






UNet 由Ronneberger等人于2015年提出,专门针对医学图像分割任务,解决了早期卷积网络在小样本数据下的效率问题和细节丢失难题。
一 核心创新
1.1对称编码器-解码器结构
实现上下文信息与高分辨率细节的双向融合
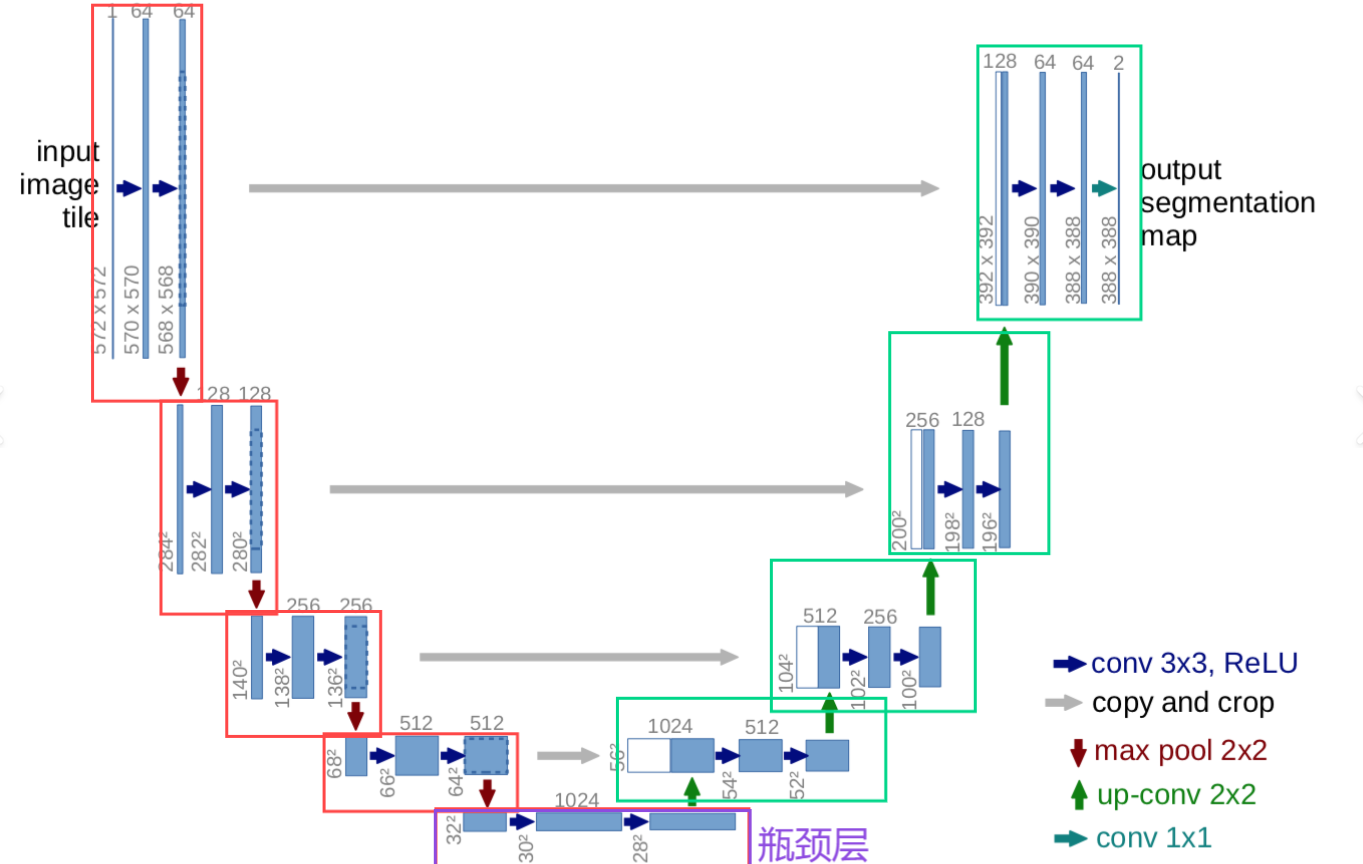
如图所示:编码器进行了4步(红框)到达了瓶颈层(紫框),每一步包含两次3x3卷积+ReLU并通过通过2x2最大池化下采样,到达瓶颈层后,解码器也进行了4步(绿框),使用了转置卷积上采样后与编码器对应层特征拼接(跳跃连接(灰色箭头))后再进行两次卷积。
可以看出解码器和编码器非常的对称,呈现一个U型,所以叫UNet。
其中:
编码器:通过池化逐渐扩大感受野。
解码器:逐步恢复空间分辨率,精确定位目标边界。
跳跃连接:将编码器特征与解码器特征拼接,融合多级信息解决深层网络定位精度下降的问题
1.2跳跃连接(Skip Connections)
解决深层卷积神经网络中空间信息丢失和细节模糊的核心问题。
因为编码器下采样会丢失细节,而解码器上采样又难以完全恢复位置信息,所以使用跳跃链接来补偿细节。
1.2.1数学形式表达
设编码器第 层输出为
, 解码器第
层输入为
, 则跳跃连接操作:
转置卷积/双线性插值将解码器输出的分辨率提升至与编码器相同
1.2.2特征融合方法
编码器每层的输出须与解码器对应层上采样后的尺寸匹配,拼接后总通道数为两者之和。
(黑色圆圈)

# PyTorch代码示例:拼接编码器和解码器特征
def forward(self, decoder_feat, encoder_feat):
# decoder_feat: [B, C1, H, W]
# encoder_feat: [B, C2, H, W]
merged = torch.cat([decoder_feat, encoder_feat], dim=1) # 沿通道拼接
return merged # 结果维度:[B, C1+C2, H, W]
1.3端到端精细分割(End-to-End Fine Segmentation)
在少量标注数据下仍能输出像素级预测
直接从原始输入图像生成像素级预测的模型设计范式,无需手动设计特征提取器或多阶段后处理。
1.3.1核心
全流程自动映射:输入 → 特征学习 → 高精度分割结果,中间过程由网络自动优化
细节敏感机制:通过多层次特征融合、边界增强模块等手段保证细粒度分割
无后处理输出:输出可直接使用,无需形态学后处理
1.3.2技术实现
编码器:通过卷积与池化逐层提取高层语义(形状、位置)
# 编码器层示例:每次下采样通道数翻倍
class Encoder(nn.Module):
def __init__(self, in_ch, out_ch):
super().__init__()
self.block = nn.Sequential(
nn.Conv2d(in_ch, out_ch, 3, padding=1),#卷积
nn.BatchNorm2d(out_ch),#标准化(归一+线性变换)
nn.ReLU(),#非线性激活
nn.Conv2d(out_ch, out_ch, 3, padding=1),
nn.BatchNorm2d(out_ch),
nn.ReLU(),
nn.MaxPool2d(2)#最大值池化
)
def forward(self, x):
return self.block(x)
解码器:上采样恢复分辨率 + 跳跃连接补充细节
# 解码器层示例:特征拼接后卷积
class Decoder(nn.Module):
def __init__(self, in_ch, out_ch):
super().__init__()
self.up = nn.ConvTranspose2d(in_ch, out_ch, 2, stride=2)
self.conv = nn.Sequential(
nn.Conv2d(out_ch*2, out_ch, 3, padding=1), # 拼接后通道数翻倍
nn.BatchNorm2d(out_ch),
nn.ReLU()
)
def forward(self, x, skip):
x = self.up(x)
x = torch.cat([x, skip], dim=1) # 与编码器特征拼接
return self.conv(x)
改良1: 注意力引导跳跃连接:通过空间注意力强化边缘区域(在跳跃连接前应用空间注意力,突出边缘信息)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super().__init__()
self.conv = nn.Conv2d(2, 1, kernel_size, padding=kernel_size//2)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg = torch.mean(x, dim=1, keepdim=True)
max_pool, _ = torch.max(x, dim=1, keepdim=True)
concat = torch.cat([avg, max_pool], dim=1) # 沿通道维度拼接均值和最大值
mask = self.sigmoid(self.conv(concat)) # 生成空间注意力掩码
return x * mask # 加权增强关键区域
改良2: 多尺度损失监督:在不同解码层注入辅助损失。
class MultiScaleLoss(nn.Module):
def __init__(self, losses):
super().__init__()
self.losses = losses # 各层对应的损失函数列表
def forward(self, preds, target):
total_loss = 0
for pred, loss_fn in zip(preds, self.losses):
# 将目标下采样至与当前预测同尺寸
_, _, H, W = pred.shape
resized_target = F.interpolate(target, size=(H,W), mode='nearest')
total_loss += loss_fn(pred, resized_target)
return total_loss
适用性扩展:该范式可迁移至其他密集预测任务,如卫星影像分析、自动驾驶场景理解等。
二 与传统分割模型对比
| 模型 | 优势 | 局限性 |
|---|---|---|
| FCN | 全卷积保留空间信息 | 输出分辨率粗糙,跳跃连接简单 |
| SegNet | 使用池化索引提升精度 | 特征复用效率低 |
| DeepLab | 空洞卷积扩大感受野 | 小目标分割边缘模糊 |
| UNet | 对称结构+密集跳跃连接,细节恢复 | 原版对大尺度变化敏感 |
三 UNet的改良方法
3.1跨尺度空洞卷积替换编码器的普通卷积层
在底层使用扩张率=1捕捉细节,高层使用d=3或5扩大感受野。
# 原编码器卷积块
self.encoder_conv = nn.Sequential(
nn.Conv2d(in_ch, out_ch, 3, padding=1),
nn.ReLU(),
nn.Conv2d(out_ch, out_ch, 3, padding=1),
nn.ReLU()
)
# 改进:跨尺度空洞卷积模块
self.encoder_conv = CrossScaleDilatedConv(in_ch, out_ch)
3.2融入密集块融合增强跳跃连接的特征传递
在编码器和解码器拼接前加入密集块
class ImprovedSkipConnection(nn.Module):
def __init__(self, in_ch):
super().__init__()
self.dense_block = DenseBlock(num_layers=4, in_channels=in_ch)
def forward(self, enc_feat, dec_feat):
enc_processed = self.dense_block(enc_feat) # 特征增强
merged = torch.cat([enc_processed, dec_feat], dim=1)
return merged
# 在UNet解码器中应用
def forward(self, x):
# ... 编码过程
d4 = self.upconv4(d5)
d4 = self.skip_conn4(e4, d4) # 使用改进的跳跃连接
d4 = self.decoder_conv4(d4)
# ...
四 核心代码(未改良)
class UNet(nn.Module):
def __init__(self, n_class=1):
super().__init__()
# 编码器
self.enc1 = EncoderBlock(3, 64)
self.enc2 = EncoderBlock(64, 128)
self.enc3 = EncoderBlock(128, 256)
self.enc4 = EncoderBlock(256, 512)
self.bottleneck = EncoderBlock(512, 1024)
# 解码器
self.upconv4 = UpConv(1024, 512)
self.dec4 = DecoderBlock(1024, 512) # 输入1024因拼接
self.upconv3 = UpConv(512, 256)
self.dec3 = DecoderBlock(512, 256)
self.upconv2 = UpConv(256, 128)
self.dec2 = DecoderBlock(256, 128)
self.upconv1 = UpConv(128, 64)
self.dec1 = DecoderBlock(128, 64)
self.final = nn.Conv2d(64, n_class, kernel_size=1)
def forward(self, x):
# 编码
e1 = self.enc1(x)
e2 = self.enc2(F.max_pool2d(e1, 2))
e3 = self.enc3(F.max_pool2d(e2, 2))
e4 = self.enc4(F.max_pool2d(e3, 2))
bn = self.bottleneck(F.max_pool2d(e4, 2))
# 解码
d4 = self.dec4(self.upconv4(bn), e4)
d3 = self.dec3(self.upconv3(d4), e3)
d2 = self.dec2(self.upconv2(d3), e2)
d1 = self.dec1(self.upconv1(d2), e1)
return torch.sigmoid(self.final(d1))
class EncoderBlock(nn.Module):
def __init__(self, in_ch, out_ch):
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_ch, out_ch, 3, padding=1),
nn.BatchNorm2d(out_ch),
nn.ReLU(),
nn.Conv2d(out_ch, out_ch, 3, padding=1),
nn.BatchNorm2d(out_ch),
nn.ReLU()
)
def forward(self, x):
return self.conv(x)
class UpConv(nn.Module):
def __init__(self, in_ch, out_ch):
super().__init__()
self.up = nn.ConvTranspose2d(in_ch, out_ch, 2, stride=2)
def forward(self, x):
return self.up(x)
class DecoderBlock(nn.Module):
def __init__(self, in_ch, out_ch):
super().__init__()
self.conv = EncoderBlock(in_ch, out_ch)
def forward(self, x, skip):
x = torch.cat([x, skip], dim=1) # 通道拼接
return self.conv(x)
UNet凭借其优雅的对称结构和密集跳跃连接,成为医学图像分割的基准模型。通过集成跨尺度空洞卷积与密集块融合等模块,可显著提升其对多尺度目标的适应性。

















 1602
1602

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









