






原文地址:
https://arxiv.org/pdf/1610.02357.pdf
时间:
出现于inception v4之后。
论文目标:
进一步提高网络性能(目标并非压缩网络)(在不增加网络复杂度的情况下)。
论文的主要工作:
受启发与inception模块,也可以说是对inception v3的一种改进,主要是采用depthwise separable convolution来替换原来Inception v3中的inception模块。inception结构介于常规卷积和我们此处的深度可分离卷积之间。Xception做到了更有效的利用模型参数。
结构的实现结果:
我们发现这个名为Xception的体系结构在ImageNet数据集(Inception V3的设计目的)上略胜过Inception V3,并且在包含3.5亿个图像和17,000个类的较大图像分类数据集上显著优于Inception V3。
Xception的提出过程:
1.卷积神经网络发展回顾:
1.卷积神经网络设计的历史始于LeNet风格的模型[10],这些模型是卷积(用于特征提取)和池化(用于空间子采样)的简单堆叠。
2.在2012年,这些想法被改写入AlexNet架构[9],其中卷积操作在最大池操作之间重复多次,使网络能够在每个空间范围内学习更丰富的特性。
3.随之而来的趋势是使这种网络风格变得更加深入,主要由每年的ILSVRC竞赛推动;首先与2013年的Zeiler和Fergus [25],然后是2014年的VGG架构[18]。
4.此时出现了一种新型的网络,Szegedy等人介绍的Inception架构。在2014年[20]为GoogLeNet(Inception V1),后来被改为Inception V2 [7],Inception V3 [21],以及最近的Inception-ResNet [19]。初期本身受到早期的NetworkIn-Network架构的启发[11]。自从首次推出以来,Inception一直是ImageNet数据集上性能最佳的系列之一[14],以及Google使用的内部数据集,尤其是JFT [5]。
2.Xception结构的提出:
1.inception功能回顾:
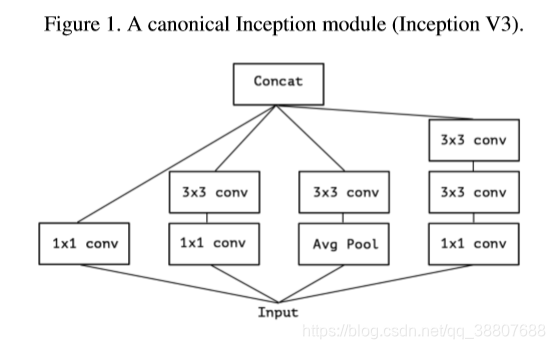
Inception风格模型的基本组成部分是Inception模块,其中存在几个不同的版本。在图1中,我们展示了Inception V3架构中的Inception模块的典型结构。初始模型可以被理解为一堆这样的模块。这与早期的VGG式网络有所不同,它们是简单卷积层的堆叠。虽然初始模块在概念上类似于卷积(它们是卷积特征提取器),但它们凭经验似乎能够用更少的参数学习更丰富的表示。(博客上的某个理解:Inception的初衷可以认为是:特征的提取和传递可以通过1*1卷积,3*3卷积,5*5卷积,pooling等,到底哪种才是最好的提取特征方式呢?Inception结构将这个疑问留给网络自己训练,也就是将一个输入同时输给这几种提取特征方式,然后做聚合。Inception v3和Inception v1(googleNet)对比主要是将5*5卷积换成两个3*3卷积层的叠加)。
常规卷积层尝试在3D空间中学习滤波器,具有2个空间维度(宽度和高度)和一个通道维度;因此单个卷积内核的任务是同时映射通道相关性和空间相关性。
Inception模块背后的理念是通过将这个过程明确地分解为一系列独立考虑通道相关性和空间相关性的操作,使这个过程更容易,更有效。它的假设就是通道相关性和空间相关性已经被充分解耦。
具体看来,inception是这么做的:
典型的Inception模块首先通过一组1×1卷积来查看交叉通道相关性,将输入数据映射到3或4个小于原始输入空间的分离的空间,然后将前面所有相关性映射到较小的3D空间中(例如常规的3x3或5x5卷积)。
2.Xception改进步骤:
Xception是对inceptionv3结构的一种改进,核心是采用depthwise separable convolution(深度可分离卷积)来替代原来的inception v3中的inception模块。
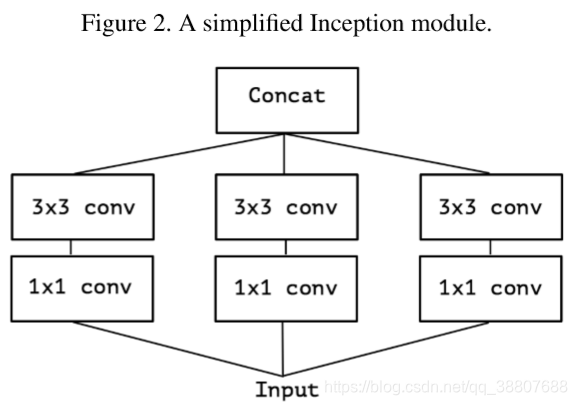
1.考虑一个简单版本的Inception模块,它只使用一种卷积大小(例如3x3),并且不包含平均汇集层(图2)。这个Inception模块被重新配置为一个大的1x1卷积,然后是空间卷积,这些卷积可以在输出通道的非重叠段上运行(因为只有一种3*3的空间卷积,所以没有在输出通道上覆盖运行)。
观察这个简单版本的inception模块,很容易产生这两个问题:
1.inception中的卷积块的个数和大小都会产生什么影响?
2.是否可以假设通道间的相关性和空间上的相关性可以靠这种方式完全分开?
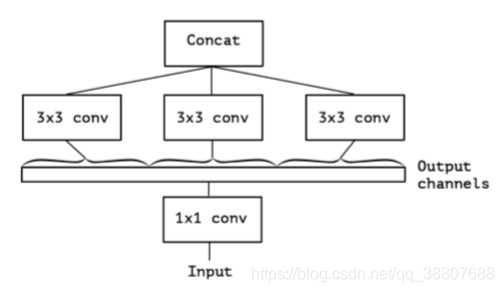
2.卷积和可分离卷积之间的连续体
inception模块的“极端”版本,基于上面第二点的假设,将首先使用1x1卷积来映射跨通道相关性,然后分别映射每个输出通道的空间相关性(inceptionv3模块交替使用7x1和1x7卷积做到这种空间上可分离的效果)。这在图4中显示。这种极端形式已经几乎与深度可分离卷积(一种很流行的网络结构设计)相同了。
注意空间可分离卷积不要和深度可分离卷积混淆。
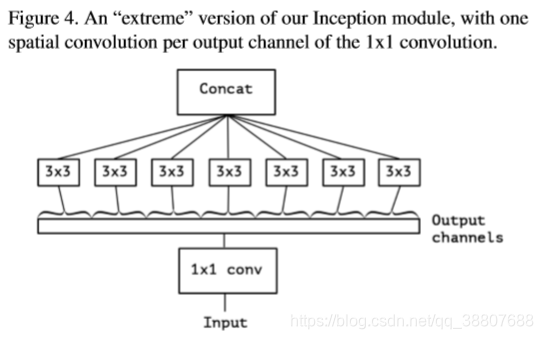
现在,这个极端版本的inception模块和我们的深度可分离卷积的区别就之后以下几点了:
1.操作顺序:通常实现的深度可分卷积(例如在TensorFlow中)执行第一个通道空间卷积,然后执行1x1卷积,而Inception首先执行1x1卷积。
2.第一个操作后是否有非线性。Inception中,第一步和第二部操作都有非线性(ReLU);而depthwise separable卷积后面通常没有非线性操作。
分析:
上面两点不同种,第一点不同不太重要,因为这些操作旨在用于堆叠设置,第二点不同比较重要,后面将做实验对比。
一个理论上的分析:
普通卷积和深度可分卷积之间存在一个离散谱,输入的每个通道(每张Fm)都对应一个频率,这个频谱被空间卷积的数量参数化。普通卷积将频谱里各种频率合成一个,inception结构将他们合成3-4个,深度可分离卷积则对每一个频率做卷积操作。所以,在inception结构和深度可分离卷积之间还存在一个中间状态,这一块的特性还没有人探索过。
基于以上观察,可以把Inception结构替换为depthwise separable卷积。深度可分离卷积被用作Inception V1和Inception V2的第一层[20,7](应该是指这种思想,分离通道与特征)。
3.Xception架构:
我们提出了完全基于深度可分卷积层的卷积神经网络架构。实际上,我们做出以下假设:
卷积神经网络特征映射中各通道相关性和空间相关性的映射可以完全解耦。
因为这个假设是inception架构下的假设的更强版本,所以我们将我们提出的建议架构命名为Xception(代表“Extreme Inception”)。
图5给出了网络的完整描述。Xception架构具有36个卷积层,形成网络的特征提取基础。在我们的实验评估中,我们将专门研究图像分类,因此我们的卷积基础将会跟随一个逻辑回归层。可选地,可以在逻辑回归层之前插入全连接层,这在实验评估部分中进行了探索(具体参见图7和8)。36个卷积层被分为14个模块,除了第一个和最后一个模块外,所有这些模块都具有线性残差连接。
简而言之,Xception架构是一个具有残差连接的深度可分离卷积层的线性堆叠。这使得架构非常容易定义和修改;使用像Keras [2]或TensorFlow-Slim [17]这样的高级库只需要30到40行代码,与VGG-16 [18]等体系结构不同,但与Inception V2或V3的定义要复杂得多。作为Keras应用模块2的一部分,在MIT许可下提供了使用Keras和TensorFlow的Xception的开源实现。
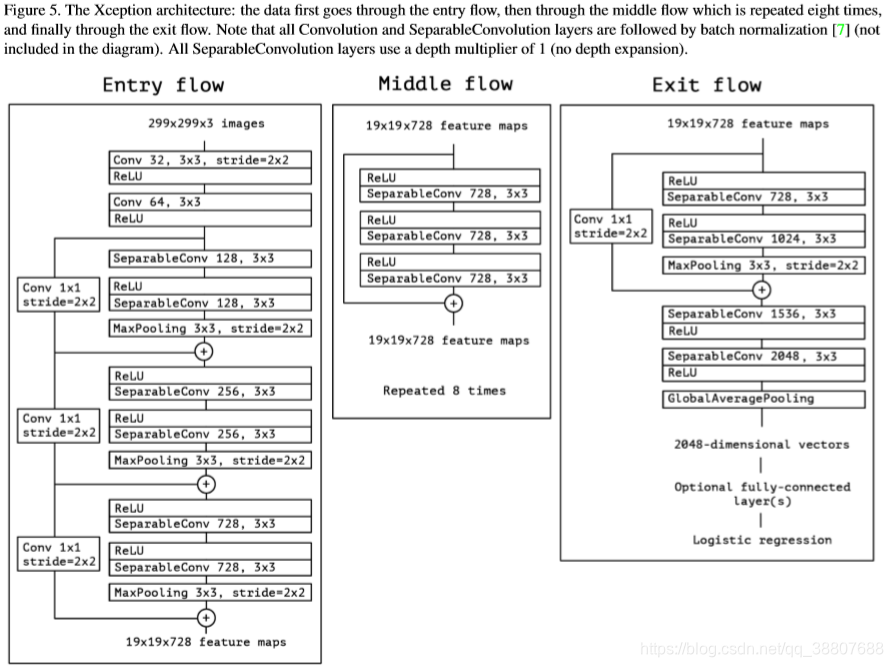
图5. Xception架构:数据首先通过入口流,然后通过重复8次的中间流,最后通过出口流。请注意,所有的卷积和SeparableConvolution图层都遵循批量归一化[7](未包含在图中)。所有SeparableConvolution图层都使用1的倍数(无深度扩展)。
Xception架构的实验评估:
我们选择将Xception与Inception V3架构进行比较,因为它们的规模相似:Xception和Inception V3的参数数量几乎相同(表3),因此任何性能差距都不能归因于网络容量的差异.
模型配置:
ImageNet和JFT数据集使用了不同的优化配置:
•在ImageNet上:
- 优化器:SGD 同步梯度下降
- 动量:0.9
- 初始学习率:0.045
- 学习速率衰减:每2个时期0.94的衰减率
•在JFT上:
- 优化器:RMSprop [22] 异步梯度下降(加快训练速度)
- 动量:0.9
- 初始学习率:0.001
- 学习速率衰减:速率衰减0.9每3,000,000个样本
(JFT模型没有接受完全收敛的训练,每个实验需要花费三个月的时间)
对于两个数据集,Xception和Inception V3都使用相同的完全相同的优化配置。权重衰减:Inception V3模型使用4e-5,xception使用了1e-5.imagenet中两种模型都在逻辑回归之前使用了droupout,jft数据中没有使用。辅助分类器,inceptionV3中使用了,xception中没有。
实验结果比较:
分类结果:
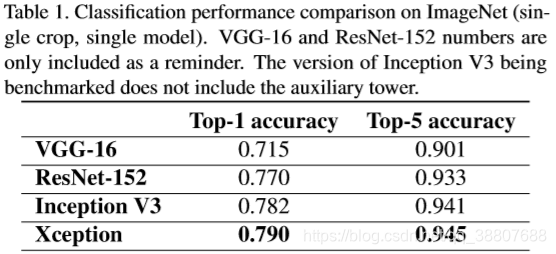
所有的评估都是在输入图像和单一模型的单一作物上进行的。ImageNet结果在验证集上报告,而不是在测试集上(即在ILSVRC 2012的验证集的非黑名单图像上)。JFT结果在3000万次迭代(训练一个月)后报告,而不是完全收敛后。结果见表1和表2,以及图6,图7,图8。在JFT上,我们测试了两个不包含任何完全连接图层的网络版本,以及在逻辑回归图层之前包含两个4096个完全连接图层的版本。

结论:
与ImageNet数据集相比,Xception架构在JFT数据集上显示出更大的性能提升。我们认为这可能是因为Inception V3是以ImageNet为中心开发的,因此可以通过设计来克服这一特定任务。另一方面,没有任何架构针对JFT进行过调整。在ImageNet上寻找更好的Xception超参数(尤其是优化参数和参数化参数)可能会产生显着的额外改进。两种架构的参数数量几乎相同这一事实表明,ImageNet和JFT上的改进不是来自增加的容量,而是来自更有效地使用模型参数。
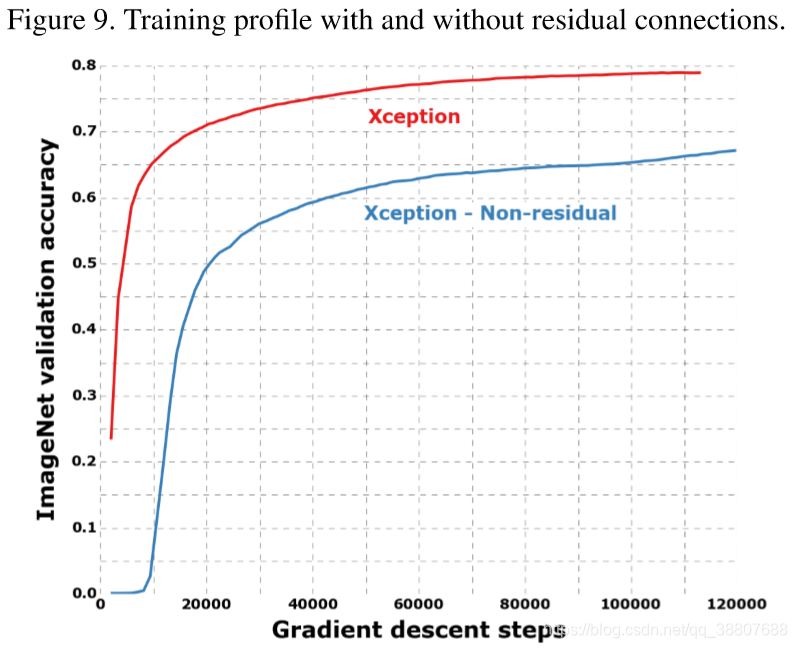
残差结构对Xception的影响:
为了量化Xception架构中剩余连接的好处,我们在ImageNet上进行了基于Xception的修改版本的基准测试,该版本不包含任何剩余连接。结果如图9所示。在速度和最终分类性能方面,残余连接显然对于帮助融合非常重要。但是我们会注意到,使用与残差模型相同的优化配置对非残差模型进行基准测试可能是不合适的,而更好的优化配置可能会产生更多的竞争结果。
深度可分离卷积中depthwise和pointwise卷积之间使用的激活函数的验证:
1.我们前面提到,深度可分卷积和Inception模块之间的类比表明深度可分卷积应该包括depthwise and pointwise之间的非线性。在迄今为止报道的实验中,没有包括这种非线性。然而,我们也通过实验测试了ReLU或ELU [3]作为中间非线性。图10中报告了ImageNet的结果,并表明没有任何非线性会导致更快的收敛和更好的性能。
2.这是一个了不起的观察,因为在Inception模块中报告《Rethinking the inception architecture for computer vision》中的相反结果。这可能和特征空间深度相关:深特征空间(inception模块中)的非线性是有帮助的,但对于浅(例如depthwise卷积,1-channel特征空间),它可能由于信息丢失而变得有害。
欢迎批评指正,讨论学习~
最近在github放了两份分类的代码,分别是用Tensorflow和Pytorch实现的,主要用于深度学习入门,学习Tensorflow和Pytorch搭建网络基本的操作。打算将各网络实现一下放入这两份代码中,有兴趣可以看一看,期待和大家一起维护更新。
代码地址:
Tensorflow实现分类网络
Pytorch实现分类网络

















 4041
4041

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









