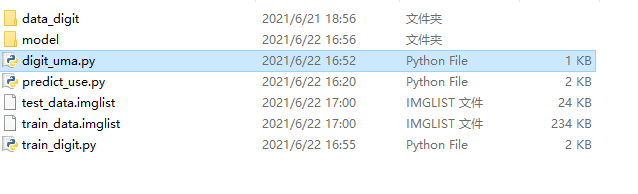
建立工程目录

data_digit 数据集
model 模型保存位置
digit_uma.py 生成准备文件
predict_use.py 预测图片文件
train_digit.py 训练生成网络文件
数据集

说明:0-9每个种类一千张,共10000张,需要求留言
digit_uma.py
# coding: utf-8
import os
import cv2
import numpy as np
import random
def write_img_list(data, filename, num=10000):
file_list = os.listdir(data)
print (len(file_list))
file_list = random.sample(file_list,num)
with open(filename, 'w') as f:
for i in range(len(file_list)):
f.write(data + "/" +file_list[i]+' '+ file_list[i][0] +'\n')
write_img_list("data_digit", 'train_data.imglist',10000)
write_img_list("data_digit", 'test_data.imglist',1000)
说明:从数据集目录遍历文件,得到文件列表,并随机得到10000张(打乱顺序),1000张(获取测试图片)。

建立txt.txt
0
1
2
3
4
5
6
7
8
9
说明,如果是本文数据集一共十类,0-9。 假设为26个字母,应写入a-z.
此文件为标签索引文件。
lenet_auto_solver.prototxt
train_net: "auto_train.prototxt"
test_net: "auto_test.prototxt"
test_iter: 50
test_interval: 150
base_lr: 0.9
momentum: 0.9
weight_decay: 0.05
lr_policy: "step"
gamma: 0.25
stepsize: 1000
display: 100
snapshot: 500 # 每500次输入一次模型
snapshot_prefix: "model/let"
solver_mode: GPU
max_iter: 1500 # 最大迭代次数
说明:相当于caffe的配置文件。
train_digit.py
import caffe
from caffe import layers as L
import os
import numpy as np
from matplotlib import pyplot as plt
Solver_PATH = 'lenet_auto_solver.prototxt'
def change_env():
root = os.path.dirname(__file__)
os.chdir(root)
print ("current work root:->",root)
def net(img_list,batch_size,mean_value=0):
network = caffe.NetSpec()
network.data,network.label = L.ImageData(source=img_list,batch_size=batch_size,new_width=28,new_height=28,ntop=2, transform_param=dict(scale=1/255.0, mean_value=mean_value))
network.ip1 = L.InnerProduct(network.data,num_output=50,weight_filler=dict(type="xavier"))
network.relu1 = L.ReLU(network.ip1,in_place=True)
network.ip2 = L.InnerProduct(network.relu1,num_output=10,weight_filler=dict(type="xavier"))
network.loss = L.SoftmaxWithLoss(network.ip2,network.label)
network.accu = L.Accuracy(network.ip2,network.label)
network.prob = L.Softmax(network.ip2)
return network.to_proto()
def file_write(path1="auto_train.prototxt",path2="auto_test.prototxt"):
with open(path1,"w") as f:
f.write(str(net("train_data.imglist",200,108)))
with open(path2,"w") as f:
f.write(str(net("test_data.imglist",40,108)))
def main():
change_env()
file_write()
solver = caffe.SGDSolver(Solver_PATH)
solver.solve()
if __name__ == '__main__':
main()
说明,定义网络结果,并输出,加载solver文件并训练,训练1500次。
deploy.prototxt
layer {
name: "data"
type: "Input"
top: "data"
input_param { shape: { dim: 64 dim: 3 dim: 28 dim: 28 } }
}
layer {
name: "ip1"
type: "InnerProduct"
bottom: "data"
top: "ip1"
inner_product_param {
num_output: 50
weight_filler {
type: "xavier"
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "ip1"
top: "ip1"
}
layer {
name: "ip2"
type: "InnerProduct"
bottom: "ip1"
top: "ip2"
inner_product_param {
num_output: 10
weight_filler {
type: "xavier"
}
}
}
layer {
name: "prob"
type: "Softmax"
bottom: "ip2"
top: "prob"
}
说明:与auto_train.prototxt类似,去除第一层,loss、accu层,如果不正确会影响预测结果。
predict_use.py
# -*- coding: UTF-8 -*-
import caffe
import numpy as np
import matplotlib.pyplot as plt
def test(my_project_root, deploy_proto):
caffe_model = './model/lenet_iter_500.caffemodel'
img = 'data_digit/6_2.png'
labels_filename = 'txt.txt'
net = caffe.Net(deploy_proto, caffe_model, caffe.TEST)
mu = np.load('ilsvrc_2012_mean.npy')
mu = mu.mean(1).mean(1)
print ('mean-subtracted values:', zip('BGR', mu))
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape})
transformer.set_transpose('data', (2,0,1))
transformer.set_mean('data', mu)
transformer.set_raw_scale('data', 255)
transformer.set_channel_swap('data', (2,1,0))
net.blobs['data'].reshape(64,3,28, 28)
image = caffe.io.load_image(img)
transformed_image = transformer.preprocess('data', image)
plt.imshow(image)
net.blobs['data'].data[...] = transformed_image
output = net.forward()
output_prob = output['prob'][0]
print ('predicted class is:', output_prob.argmax())
labels = np.loadtxt(labels_filename, str, delimiter='\t')
prob = net.blobs['prob'].data[0].flatten()
order = prob.argsort()[-1]
print ('predicted object is:',labels[order])
if __name__ == '__main__':
my_project_root = "./"
deploy_proto = my_project_root + "deploy.prototxt"
test(my_project_root, deploy_proto)

ilsvrc_2012_mean.npy caffe目录里能找到
说明,识别率很高,刚开始由于配置不正确,准确率很高,但识别率几乎为零。
注意deploy.prototxt的内容。
此外,训练时需要加入loss,accu层,不加入的话,几乎识别不了。
注意即使相同图片,如果格式不同,识别效果也不同,最好和训练图片格式保持一致。
















 1926
1926











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











