









[pytorch] Kaggle图片分类比赛 ArcFace + Metric Learning 代码学习
比赛中的数据包含来自 28 个不同研究机构的 30 个不同物种(鲸鱼和海豚)的 15,000 多只独特个体海洋哺乳动物的图像。比赛要求是对测试集个体id的分类。
kaggle 比赛数据详情及数据集下载:Happywhale - Whale and Dolphin Identification
代码链接
arcface是本次比赛中表现最好的方法之一。代码:
基础知识
[理论] 度量学习 Metric Learning
度量学习(Metric Learning)是机器学习过程中经常用到的一种方法,它可以借助一系列观测,构造出对应的度量函数,从而学习数据间的距离或差异,有效地描述样本之间的相似度。这个度量函数对于相似度高的观测值,会返回一个小的距离值;对于差异巨大的观测值,则会返回一个大的距离值。当样本量不大时,度量学习在处理分类任务的准确率和高效率上,展现出了显著优势。
然而,如果要处理的分类任务十分复杂,具有多类别、小样本等特征时,结合深度学习和度量学习的深度度量学习((Deep Metric Learning,简称 DML)),才是真正的王者。深度度量学习又被称为距离度量学习(Distance Metric Learning)。相较于度量学习,深度度量学习可以对输入特征做非线性映射。
通过训练一个基于 CNN 的非线性特征提取模块或编码器,深度度量学习可以将提取的图像特征(Embedding)嵌入到近邻位置,同时借助欧氏距离、cosine 等距离度量方法,将不同的图像特征区分开来。
深度度量学习在 CV 领域的一些极端分类任务(类别众多、样本量不足)中表现优异,应用遍及人脸识别、行人重识别、图像检索、目标跟踪、特征匹配等场景。
参考链接:
- 度量学习和pytorch-metric-learning的使用
- PyTorch 深度度量学习无敌 Buff:九大模块、随意调用
- 度量学习/对比学习入门: 论文阅读笔记-Deep Metric Learning: A Survey
[pytorch] PyTorch Metric Learning
度量学习作为一个大领域,网上有不少介绍的文章,pytorch-metric-learning库可以帮助我们轻松实现度量学习,它的官方文档也有比较详细的说明和demo. 简介度量学习和pytorch-metric-learning的使用
官方 API : PyTorch Metric Learning
在这次的代码中,作者也是大量的调用了PyTorch Metric Learning库中的函数,由于函数封装程度比较高,所以建议大家首先学习这个库的使用,这是理解这次代码的关键。
这里我贴一张自己总结的logging模块和Inference模块的思维导图,这是训练流程的关键。
[理论] bounding box 目标检测
在图像分类任务中,我们假设图像中只有一个主要物体对象,我们只关注如何识别其类别。 然而,很多时候图像里有多个我们感兴趣的目标,我们不仅想知道它们的类别,还想得到它们在图像中的具体位置。 在计算机视觉里,我们将这类任务称为目标检测(object detection)或目标识别(object recognition)。
在目标检测中,我们通常使用边界框(bounding box)来描述对象的空间位置。 边界框是矩形的,由矩形左上角的以及右下角的 x 和 y 坐标决定。 另一种常用的边界框表示方法是边界框中心的 (x,y) 轴坐标以及框的宽度和高度。



参考链接:
1.CNN: bounding box prediction 01 problem
2.CNN: bounding box prediction - specify bounding box
3.CNN: bounding box prediction - YOLO algo
4.CNN: 3.9 YOLO 算法 part1
5.CNN: 3.9 YOLO 算法 part2
[python] logging模块
那么在 Python 中,怎样才能算作一个比较标准的日志记录过程呢?或许很多人会使用 print 语句输出一些运行信息,然后再在控制台观察,运行的时候再将输出重定向到文件输出流保存到文件中,这样其实是非常不规范的,在 Python 中有一个标准的 logging 模块,我们可以使用它来进行标注的日志记录,利用它我们可以更方便地进行日志记录,同时还可以做更方便的级别区分以及一些额外日志信息的记录,如时间、运行模块信息等。
接下来我们先了解一下日志记录流程的整体框架。


参考链接:
[pytorch] 梯度累加(Gradient Accumulation)
受显存限制,运行一些预训练的large模型时,batch-size往往设置的比较小1-4,否则就会‘CUDA out of memory’,但一般batch-size越大(一定范围内)模型收敛越稳定效果相对越好,这时梯度累加(Gradient Accumulation)就可以发挥作用了,梯度累加可以先累加多个batch的梯度再进行一次参数更新,相当于增大了batch-size。
我们以Pytorch为例,一个神经网络的训练过程通常如下:
for i, (inputs, labels) in enumerate(trainloader):
optimizer.zero_grad() # 梯度清零
outputs = net(inputs) # 正向传播
loss = criterion(outputs, labels) # 计算损失
loss.backward() # 反向传播,计算梯度
optimizer.step() # 更新参数
if (i+1) % evaluation_steps == 0:
evaluate_model()
从代码中可以很清楚地看到神经网络是如何做到训练的:
1.将前一个batch计算之后的网络梯度清零
2.正向传播,将数据传入网络,得到预测结果
3.根据预测结果与label,计算损失值
4.利用损失进行反向传播,计算参数梯度
5.利用计算的参数梯度更新网络参数
下面来看梯度累加是如何做的:
for i, (inputs, labels) in enumerate(trainloader):
outputs = net(inputs) # 正向传播
loss = criterion(outputs, labels) # 计算损失函数
loss = loss / accumulation_steps # 损失标准化
loss.backward() # 反向传播,计算梯度
if (i+1) % accumulation_steps == 0:
optimizer.step() # 更新参数
optimizer.zero_grad() # 梯度清零
if (i+1) % evaluation_steps == 0:
evaluate_model()
1.正向传播,将数据传入网络,得到预测结果
2.根据预测结果与label,计算损失值
3.利用损失进行反向传播,计算参数梯度
4.重复1-3,不清空梯度,而是将梯度累加
5.梯度累加达到固定次数之后,更新参数,然后将梯度清零
总结来讲,梯度累加就是每计算一个batch的梯度,不进行清零,而是做梯度的累加,当累加到一定的次数之后,再更新网络参数,然后将梯度清零。
通过这种参数延迟更新的手段,可以实现与采用大batch size相近的效果。在平时的实验过程中,我一般会采用梯度累加技术,大多数情况下,采用梯度累加训练的模型效果,要比采用小batch size训练的模型效果要好很多。
参考: 梯度累加(Gradient Accumulation)
数据预处理
首先,根据我们数据统计的结果:[pytorch] Kaggle大型图像数据集 数据分析+可视化
数据图片的大小差异非常大,其中我们要检测的鲸鱼或海豚的位置也是乱七八糟
Things to know before starting image preprocessing
这里你可以看到一些极端案例
所以,图片处理的第一步就是确定海豚/鲸鱼的在图片中的位置,为此,我们使用了bounding box[YOLOv5].
Happywhale: BoundingBox [YOLOv5]
在这个代码中,我们将使用 YOLOv5 生成边界框。这么做的目的是为之后图像的crop提供方向,从而对大小各异的数据集图片进行裁剪,最终可以达到更好的分类结果.
我们使用 Whale Flute 数据集(另一个Kaggle竞赛数据,鲸鱼尾鳍定位)来训练和测试BoundingBox模型,我们总共有 1200 个带有边界框的样本。之后,我们将使用 Whale Flute 模型对我们的 Whale 和 Dolphin 数据集进行预测。
Whales Fluke 数据集中的边界框很大,而 Whales & Dolphin 数据集既有小边界框也有大边界框。 要调整此问题,您可以尝试更改 hyp.yaml 文件中的 scale 参数。 默认值为 0.5,您可以尝试增加该值。您也可以尝试将 bbox 放大,例如 1.5x 或 1.7x。 这将确保您不会裁剪到鲸鱼或海豚。
在确定好边界框的位置之后,我们继续对图像进行剪裁来得到我们分类所需要的图像
Happywhale: Cropped Dataset [YOLOv5]

最终,在调整大小之后,我们得到新的数据数据集图像。
截至至目前的版本,作者还没有用bounding box处理过后的数据集,我询问了作者,他的回复是目前没有对bounding box后的质量进行评估。实际上,在bounding box处理过后的数据集中,也有许多错误检测的图片(比如说检测到船,岛屿上的物体等),所以,目前作者只使用了大小变换后的数据集。
数据集:JPEG Happywhale 384x384
但是毫无疑问,bounding box是一种不错的数据处理方法,作者也强调,当他有时间了会自己训练bounding box的数据集来i预处理数据。
代码详解
配置
!pip install timm
!pip install pytorch-metric-learning[with-hooks]
开源的度量学习库pytorch-metric-learning,集成了当前常用的各种度量学习方法,是一个非常好用的工具。
import os
import glob
import pandas as pd
import numpy as np
import logging
import timm
from tqdm.notebook import tqdm #进度条
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from torchvision.io import ImageReadMode, read_image
from torchvision.transforms import Compose, Lambda, Normalize, AutoAugment, AutoAugmentPolicy
import pytorch_metric_learning
import pytorch_metric_learning.utils.logging_presets as LP
from pytorch_metric_learning.utils import common_functions
from pytorch_metric_learning import losses, miners, samplers, testers, trainers
from pytorch_metric_learning.utils.accuracy_calculator import AccuracyCalculator
from pytorch_metric_learning.utils.inference import InferenceModel
for handler in logging.root.handlers[:]:
logging.root.removeHandler(handler) # remove exactly the preexisting handler object
logging.getLogger().setLevel(logging.INFO) # 获取logger实例 指定日志的最低输出级别
logging.info("VERSION %s" % pytorch_metric_learning.__version__) # 打印库版本
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device) # cuda:0
print(torch.cuda.get_device_name(0)) # NVIDIA RTX A6000
参数
MODEL_NAME='tf_efficientnet_b4_ns'
N_CLASSES=15587 #个体数
OUTPUT_SIZE = 1792
EMBEDDING_SIZE = 512
N_EPOCH=15
BATCH_SIZE=16
ACCUMULATION_STEPS = int(256 / BATCH_SIZE)
MODEL_LR = 1e-3
PCT_START=0.3
PATIENCE=5
N_WORKER=2
N_NEIGHBOURS = 750
读取csv数据
df = pd.read_csv('./happy-whale-and-dolphin/train.csv')
df.head()

df['label'] = df.groupby('individual_id').ngroup()
df['label'].describe()

实现了根据物种到标签数字的转化

-
df.groupby
groupby的过程就是将原有的DataFrame按照groupby的字段(这里是individual_id),划分为若干个分组DataFrame,被分为多少个组就有多少个分组DataFrame。Pandas教程 | 超好用的Groupby用法详解 -
GroupBy.ngroup(self, ascending:bool = True) return=每个组的唯一编号。

-
数据总结df.describe()
会返回一个有多个行的所有数字列的统计表,每个行是一个统计指标,有总数、平均数、标准差、最大最小值、四分位数等,对我们初步了解数据还是很有作用。 如果是一个时间类型则会按时间相关的如开始结束时间、周期等信息。
划分数据集
训练集和验证集
valid_proportion = 0.05
valid_df = df.sample(frac=valid_proportion, replace=False, random_state=1).copy()
train_df = df[~df['image'].isin(valid_df['image'])].copy()
print(train_df.shape) # (48481, 4)
print(valid_df.shape) # (2552, 4)
Reset index on both since we want to use it for KNN lookups later:
train_df.reset_index(drop=True, inplace=True)
valid_df.reset_index(drop=True, inplace=True)
读取图片数据
创建用于加载图像的dataset类。
class HappyWhaleDataset(Dataset):
def __init__(
self,
df: pd.DataFrame,
image_dir: str,
return_labels=True,
):
self.df = df
self.images = self.df["image"]
self.image_dir = image_dir
self.image_transform = Compose(
[
AutoAugment(AutoAugmentPolicy.IMAGENET),
Lambda(lambda x: x / 255),
]
)
self.return_labels = return_labels
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
image_path = os.path.join(self.image_dir, self.images.iloc[idx])
image = read_image(path=image_path)
image = self.image_transform(image)
if self.return_labels:
label = self.df['label'].iloc[idx] # iloc函数:通过行号来取行数据
return image, label
else:
return image
train_dataset = HappyWhaleDataset(df=train_df, image_dir=TRAIN_DIR, return_labels=True)
len(train_dataset)#48481
valid_dataset = HappyWhaleDataset(df=valid_df, image_dir=TRAIN_DIR, return_labels=True)
len(valid_dataset)#2552
dataset_dict = {"train": train_dataset, "val": valid_dataset}
看一下训练集

建立模型
首先,根据PyTorch Metric Learning库中的方法,要实现度量学习有两种结构,一种是Trunk+Embedder,这种情况下Trunk常常为resnet等经典网络删除最后的分类层,Embedder可以将分类器的输出改成Embedder的数量,也就是说模型只是将特征投影到Embeding空间,当我们做预测时需要根据测试集和投影空间中点的距离来作出预测。第二种结构是,Trunk+Embedder+Classifier,自带分类器的结构比较符合我们平时训练的习惯,官方api有相应的例子代码。
在这个代码中,我们使用第一种结构。
首先我们需要建立起Trunk和Embedder的结构,相应的,也需要分别设置他们的optimizer和学习率衰减schedule。
# Setup the trunk using a pre-trained model from timm:
trunk = timm.create_model(MODEL_NAME, pretrained=True)
trunk.classifier = common_functions.Identity() # 删除分类层
trunk = trunk.to(device)
trunk_optimizer = optim.SGD(trunk.parameters(), lr=MODEL_LR, momentum=0.9)
trunk_schedule = optim.lr_scheduler.OneCycleLR(
trunk_optimizer,
max_lr=MODEL_LR,
total_steps = N_EPOCH * int(len(train_dataset)/BATCH_SIZE),
pct_start = PCT_START
)
#Add our embedder. This is just a linear layer that will create the embeddings for KNN:
embedder = nn.Linear(OUTPUT_SIZE, EMBEDDING_SIZE).to(device)
embedder_optimizer = optim.SGD(trunk.parameters(), lr=MODEL_LR, momentum=0.9)
embedder_schedule = optim.lr_scheduler.OneCycleLR(
embedder_optimizer,
max_lr=MODEL_LR,
total_steps = N_EPOCH * int(len(train_dataset)/BATCH_SIZE),
pct_start = PCT_START
)
为了实现我们的 ArcFace 方法,我们需要设置loss.
loss_func = losses.ArcFaceLoss(num_classes=N_CLASSES, embedding_size=EMBEDDING_SIZE).to(device)
loss_optimizer = optim.SGD(trunk.parameters(), lr=MODEL_LR, momentum=0.9)
loss_schedule = optim.lr_scheduler.OneCycleLR(
loss_optimizer,
max_lr=MODEL_LR,
total_steps = N_EPOCH * int(len(train_dataset)/BATCH_SIZE),
pct_start = PCT_START
)
设置Logging模块
这一块的代码大量使用了PyTorch Metric Learning库中的函数,建立先看看我理论部分的思维导图对应着代码理解。使用Logging模块取代了传统的训练过程。
Setup some hooks for validation, logging and model saving at the end of the epoch:
创建hook
record_keeper, _, _ = LP.get_record_keeper(LOG_DIR)
hooks = LP.get_hook_container(record_keeper, primary_metric='mean_average_precision')
创建tester
tester = testers.GlobalEmbeddingSpaceTester(
end_of_testing_hook=hooks.end_of_testing_hook,
accuracy_calculator=AccuracyCalculator(
include=['mean_average_precision'],
device=torch.device("cpu"),
k=5),
dataloader_num_workers=N_WORKER,
batch_size=BATCH_SIZE
)
end_of_epoch_hook
end_of_epoch_hook = hooks.end_of_epoch_hook(
tester,
dataset_dict,
MODEL_DIR,
test_interval=1,
patience=PATIENCE,
splits_to_eval = [('val', ['train'])]
)
trainer设置
class HappyTrainer(trainers.MetricLossOnly):
def __init__(self, *args, accumulation_steps=10, **kwargs):
super().__init__(*args, **kwargs)
self.accumulation_steps = accumulation_steps
def forward_and_backward(self):
self.zero_losses()
self.update_loss_weights()
self.calculate_loss(self.get_batch())
self.loss_tracker.update(self.loss_weights)
self.backward()
self.clip_gradients()
if ((self.iteration + 1) % self.accumulation_steps == 0) or ((self.iteration + 1) == np.ceil(len(self.dataset) / self.batch_size)):
self.step_optimizers()
self.zero_grad()
def calculate_loss(self, curr_batch):
data, labels = curr_batch
with torch.cuda.amp.autocast(): #自动混合精度包
embeddings = self.compute_embeddings(data)
indices_tuple = self.maybe_mine_embeddings(embeddings, labels)
self.losses["metric_loss"] = self.maybe_get_metric_loss(
embeddings, labels, indices_tuple
)
作者这里继承MetricLossOnly自己写了个类来计算gradient accumulation.
开始训练
trainer.train(num_epochs=N_EPOCH)
训练过程
INFO:PML:Evaluating epoch 1
INFO:PML:Getting embeddings for the train split
100%|██████████| 6061/6061 [05:59<00:00, 16.88it/s]
INFO:PML:Getting embeddings for the val split
100%|██████████| 319/319 [00:19<00:00, 16.59it/s]
INFO:PML:Computing accuracy for the val split w.r.t ['train']
INFO:PML:running k-nn with k=5
INFO:PML:embedding dimensionality is 512
INFO:PML:New best accuracy! 0.07240102325083039
INFO:PML:TRAINING EPOCH 2
total_loss=40.83454: 100%|██████████| 6060/6060 [20:27<00:00, 4.94it/s]
INFO:PML:Evaluating epoch 2
INFO:PML:Getting embeddings for the train split
100%|██████████| 6061/6061 [05:58<00:00, 16.92it/s]
INFO:PML:Getting embeddings for the val split
100%|██████████| 319/319 [00:19<00:00, 16.67it/s]
INFO:PML:Computing accuracy for the val split w.r.t ['train']
INFO:PML:running k-nn with k=5
INFO:PML:embedding dimensionality is 512
INFO:PML:New best accuracy! 0.13497803492981894
INFO:PML:TRAINING EPOCH 3
total_loss=40.78382: 100%|██████████| 6060/6060 [20:26<00:00, 4.94it/s]
INFO:PML:Evaluating epoch 3
INFO:PML:Getting embeddings for the train split
100%|██████████| 6061/6061 [06:00<00:00, 16.80it/s]
INFO:PML:Getting embeddings for the val split
100%|██████████| 319/319 [00:19<00:00, 16.50it/s]
INFO:PML:Computing accuracy for the val split w.r.t ['train']
INFO:PML:running k-nn with k=5
INFO:PML:embedding dimensionality is 512
INFO:PML:New best accuracy! 0.17711614700525016
INFO:PML:TRAINING EPOCH 4
total_loss=44.27713: 100%|██████████| 6060/6060 [20:26<00:00, 4.94it/s]
INFO:PML:Evaluating epoch 4
INFO:PML:Getting embeddings for the train split
100%|██████████| 6061/6061 [05:59<00:00, 16.84it/s]
INFO:PML:Getting embeddings for the val split
100%|██████████| 319/319 [00:19<00:00, 16.50it/s]
INFO:PML:Computing accuracy for the val split w.r.t ['train']
INFO:PML:running k-nn with k=5
INFO:PML:embedding dimensionality is 512
INFO:PML:New best accuracy! 0.19266580949319617
INFO:PML:TRAINING EPOCH 5
total_loss=36.24231: 100%|██████████| 6060/6060 [20:32<00:00, 4.92it/s]
INFO:PML:Evaluating epoch 5
INFO:PML:Getting embeddings for the train split
100%|██████████| 6061/6061 [06:02<00:00, 16.72it/s]
INFO:PML:Getting embeddings for the val split
100%|██████████| 319/319 [00:19<00:00, 16.42it/s]
INFO:PML:Computing accuracy for the val split w.r.t ['train']
INFO:PML:running k-nn with k=5
INFO:PML:embedding dimensionality is 512
INFO:PML:New best accuracy! 0.1933502089360334
INFO:PML:TRAINING EPOCH 6
total_loss=34.66808: 100%|██████████| 6060/6060 [20:28<00:00, 4.93it/s]
INFO:PML:Evaluating epoch 6
INFO:PML:Getting embeddings for the train split
100%|██████████| 6061/6061 [06:00<00:00, 16.80it/s]
INFO:PML:Getting embeddings for the val split
100%|██████████| 319/319 [00:19<00:00, 16.36it/s]
INFO:PML:Computing accuracy for the val split w.r.t ['train']
INFO:PML:running k-nn with k=5
INFO:PML:embedding dimensionality is 512
INFO:PML:New best accuracy! 0.22929256402014356
INFO:PML:TRAINING EPOCH 7
total_loss=28.18377: 100%|██████████| 6060/6060 [20:25<00:00, 4.95it/s]
INFO:PML:Evaluating epoch 7
INFO:PML:Getting embeddings for the train split
100%|██████████| 6061/6061 [05:56<00:00, 17.01it/s]
INFO:PML:Getting embeddings for the val split
100%|██████████| 319/319 [00:19<00:00, 16.63it/s]
INFO:PML:Computing accuracy for the val split w.r.t ['train']
INFO:PML:running k-nn with k=5
INFO:PML:embedding dimensionality is 512
INFO:PML:New best accuracy! 0.2441323797278474
INFO:PML:TRAINING EPOCH 8
total_loss=30.59254: 100%|██████████| 6060/6060 [20:25<00:00, 4.94it/s]
INFO:PML:Evaluating epoch 8
INFO:PML:Getting embeddings for the train split
100%|██████████| 6061/6061 [06:00<00:00, 16.82it/s]
INFO:PML:Getting embeddings for the val split
100%|██████████| 319/319 [00:19<00:00, 16.44it/s]
INFO:PML:Computing accuracy for the val split w.r.t ['train']
INFO:PML:running k-nn with k=5
INFO:PML:embedding dimensionality is 512
INFO:PML:New best accuracy! 0.28265094289081755
INFO:PML:TRAINING EPOCH 9
total_loss=35.66448: 100%|██████████| 6060/6060 [20:25<00:00, 4.94it/s]
INFO:PML:Evaluating epoch 9
INFO:PML:Getting embeddings for the train split
100%|██████████| 6061/6061 [05:59<00:00, 16.87it/s]
INFO:PML:Getting embeddings for the val split
100%|██████████| 319/319 [00:19<00:00, 16.54it/s]
INFO:PML:Computing accuracy for the val split w.r.t ['train']
INFO:PML:running k-nn with k=5
INFO:PML:embedding dimensionality is 512
INFO:PML:New best accuracy! 0.32403233151183974
INFO:PML:TRAINING EPOCH 10
total_loss=28.28654: 100%|██████████| 6060/6060 [20:37<00:00, 4.90it/s]
INFO:PML:Evaluating epoch 10
INFO:PML:Getting embeddings for the train split
100%|██████████| 6061/6061 [05:59<00:00, 16.85it/s]
INFO:PML:Getting embeddings for the val split
100%|██████████| 319/319 [00:19<00:00, 16.50it/s]
INFO:PML:Computing accuracy for the val split w.r.t ['train']
INFO:PML:running k-nn with k=5
INFO:PML:embedding dimensionality is 512
INFO:PML:New best accuracy! 0.3344724365155899
保存的模型

Inference Models 预测
验证集
因为测试集数据中有new_individual的存在,所以我们根据验证集查询图像和参考图像之间的适当距离选取合适的阈值,这个阈值可以帮助我们找出new_individual。这一段用到了Inference Models 模块的函数,参数见思维导图.
首先加载训练好的模型,trunk和embedder.
best_trunk_weights = glob.glob('./models/{}/trunk_best*.pth'.format(MODEL_NAME))[0]
trunk.load_state_dict(torch.load(best_trunk_weights))
best_embedder_weights = glob.glob('./models/{}/embedder_best*.pth'.format(MODEL_NAME))[0]
embedder.load_state_dict(torch.load(best_embedder_weights))
inference_model = InferenceModel(
trunk=trunk,
embedder=embedder,
normalize_embeddings=True,
)
我们将训练集作为knn的搜索空间。
# pass in a dataset to serve as the search space for k-nn
inference_model.train_knn(train_dataset)
valid_dataloader = DataLoader(valid_dataset, batch_size=BATCH_SIZE, shuffle=False, num_workers=N_WORKER, pin_memory=True)
valid_labels_list = []
valid_distance_list = []
valid_indices_list = []
for images, labels in tqdm(valid_dataloader):
distances, indices = inference_model.get_nearest_neighbors(images, k=N_NEIGHBOURS)
# get the k nearest neighbors of a query
valid_labels_list.append(labels)
valid_distance_list.append(distances)
valid_indices_list.append(indices)
valid_labels = torch.cat(valid_labels_list, dim=0).cpu().numpy()
valid_distances = torch.cat(valid_distance_list, dim=0).cpu().numpy()
valid_indices = torch.cat(valid_indices_list, dim=0).cpu().numpy()

We have the indices of the nearest neighbours in our training set, so setup the lookups to return the individual_id:
new_whale_idx = -1
train_labels = train_df['individual_id'].unique()
train_idx_lookup = train_df['individual_id'].copy().to_dict()
train_idx_lookup[-1] = 'new_individual'
valid_class_lookup = valid_df.set_index('label')['individual_id'].copy().to_dict()




Loop through a range of thresholds and find which maximises our MAP@5:
thresholds = [np.quantile(valid_distances, q=q) for q in np.arange(0, 1.0, 0.01)]

计算距离列表中第0.1, 0.2. 0.3… 1的值,作为我们阈值的测试
results = []
for threshold in tqdm(thresholds):
prediction_list = []
running_map=0
for i in range(len(valid_distances)):
pred_knn_idx = valid_indices[i, :].copy()
insert_idx = np.where(valid_distances[i, :] > threshold)
if insert_idx[0].size != 0:
pred_knn_idx = np.insert(pred_knn_idx, np.min(insert_idx[0]), new_whale_idx)
predicted_label_list = []
for predicted_idx in pred_knn_idx:
predicted_label = train_idx_lookup[predicted_idx]
if len(predicted_label_list) == 5:
break
if (predicted_label == 'new_individual') | (predicted_label not in predicted_label_list):
predicted_label_list.append(predicted_label)
gt = valid_class_lookup[valid_labels[i]]
if gt not in train_labels:
gt = "new_individual"
precision_vals = []
for j in range(5):
if predicted_label_list[j] == gt:
precision_vals.append(1/(j+1))
else:
precision_vals.append(0)
running_map += np.max(precision_vals)
results.append([threshold, running_map / len(valid_distances)])
results_df = pd.DataFrame(results, columns=['threshold','map5'])
对于验证集中的每个点,我们找了训练集中与其相近的750个点,这些点的距离保存在valid_distances中,对应的训练集中的索引保存在valid_indices中:
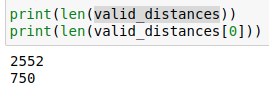

实际上,get_nearest_neighbors函数返回的数据是由最接近的点距离逐渐增加,所以我们可以看到这里一旦某个点超过了阈值,则之后的点一定也大于阈值。所以我们找出距离等于阈值的点np.min(insert_idx[0]),在这个点之后加入新个体索引new_whale_idx.

因为比赛要求的是产生五个预测结果,所以,根据距离的远近,我们选择训练集中最近的五个点的label作为我们预测的结果。
我们使用for循环,一个个的加,当出现相同的label时跳过(比如说第一个和第二点的label相同),直到我们产生五个不同的结果。
预测完了结果,我们对比一下和真实的标签相比,预测的表现。这里使用precision_vals,如果真实标签在预测结果中,则记为1, 否则记0。 之后我们记录下每个阈值的表现情况。
results_df = results_df.sort_values(by='map5', ascending=False).reset_index(drop=True)
results_df.head(5)
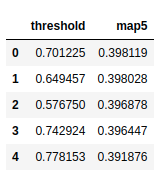
按map列的值,使用sort_values从大到小排列。
然后我们选择表现最好的第一行的阈值作为我们划分新个体的标准
threshold = results_df.loc[0, 'threshold']
threshold # 0.701225185394287
测试集预测
为了最终的测试集,我们将训练集与验证集结合起来,使用全部的数据来建立我们的搜索空间。
combined_df = pd.concat([train_df, valid_df], axis=0).reset_index(drop=True)
combined_dataset = HappyWhaleDataset(df=combined_df, image_dir=TRAIN_DIR, return_labels=True)
len(combined_dataset) # 51033
Re-train the KNN model on this:
inference_model.train_knn(combined_dataset)
test_df = pd.read_csv('./happy-whale-and-dolphin/sample_submission.csv')
test_dataset = HappyWhaleDataset(df=test_df, image_dir=TEST_DIR, return_labels=False)
len(test_dataset) # 27956
test_dataloader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False, num_workers=N_WORKER, pin_memory=True)
接下来和之前验证集的预测过程一样
test_distance_list = []
test_indices_list = []
for images in tqdm(test_dataloader):
distances, indices = inference_model.get_nearest_neighbors(images, k=N_NEIGHBOURS)
test_distance_list.append(distances)
test_indices_list.append(indices)
test_distances = torch.cat(test_distance_list, dim=0).cpu().numpy()
test_indices = torch.cat(test_indices_list, dim=0).cpu().numpy()
combined_idx_lookup = combined_df['individual_id'].copy().to_dict()
combined_idx_lookup[-1] = 'new_individual'
results = []
prediction_list = []
for i in range(len(test_distances)):
pred_knn_idx = test_indices[i, :].copy()
insert_idx = np.where(test_distances[i, :] > threshold)
if insert_idx[0].size != 0:
pred_knn_idx = np.insert(pred_knn_idx, np.min(insert_idx[0]), new_whale_idx)
predicted_label_list = []
for predicted_idx in pred_knn_idx:
predicted_label = combined_idx_lookup[predicted_idx]
if len(predicted_label_list) == 5:
break
if (predicted_label == 'new_individual') | (predicted_label not in predicted_label_list):
predicted_label_list.append(predicted_label)
prediction_list.append(predicted_label_list)
prediction_df = pd.DataFrame(prediction_list)
prediction_df.head()
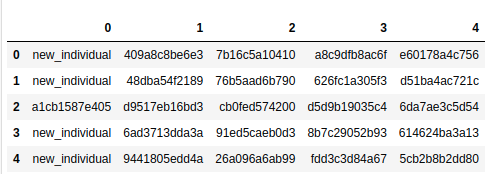
最后将输出转换为比赛要求的格式
prediction_df['predictions'] = prediction_df[0].astype(str) + ' ' + prediction_df[1].astype(str) + ' ' + prediction_df[2 ].astype(str) + ' ' + prediction_df[3].astype(str) + ' ' + prediction_df[4].astype(str)
prediction_df.head()
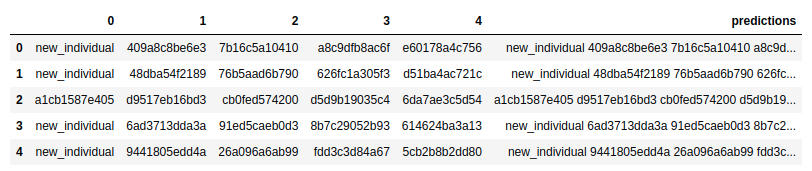
submission = pd.read_csv('./happy-whale-and-dolphin/sample_submission.csv')
submission['predictions'] = prediction_df['predictions']
submission.to_csv('submission.csv', index=False)
结果

目前的结果一般,但只训练了10个epoch,还有上升空间。此数据集的预处理也是一个可以优化的点。















 1091
1091











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









