







[pytorch] Distributed Data-Parallel Training
Intro
PYTORCH DISTRIBUTED OVERVIEW
Distributed Data-Parallel Training (DDP) is a widely adopted single-program multiple-data training paradigm. With DDP, the model is replicated on every process, and every model replica will be fed with a different set of input data samples. DDP takes care of gradient communication to keep model replicas synchronized and overlaps it with the gradient computations to speed up training.
PyTorch provides several options for data-parallel training. For applications that gradually grow from simple to complex and from prototype to production, the common development trajectory would be:
- Use single-device training if the data and model can fit in one GPU, and training speed is not a concern.
- Use single-machine multi-GPU DataParallel to make use of multiple GPUs on a single machine to speed up training with minimal code changes.
- Use single-machine multi-GPU DistributedDataParallel, if you would like to further speed up training and are willing to write a little more code to set it up.
- Use multi-machine DistributedDataParallel, if the application needs to scale across machine boundaries.
cluster
- GPU
Actuellement, pour notre cluster, il y a 6 nœuds au total (ns[3182447,3185995,3186000-3186002,31374487]), et chaque liste de nœuds contient 4 GPU.
Si un GPU est utilisé sur un nœud, la formation distribuée (utilisant 4 GPU en même temps) sur ce nœud sera bloquée.
Nous espérons juste que lors de l’exécution des tâches, nous pourrons spécifier #SBATCH --nodelist, afin d’éviter que les tâches soient affectées à différents nœuds, affectant ainsi l’utilisation de la formation distribuée sur d’autres nœuds.
ex: il y a 2 GPU libre sur ns3185995, pour les utiliser, nous devons écrire en .sh
#SBATCH --gres=gpu:2
#SBATCH --nodelist=ns3185995
- CPU
for each node, 32 cores 64 threads
import psutil
print(psutil.cpu_count(False)) # 32
import multiprocessing
print('nomber t = ',multiprocessing.cpu_count()) # 64
One tasks on one node, #SBATCH -c max 60
4 tasks on one node, #SBATCH -c 16 + 16 +16 +10
3 tasks on one node, #SBATCH -c 20+20+20
2 tesks on one node, #SBATCH -c 30 + 30
torch.nn.DataParallel
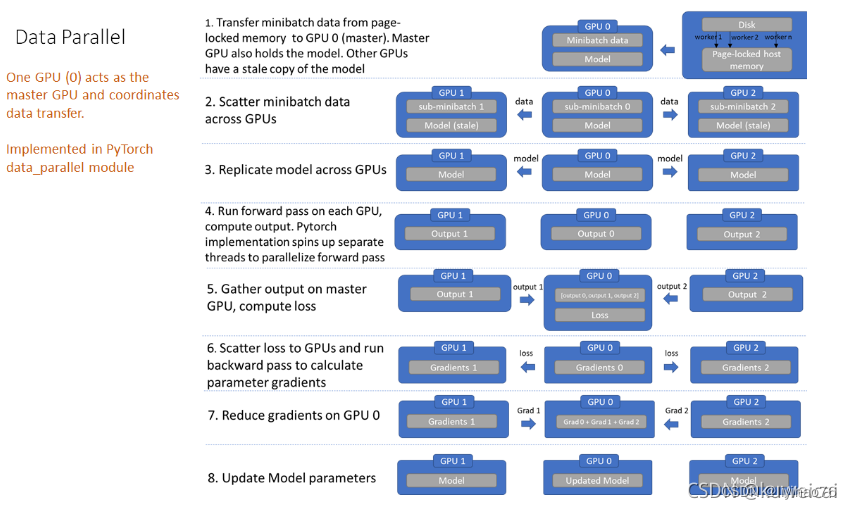
OPTIONAL: DATA PARALLELISM
The DataParallel package enables single-machine multi-GPU parallelism with the lowest coding hurdle. It only requires a one-line change to the application code. Although DataParallel is very easy to use, it usually does not offer the best performance because it replicates the model in every forward pass, and its single-process multi-thread parallelism naturally suffers from GIL contention. To get better performance, consider using DistributedDataParallel.
It’s natural to execute your forward, backward propagations on multiple GPUs. However, Pytorch will only use one GPU by default. You can easily run your operations on multiple GPUs by making your model run parallelly using DataParallel:
model = model.cuda()
model = nn.DataParallel(model)
Although DataParallel is easier to use (simply wrap a single GPU model), since a process is used to compute model weights, which are then distributed to each GPU during each batch, communication quickly becomes a bottleneck and GPU utilization Usually very low. Also, nn.DataParallel requires all GPUs to be on the same node.
Prerequisite for DistributedDataParallel
Principle
The process of DistributedDataParallel is different from that of DataParallel, only the derivative is propagated between subprocesses.
Taking 2 gpus as an example, GPU0 takes the derivative of the data allocated to itself, and then passes the derivative of the batch of data to GPU1; GPU1 takes the derivative of the data allocated to itself, and then passes the derivative of the batch of data to GPU0.
Therefore, each GPU has the complete derivative of the batch data, and then each GPU performs a gradient descent. Because the parameters and gradients and the optimizer are consistent, the parameters after each GPU update independently are still consistent.
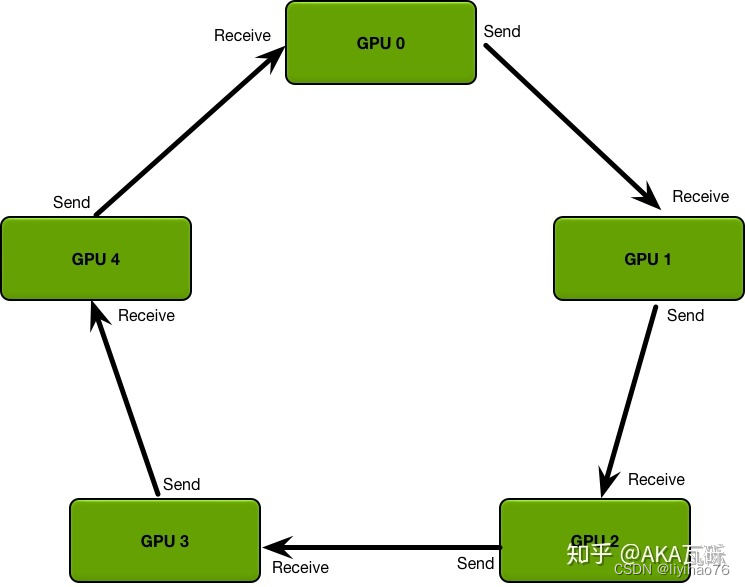
Scatter Reduce process: First, we divide the parameters into N parts, and adjacent GPUs pass different parameters. After passing N-1 times, the accumulation of each parameter (on different GPUs) can be obtained.

All Gather: After getting the accumulation of each parameter, make another pass and synchronize to all GPUs.

Backends
DISTRIBUTED COMMUNICATION PACKAGE - TORCH.DISTRIBUTED
torch.distributed supports three built-in backends, each with different capabilities. The table below shows which functions are available for use with CPU / CUDA tensors. MPI supports CUDA only if the implementation used to build PyTorch supports it.
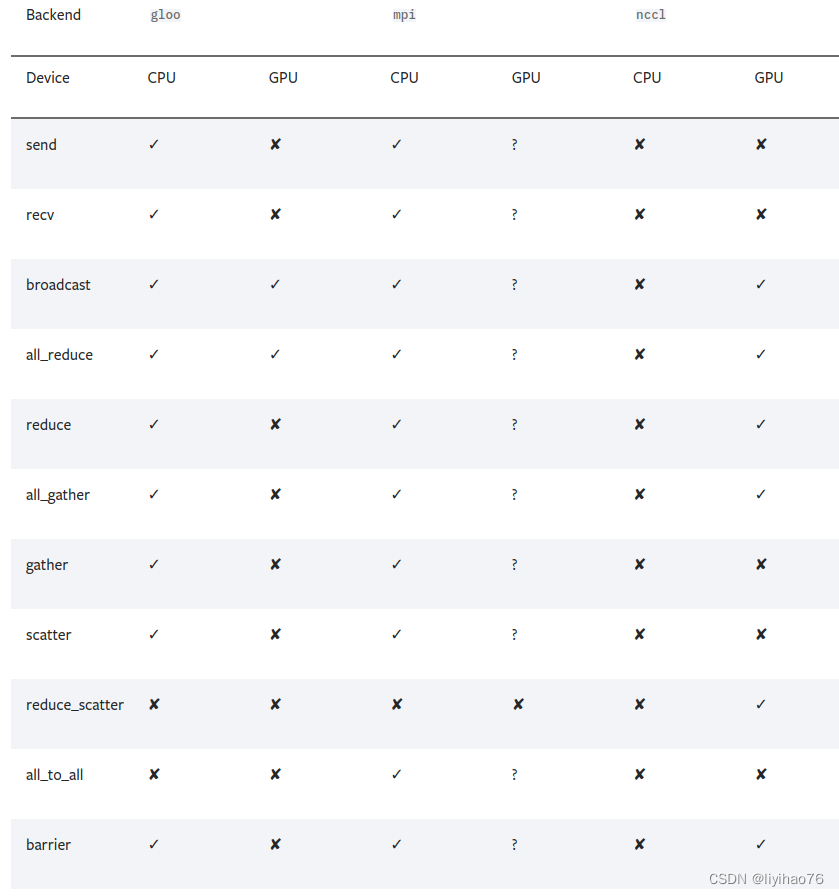
- Use the NCCL backend for distributed GPU training
- Use the Gloo backend for distributed CPU training.
NVIDIA NCCL
The NVIDIA Collective Communication Library (NCCL) implements multi-GPU and multi-node communication primitives optimized for NVIDIA GPUs and Networking. NCCL provides routines such as all-gather, all-reduce, broadcast, reduce, reduce-scatter as well as point-to-point send and receive that are optimized to achieve high bandwidth and low latency over PCIe and NVLink high-speed interconnects within a node and over NVIDIA Mellanox Network across nodes.
Leading deep learning frameworks such as Caffe2, Chainer, MxNet, PyTorch and TensorFlow have integrated NCCL to accelerate deep learning training on multi-GPU multi-node systems.
NCCL is available for download as part of the NVIDIA HPC SDK and as a separate package for Ubuntu and Red Hat.
Installing NCCL on Ubuntu
Note: torch.cuda.nccl.version() can look up version information , os.environ["NCCL_DEBUG"]="INFO" can look up error messages
Initialize the process group (dist.init_process_group)
The first and most complicated thing you need to deal with is process initialization.
There are as many in-sync copies of the train script as GPUs in the cluster, each gpu runs in a different process.
DDP relies on c10d ProcessGroup for communications. Hence, applications must create ProcessGroup instances before constructing DDP.
# multi_init.py
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import os
def init_process(rank, size, backend='gloo'):
""" Initialize the distributed environment. """
dist.init_process_group(backend,init_method= 'tcp://127.0.0.1:23456', rank=rank, world_size=size)
def train(rank, num_epochs, world_size):
init_process(rank, world_size)
print(
f"Rank {rank + 1}/{world_size} process initialized.\n"
)
# rest of the training script goes here!
if __name__=="__main__":
WORLD_SIZE = torch.cuda.device_count()
NUM_EPOCHS = 5
mp.spawn(
train, args=(NUM_EPOCHS, WORLD_SIZE),
nprocs=torch.cuda.device_count(), join=True
)
mp.spawn spawns 4 different processes, each with a level of 0, 1, 2 or 3. The rank 0 process is given some additional responsibilities and is therefore called the master process.
Let’s have a look at the init_process function. It ensures that every process will be able to coordinate through a master, using the same ip address and port. Note that we used the gloo backend but other backends are available.
The package needs to be initialized using the torch.distributed.init_process_group() function before calling any other methods. This blocks until all processes have joined.
torch.distributed.init_process_group(backend, init_method=None, timeout=datetime.timedelta(seconds=1800), world_size=- 1, rank=- 1, store=None, group_name='', pg_options=None)
- backend (str or Backend) – The backend to use. Depending on build-time configurations, valid values include mpi, gloo, and nccl.
- init_method (str, optional) – URL specifying how to initialize the process group.
- world_size (int, optional) – Number of processes participating in the job. / Number of GPUs.
- rank (int, optional) – Rank of the current process (it should be a number between 0 and world_size-1)./ global rank.
Currently three initialization methods are supported:
- TCP initialization
Initialize using TCP, requiring a network address reachable from all processes and a desired world_size. It requires specifying an address that belongs to the rank 0 process.
import torch.distributed as dist
# Use address of one of the machines
dist.init_process_group(backend, init_method='tcp://10.1.1.20:23456',
rank=args.rank, world_size=4)
host_name (str) – The hostname or IP Address the server store should run on.
port (int) – The port on which the server store should listen for incoming requests.
If we use Multiple nodes, We should choose ip according to the address of the cluster node, for exemple rank = ns3186000, then init_method='tcp://135.125.87.167:23500'. We can choose an unused port.
If we use Single node, ip and port can choose at will.
- Shared file-system initialization
Another initialization method makes use of a file system that is shared and visible from all machines in a group, along with a desired world_size. The URL should start with file:// and contain a path to a non-existent file (in an existing directory) on a shared file system. File-system initialization will automatically create that file if it doesn’t exist, but will not delete the file. Therefore, it is your responsibility to make sure that the file is cleaned up before the next init_process_group() call on the same file path/name.
import torch.distributed as dist
# rank should always be specified
dist.init_process_group(backend, init_method='file:///mnt/nfs/sharedfile',
world_size=4, rank=args.rank)
Our nodes share the /home path, so we can specify a non-existing file on a path we have write access to, for exemple file:///home/yihao/sharedfile.
-
Environment variable initialization
This method will read the configuration from environment variables, allowing one to fully customize how the information is obtained. The variables to be set are:MASTER_PORT - required; has to be a free port on machine with rank 0
MASTER_ADDR - required (except for rank 0); address of rank 0 node
WORLD_SIZE - required; can be set either here, or in a call to init function
RANK - required; can be set either here, or in a call to init function
import torch.distributed as dist
""" Initialize the distributed environment. """
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group(backend, rank=rank, world_size=size)
torch.nn.parallel.DistributedDataParallel
Now that we understand the initialization process, we can start to complete the body of the train method.
def train(rank, num_epochs, world_size):
init_process(rank, world_size)
print(
f"{rank + 1}/{world_size} process initialized.\n"
)
# rest of the training script goes here!
Each of our four training processes runs this function until completion, then exits when done. If we run this code now (via python multi_init.py) we will see something like this on the console:
$ python multi_init.py
1/4 process initialized.
3/4 process initialized.
2/4 process initialized.
4/4 process initialized.
These processes run independently, and there is no guarantee what state will be at any point in the training loop. So some modifications to the training process are required here.
Please note, as DDP broadcasts model states from rank 0 process to all other processes in the DDP constructor, you don’t need to worry about different DDP processes start from different model parameter initial values.
- Downloads of any data should be isolated to the main process.
Otherwise, the data download process will be replicated across all processes, causing four processes to write to the same file at the same time, which is the cause of data corruption.
# import torch.distributed as dist
if rank == 0:
downloading_dataset()
downloading_model_weights()
dist.barrier()
print(
f"Rank {rank + 1}/{world_size} training process passed data download barrier.\n"
)
The dist.barrier in this code sample will block the call until the main process (rank == 0) downloading_dataset and downloading_model_weights is done. This isolates all network I/O into one process and prevents other processes from moving on.
- The data loader needs to use DistributedSampler.
>>> sampler = DistributedSampler(dataset) if is_distributed else None
>>> loader = DataLoader(dataset, shuffle=(sampler is None),
... sampler=sampler)
>>> for epoch in range(start_epoch, n_epochs):
... if is_distributed:
... sampler.set_epoch(epoch)
... train(loader)
- Load tensors in the correct device.
To do this, parameterize the .cuda() call with the local rank of the device the process is managing:
torch.cuda.set_device(args.local_rank)
device = torch.device("cuda", args.local_rank)
model = model.cuda(args.local_rank)
image = image.cuda(args.local_rank)
label = label.cuda(args.local_rank)
- Any method of file I/O should be isolated in the main process.
if rank == 0:
filepath = args.weights_dir
folder = os.path.exists(filepath)
if not folder:
# 判断是否存在文件夹如果不存在则创建为文件夹
os.makedirs(filepath)
path = './weights/model' + str(epoch) + '.pth'
# torch.save(model.state_dict(), path)
torch.save(model.module.state_dict(), path) # multi gpu
- Wrap the model in DistributedDataParallel.
model = DistributedDataParallel(model)
Code comparison
No Distributed Data-Parallel : 1 device 1 GPU
#SBATCH --gres=gpu
#SBATCH --nodelist=ns3185995
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, input_x):
x = self.pool(F.relu(self.conv1(input_x)))
x = self.pool(F.relu(self.conv2(x)))
x = torch.flatten(x, 1) # flatten all dimensions except batch
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
output_x = self.fc3(x)
print("\tIn Model: input size", input_x.size(),
"output size", output_x.size())
return output_x
if __name__=="__main__":
print('nccl version')
print(torch.cuda.nccl.version())
print('pytorch version')
print(torch.__version__)
print('cuda', torch.cuda.is_available())
print('gpu number', torch.cuda.device_count())
for i in range(torch.cuda.device_count()):
print(torch.cuda.get_device_name(i))
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
batch_size = 64
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size,
shuffle=False, num_workers=2)
net = Net()
net = net.cuda()
print('Start Training')
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for epoch in range(2): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
inputs = inputs.cuda()
labels = labels.cuda()
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 200 == 0: # print every 2000 mini-batches
print(f'[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 2000:.3f}')
print('Finished Training')
PATH = './cifar_net.pth'
torch.save(net.state_dict(), PATH)
nccl version
(2, 12, 9)
pytorch version
1.12.0a0+2c916ef
cuda True
gpu number 1
Tesla V100S-PCIE-32GB
Files already downloaded and verified
Files already downloaded and verified
Start Training
In Model: input size torch.Size([64, 3, 32, 32]) output size torch.Size([64, 10])
[1, 1] loss: 0.001
In Model: input size torch.Size([64, 3, 32, 32]) output size torch.Size([64, 10])
In Model: input size torch.Size([64, 3, 32, 32]) output size torch.Size([64, 10])
In Model: input size torch.Size([64, 3, 32, 32]) output size torch.Size([64, 10])
In Model: input size torch.Size([64, 3, 32, 32]) output size torch.Size([64, 10])
In Model: input size torch.Size([64, 3, 32, 32]) output size torch.Size([64, 10])
In Model: input size torch.Size([64, 3, 32, 32]) output size torch.Size([64, 10])
In Model: input size torch.Size([64, 3, 32, 32]) output size torch.Size([64, 10])
In Model: input size torch.Size([64, 3, 32, 32]) output size torch.Size([64, 10])
In Model: input size torch.Size([64, 3, 32, 32]) output size torch.Size([64, 10])
In Model: input size torch.Size([64, 3, 32, 32]) output size torch.Size([64, 10])
In Model: input size torch.Size([64, 3, 32, 32]) output size torch.Size([64, 10])
In Model: input size torch.Size([64, 3, 32, 32]) output size torch.Size([64, 10])
In Model: input size torch.Size([64, 3, 32, 32]) output size torch.Size([64, 10])
In Model: input size torch.Size([16, 3, 32, 32]) output size torch.Size([16, 10])
Finished Training
torch.nn.DataParallel : 1 device 2 GPU
#SBATCH --gres=gpu:2
#SBATCH --nodelist=ns3185995
net = Net()
net = net.cuda()
net = nn.DataParallel(net)
filepath = './weights/model'
folder = os.path.exists(filepath)
if not folder:
# 判断是否存在文件夹如果不存在则创建为文件夹
os.makedirs(filepath)
path = './weights/model' + str(epoch) + '.pth'
# torch.save(model.state_dict(), path)
torch.save(model.module.state_dict(), path) # multi gpu
nccl version
(2, 12, 9)
pytorch version
1.12.0a0+2c916ef
cuda True
gpu number 2
Tesla V100S-PCIE-32GB
Tesla V100S-PCIE-32GB
Files already downloaded and verified
Files already downloaded and verified
Start Training
In Model: input size torch.Size([32, 3, 32, 32]) output size torch.Size([32, 10])
In Model: input size torch.Size([32, 3, 32, 32]) output size torch.Size([32, 10])
[1, 1] loss: 0.001
In Model: input size torch.Size([32, 3, 32, 32]) output size torch.Size([32, 10])
In Model: input size torch.Size([32, 3, 32, 32]) output size torch.Size([32, 10])
In Model: input size torch.Size([32, 3, 32, 32]) output size torch.Size([32, 10])
In Model: input size torch.Size([32, 3, 32, 32]) output size torch.Size([32, 10])
In Model: input size torch.Size([32, 3, 32, 32]) output size torch.Size([32, 10])
In Model: input size torch.Size([32, 3, 32, 32]) output size torch.Size([32, 10])
In Model: input size torch.Size([32, 3, 32, 32]) output size torch.Size([32, 10])
In Model: input size torch.Size([32, 3, 32, 32]) output size torch.Size([32, 10])
In Model: input size torch.Size([32, 3, 32, 32]) output size torch.Size([32, 10])
.......
In Model: input size torch.Size([8, 3, 32, 32]) output size torch.Size([8, 10])
In Model: input size torch.Size([8, 3, 32, 32]) output size torch.Size([8, 10])
Finished Training
torch.nn.parallel.DistributedDataParallel
2 methods:
- Each process occupies a GPU card (recommend)
- Each process occupies multiple gpu cards
Each process occupies a GPU card (recommend)
- The rank in dist.init_process_group needs to be calculated according to the number of nodes and GPUs
- The size of world_size = number of nodes x number of GPUs
- The device_ids in ddp need to specify the corresponding graphics card.
import argparse
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import random
import numpy as np
import os
import torch.nn.parallel
import torch.backends.cudnn as cudnn
import torch.distributed as dist
import torch.optim
from torch.optim.lr_scheduler import StepLR
import torch.multiprocessing as mp
import torch.utils.data
import torch.utils.data.distributed
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torchvision.models as models
parser = argparse.ArgumentParser(description='PyTorch Example')
parser.add_argument('--init-method', type=str, default='tcp://127.0.0.1:23456')
parser.add_argument('--rank', type=int)
parser.add_argument('--world-size',type=int)
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, input_x):
x = self.pool(F.relu(self.conv1(input_x)))
x = self.pool(F.relu(self.conv2(x)))
x = torch.flatten(x, 1) # flatten all dimensions except batch
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
output_x = self.fc3(x)
#print("\tIn Model: input size", input_x.size(),
# "output size", output_x.size())
return output_x
def main():
random.seed(76)
torch.manual_seed(76)
cudnn.deterministic = True
torch.backends.cudnn.deterministic = True
np.random.seed(76)
args = parser.parse_args()
ngpus_per_node = torch.cuda.device_count()
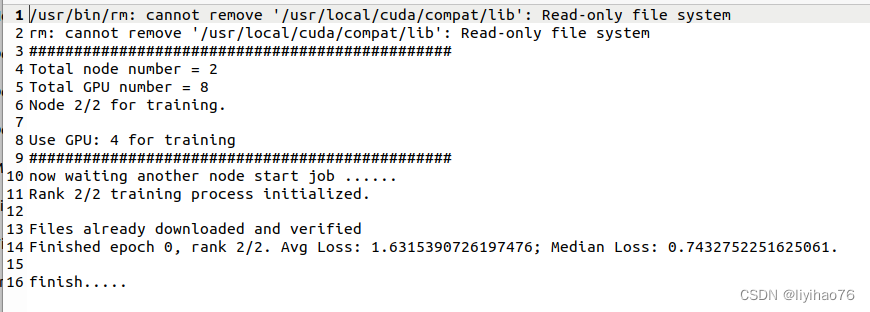
print('###############################################')
print('Total node number =', (args.world_size))
print('Total GPU number =', (ngpus_per_node * args.world_size))
print(f"Node {args.rank + 1}/{args.world_size} for training.\n")
print("Use GPU: {} for training".format(torch.cuda.device_count()))
print('###############################################')
if not args.world_size == 1:
print('now waiting another node start job ......')
mp.spawn(main_worker, nprocs=ngpus_per_node, args=(ngpus_per_node, args))
def main_worker(gpu, ngpus_per_node, args):
world_size = ngpus_per_node * args.world_size
rank = args.rank * ngpus_per_node + gpu
# rank : global rank
# gpu : local rank
dist.init_process_group(init_method=args.init_method,backend="nccl",world_size=world_size,rank=rank,group_name="pytorch_test")
print(f"Rank {rank+1}/{world_size} training process initialized.\n")
# For multiprocessing distributed, DistributedDataParallel constructor
# should always set the single device scope, otherwise,
# DistributedDataParallel will use all available devices.
torch.cuda.set_device(gpu)
model = Net()
model.cuda(gpu)
# When using a single GPU per process and per
# DistributedDataParallel, we need to divide the batch size
# ourselves based on the total number of GPUs of the current node.
batch_size = 64
batch_size = int(batch_size / ngpus_per_node)
model = torch.nn.parallel.DistributedDataParallel(model,device_ids=[gpu], output_device=gpu)
# define loss function (criterion), optimizer, and learning rate scheduler
criterion = nn.CrossEntropyLoss().cuda(gpu)
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# Data loading code
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
if rank == 0:
torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
dist.barrier()
train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size, shuffle=(train_sampler is None),
num_workers=0, sampler=train_sampler)
num_epochs = 10
for epoch in range(num_epochs):
train_sampler.set_epoch(epoch)
# switch to train mode
model.train()
running_loss = []
for i, (images, target) in enumerate(train_loader):
images = images.cuda(gpu)
target = target.cuda(gpu)
output = model(images)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss.append(loss.item())
if rank == 0:
if not os.path.exists('./checkpoints/'):
os.mkdir('./checkpoints/')
torch.save(
model.state_dict(),
'./checkpoints/model_{epoch}.pth'
)
print(
f'Finished epoch {epoch}, rank {rank+1}/{world_size}. '
f'Avg Loss: {np.mean(running_loss)}; Median Loss: {np.min(running_loss)}.\n'
)
dist.barrier()
if __name__=="__main__":
main()
print('finish.....')
Single node, multiple GPUs
#SBATCH -J LIYIHAO
#SBATCH --output=cataract_RL_%j.out
#SBATCH --gres=gpu:4
#SBATCH --nodelist=ns3186001
srun singularity exec --bind /home/shared:/home/shared --nv /home/yihao/2022/docker/monai_new.simg python3 test.py --init-method tcp://127.0.0.1:23500 --rank 0 --world-size 1

Multiple nodes
world-size : Total node number
global rank : which node
local rank : var gpu in code
init-method : Two initialization methods
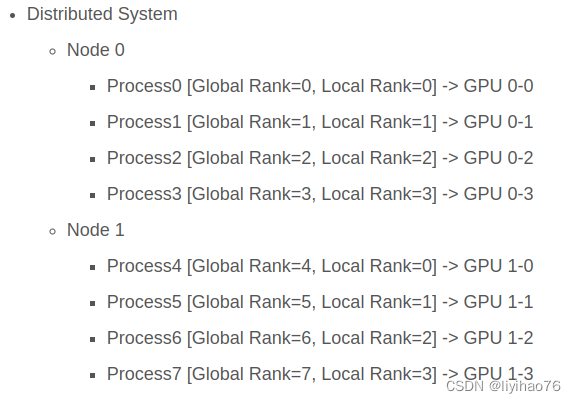
There are two initialization methods,we can choose one.
1. by file : file:///home/yihao/sharedfile # Manually delete this file after each execution
2. by tcp : tcp://tcp://IP_OF_NODE0:FREEPORT ex :tcp://135.125.87.167:23500
We need to start the test on a different node.
There is no requirement for the execution order of the different node tests,if another task has not started, it will show now waiting another node start job .......
- for node0 :
#!/bin/bash
#SBATCH -J LIYIHAO
#SBATCH --output=cataract_RL_%j.out
#SBATCH --gres=gpu:4
#SBATCH --nodelist=ns3186001
srun singularity exec --bind /home/shared:/home/shared --nv /home/yihao/2022/docker/monai_new.simg python3 test0.py --init-method file:///home/yihao/sharedfile --rank 0 --world-size 2
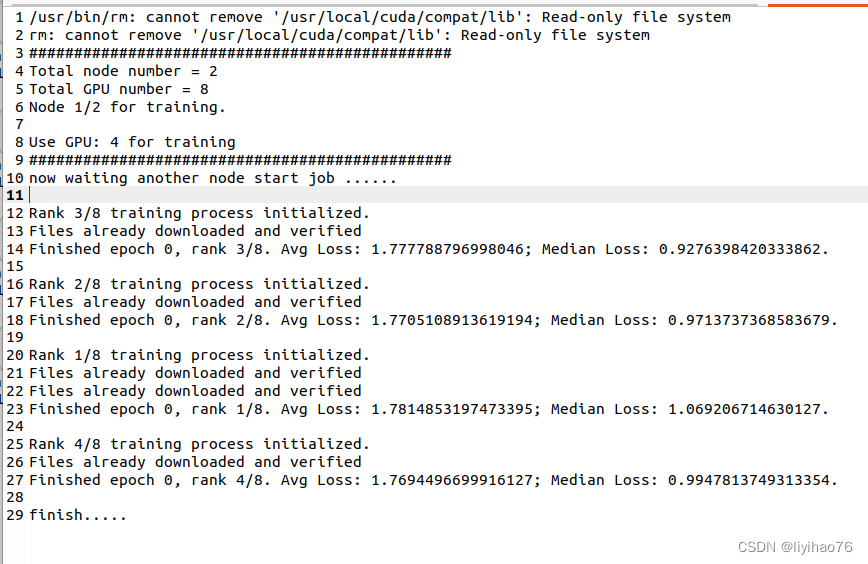
- for node1:
#!/bin/bash
#SBATCH -J LIYIHAO
#SBATCH --output=cataract_RL_%j.out
#SBATCH --gres=gpu:4
#SBATCH --nodelist=ns3186002
srun singularity exec --bind /home/shared:/home/shared --nv /home/yihao/2022/docker/monai_new.simg python3 test0.py --init-method file:///home/yihao/sharedfile --rank 1 --world-size 2
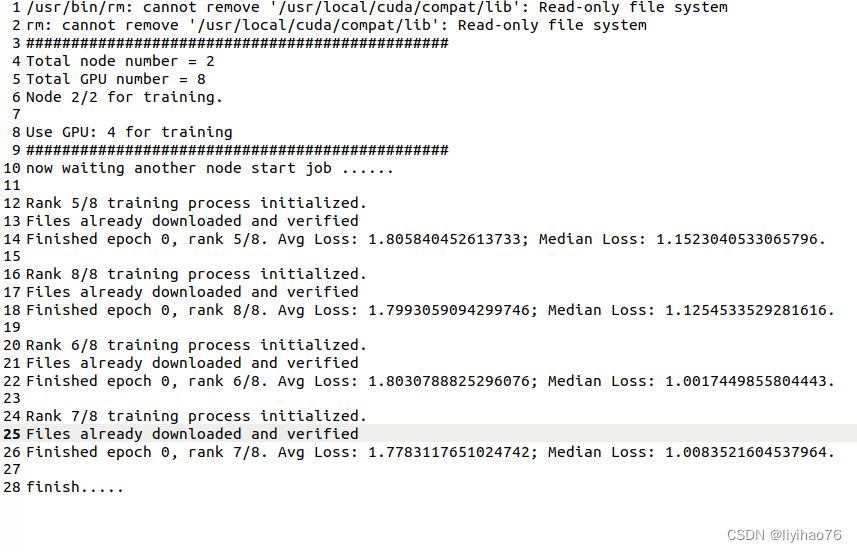
Each process occupies multiple gpu cards
- The rank in dist.init_process_group is equal to the node number;
- world_size is equal to the total number of nodes;
- DDP does not need to specify device.
import argparse
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import random
import numpy as np
import os
import torch.nn.parallel
import torch.backends.cudnn as cudnn
import torch.distributed as dist
import torch.optim
from torch.optim.lr_scheduler import StepLR
import torch.multiprocessing as mp
import torch.utils.data
import torch.utils.data.distributed
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torchvision.models as models
parser = argparse.ArgumentParser(description='PyTorch Example')
parser.add_argument('--init-method', type=str, default='tcp://127.0.0.1:23456')
parser.add_argument('--rank', type=int)
parser.add_argument('--world-size',type=int)
def main():
random.seed(76)
torch.manual_seed(76)
cudnn.deterministic = True
torch.backends.cudnn.deterministic = True
np.random.seed(76)
args = parser.parse_args()
ngpus_per_node = torch.cuda.device_count()
print('###############################################')
print('Total node number =', (args.world_size))
print('Total GPU number =', (ngpus_per_node * args.world_size))
print(f"Node {args.rank+1}/{args.world_size} for training.\n")
print("Use GPU: {} for training".format(torch.cuda.device_count()))
print('###############################################')
if not args.world_size == 1:
print('now waiting another node start job ......')
main_worker(args.rank,ngpus_per_node,args)
def main_worker(gpu, ngpus_per_node, args):
world_size = args.world_size
rank = args.rank
dist.init_process_group(init_method=args.init_method,backend="nccl",world_size=world_size,rank=rank,group_name="pytorch_test")
print(f"Rank {rank + 1}/{world_size} training process initialized.\n")
# For multiprocessing distributed, DistributedDataParallel constructor
# should always set the single device scope, otherwise,
# DistributedDataParallel will use all available devices.
#torch.cuda.set_device(gpu)
model = models.resnet18()
# 修改全连接层的输出
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, 10)
model.cuda()
# When using a single GPU per process and per
# DistributedDataParallel, we need to divide the batch size
# ourselves based on the total number of GPUs of the current node.
batch_size = 64
batch_size = int(batch_size / ngpus_per_node)
model = torch.nn.parallel.DistributedDataParallel(model)
# define loss function (criterion), optimizer, and learning rate scheduler
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# Data loading code
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
if rank == 0:
torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
dist.barrier()
train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size, shuffle=(train_sampler is None),
num_workers=0, sampler=train_sampler)
#print('before train is ok')
num_epochs = 1
for epoch in range(num_epochs):
train_sampler.set_epoch(epoch)
# switch to train mode
model.train()
running_loss = []
for i, (images, target) in enumerate(train_loader):
images = images.cuda()
target = target.cuda()
output = model(images)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss.append(loss.item())
print(
f'Finished epoch {epoch}, rank {rank + 1}/{world_size}. '
f'Avg Loss: {np.mean(running_loss)}; Median Loss: {np.min(running_loss)}.\n'
)
if __name__=="__main__":
main()
print('finish.....')
Single node, multiple GPUs
#!/bin/bash
#SBATCH -J LIYIHAO
#SBATCH --output=cataract_RL_%j.out
#SBATCH --gres=gpu:4
#SBATCH --nodelist=ns3186001
srun singularity exec --bind /home/shared:/home/shared --nv /home/yihao/2022/docker/monai_new.simg python3 test1.py --init-method tcp://127.0.0.1:23500 --rank 0 --world-size 1
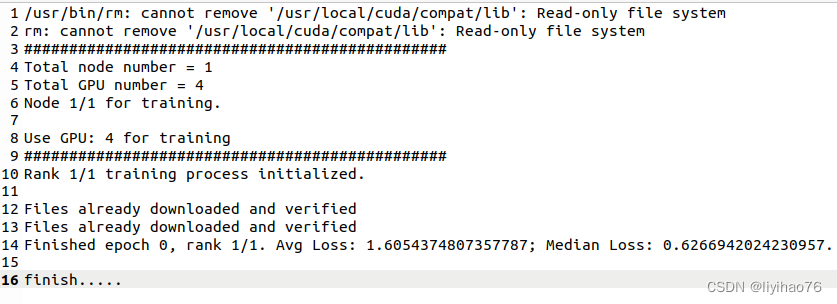
Multiple nodes
- node0 :
#!/bin/bash
#SBATCH -J LIYIHAO
#SBATCH --output=cataract_RL_%j.out
#SBATCH --gres=gpu:4
#SBATCH --nodelist=ns3186001
srun singularity exec --bind /home/shared:/home/shared --nv /home/yihao/2022/docker/monai_new.simg python3 test1.py --init-method file:///home/yihao/sharedfile33 --rank 0 --world-size 2
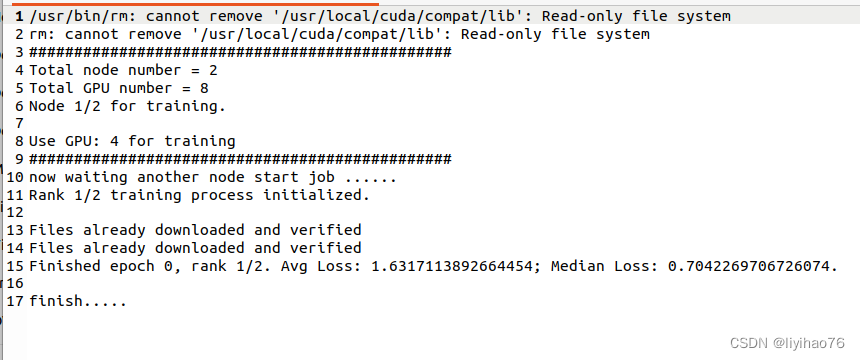
- node1 :
#!/bin/bash
#SBATCH -J LIYIHAO
#SBATCH --output=cataract_RL_%j.out
#SBATCH --gres=gpu:4
#SBATCH --nodelist=ns3186002
srun singularity exec --bind /home/shared:/home/shared --nv /home/yihao/2022/docker/monai_new.simg python3 test1.py --init-method file:///home/yihao/sharedfile33 --rank 1 --world-size 2
Performance comparison
cifar10
| No DP | DP | DDP (1 node) | DDP (2 node) | |
|---|---|---|---|---|
| GPU | 1 | 4 | 4 | 8 |
| CPU | 1 | 1 | 1 | 1 |
| batch_size | 64 | 64*4 | 64*4 | 64*8 |
| loss- 0 epoch | 2.285884 | 2.304621 | 2.306401 | 2.304969 |
| loss- 24 epoch | 0.963238 | 1.521069 | 1.445795 | |
| loss- 49 epoch | 0.644783 | 1.226753 | 1.176290 | |
| time (50epochs) | 576.94s | 555.67s | 1438.51s | more than 3000s |
OCT-A
| TEST1 | TEST2 | TEST3 | DP | DDP | |
|---|---|---|---|---|---|
| GPU | 1 | 1 | 1 | 4 | 4 |
| CPU | 1 | 8 | 12 | 1 | 1 |
| batch_size | 4 | 4 | 4 | 12 | 12 |
| loss- 0 epoch | 0.611296 | 0.675859 | 0.611652 | 0.600055 | 0.725467 |
| loss- 9 epoch | 0.549468 | 0.543123 | 0.569846 | 0.544406 | 0.523935 |
| time (10 epochs) | 55248.91s | 44117.22s | 43300.80s | 17612.83s | 20745.87s |
| TEST4 | TEST5 | DP | DDP | |
|---|---|---|---|---|
| GPU | 1 | 1 | 4 | 4 |
| SBATCH -c | 58 | 30 | 56 | 60 |
| num_worker | 50 | 28 | 12 | 14 |
| batch_size | 4 | 4 | 12 | 12 |
| loss- 0 epoch | 0.650601 | 0.623308 | 0.620667 | 0.719268 |
| loss- 9 epoch | 0.504250 | 0.546000 | 0.545852 | 0.514747 |
| time (10 epochs) | 2666.15s | 4547.34s | 3185.96s | 1696.70s |
| DDP | TEST1 | TEST2 | TEST3 | TEST4 | TEST5 | TEST6 | TEST7 |
|---|---|---|---|---|---|---|---|
| GPU | 4 | 2 | 4 | 4 | 4 | 4 | 4 |
| - C | 60 | 60 | 60 | 60 | 60 | 60 | 60 |
| num_worker | 14 | 28 | 8 | 12 | 20 | 32 | 54 |
| time (10 epochs) | 1696s | 2201s | 2297s | 1582s | 1850s | 3014s | 3112s |
Conclusion
Grâce à l’exploration du cluster OVH, nous avons réussi à réduire considérablement le temps nécessaire à la formation. Le temps de formation pour 10 époques est réduit de 55000s à environ 1700s (plus de 30 fois).
La meilleure configuration actuelle est #SBATCH -c 60 + DistributedDataParallel (4 GPU). Elle tire pleinement parti de presque toutes les ressources CPU et GPU d’un nœud.
Je pense qu’il y a deux goulots d’étranglement dans le temps de formation, l’un est le traitement des données (lecture et augmentation), et l’autre est la formation en réseau.
Parmi eux, l’augmentation du nombre de cpu/thread (= augmentation de la limite supérieure de num_worker) peut réduire considérablement le temps de traitement des données, tandis que la formation distribuée peut accélérer le temps de formation du réseau.
Ref
问题: pytorch 多机多卡卡住问题汇总
问题: PyTorch 训练时中遇到的卡住停住等问题
启动方式 : PyTorch分布式训练基础–DDP使用
单机多卡代码: 在PyTorch中使用DistributedDataParallel进行多GPU分布式模型训练
示例项目代码: ImageNet training in PyTorch
代码例子: PyTorch: Multi-GPU and multi-node data parallelism
代码示例: Distributed data parallel training using Pytorch on the multiple nodes of CSC and Narvi clusters
讲解: Pytorch 分布式训练
DDP原理: 【分布式训练】单机多卡的正确打开方式(一):理论基础
注意事项: pytorch 分布式多卡训练DistributedDataParallel 踩坑记















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









