









案例数据准备
下载
链接:https://pan.baidu.com/s/10CmpZUdEVmma4A0mziu9dw
提取码:dmjr
复制这段内容后打开百度网盘手机App,操作更方便哦
解压后放到data/mnist
进入C:\Windows\System32\WindowsPowerShell\v1.0
管理员运行PowerShell
PS F:\caffe-windows> examples\mnist\create_mnist.ps1
生成两个目录
之后将mnist拷贝到自己的工程目录备用
文件目录
lmdb提取数据,获取图片
# -*- coding:utf-8 -*-
import caffe
from caffe.proto import caffe_pb2
import lmdb
import cv2 as cv
env = lmdb.open("mnist/mnist_train_lmdb", readonly=True) # 打开数据文件
txn = env.begin() # 生成处理句柄
cur = txn.cursor() # 生成迭代器指针
datum = caffe_pb2.Datum() # caffe 定义的数据类型
for key, value in cur:
print(type(key), key)
datum.ParseFromString(value) # 反序列化成datum对象
label = datum.label
data = caffe.io.datum_to_array(datum)
print (data.shape)
print (datum.channels)
image = data[0]
image = data.transpose(1, 2, 0)
print(type(label))
cv.imwrite("temp.png",image)
cv.imshow("img", image)
key = cv.waitKey(0) & 0xFF
if key == 27 or key == ord('s'):
break
cv.destroyAllWindows()
env.close()
运行代码,会显示一张图片,如果喜欢,esc或q键退出即可,不喜欢按任意键继续显示,
当想要退出按esc或q键。然后同级目录产生一张图片,只会保存查看过的最后一张。
生成配置文件并训练
#coding='utf-8'
import lmdb
import caffe
from caffe.proto import caffe_pb2
from caffe import layers as L
from caffe import params as P
from matplotlib import pyplot as plt
import numpy as np
solver_file = './mnist/lenet_auto_solver.prototxt'
train_proto = "./mnist/lenet_auto_train.prototxt"
train_lmdb = "./mnist/mnist_train_lmdb"
test_proto = "./mnist/lenet_auto_test.prototxt"
test_lmdb = "./mnist/mnist_test_lmdb"
def lenet(lmdb,batch_size):
n = caffe.NetSpec()
n.data,n.label = L.Data(batch_size=batch_size,backend=P.Data.LMDB,source=lmdb,transform_param=dict(scale=1./255,mean_value=0),ntop=2)
n.conv1 = L.Convolution(n.data,num_output=20,kernel_size=5,weight_filler=dict(type='xavier'))
n.pool1 = L.Pooling(n.conv1,pool=P.Pooling.MAX,kernel_size=2,stride=2)
n.conv2 = L.Convolution(n.pool1,num_output=50,kernel_size=5,weight_filler=dict(type='xavier'))
n.pool2 = L.Pooling(n.conv2,pool=P.Pooling.MAX,kernel_size=2,stride=2)
n.fc1 = L.InnerProduct(n.pool2, num_output=500, weight_filler=dict(type='xavier'))
n.relu1 = L.ReLU(n.fc1,in_place=True)
n.score = L.InnerProduct(n.relu1, num_output=10, weight_filler=dict(type='xavier'))
n.loss = L.SoftmaxWithLoss(n.score,n.label)
n.accu = L.Accuracy(n.score,n.label)
n.prob = L.Softmax(n.score)
return n.to_proto()
def gen_solver(solver_file, train_proto, test_net_file=None):
s = caffe_pb2.SolverParameter()
s.train_net = train_proto
if not test_proto:
s.test_net.append(train_proto)
else:
s.test_net.append(test_proto)
s.test_interval = 200
s.test_iter.append(50)
s.max_iter = 10000
s.base_lr = 0.010
s.momentum = 0.9
s.weight_decay = 5e-4
s.lr_policy = 'inv'
s.gamma = 0.1
s.power = 0.75
s.display = 100
s.snapshot = 200
s.snapshot_prefix = 'mnist/lenet'
#s.type = 'SGD'
#s.solver_mode = caffe_pb2.SolverParameter.GPU
with open(solver_file, 'w') as f:
f.write(str(s))
def write_data(train_proto,train_lmdb,test_proto,test_lmdb):
with open(train_proto,'w') as f:
f.write(str(lenet(train_lmdb,64)))
with open(test_proto,'w') as f:
f.write(str(lenet(test_lmdb,100)))
def main():
write_data(train_proto,train_lmdb,test_proto,test_lmdb)
#caffe.set_device(0)#使用GPU
#caffe.set_mode_gpu()
gen_solver(solver_file, train_proto, test_net_file=None)
solver = None
solver = caffe.SGDSolver(solver_file)
test_interval = 25
niter = 400
train_loss = np.zeros(niter)
test_acc = np.zeros(int(np.ceil(niter/test_interval)))
output = np.zeros((niter,8,10))
for it in range(niter):
solver.step(1)
#train_loss[it] = solver.net.blobs['loss'].data
solver.test_nets[0].forward(start='conv1')
output[it] = solver.test_nets[0].blobs["score"].data[:8]
if it%test_interval == 0:
print("run test ing...",it)
f = open("num.txt","w")
correct = 0
for test_it in range(100):
solver.test_nets[0].forward()
correct+=sum(solver.test_nets[0].blobs['score'].data.argmax(1) == solver.test_nets[0].blobs['label'].data)
test_acc[it//test_interval] = correct/1e4
print("run test ing...",test_acc[-1])
f.write(str(test_acc) + " " + str(it)+"\n")
f.close()
_, ax1 = plt.subplots()
ax2 = ax1.twinx()
ax2.plot(test_interval*np.arange(len(test_acc)), test_acc, 'r')
ax1.set_xlabel('iteration')
ax1.set_ylabel('train loss')
ax2.set_ylabel('test accuracy')
ax2.set_title('Test accuracy:{:.2f}'.format(test_acc[-1]))
_.savefig('result1.png')
main()
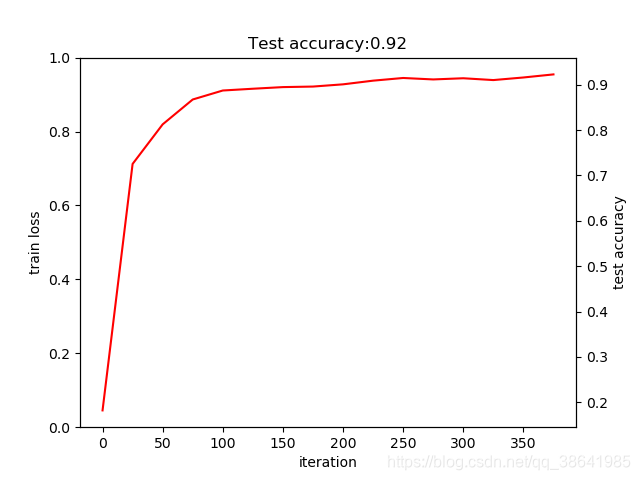
说明,利用caffe生成train,test的prototxt文件,而且也会生成solver的t的prototxt文件。
由于使用cpu进行训练,所以写入txt文件查看进度。
deploy.prototxt
layer{
name: "data"
type: "Input"
top: "data"
top: "label"
input_param { shape: { dim: 64 dim: 1 dim: 28 dim: 28 } }
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
convolution_param {
num_output: 20
kernel_size: 5
weight_filler {
type: "xavier"
}
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
convolution_param {
num_output: 50
kernel_size: 5
weight_filler {
type: "xavier"
}
}
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "fc1"
type: "InnerProduct"
bottom: "pool2"
top: "fc1"
inner_product_param {
num_output: 500
weight_filler {
type: "xavier"
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "fc1"
top: "fc1"
}
layer {
name: "score"
type: "InnerProduct"
bottom: "fc1"
top: "score"
inner_product_param {
num_output: 10
weight_filler {
type: "xavier"
}
}
}
layer {
name: "prob"
type: "Softmax"
bottom: "score"
top: "prob"
}
预测
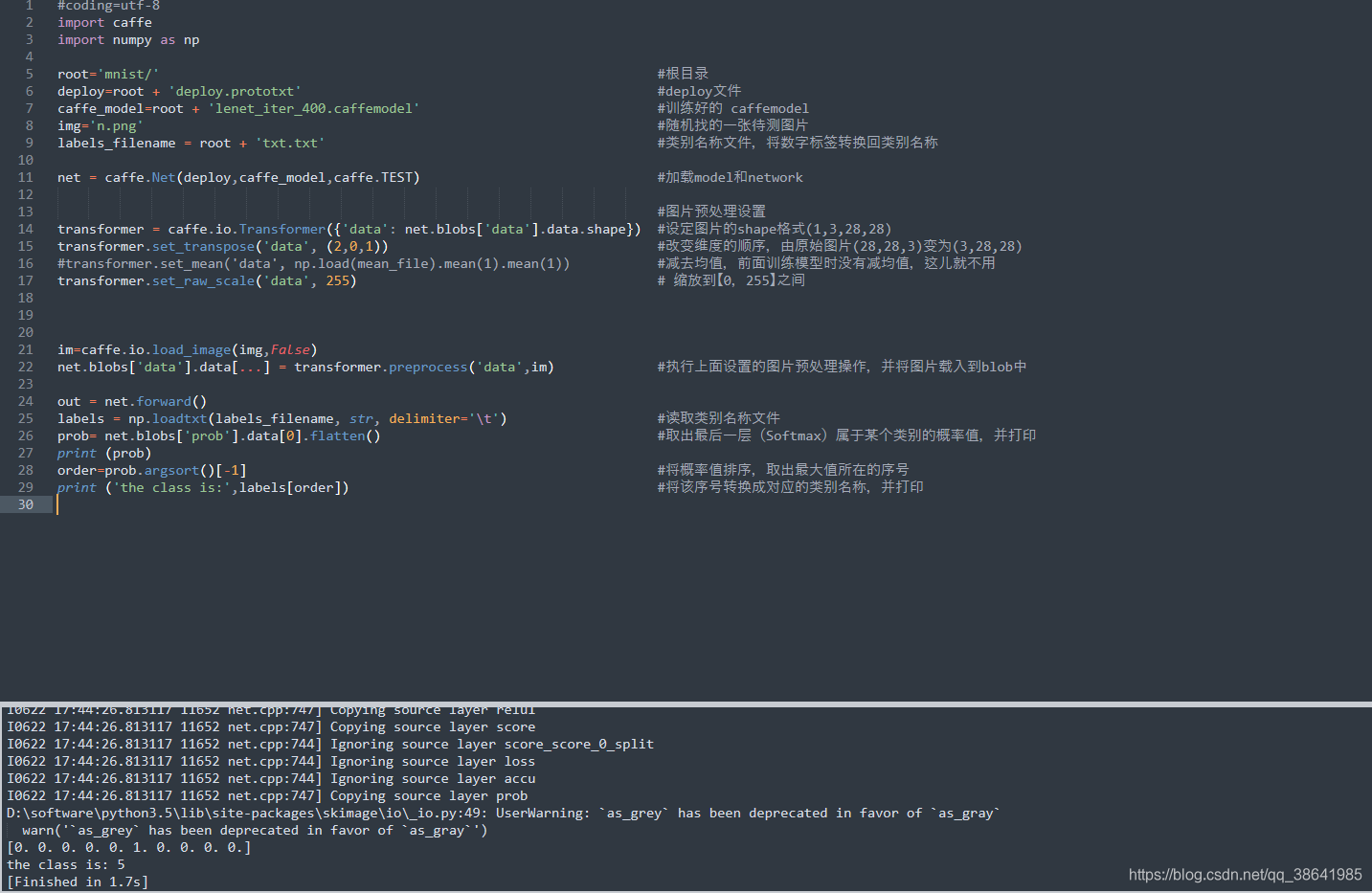
#coding=utf-8
import caffe
import numpy as np
root='mnist/' #根目录
deploy=root + 'deploy.prototxt' #deploy文件
caffe_model=root + 'lenet_iter_400.caffemodel' #训练好的 caffemodel
img='n.png' #随机找的一张待测图片
labels_filename = root + 'txt.txt' #类别名称文件,将数字标签转换回类别名称
net = caffe.Net(deploy,caffe_model,caffe.TEST) #加载model和network
#图片预处理设置
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape}) #设定图片的shape格式(1,3,28,28)
transformer.set_transpose('data', (2,0,1)) #改变维度的顺序,由原始图片(28,28,3)变为(3,28,28)
#transformer.set_mean('data', np.load(mean_file).mean(1).mean(1)) #减去均值,前面训练模型时没有减均值,这儿就不用
transformer.set_raw_scale('data', 255) # 缩放到【0,255】之间
im=caffe.io.load_image(img,False)
net.blobs['data'].data[...] = transformer.preprocess('data',im) #执行上面设置的图片预处理操作,并将图片载入到blob中
out = net.forward()
labels = np.loadtxt(labels_filename, str, delimiter='\t') #读取类别名称文件
prob= net.blobs['prob'].data[0].flatten() #取出最后一层(Softmax)属于某个类别的概率值,并打印
print (prob)
order=prob.argsort()[-1] #将概率值排序,取出最大值所在的序号
print ('the class is:',labels[order]) #将该序号转换成对应的类别名称,并打印
















 136
136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











