







1. 简述梯度提升树(GBDT)原理
- Decision Tree:CART回归树
GBDT使用的决策树是CART回归树,无论是处理回归问题还是二分类以及多分类,GBDT使用的决策树都是CART回归树。为什么不用CART分类树呢?因为GBDT每轮的训练是在上一轮的训练的残差基础之上进行训练的。这里的残差就是当前模型的负梯度值 。这个要求每轮迭代的时候,弱分类器的输出的结果相减是有意义的。残差相减是有意义的。如果选用的弱分类器是分类树,类别相减是没有意义的。
对于回归树算法来说最重要的是寻找最佳的划分点,那么回归树中的可划分点包含了所有特征的所有可取的值。在分类树中最佳划分点的判别标准是熵或者基尼系数,都是用纯度来衡量的,但是在回归树中的样本标签是连续数值,所以再使用熵之类的指标不再合适,取而代之的是平方误差,它能很好的评判拟合程度。

- Gradient Boosting
Boosting是一种模型的组合方式,我们熟悉的AdaBoost就是一种Boosting的组合方式。和随机森林并行训练不同的决策树最后组合所有树的bagging方式不同,Boosting是一种递进的组合方式,每一个新的分类器都在前一个分类器的预测结果上改进,所以说boosting是减少bias而bagging是减少variance的模型组合方式。
GBDT和AdaBoost模型都可以表示成:
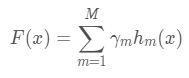
AdaBoost在训练完一个hm后会重新赋值样本的权重:分类错误的样本的权重会增大而分类正确的样本的权重则会减小。这样在训练hm+1 时会侧重对错误样本的训练,以达到模型性能的提升,但是AdaBoost模型每个基分类器的损失函数优化目标是相同的且独立的,都是最优化当前样本(样本权重)的指数损失。
GBDT虽然也是一个加法模型,但其是通过不断迭代拟合样本真实值与当前分类器的残差 来逼近真实值的,按照这个思路,第m 个基分类器的预测结果为:
![]()
而hm(x)的优化目标就是最小化损失函数,即当前预测结果和yi之间的差距。
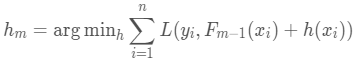
当损失函数是平方损失和指数损失函数时,梯度提升树每一步优化是很简单的,但是对于一般损失函数而言,往往每一步优化起来不那么容易,针对这一问题,Friedman提出了梯度提升树算法,这是利用最速下降的近似方法,其关键是利用损失函数的负梯度作为提升树算法中的残差的近似值。第 t 轮的第 i 个样本的损失函数的负梯度为:
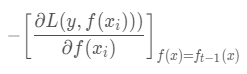
GBDT的负梯度就是残差,所以说对于回归问题,我们要拟合的就是残差。
- GBDT算法原理
流程如下:
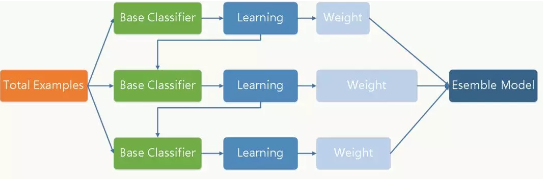
GBDT通过多轮迭代,每轮迭代产生一个弱分类器,每个分类器在上一轮分类器的残差基础上进行训练。对弱分类器的要求一般是足够简单,并且是低方差和高偏差的。因为训练的过程是通过降低偏差来不断提高最终分类器的精度。
弱分类器一般会选择为CART回归树。由于上述高偏差和简单的要求,每个分类回归树的深度不会很深。

2. GBDT常用损失函数有哪些?
- 分类算法的损失函数:
- 指数损失函数
- 对数损失函数:
二元分类的对数函数
多元分类的对数函数
- 回归算法的损失函数:
- 均方损失函数
- 绝对值损失函数
- Huber损失函数
- 分位数损失函数
3. GBDT如何用于分类?

4. 为什么GBDT不适合使用高维稀疏特征

5. GBDT算法的优缺点?


附加题
1. 目标检测如何有效解决常见的前景少背景多的问题
(1)Focal Loss:https://www.cnblogs.com/king-lps/p/9497836.html
(2)为了保证正负样本尽量平衡,SSD采用了hard negative mining,就是对负样本进行抽样,抽样时按照置信度误差(预测背景的置信度越小,误差越大)进行降序排列,选取误差的较大的top-k作为训练的负样本,以保证正负样本比例接近1:3。
(3)采用two stage的方式,用RPN先筛一遍。
2. CNN中1*1的卷积有什么用
- 1×1卷积层在实现全卷积神经网络中经常用到,即使用1*1的卷积层替换到全连接层,这样可以不限制输入图片大小的尺寸,使网络更灵活;
- 进行卷积核通道数的降维,减少卷积核参数数量;
- 可以Inception模块来进行计算校验
- 进行卷积核通道数的升维,用最少的参数拓宽网络的channal;
- 实现跨通道的交互和信息整合;
例子:使用1*1卷积核,实现降维和升维的操作其实就是channel间信息的线性组合变化,3*3,64channels的卷积核后面添加一个1*1,28channels的卷积核,就变成了3*3,28channels的卷积核,原来的64个channels就可以理解为跨通道线性组合变成了28channels,这就是通道间的信息交互。
6. 增加非线性特性
1*1卷积核,可以在保持feature map尺度不变的(即不损失分辨率)的前提下大幅增加非线性特性(利用后接的非线性激活函数),把网络做的很deep。
















 1950
1950











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











